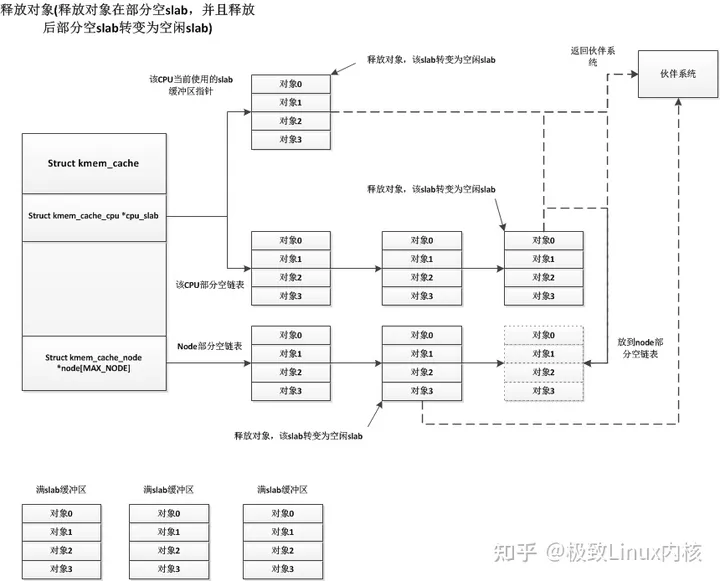
再来看内置式对象,如下图所示。指针位于对象的头部,与对象共用存储空间。这是因为对象被分配出去之前,其存储空间是空闲的可用状态,可用于存放空闲对象指针。对象被分配出去后,也不再需要这个指针了,可以被对象内容覆盖。同理,对象释放时,不再使用对象内容,其空间可以用于存放指针。
如果在分配之前或释放之后,使用了对象的存储空间,那么就不能使用内置式指针,必须使用外置式指针,比如:
1)对象构造函数不为空:这样调用构造函数时,对象的存储空间被构造函数初始化。
2)使能了某些调试标记位:比如__OBJECT_POISON标记位,这样对象的存储空间会被初始化为固定的值,以利于调试。
struct kmem_cache *kmem_cache_create(const char *name, size_t size,
size_t align, unsigned long flags, void (*ctor)(void *))
{
struct kmem_cache *s;
char *n;
if (WARN_ON(!name))
return NULL;
down_write(&slub_lock);
/*是否能复用已有的cache,能复用的都是内置式对象*/
s = find_mergeable(size, align, flags, name, ctor);
if (s) {
/* cache引用计数加一,表示又多了一种对象使用此cache */
s->refcount++;
/*
* Adjust the object sizes so that we clear
* the complete object on kzalloc.
*/
/*新的对象实际大小为较大对象的实际大小*/
s->objsize = max(s->objsize, (int)size);
/* inuse包括对象实际大小、word对齐大小*/
s->inuse = max_t(int, s->inuse, ALIGN(size, sizeof(void *)));
/*添加一个sysfs的别名*/
if (sysfs_slab_alias(s, name)) {
s->refcount--;
goto err;
}
up_write(&slub_lock);
return s;
}
/*走到这说明不能合并,需要创建一个新的cache */
/*拷贝cache名*/
n = kstrdup(name, GFP_KERNEL);
if (!n)
goto err;
/*分配节点使用的struct kmem_cache对象,注意这里与slab模型不同,没有通过kmem_cache_alloc从struct kmem_cache cache分配,而是根据大小从kmalloc cache中分配。事实上只有struct kmem_cache_node、struct kmem_cache、kmalloc[3-13]这些slub模型初始化阶段创建的cache,其cache节点使用的struct kmem_cache对象是从struct kmem_cache cache分配的,slub初始化完成后再创建cache时,其struct kmem_cache对象都是从kmalloc cache中分配的。*/
s = kmalloc(kmem_size, GFP_KERNEL);
if (s) {
/*初始化struct kmem_cache对象*/
if (kmem_cache_open(s, n,
size, align, flags, ctor)) {
/*加入到全局cache链表中*/
list_add(&s->list, &slab_caches);
/*加入到sysfs中*/
if (sysfs_slab_add(s)) {
list_del(&s->list);
kfree(n);
kfree(s);
goto err;
}
up_write(&slub_lock);
return s;
}
kfree(n);
kfree(s);
}
err:
up_write(&slub_lock);
if (flags & SLAB_PANIC)
panic("Cannot create slabcache %s\n", name);
else
s = NULL;
return s;
}
find_mergeable
遍历已有的cache,看待创建的cache是否能和已有的cache合并。
static struct kmem_cache *find_mergeable(size_t size,
size_t align, unsigned long flags, const char *name,
void (*ctor)(void *))
{
struct kmem_cache *s;
/* SLUB_NEVER_MERGE定义了一些不允许cache复用的标记*/
if (slub_nomerge || (flags & SLUB_NEVER_MERGE))
return NULL;
/*构造函数非空的对象不能复用cache。与SLUB_NEVER_MERGE一起将外置式对象的cache排除在外,此类cache如果复用,空闲对象指针的位置无法确定*/
if (ctor)
return NULL;
/*计算word对齐后的对象大小*/
size = ALIGN(size, sizeof(void *));
/*计算obj对齐大小*/
align = calculate_alignment(flags, align, size);
/*得到对象的总对齐大小,包括word对齐与obj对齐。由于走到这的都是内置式,指针不占用空间,所以对齐大小也就是总大小。*/
size = ALIGN(size, align);
flags = kmem_cache_flags(size, flags, name, NULL);
/*遍历现有的cache节点*/
list_for_each_entry(s, &slab_caches, list) {
/*此cache不能合并,跳过*/
if (slab_unmergeable(s))
continue;
/*已有cache的对象总大小小于待创建cache的对象总大小,跳过*/
if (size > s->size)
continue;
/*标志位不符,跳过*/
if ((flags & SLUB_MERGE_SAME) != (s->flags & SLUB_MERGE_SAME))
continue;
/*
* Check if alignment is compatible.
* Courtesy of Adrian Drzewiecki
*/
/*对象大小不满足对齐要求,跳过*/
if ((s->size & ~(align - 1)) != s->size)
continue;
/*已有cache的对象总大小过大,跳过*/
if (s->size - size >= sizeof(void *))
continue;
/*层层筛查之后,终于找到了意中人:已有cache的对象总大小大于等于待创建cache的对象总大小,并且相差不超过sizeof(void *) */
return s;
}
return NULL;
}
slab_unmergeable
检查一个cache是否可以复用。
static int slab_unmergeable(struct kmem_cache *s)
{
/*外置式对象指针的cache不允许复用*/
if (slub_nomerge || (s->flags & SLUB_NEVER_MERGE))
return 1;
if (s->ctor)
return 1;
/*
* We may have set a slab to be unmergeable during bootstrap.
*/
/* boot阶段创建的cache,不允许复用*/
if (s->refcount < 0)
return 1;
return 0;
}
kmem_cache_open
初始化struct kmem_cache对象。
参数:
1)s:待初始化的struct kmem_cache对象
2)name:cache的名字
3)size:对象大小
4)align:对齐方式
5)flags:标志
6)ctor:构造函数指针
static int kmem_cache_open(struct kmem_cache *s,
const char *name, size_t size,
size_t align, unsigned long flags,
void (*ctor)(void *))
{
/*初始化struct kmem_cache对象*/
memset(s, 0, kmem_size);
s->name = name;
s->ctor = ctor;
/* objsize保存对象实际大小*/
s->objsize = size;
/*对齐方式*/
s->align = align;
/*标志*/
s->flags = kmem_cache_flags(size, flags, name, ctor);
/*计算此对象slab页块order及对象个数*/
if (!calculate_sizes(s, -1))
goto error;
if (disable_higher_order_debug) {
……
}
/*
* The larger the object size is, the more pages we want on the partial
* list to avoid pounding the page allocator excessively.
*/
/*依据对象大小计算部分满slab链中slab的最少数目。对象越大,部分满slab链所需页面越多,以保证对象数目,避免因对象不足,过多的调用页分配器*/
set_min_partial(s, ilog2(s->size));
/* cache的引用计数初始化为1。slub引入了cache复用机制,不同类型的对象,只要大小相差不大,符合一定的要求,就可以复用一个cache,这个refcount记录cache中有多少种对象,即此cache被多少种对象复用了*/
s->refcount = 1;
#ifdef CONFIG_NUMA
s->remote_node_defrag_ratio = 1000;
#endif
/*分配struct kmem_cache_node对象,即slab双链*/
if (!init_kmem_cache_nodes(s))
goto error;
/*分配struct kmem_cache_cpu对象*/
if (alloc_kmem_cache_cpus(s))
/*分配成功,返回*/
return 1;
/*前面分配失败,释放资源*/
free_kmem_cache_nodes(s);
error:
if (flags & SLAB_PANIC)
panic("Cannot create slab %s size=%lu realsize=%u "
"order=%u offset=%u flags=%lx\n",
s->name, (unsigned long)size, s->size, oo_order(s->oo),
s->offset, flags);
return 0;
}
calculate_sizes
计算每个slab页块的order以及每个slab中对象个数。
参数:
1)s:cache指针
2)forced_order:小于0时,使用计算的order,大于等于0时,使用此参数指定的order。
static int calculate_sizes(struct kmem_cache *s, int forced_order)
{
unsigned long flags = s->flags;
unsigned long size = s->objsize;
unsigned long align = s->align;
int order;
/*
* Round up object size to the next word boundary. We can only
* place the free pointer at word boundaries and this determines
* the possible location of the free pointer.
*/
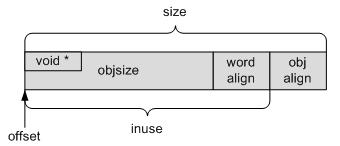
/* word对齐。对象后面需存放下一个空闲对象的指针,该指针的地址必须是word对齐的*/
size = ALIGN(size, sizeof(void *));
#ifdef CONFIG_SLUB_DEBUG
/*
* Determine if we can poison the object itself. If the user of
* the slab may touch the object after free or before allocation
* then we should never poison the object itself.
*/
if ((flags & SLAB_POISON) && !(flags & SLAB_DESTROY_BY_RCU) &&
!s->ctor)
/*通过填充标识出对象位置,调试用。此类对象必须采用外置式存放指针*/
s->flags |= __OBJECT_POISON;
else
s->flags &= ~__OBJECT_POISON;
/*
* If we are Redzoning then check if there is some space between the
* end of the object and the free pointer. If not then add an
* additional word to have some bytes to store Redzone information.
*/
/* Redzone需要一个额外的word空间*/
if ((flags & SLAB_RED_ZONE) && size == s->objsize)
size += sizeof(void *);
#endif
/*
* With that we have determined the number of bytes in actual use
* by the object. This is the potential offset to the free pointer.
*/
/* inuse包括对象实际大小、word对齐大小,对于外置式对象而言,即空闲对象指针的偏移*/
s->inuse = size;
if (((flags & (SLAB_DESTROY_BY_RCU | SLAB_POISON)) ||
s->ctor)) {
/*
* Relocate free pointer after the object if it is not
* permitted to overwrite the first word of the object on
* kmem_cache_free.
*
* This is the case if we do RCU, have a constructor or
* destructor or are poisoning the objects.
*/
/*外置式对象,空闲对象指针的偏移*/
s->offset = size;
/*对象总大小加上指针大小*/
size += sizeof(void *);
}
#ifdef CONFIG_SLUB_DEBUG
if (flags & SLAB_STORE_USER)
/*
* Need to store information about allocs and frees after
* the object.
*/
size += 2 * sizeof(struct track);
if (flags & SLAB_RED_ZONE)
/*
* Add some empty padding so that we can catch
* overwrites from earlier objects rather than let
* tracking information or the free pointer be
* corrupted if a user writes before the start
* of the object.
*/
size += sizeof(void *);
#endif
/*
* Determine the alignment based on various parameters that the
* user specified and the dynamic determination of cache line size
* on bootup.
*/
/*计算对象的obj对齐大小*/
align = calculate_alignment(flags, align, s->objsize);
s->align = align;
/*
* SLUB stores one object immediately after another beginning from
* offset 0. In order to align the objects we have to simply size
* each object to conform to the alignment.
*/
/*叠加obj对齐后的对象总大小*/
size = ALIGN(size, align);
/*保存对象总大小*/
s->size = size;
if (forced_order >= 0)
/*使用指定的order */
order = forced_order;
else
/*计算slab页块的order */
order = calculate_order(size);
if (order < 0)
return 0;
s->allocflags = 0;
if (order)
/*多于一个页面,采用大页面方式*/
s->allocflags |= __GFP_COMP;
if (s->flags & SLAB_CACHE_DMA)
s->allocflags |= SLUB_DMA;
if (s->flags & SLAB_RECLAIM_ACCOUNT)
s->allocflags |= __GFP_RECLAIMABLE;
/*
* Determine the number of objects per slab
*/
/* oo成员的高位保存页块order,低位保存对象个数*/
s->oo = oo_make(order, size);
/*按一个对象大小计算页面order,此为最小order */
s->min = oo_make(get_order(size), size);
/*更新最大order */
if (oo_objects(s->oo) > oo_objects(s->max))
s->max = s->oo;
return !!oo_objects(s->oo);
}
calculate_order
计算每个slab由多少个页面组成。
static inline int calculate_order(int size)
{
int order;
int min_objects;
int fraction;
int max_objects;
/*
* Attempt to find best configuration for a slab.This
* works by first attempting to generate a layout with
* the best configuration and backing off gradually.
*
* First we reduce the acceptable waste in a slab.Then
* we reduce the minimum objects required in a slab.
*/
/*全局变量slub_min_objects保存配置的slab内最小对象数*/
min_objects = slub_min_objects;
/*如果没有配置,依据CPU个数计算之*/
if (!min_objects)
min_objects = 4 * (fls(nr_cpu_ids) + 1);
/*全局变量slub_max_order保存slab页块最大order数,依据它计算某对象的最大对象数*/
max_objects = (PAGE_SIZE << slub_max_order)/size;
/*最小对象数当然要取两者中最小的那个*/
min_objects = min(min_objects, max_objects);
/*首先依据最小对象数计算每个slab包含多少页面*/
while (min_objects > 1) {
/* fraction为计算碎片大小的基数,取值越小,条件越宽,碎片越多*/
fraction = 16;
/*不断放宽碎片大小的限制*/
while (fraction >= 4) {
/*计算页面order */
order = slab_order(size, min_objects,
slub_max_order, fraction);
/*如果order小于最大order,符合条件,返回*/
if (order <= slub_max_order)
return order;
/*超过了最大order,减少碎片计算基数*/
fraction /= 2;
}
/*放宽最小对象数的限制,重新计算*/
min_objects--;
}
/*
* We were unable to place multiple objects in a slab. Now
* lets see if we can place a single object there.
*/
/*走到这,说明前面无法找到一个合适的页块order,看看能不能只放下一个对象。碎片基数为1,表示忽略碎片方面的限制*/
order = slab_order(size, 1, slub_max_order, 1);
if (order <= slub_max_order)
return order;
/*
* Doh this slab cannot be placed using slub_max_order.
*/
/*还不行,只能提高order的上限了,MAX_ORDER定义了最大order */
order = slab_order(size, 1, MAX_ORDER, 1);
if (order < MAX_ORDER)
return order;
/*还不行,返回错误*/
return -ENOSYS;
}
slab_order
计算每个slab由多少个页面组成。
参数:
1)size:对象对齐后大小。
2)min_objects:slab至少放下多少个对象。
3)max_order:每个slab最多包含2max_order个页面。
4)fract_leftover:检查碎片时的基数
static inline int slab_order(int size, int min_objects,
int max_order, int fract_leftover)
{
int order;
int rem;
/*全局变量slub_min_order保存配置的最小order值*/
int min_order = slub_min_order;
/* MAX_OBJS_PER_PAGE指一个slab(1或多个页组成的大页面)内最多对象数,值为65535,因为struct page中objects成员为u16类型。如果对象数超出这个上限,根据上限计算order。*/
if ((PAGE_SIZE << min_order) / size > MAX_OBJS_PER_PAGE)
/* get_order将页面大小转换成页面order */
return get_order(size * MAX_OBJS_PER_PAGE) - 1;
/* min_order为配置的最小order,fls(min_objects * size - 1) - PAGE_SHIFT为依据参数计算的最小order,取二者中较大的为最小order,以同时满足限定条件*/
for (order = max(min_order,
fls(min_objects * size - 1) - PAGE_SHIFT);
order <= max_order; order++) {
unsigned long slab_size = PAGE_SIZE << order;
/*不满足min_objects的要求,尝试更高一级order。规定一个slab内最小对象数,以避免产生过多的部分满slab块*/
if (slab_size < min_objects * size)
continue;
/*计算碎片大小*/
rem = slab_size % size;
/*依据基数检查碎片大小,比如基数为16,那么碎片小于等于slab总大小的1/16时碎片满足要求,跳出*/
if (rem <= slab_size / fract_leftover)
break;
}
return order;
}
init_kmem_cache_nodes
分配struct kmem_cache_node对象,即slab双链。
static int init_kmem_cache_nodes(struct kmem_cache *s)
{
int node;
/*初始化每个内存节点的struct kmem_cache_node */
for_each_node_state(node, N_NORMAL_MEMORY) {
struct kmem_cache_node *n;
/* slub分配器还未完成初始化,意味着struct kmem_cache_node所在的cache还未建立,还不能使用kmem_cache_alloc函数分配对象*/
if (slab_state == DOWN) {
/*初始化阶段分配一个struct kmem_cache_node对象*/
early_kmem_cache_node_alloc(node);
continue;
}
/* struct kmem_cache_node所在的cache(由全局变量kmem_cache_node保存)已经初始化好,直接从里面分配一个空闲对象*/
n = kmem_cache_alloc_node(kmem_cache_node,
GFP_KERNEL, node);
if (!n) {
free_kmem_cache_nodes(s);
return 0;
}
/* struct kmem_cache对象的node指针指向刚分配的struct kmem_cache_node对象*/
s->node[node] = n;
/*初始化struct kmem_cache_node对象*/
init_kmem_cache_node(n, s);
}
return 1;
}
early_kmem_cache_node_alloc
初始化阶段分配一个struct kmem_cache_node对象。
static void early_kmem_cache_node_alloc(int node)
{
struct page *page;
struct kmem_cache_node *n;
unsigned long flags;
BUG_ON(kmem_cache_node->size < sizeof(struct kmem_cache_node));
/*创建struct kmem_cache_node对象cache的一个slab */
page = new_slab(kmem_cache_node, GFP_NOWAIT, node);
BUG_ON(!page);
/*创建的slab不在本内存节点*/
if (page_to_nid(page) != node) {
printk(KERN_ERR "SLUB: Unable to allocate memory from "
"node %d\n", node);
printk(KERN_ERR "SLUB: Allocating a useless per node structure "
"in order to be able to continue\n");
}
/*获得本slab第一个空闲对象的指针*/
n = page->freelist;
BUG_ON(!n);
/*提取第一个空闲对象,指针记录下一个空闲对象*/
page->freelist = get_freepointer(kmem_cache_node, n);
/*分配对象数加一*/
page->inuse++;
/*设置cache到slab双链的指针*/
kmem_cache_node->node[node] = n;
#ifdef CONFIG_SLUB_DEBUG
/*填充对象,调试用*/
init_object(kmem_cache_node, n, SLUB_RED_ACTIVE);
init_tracking(kmem_cache_node, n);
#endif
/*初始化struct kmem_cache_node对象*/
init_kmem_cache_node(n, kmem_cache_node);
/*更新cache内slab数和对象数*/
inc_slabs_node(kmem_cache_node, node, page->objects);
/*
* lockdep requires consistent irq usage for each lock
* so even though there cannot be a race this early in
* the boot sequence, we still disable irqs.
*/
local_irq_save(flags);
/*将新创建的slab加入部分满链*/
add_partial(n, page, 0);
local_irq_restore(flags);
}
init_kmem_cache_node
初始化struct kmem_cache_node对象,即slab双链。
static void
init_kmem_cache_node(struct kmem_cache_node *n, struct kmem_cache *s)
{
/*部分满slab数目清0 */
n->nr_partial = 0;
spin_lock_init(&n->list_lock);
/*初始化部分满slab链表头*/
INIT_LIST_HEAD(&n->partial);
#ifdef CONFIG_SLUB_DEBUG
/*初始化slab数和对象数*/
atomic_long_set(&n->nr_slabs, 0);
atomic_long_set(&n->total_objects, 0);
/*初始化满slab链表头。可见只有调试时,才需要满slab链*/
INIT_LIST_HEAD(&n->full);
#endif
}
alloc_kmem_cache_cpus
分配struct kmem_cache_cpu对象,即local slab。
static inline int alloc_kmem_cache_cpus(struct kmem_cache *s)
{
BUILD_BUG_ON(PERCPU_DYNAMIC_EARLY_SIZE <
SLUB_PAGE_SHIFT * sizeof(struct kmem_cache_cpu));
/*为每个cpu分配struct kmem_cache_cpu对象作为该cpu的local slab */
s->cpu_slab = alloc_percpu(struct kmem_cache_cpu);
return s->cpu_slab != NULL;
}