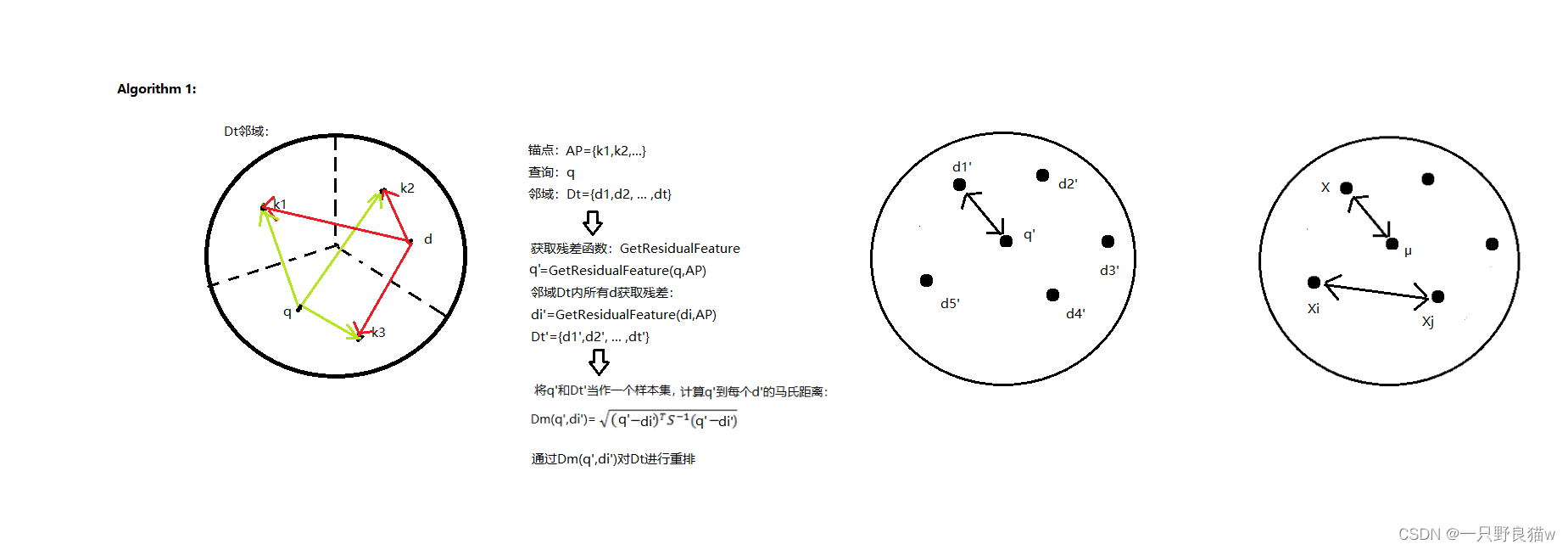
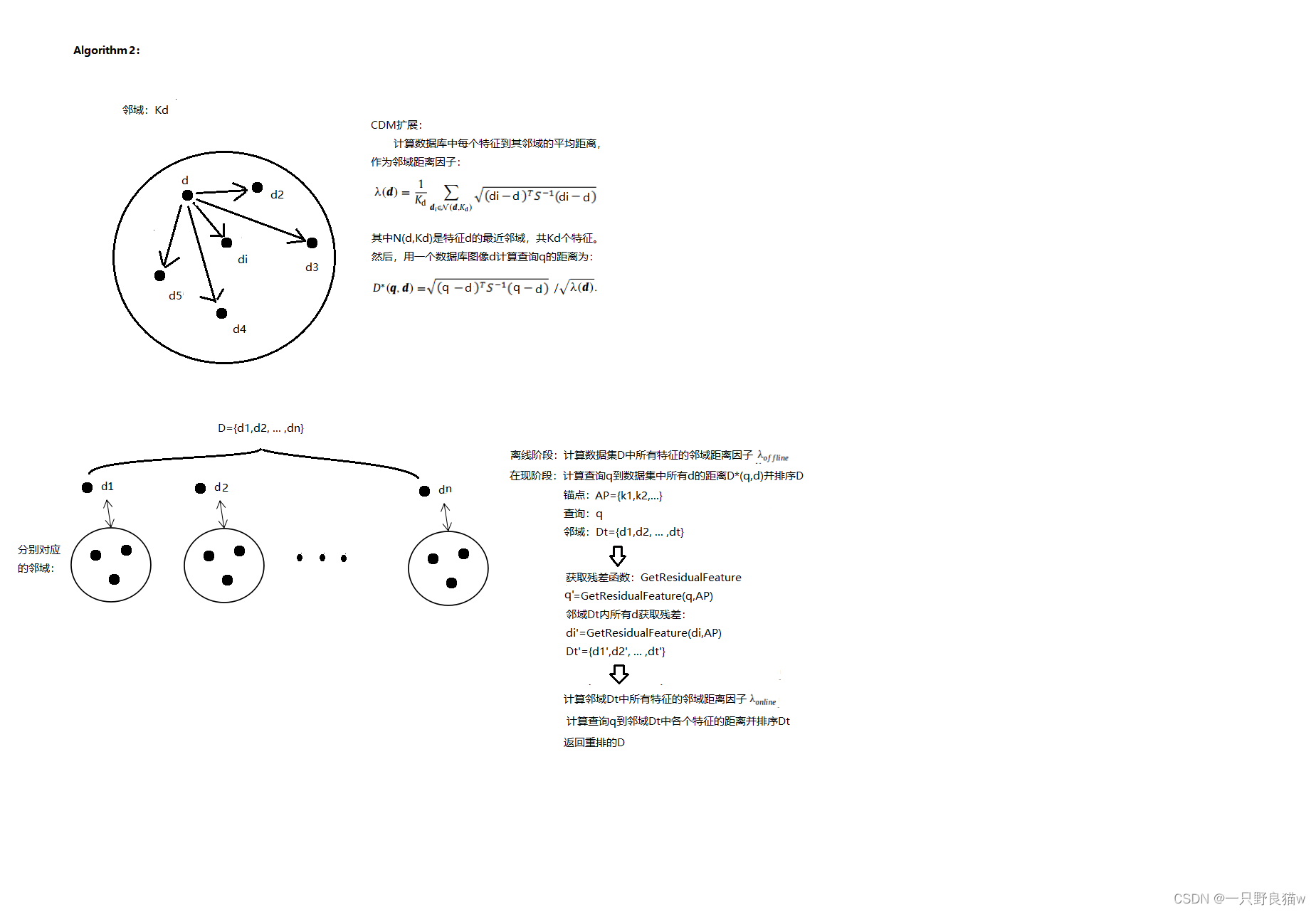
马氏距离
一、基本概念:
- 方差:方差是标准差的平方,而标准差的意义是数据集中各个点到均值点距离的平均值。反应的是数据的离散程度。
- 协方差:标准差与方差是描述一维数据的,当存在多维数据时,我们通常需要知道每个维数的变量中间是否存在关联。协方差就是衡量多维数据集中,变量之间相关性的统计量。比如说,一个人的身高与他的体重的关系,这就需要用协方差来衡量。如果两个变量之间的协方差为正值,则这两个变量之间存在正相关,若为负值,则为负相关。
- 协方差矩阵:当变量多了,超过两个变量了。那么,就用协方差矩阵来衡量这么多变量之间的相关性。假设X是以n个随机变数(其中的每个随机变数是也是一个向量,当然是一个行向量)组成的列向量:

其中,μi 是第i个元素的期望值,即 μi=E(Xi)。协方差矩阵的第i,j项(第i,j项是一个协方差)被定义为如下形式:
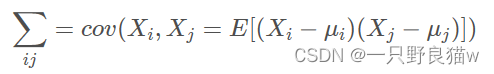
即:
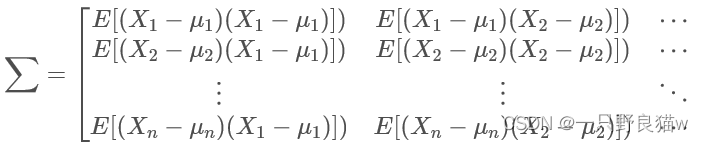
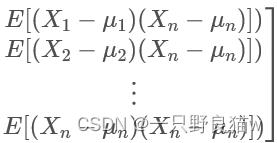
矩阵中的第(i,j) 个元素是Xi与Xj的协方差。
均值 :
 kkk
kkk 方差:
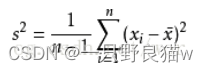
二、马氏距离
马氏距离(Mahalanobis Distance)是度量学习中一种常用的距离指标,同欧氏距离、曼哈顿距离、汉明距离等一样被用作评定数据之间的相似度指标。但却可以应对高维线性分布的数据中各维度间非独立同分布的问题。
马氏距离(Mahalanobis Distance)是一种距离的度量,表示点与一个分布之间的距离。它是一种有效的计算两个未知样本集的相似度的方法可以看作是欧氏距离的一种修正,修正了欧式距离中各个维度尺度不一致且相关的问题。
有M个样本向量X1~Xm,样本均值μ=( μ1, μ2, μ3, ... , μm)^T, Σ是多维随机变量x的协方差矩阵,则当中样本向量X到μ的马氏距离表示为:
而当中向量Xi与Xj之间的马氏距离定义为:
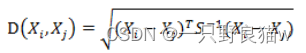
如果协方差矩阵是单位阵,也就是各维度独立同分布,马氏距离就变成了欧氏距离:
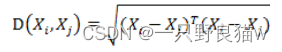
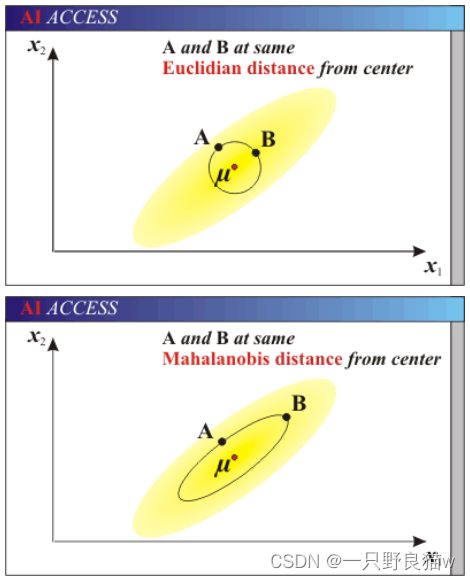
马氏距离的优点:
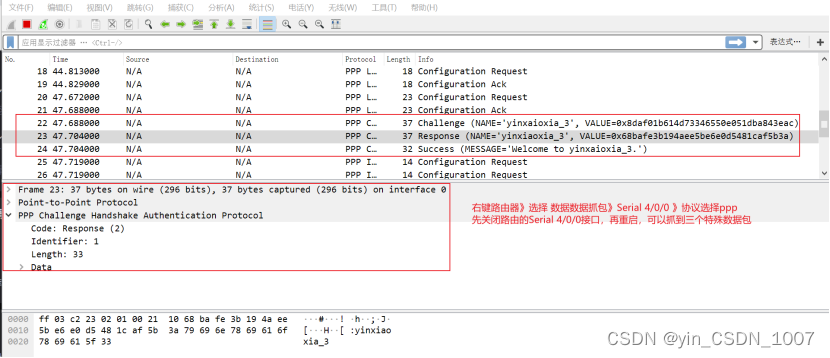
马氏距离不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关;由标准化数据和中心化数据(即原始数据与均值之差)计算出的二点之间的马氏距离相同。 马氏距离还可以排除变量之间的相关性的干扰。
下面看一个例子:
如果我们以厘米为单位来测量人的身高,以克(g)为单位测量人的体重。每个人被表示为一个两维向量,如一个人身高173cm,体重50000g,表示为(173,50000),根据身高体重的信息来判断体型的相似程度。
我们已知小明(160,60000);小王(160,59000);小李(170,60000)。根据常识可以知道小明和小王体型相似。但是如果根据欧几里得距离来判断,小明和小王的距离要远远大于小明和小李之间的距离,即小明和小李体型相似。 这是因为不同特征的度量标准之间存在差异而导致判断出错。
以克(g)为单位测量人的体重,数据分布比较分散,即方差大,而以厘米为单位来测量人的身高,数据分布就相对集中,方差小。 马氏距离的目的就是把方差归一化,使得特征之间的关系更加符合实际情况。
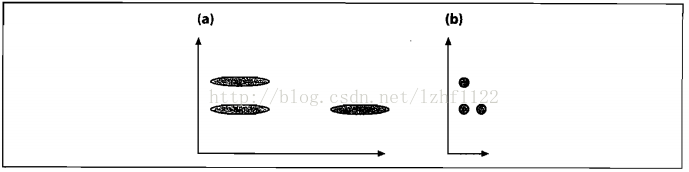
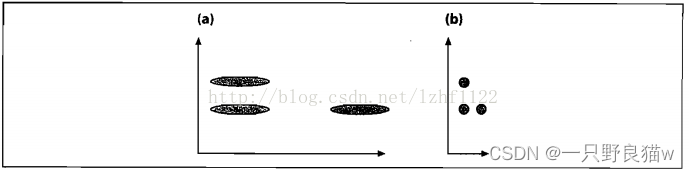
下图(a)展示了三个数据集的初始分布,看起来竖直方向上的那两个集合比较接近。在我们 根据数据的协方差归一化空间之后,如图(b),实际上水平方向上的两个集合比较接近。
深入分析:
当求距离的时候,由于随机向量的每个分量之间量级不一样,比如说x1可能取值范围只有零点几,而x2有可能时而是2000,时而是3000,因此两个变量的离散度具有很大差异。
马氏距离除以了一个方差矩阵,这就把各个分量之间的方差都除掉了,消除了量纲性,更加科学合理。
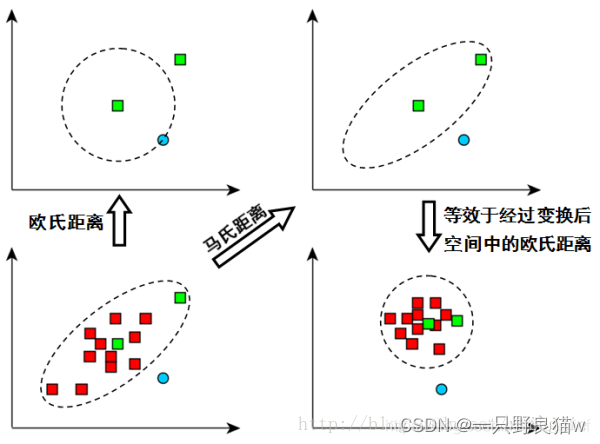
如上图,看左下方的图,比较中间那个绿色的和另外一个绿色的距离,以及中间绿色到蓝色的距离。 如果不考虑数据的分布,就是直接计算欧式距离,那就是蓝色距离更近。
但实际上需要考虑各分量的分布的,呈椭圆形分布。 蓝色的在椭圆外,绿色的在椭圆内,因此绿色的实际上更近。
马氏距离除以了协方差矩阵,实际上就是把右上角的图变成了右下角。