目录
一、概述
二、SLUB
2.1 数据结构
2.2 初始化
2.2.1 静态建立过程
2.3 API
2.3.1 kmem_cache_create
2.3.2 kmem_cache_alloc
2.3.3 kmem_cache_free
2.3.4 kmalloc/kfree
三、参考
一、概述
伙伴系统最小的分配单位是页,这对于较小的内存需求会造成浪费,所以在伙伴系统之上引入了slab。slab是相同大小内存块的集合,在具体设计上,考虑NUMA上node到cpu的层级关系,slub被设计成一个三级缓存的形式【1】:
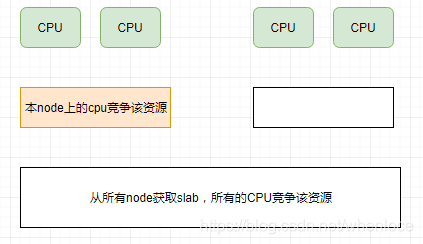
- 第一个层次,每cpu一个,无锁
- 第二个层次,每node一个,本node,cpu之间的锁
- 第三个层次,每NUMA一个,node之间的锁
和缓存的思想一样,越是下层开销越大,每个级别的cache增加内存分配/释放的性能。
二、SLUB
我们说,slab可以看做是相同大小的小块内存的集合,它的规格由kmem_cache描述。
2.1 数据结构
[include/linux/slub_def.h]
struct kmem_cache {struct kmem_cache_cpu __percpu *cpu_slab;/* Used for retriving partial slabs etc */slab_flags_t flags;unsigned long min_partial;unsigned int size; /* The size of an object including meta data */unsigned int object_size;/* The size of an object without meta data */unsigned int offset; /* Free pointer offset. */struct kmem_cache_order_objects oo;/* Allocation and freeing of slabs */struct kmem_cache_order_objects max;struct kmem_cache_order_objects min;gfp_t allocflags; /* gfp flags to use on each alloc */int refcount; /* Refcount for slab cache destroy */void (*ctor)(void *);unsigned int inuse; /* Offset to metadata */unsigned int align; /* Alignment */unsigned int reserved; /* Reserved bytes at the end of slabs */unsigned int red_left_pad; /* Left redzone padding size */const char *name; /* Name (only for display!) */struct list_head list; /* List of slab caches */unsigned int useroffset; /* Usercopy region offset */unsigned int usersize; /* Usercopy region size */struct kmem_cache_node *node[MAX_NUMNODES];
};其中描述slub规格的有:
- object_size 小块内存的实际大小
- size 每个小块内存实际需要的大小
- offset 到空闲指针的偏移
- oo 记录slab占用页面大小(order)和slab obj的数量
- inuse 到metadata的偏移
- align 对齐
- reserved slab 一般不能正好容纳obj,表示剩余的空间
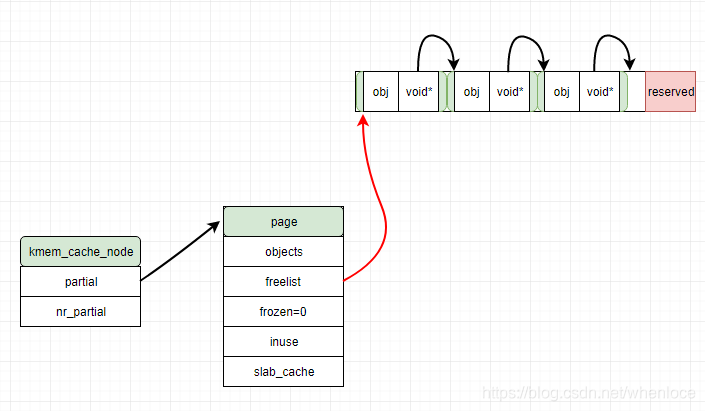
一个slab的简单示意如下:
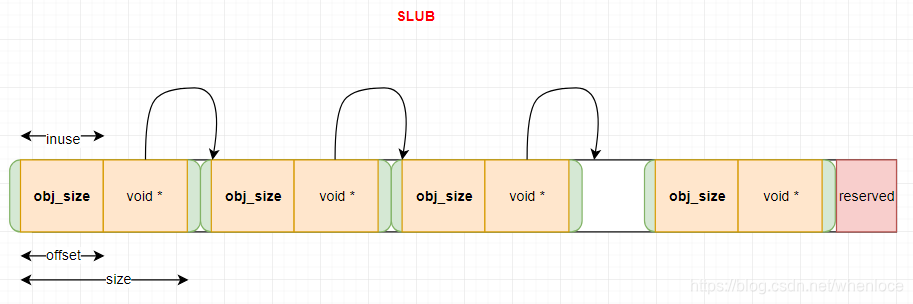
- 一个slab 占用2^order个页面,容纳nr_obj个obj
- slab使用空闲链表组织,空闲指针如上图void*所示(当然也可以使用占用obj的模式)
下面来看一下slab三层缓存的描述:
struct kmem_cache_cpu {void **freelist; /* Pointer to next available object */unsigned long tid; /* Globally unique transaction id */struct page *page; /* The slab from which we are allocating */
};struct kmem_cache_node {spinlock_t list_lock;unsigned long nr_partial;struct list_head partial;
};上述结构的关系如下图所示:
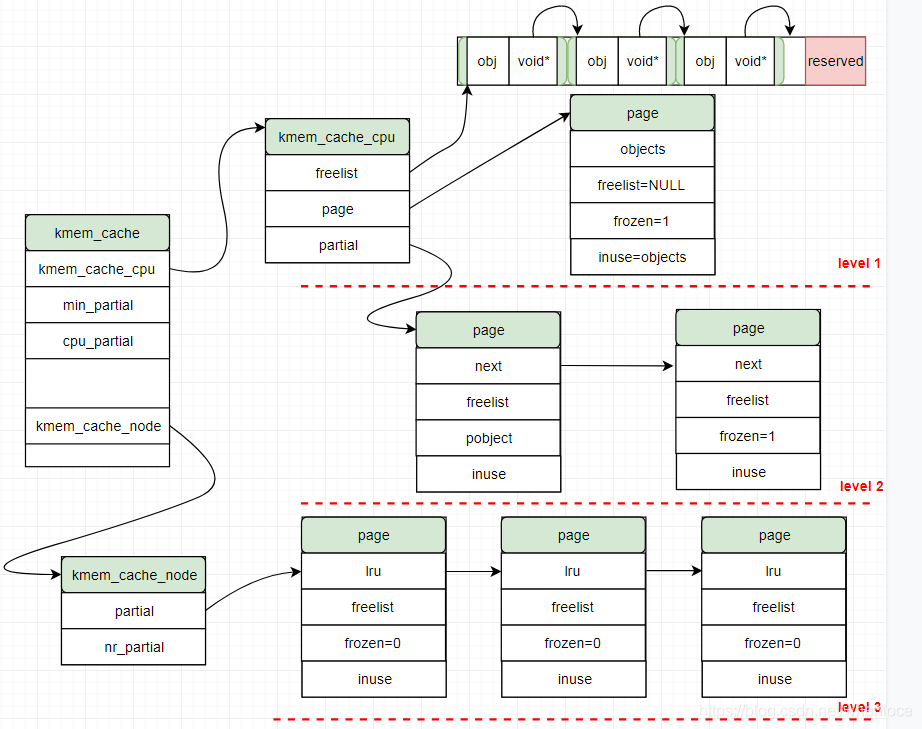
- 各级缓存的门限值分别由cpu_partial, min_partial控制
- kmem_cache_node 是一组:node[MAX_NUMNODES],图中没有画出
2.2 初始化
mm_init->kmem_cache_init
2.2.1 静态建立过程
由于kmem_cache这个管理的slub的结构也要纳入slub的, 其在kmem_cache_init中使用静态构建的bootstrap方式
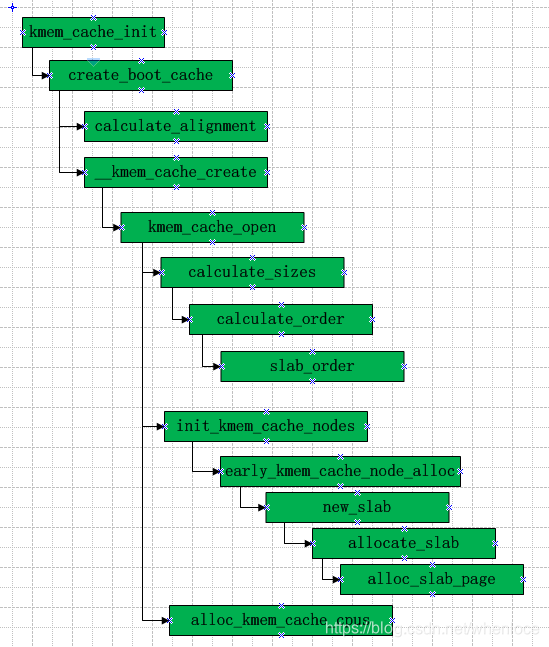
[mm/slub.c]
void __init kmem_cache_init(void)
{static __initdata struct kmem_cache boot_kmem_cache, boot_kmem_cache_node;kmem_cache_node = &boot_kmem_cache_node;kmem_cache = &boot_kmem_cache;create_boot_cache(kmem_cache_node, "kmem_cache_node",sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN, 0, 0);register_hotmemory_notifier(&slab_memory_callback_nb);/* Able to allocate the per node structures */slab_state = PARTIAL;create_boot_cache(kmem_cache, "kmem_cache",offsetof(struct kmem_cache, node) +nr_node_ids * sizeof(struct kmem_cache_node *),SLAB_HWCACHE_ALIGN, 0, 0);kmem_cache = bootstrap(&boot_kmem_cache);kmem_cache_node = bootstrap(&boot_kmem_cache_node);/* Now we can use the kmem_cache to allocate kmalloc slabs */setup_kmalloc_cache_index_table();create_kmalloc_caches(0);/* Setup random freelists for each cache */init_freelist_randomization();cpuhp_setup_state_nocalls(CPUHP_SLUB_DEAD, "slub:dead", NULL,slub_cpu_dead);pr_info("SLUB: HWalign=%d, Order=%u-%u, MinObjects=%u, CPUs=%u, Nodes=%d\n",cache_line_size(),slub_min_order, slub_max_order, slub_min_objects,nr_cpu_ids, nr_node_ids);
}create_boot_cache创建struct kmem_cache_node的kmem_cache,其核心是__kmem_cache_create,在这个过程中slub需要计算几个量,这里展示如下:
unsigned long calculate_alignment(unsigned long flags,unsigned long align, unsigned long size)
{if (flags & SLAB_HWCACHE_ALIGN) {unsigned long ralign = cache_line_size();while (size <= ralign / 2)ralign /= 2;align = max(align, ralign);}if (align < ARCH_SLAB_MINALIGN)align = ARCH_SLAB_MINALIGN;return ALIGN(align, sizeof(void *));
}- calculate_alignment计算slub的对齐属性
- 如果指定了SLAB_HWCACHE_ALIGN,尽可能将obj放入一个cache中,但最终对齐不能小于指定align
- align至少关于word对齐(不能跨越word边界)
static inline int slab_order(int size, int min_objects,int max_order, int fract_leftover, int reserved)
{int order;int rem;int min_order = slub_min_order;if (order_objects(min_order, size, reserved) > MAX_OBJS_PER_PAGE)return get_order(size * MAX_OBJS_PER_PAGE) - 1;for (order = max(min_order, get_order(min_objects * size + reserved));order <= max_order; order++) {unsigned long slab_size = PAGE_SIZE << order;rem = (slab_size - reserved) % size;if (rem <= slab_size / fract_leftover)break;}return order;
}- slab_order 计算需要为指定size的obj分配page的数量(以order表示,范围在[slub_min_order, slub_max_order]
- 需要保证不浪费空间,不超过总空间的 1/ fract_leftover(rem/slab_size <= 1 / fract_leftover)
static inline int calculate_order(int size, int reserved)
{int order;int min_objects;int fraction;int max_objects;min_objects = slub_min_objects;if (!min_objects)min_objects = 4 * (fls(nr_cpu_ids) + 1);max_objects = order_objects(slub_max_order, size, reserved);min_objects = min(min_objects, max_objects);while (min_objects > 1) {fraction = 16;while (fraction >= 4) {order = slab_order(size, min_objects,slub_max_order, fraction, reserved);if (order <= slub_max_order)return order;fraction /= 2;}min_objects--;}order = slab_order(size, 1, slub_max_order, 1, reserved);if (order <= slub_max_order)return order;order = slab_order(size, 1, MAX_ORDER, 1, reserved);if (order < MAX_ORDER)return order;return -ENOSYS;
}
- 在min_objects条件下,合理的order数
- 如果object太大,尝试放开(min_objects=1或者slub_max_order=MAX_ORDER)
static int calculate_sizes(struct kmem_cache *s, int forced_order)
{unsigned long flags = s->flags;size_t size = s->object_size;int order;size = ALIGN(size, sizeof(void *));s->inuse = size;size = ALIGN(size, s->align);s->size = size;if (forced_order >= 0)order = forced_order;elseorder = calculate_order(size, s->reserved);if (order < 0)return 0;s->allocflags = 0;if (order)s->allocflags |= __GFP_COMP;if (s->flags & SLAB_CACHE_DMA)s->allocflags |= GFP_DMA;if (s->flags & SLAB_RECLAIM_ACCOUNT)s->allocflags |= __GFP_RECLAIMABLE;s->oo = oo_make(order, size, s->reserved);s->min = oo_make(get_order(size), size, s->reserved);if (oo_objects(s->oo) > oo_objects(s->max))s->max = s->oo;return !!oo_objects(s->oo);
}- calculate_sizes计算object实际占用的空间,及需要分配page的数量(2^order)
- 主要区分s->object_size,s->inuse,s->size(obj大小,跨word对齐,s->align对齐)
- s->oo记录slub 最终的order和其包含的object数量
static inline int order_objects(int order, unsigned long size, int reserved)
{return ((PAGE_SIZE << order) - reserved) / size;
}static inline struct kmem_cache_order_objects oo_make(int order,unsigned long size, int reserved)
{struct kmem_cache_order_objects x = {(order << OO_SHIFT) + order_objects(order, size, reserved)};return x;
}slub的各指标都确定了,现在可以分配空间了,最终就是在底层调用前面计算的order大小的配置,这里主要关注page的一系列操作。先看一下和slub有关的page的结构:
struct page {unsigned long flags; union {};union { void *freelist; };union { struct {unsigned inuse:16;unsigned objects:15;unsigned frozen:1;};};union {struct { struct page *next; int pages; int pobjects; };}union {struct kmem_cache *slab_cache; };
};- freelist 空闲链表头
- inuse 当前已使用object数量
- objects slub中object总数
- frozen
- slab_cache
kmem_cache未建立起来之前,使用early_kmem_cache_node_alloc分配kmem_cache_node, 重点看一下过程中分配一个slab的过程。
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{page = alloc_slab_page(s, alloc_gfp, node, oo);page->objects = oo_objects(oo);order = compound_order(page);page->slab_cache = s;__SetPageSlab(page);if (page_is_pfmemalloc(page))SetPageSlabPfmemalloc(page);start = page_address(page);shuffle = shuffle_freelist(s, page);if (!shuffle) {for_each_object_idx(p, idx, s, start, page->objects) {setup_object(s, page, p);if (likely(idx < page->objects))set_freepointer(s, p, p + s->size);elseset_freepointer(s, p, NULL);}page->freelist = fixup_red_left(s, start);}page->inuse = page->objects;page->frozen = 1;out:if (gfpflags_allow_blocking(flags))local_irq_disable();if (!page)return NULL;mod_lruvec_page_state(page,(s->flags & SLAB_RECLAIM_ACCOUNT) ?NR_SLAB_RECLAIMABLE : NR_SLAB_UNRECLAIMABLE,1 << oo_order(oo));inc_slabs_node(s, page_to_nid(page), page->objects);return page;
}- alloc_slab_page分配对于order的page
- 设置page的slab属性:__SetPageSlab(page);
- 初始化freelist链表
一个slab分配后如下图所示:

下面来看上述slub结构是如何管理的:
static void early_kmem_cache_node_alloc(int node)
{struct page *page;struct kmem_cache_node *n;page = new_slab(kmem_cache_node, GFP_NOWAIT, node);n = page->freelist;BUG_ON(!n);page->freelist = get_freepointer(kmem_cache_node, n);page->inuse = 1;page->frozen = 0;kmem_cache_node->node[node] = n;init_kmem_cache_node(n);inc_slabs_node(kmem_cache_node, node, page->objects);/** No locks need to be taken here as it has just been* initialized and there is no concurrent access.*/__add_partial(n, page, DEACTIVATE_TO_HEAD);
}- 注意这里是分配struct kmem_cache_node结构,所以kmem_cache_node->node[node] = n; 这句话直接将kmem_cache中的node指向第一个kmem_cache_node
接下来是分配每cpu结构:
static inline int alloc_kmem_cache_cpus(struct kmem_cache *s)
{s->cpu_slab = __alloc_percpu(sizeof(struct kmem_cache_cpu),2 * sizeof(void *));if (!s->cpu_slab)return 0;init_kmem_cache_cpus(s);return 1;
}- 可以看到就是简单的分配并初始化kmem_cache_cpu
至此,静态的"kmem_cache_node"结构就建立了,kmem_cache的状态变为slab_state = PARTIAL,那么接下来的"kmem_cache"的静态分配kmem_cache_node就可以从前面建立的slub中取了!
kmem_cache和kmem_cache_node的kmem_cache就创建完成了,可以调用标准的接口了,所以此时要将kmem_cache和kmem_cache_node纳入标准的kmem_cache管理中,由静态变为动态,先列函数流程:
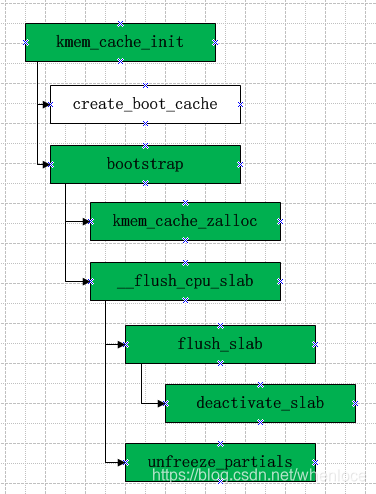
static struct kmem_cache * __init bootstrap(struct kmem_cache *static_cache)
{int node;struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);struct kmem_cache_node *n;memcpy(s, static_cache, kmem_cache->object_size);__flush_cpu_slab(s, smp_processor_id());for_each_kmem_cache_node(s, node, n) {struct page *p;list_for_each_entry(p, &n->partial, lru)p->slab_cache = s;}slab_init_memcg_params(s);list_add(&s->list, &slab_caches);memcg_link_cache(s);return s;
}- 首先分配一个kmem_cache的kmem_cache, 通过memcpy将静态转变为动态的,其中分配kmem_cache_zalloc->kmem_cache_alloc->slab_alloc->slab_alloc_node,我们上面已经分析过了
接下来一路通过__flush_cpu_slab将kmem_cache_cpu flush掉,主要函数是:
static void deactivate_slab(struct kmem_cache *s, struct page *page,void *freelist)
{enum slab_modes { M_NONE, M_PARTIAL, M_FULL, M_FREE };struct kmem_cache_node *n = get_node(s, page_to_nid(page));int lock = 0;enum slab_modes l = M_NONE, m = M_NONE;void *nextfree;int tail = DEACTIVATE_TO_HEAD;struct page new;struct page old;if (page->freelist) {stat(s, DEACTIVATE_REMOTE_FREES);tail = DEACTIVATE_TO_TAIL;}/** Stage one: Free all available per cpu objects back* to the page freelist while it is still frozen. Leave the* last one.** There is no need to take the list->lock because the page* is still frozen.*/while (freelist && (nextfree = get_freepointer(s, freelist))) {void *prior;unsigned long counters;do {prior = page->freelist;counters = page->counters;set_freepointer(s, freelist, prior);new.counters = counters;new.inuse--;VM_BUG_ON(!new.frozen);} while (!__cmpxchg_double_slab(s, page,prior, counters,freelist, new.counters,"drain percpu freelist"));freelist = nextfree;}...
}- 先来看第一阶段,注释写的很明白,将kmem_cache_cpu对应的freelist空闲的obj放入page对应的freelist,最终要剩余一个free的obj,此时frozen=1
下面来看第二阶段:
/** Stage two: Ensure that the page is unfrozen while the* list presence reflects the actual number of objects* during unfreeze.** We setup the list membership and then perform a cmpxchg* with the count. If there is a mismatch then the page* is not unfrozen but the page is on the wrong list.** Then we restart the process which may have to remove* the page from the list that we just put it on again* because the number of objects in the slab may have* changed.*/
redo:old.freelist = page->freelist;old.counters = page->counters;VM_BUG_ON(!old.frozen);/* Determine target state of the slab */new.counters = old.counters;if (freelist) {new.inuse--;set_freepointer(s, freelist, old.freelist);new.freelist = freelist;} elsenew.freelist = old.freelist;new.frozen = 0;if (!new.inuse && n->nr_partial >= s->min_partial)m = M_FREE;else if (new.freelist) {m = M_PARTIAL;if (!lock) {lock = 1;/** Taking the spinlock removes the possiblity* that acquire_slab() will see a slab page that* is frozen*/spin_lock(&n->list_lock);}} else {m = M_FULL;if (kmem_cache_debug(s) && !lock) {lock = 1;/** This also ensures that the scanning of full* slabs from diagnostic functions will not see* any frozen slabs.*/spin_lock(&n->list_lock);}}if (l != m) {if (l == M_PARTIAL)remove_partial(n, page);else if (l == M_FULL)remove_full(s, n, page);if (m == M_PARTIAL) {add_partial(n, page, tail);stat(s, tail);} else if (m == M_FULL) {stat(s, DEACTIVATE_FULL);add_full(s, n, page);}}l = m;if (!__cmpxchg_double_slab(s, page,old.freelist, old.counters,new.freelist, new.counters,"unfreezing slab"))goto redo;if (lock)spin_unlock(&n->list_lock);if (m == M_FREE) {stat(s, DEACTIVATE_EMPTY);discard_slab(s, page);stat(s, FREE_SLAB);}2.3 API
- struct kmem_cache * kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *))
- void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)
- void kmem_cache_free(struct kmem_cache *s, void *x)
- void *kmalloc(size_t size, gfp_t flags)
- void kfree(const void *x)
2.3.1 kmem_cache_create
先来看kmem_cache_create,这个函数调用create_cache->__kmem_cache_create,该流程和上面的流程是一致的,不同的地方体现在init_kmem_cache_nodes会调用kmem_cache_alloc_node:
static int init_kmem_cache_nodes(struct kmem_cache *s)
{int node;for_each_node_state(node, N_NORMAL_MEMORY) {struct kmem_cache_node *n;if (slab_state == DOWN) {early_kmem_cache_node_alloc(node);continue;}n = kmem_cache_alloc_node(kmem_cache_node,GFP_KERNEL, node);...
}其流程如下:
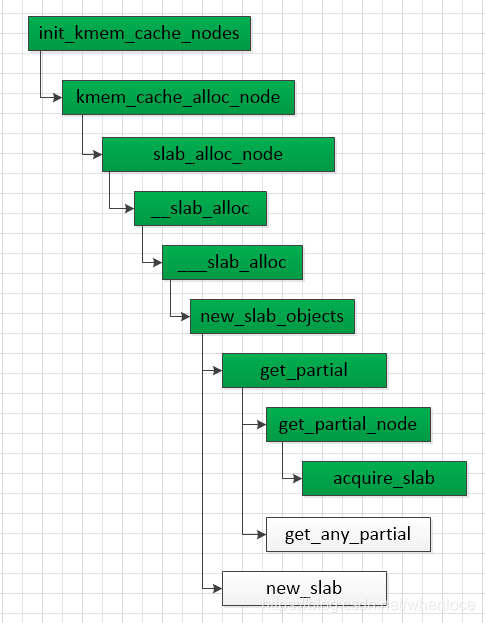
上述过程和kmem_cache_alloc是一致的,放到下面分析.
2.3.2 kmem_cache_alloc
kmem_cache_alloc申请过程中各级缓存的形态如下图:
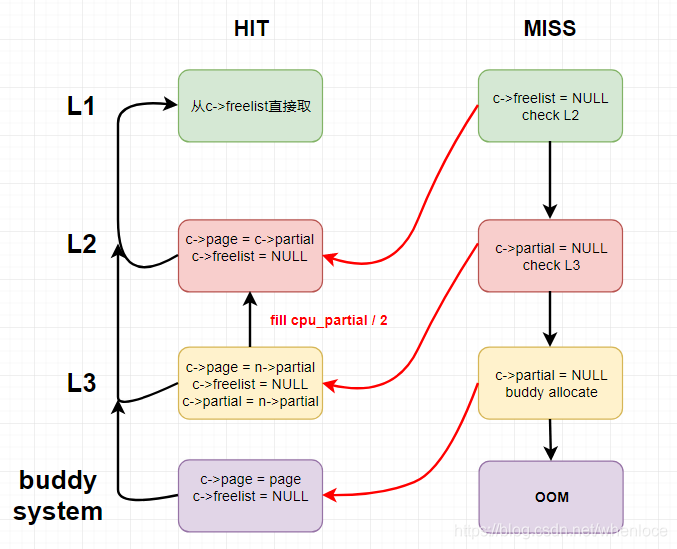
先说明一下分配的时候的流程:
- L1 HIT, 即命中本地kmem_cache_cpu(c->freelist != NULL),直接从freelist头取一个,所谓fastpath
- L1 MISS, L2 HIT(c->partial != NULL),在L2中取一个slab挂到L1(c->page)上
- L1 MISS, L2 MISS, L3 HIT(n->partial != NULL),在L3中取一个slab挂到L1(c->page)上,并取数量为cpu_partial / 2为上限个obj挂到L2(c->partial)上
- L1 MISS, L2 MISS, L3 MISS,在伙伴系统中分配一个slab挂到L1(c->page)上
- 伙伴系统也分配失败,OOM
下面结合上面的步骤分析一下kmem_cache_alloc流程:kmem_cache_alloc->slab_alloc->slab_alloc_node
static __always_inline void *slab_alloc_node(struct kmem_cache *s,gfp_t gfpflags, int node, unsigned long addr)
{void *object;struct kmem_cache_cpu *c;struct page *page;unsigned long tid;s = slab_pre_alloc_hook(s, gfpflags);if (!s)return NULL;
redo:do {tid = this_cpu_read(s->cpu_slab->tid);c = raw_cpu_ptr(s->cpu_slab);} while (IS_ENABLED(CONFIG_PREEMPT) &&unlikely(tid != READ_ONCE(c->tid)));barrier();object = c->freelist;page = c->page;if (unlikely(!object || !node_match(page, node))) {object = __slab_alloc(s, gfpflags, node, addr, c);stat(s, ALLOC_SLOWPATH);} else {void *next_object = get_freepointer_safe(s, object);if (unlikely(!this_cpu_cmpxchg_double(s->cpu_slab->freelist, s->cpu_slab->tid,object, tid,next_object, next_tid(tid)))) {note_cmpxchg_failure("slab_alloc", s, tid);goto redo;}prefetch_freepointer(s, next_object);stat(s, ALLOC_FASTPATH);}return object;
}
先看本地cache不为空的情况( c->freelist),即所谓fastpath操作,其实就是一个原子操作,移动freelist指针。
下面看一下slowpath的情况:
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,unsigned long addr, struct kmem_cache_cpu *c)
{void *freelist;struct page *page;page = c->page;if (!page)goto new_slab;...
load_freelist:/** freelist is pointing to the list of objects to be used.* page is pointing to the page from which the objects are obtained.* That page must be frozen for per cpu allocations to work.*/VM_BUG_ON(!c->page->frozen);c->freelist = get_freepointer(s, freelist);c->tid = next_tid(c->tid);return freelist;new_slab:if (slub_percpu_partial(c)) {page = c->page = slub_percpu_partial(c);slub_set_percpu_partial(c, page);stat(s, CPU_PARTIAL_ALLOC);goto redo;}freelist = new_slab_objects(s, gfpflags, node, &c);if (unlikely(!freelist)) {slab_out_of_memory(s, gfpflags, node);return NULL;}page = c->page;if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))goto load_freelist;
}- c->page为空,说明本地缓存为空,执行new_slab_objects,改函数首先尝试从kmem_cache_node对应的partial链表上去寻找合适的slub,对应get_partial函数,参照上图,这里分析一下acquire_slab
如果cpu partial为空,那么考虑kmem_cache_node,对应new_slab_objects->get_partial
static void *get_partial(struct kmem_cache *s, gfp_t flags, int node,struct kmem_cache_cpu *c)
{void *object;int searchnode = node;if (node == NUMA_NO_NODE)searchnode = numa_mem_id();else if (!node_present_pages(node))searchnode = node_to_mem_node(node);object = get_partial_node(s, get_node(s, searchnode), c, flags);if (object || node != NUMA_NO_NODE)return object;return get_any_partial(s, flags, c);
}- get_partial先从kmem_cache_node的searchnode的partial链表,如果不满足,按照distance去其他node对应的partial链表中获取。
先来看get_partial_node
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,struct kmem_cache_cpu *c, gfp_t flags)
{struct page *page, *page2;void *object = NULL;int available = 0;int objects;if (!n || !n->nr_partial)return NULL;spin_lock(&n->list_lock);list_for_each_entry_safe(page, page2, &n->partial, lru) {void *t;if (!pfmemalloc_match(page, flags))continue;t = acquire_slab(s, n, page, object == NULL, &objects);if (!t)break;available += objects;if (!object) {c->page = page;stat(s, ALLOC_FROM_PARTIAL);object = t;} else {put_cpu_partial(s, page, 0);stat(s, CPU_PARTIAL_NODE);}if (!kmem_cache_has_cpu_partial(s)|| available > s->cpu_partial / 2)break;}spin_unlock(&n->list_lock);return object;
}get_partial_node描述了kmem_cache_node层次命中后的操作,可以看到主要是:
- 变量partial,acquire_slab获取partial链表上slab空闲的数量,对于第一个获取到的slab,挂到c->page上,即L1 上
- 然后将后续slab挂到c->partial,即L2上,直到满足其数量大于cpu_partial的一半
static inline void *acquire_slab(struct kmem_cache *s,struct kmem_cache_node *n, struct page *page,int mode, int *objects)
{void *freelist;unsigned long counters;struct page new;freelist = page->freelist;counters = page->counters;new.counters = counters;*objects = new.objects - new.inuse;if (mode) {new.inuse = page->objects;new.freelist = NULL;} else {new.freelist = freelist;}VM_BUG_ON(new.frozen);new.frozen = 1;if (!__cmpxchg_double_slab(s, page,freelist, counters,new.freelist, new.counters,"acquire_slab"))return NULL;remove_partial(n, page);return freelist;
}- acquire_slab 主要的操作就是将slub从kmem_cache_node的partial链摘除,这里注意,第一次获取的slab是挂在L1上的,所以要:
new.inuse = page->objects;new.freelist = NULL;- remove_partial 对应摘链动作
如果L3 miss了,会执行new_slab从伙伴系统中分配:
page = new_slab(s, flags, node);if (page) {c = raw_cpu_ptr(s->cpu_slab);if (c->page)flush_slab(s, c);/** No other reference to the page yet so we can* muck around with it freely without cmpxchg*/freelist = page->freelist;page->freelist = NULL;stat(s, ALLOC_SLAB);c->page = page;*pc = c;} elsefreelist = NULL;将申请到的slab,挂在L1上,相应的字段处理一下就好了,具体参照文章开始的框图。如果伙伴系统也失败了,只能OOM了。
综上,如果L1 miss,L2,L3,乃至从伙伴系统找到一个新的slab都要保证下面的状态:
page->freelist = NULL;
c->page = page;这个很容易理解,一个slab不完全是free的,因此freelist指向也是不确定的。最终在下面
load_freelist:
VM_BUG_ON(!c->page->frozen);
c->freelist = get_freepointer(s, freelist); //这里跳过第一个元素,慢速路径返回原freelist就能直接使用了
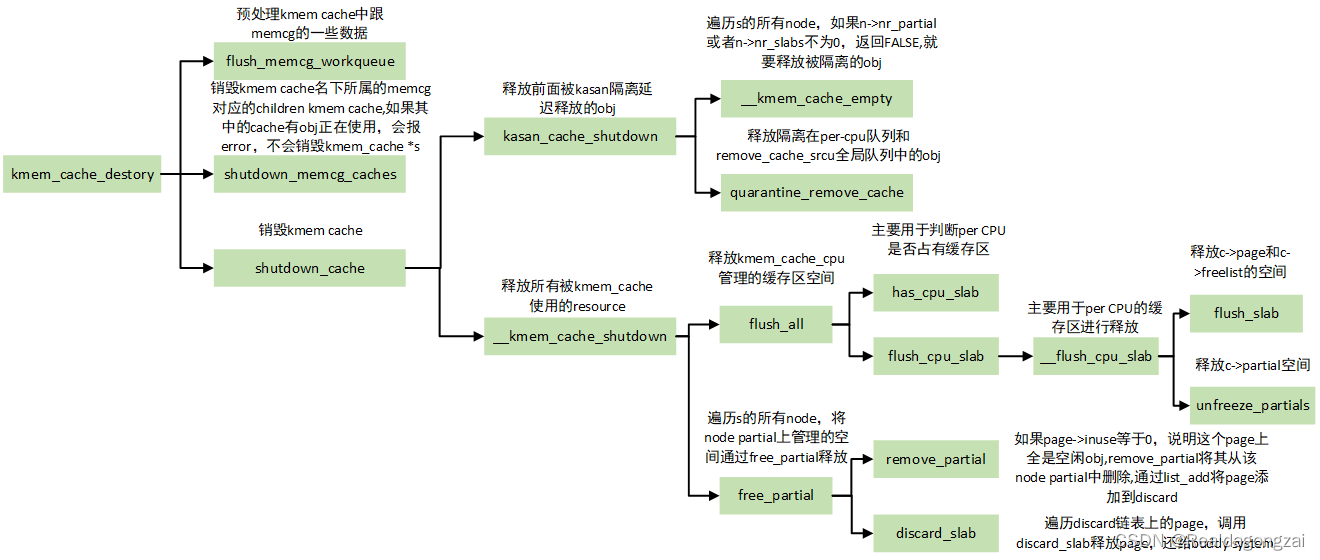
2.3.3 kmem_cache_free
下面分析kmem_cache_free,其函数调用流程大体如下:
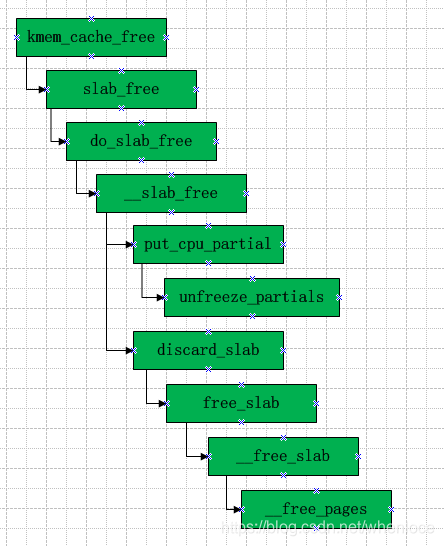
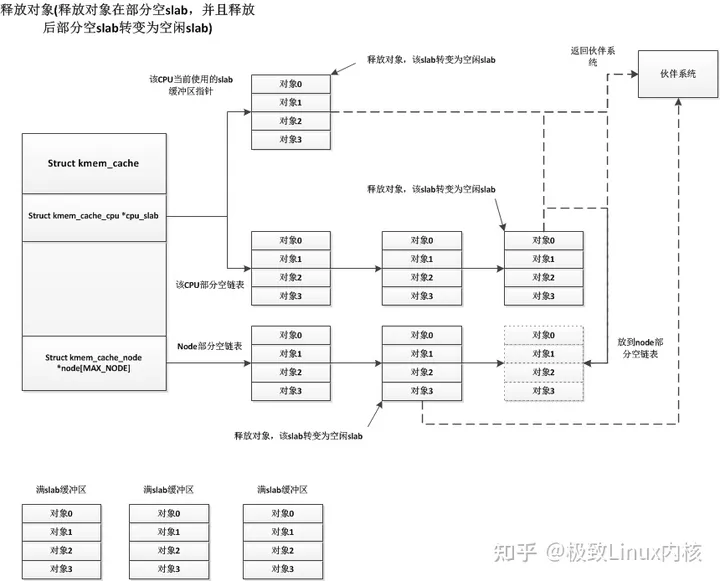
释放的流程,可以参照下图,来自【2】
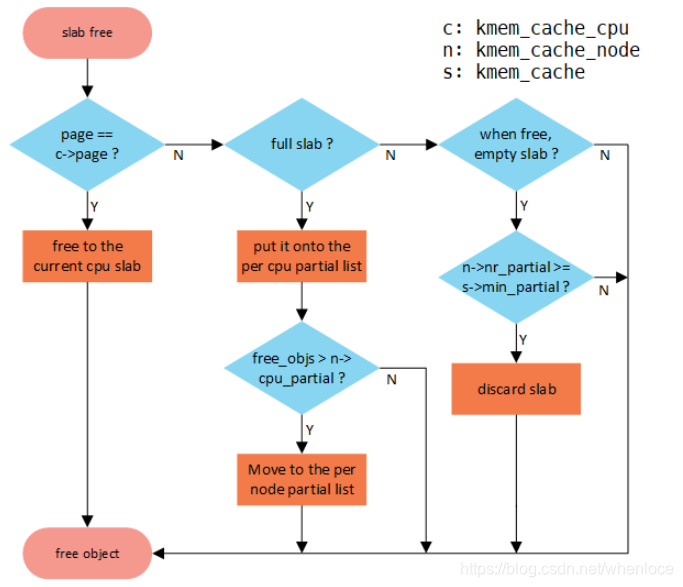
- 如果slab所在L1, L2, L3 中直接释放
- 如果slab是full,加入L2(cpu partial)链表中,这种情况下要检查L2 obj总数是否超过cpu_partial,如果超过,将L2移动到L3。
- 如果释放obj后slab变成empty且在L3中,如果slab数量nr_partial > min_partial,考虑将slab回收到伙伴系统中。
分段来看__slab_free:
static void __slab_free(struct kmem_cache *s, struct page *page,void *head, void *tail, int cnt, unsigned long addr)
{void *prior;int was_frozen;struct page new;unsigned long counters;struct kmem_cache_node *n = NULL;unsigned long uninitialized_var(flags);stat(s, FREE_SLOWPATH);do {if (unlikely(n)) {spin_unlock_irqrestore(&n->list_lock, flags);n = NULL;}prior = page->freelist;counters = page->counters;set_freepointer(s, tail, prior);new.counters = counters;was_frozen = new.frozen;new.inuse -= cnt;if ((!new.inuse || !prior) && !was_frozen) {if (kmem_cache_has_cpu_partial(s) && !prior) {new.frozen = 1;} else { /* Needs to be taken off a list */n = get_node(s, page_to_nid(page));spin_lock_irqsave(&n->list_lock, flags);}}} while (!cmpxchg_double_slab(s, page,prior, counters,head, new.counters,"__slab_free"));如果page不在kmem_cache_cpu中,有以下几种情况:
- 在cpu partial链表中,此时frozen=1
- slab是满的(page->freelist == NULL),不在任何链表中,此时frozen=0
- 在node partial中,此时frozen=0
上面代码片段就是将obj释放到对应的slab中,需要考虑下面的情况:
- 如果slab是满的(!prior),因为没有在任何链表中,需要将其加入cpu partial中,因此将frozen=1
- 如果slab在node partial链表中,释放n个obj之后为slab变空,需要选择一个node
如果是上述情况1,即在full slab释放n个obj,那么将该slab放入cpu partial中,使用put_cpu_partial,即要考虑是否超过空闲门限cpu_partial:
if (likely(!n)) {/** If we just froze the page then put it onto the* per cpu partial list.*/if (new.frozen && !was_frozen) {put_cpu_partial(s, page, 1);stat(s, CPU_PARTIAL_FREE);}/** The list lock was not taken therefore no list* activity can be necessary.*/if (was_frozen)stat(s, FREE_FROZEN);return;}如果是情况2,需要判断空slab以及是否超过L3门限min_partial而将其释放给buddy allcator,根据slab情况将其从node partial移除,接着使用discard_slab释放:
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))goto slab_empty;slab_empty:if (prior) {/** Slab on the partial list.*/remove_partial(n, page);stat(s, FREE_REMOVE_PARTIAL);} else {/* Slab must be on the full list */remove_full(s, n, page);}spin_unlock_irqrestore(&n->list_lock, flags);stat(s, FREE_SLAB);discard_slab(s, page);2.3.4 kmalloc/kfree
kmalloc基于kmem_cache,下面的函数建立各个长度的slab,存储在kmalloc_caches中。
void __init create_kmalloc_caches(unsigned long flags)
{int i;for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {if (!kmalloc_caches[i])new_kmalloc_cache(i, flags);/** Caches that are not of the two-to-the-power-of size.* These have to be created immediately after the* earlier power of two caches*/if (KMALLOC_MIN_SIZE <= 32 && !kmalloc_caches[1] && i == 6)new_kmalloc_cache(1, flags);if (KMALLOC_MIN_SIZE <= 64 && !kmalloc_caches[2] && i == 7)new_kmalloc_cache(2, flags);}/* Kmalloc array is now usable */slab_state = UP;#ifdef CONFIG_ZONE_DMAfor (i = 0; i <= KMALLOC_SHIFT_HIGH; i++) {struct kmem_cache *s = kmalloc_caches[i];if (s) {int size = kmalloc_size(i);char *n = kasprintf(GFP_NOWAIT,"dma-kmalloc-%d", size);BUG_ON(!n);kmalloc_dma_caches[i] = create_kmalloc_cache(n,size, SLAB_CACHE_DMA | flags);}}
#endif
}在我的机器上KMALLOC_SHIFT_LOW是3, KMALLOC_SHIFT_HIGH是13,而kmalloc_info如下:
const struct kmalloc_info_struct kmalloc_info[] __initconst = {{NULL, 0}, {"kmalloc-96", 96},{"kmalloc-192", 192}, {"kmalloc-8", 8},{"kmalloc-16", 16}, {"kmalloc-32", 32},{"kmalloc-64", 64}, {"kmalloc-128", 128},{"kmalloc-256", 256}, {"kmalloc-512", 512},{"kmalloc-1024", 1024}, {"kmalloc-2048", 2048},{"kmalloc-4096", 4096}, {"kmalloc-8192", 8192},{"kmalloc-16384", 16384}, {"kmalloc-32768", 32768},{"kmalloc-65536", 65536}, {"kmalloc-131072", 131072},{"kmalloc-262144", 262144}, {"kmalloc-524288", 524288},{"kmalloc-1048576", 1048576}, {"kmalloc-2097152", 2097152},{"kmalloc-4194304", 4194304}, {"kmalloc-8388608", 8388608},{"kmalloc-16777216", 16777216}, {"kmalloc-33554432", 33554432},{"kmalloc-67108864", 67108864}
};可见上述创建了表中kmalloc-8~kmalloc-8192,dma-kmalloc-8~dma-kmalloc-8192的slab
顺便看一下kmalloc
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{if (__builtin_constant_p(size)) {if (size > KMALLOC_MAX_CACHE_SIZE)return kmalloc_large(size, flags);
#ifndef CONFIG_SLOBif (!(flags & GFP_DMA)) {int index = kmalloc_index(size);if (!index)return ZERO_SIZE_PTR;return kmem_cache_alloc_trace(kmalloc_caches[index],flags, size);}
#endif}return __kmalloc(size, flags);
}- size 大于8192(4K),使用伙伴系统分配kmalloc_large
- 没有指定GFP_DMA标志,使用kmalloc_index(size)寻找size对应kmalloc_caches中的下标
kfree涉及到的函数上面也都分析过了,略过。
三、参考
【1】多核心Linux内核路径优化的不二法门之-slab与伙伴系统
【2】图解slub