前言
在Linux中,伙伴系统(buddy system)是以页(1page等于4K)为单位管理和分配内存。对于小内存的分配,如果还是使用伙伴系统进行内存分配,就会导致严重浪费内存。此时,slab分配器就应运而生了,专为小内存分配而生。slab分配器分配内存以Byte为单位。但是slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步细分成小内存分配。
说明:slub是slab中的一种,slab也是slab中的一种。有时候用slab来统称slab, slub和slob。slab, slub和slob仅仅是分配内存策略不同,内存管理基本一致。本篇文章中说的是slub分配器工作的原理。但是针对分配器管理的内存,下文统称为slab缓存池。所以文章中slub和slab会混用,表示同一个意思。
注:文章代码分析基于linux-4.19
一、SLUB数据结构
现在假如从buddy system分配1个page内存供slub分配器管理。对于slub分配器来说,会将这段连续内存平均分成size相等的object(对象)进行管理。此时就需要一个数据结构管理。那就是struct kmem_cache。kmem_cache数据结构描述如下,include/linux/slub_def.h:
1.1 kmem_cache
/** Slab cache management.*/
struct kmem_cache {struct kmem_cache_cpu __percpu *cpu_slab;/* Used for retriving partial slabs etc */slab_flags_t flags;unsigned long min_partial;unsigned int size; /* The size of an object including meta data */unsigned int object_size;/* The size of an object without meta data */unsigned int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL/* Number of per cpu partial objects to keep around */unsigned int cpu_partial;
#endifstruct kmem_cache_order_objects oo;/* Allocation and freeing of slabs */struct kmem_cache_order_objects max;struct kmem_cache_order_objects min;gfp_t allocflags; /* gfp flags to use on each alloc */int refcount; /* Refcount for slab cache destroy */void (*ctor)(void *);//创建slab的构造函数unsigned int inuse; /* Offset to metadata */unsigned int align; /* Alignment */unsigned int red_left_pad; /* Left redzone padding size */const char *name; /* Name (only for display!) */struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFSstruct kobject kobj; /* For sysfs */struct work_struct kobj_remove_work;
#endif
#ifdef CONFIG_MEMCGstruct memcg_cache_params memcg_params;/* for propagation, maximum size of a stored attr */unsigned int max_attr_size;
#ifdef CONFIG_SYSFSstruct kset *memcg_kset;
#endif
#endif#ifdef CONFIG_SLAB_FREELIST_HARDENEDunsigned long random;
#endif#ifdef CONFIG_NUMA/** Defragmentation by allocating from a remote node.*/unsigned int remote_node_defrag_ratio;
#endif#ifdef CONFIG_SLAB_FREELIST_RANDOMunsigned int *random_seq;
#endif#ifdef CONFIG_KASANstruct kasan_cache kasan_info;
#endifunsigned int useroffset; /* Usercopy region offset */unsigned int usersize; /* Usercopy region size */struct kmem_cache_node *node[MAX_NUMNODES];
};1) cpu_slab:一个per cpu变量,每个cpu都有一个这个变量,相当于一个本地内存缓存池。当分配内存的时候优先从本地内存缓存池分配内存以保证cache的命中率。
2) flags:object分配掩码,例如经常使用的SLAB_HWCACHE_ALIGN标志位,代表创建的kmem_cache管理的object按照硬件cache 对齐,一切都是为了速度。
3) min_partial:限制struct kmem_cache_node中的partial链表slab的数量。虽说是mini_partial,但通过看代码,实际上这个变量是kmem_cache_node中partial链表最大slab数量,如果大于这个mini_partial的值,那么多余的slab就会被释放。(mm/slub.c unfreeze_partials函数里面有,确实如此)
4) size:分配的object size
5) object_size:实际的object size,就是创建kmem_cache时候传递进来的参数。和size的关系就是,size是各种地址对齐之后的大小。因此,size要大于等于object_size。
6) offset:slub分配在管理object的时候采用的方法是:既然每个object在没有分配之前不在乎每个object中存储的内容,那么完全可以在每个object中存储下一个object内存首地址,就形成了一个单链表。这个地址数据存储在object前8个字节里面,指针内置法,这个一般是未开启slub debug情况。如果开启slub debug,就是指针外置法,不是每个object中存储下一个object内存首地址。看Slub Debug原理里面的object layout就可以发现。offset就是存储下个object地址相对于这个object首地址的偏移,对应Free pointer(FP)。
7) cpu_partial:cpu partial中所有slab的free object的数量的最大值,超过这个值就会将所有的slab转移到kmem_cache_node的partial链表。
8) oo:低16位代表一个slub 分配器管理的所有object的数量(oo & ((1 << 16) - 1)),高16位代表slub分配器管理的page数量((2^(oo>>16)) pages),order值。
9) max:看了代码好像就是等于oo。
10) min:当按照oo大小分配内存的时候出现内存不足就会考虑min大小方式分配。min只需要可以容纳一个object即可。
11) allocflags:从伙伴系统分配内存的掩码 gfp flag 。
12) inuse:object_size按照word对齐之后的大小。
13) align:字节对齐大小。
14) red_left_pad:left readzone padding的大小
15) name:sysfs文件系统显示使用,slab缓冲区的名字。
16) list:系统有一个全局slab_caches链表,所有的slab都会挂入此链表。
17) node:slab节点。在NUMA系统中,每个node都是struct kmem_cache_node数据结构类型指针。
18)Refcount:引用计数,当前slab缓存每被引用一次就+1,当销毁时-1,如果减1后等于0,则直接销毁这个slab缓存
1.2 kmem_cache_cpu
struct kmem_cache_cpu是对本地内存缓存池的描述,管理每个CPU的slab页面,每一个cpu对应一个结构体。其数据结构如下:
struct kmem_cache_cpu {void **freelist; /* Pointer to next available object */unsigned long tid; /* Globally unique transaction id */struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIALstruct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATSunsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};1) freelist:指向下一个可用的object。
2) tid:一个神奇的数字,主要用来同步作用的。
3) page:指向slab缓存的page指针,这个slab的来源的page。
4) partial:本地slab partial链表。主要是一些部分使用object的slab。
5)stat[NR_SLUB_STAT_ITEMS]:记录对slub操作的状态变化,通过这个stat可以大概知道object从申请到释放经历了哪些步骤
1.3 kmem_cahce_node
slab节点描述,使用slub分配器,成员变量要很多,比使用slab分配器要简洁
/** The slab lists for all objects.*/
struct kmem_cache_node {spinlock_t list_lock;#ifdef CONFIG_SLABstruct list_head slabs_partial; /* partial list first, better asm code */struct list_head slabs_full;struct list_head slabs_free;unsigned long total_slabs; /* length of all slab lists */unsigned long free_slabs; /* length of free slab list only */unsigned long free_objects;unsigned int free_limit;unsigned int colour_next; /* Per-node cache coloring */struct array_cache *shared; /* shared per node */struct alien_cache **alien; /* on other nodes */unsigned long next_reap; /* updated without locking */int free_touched; /* updated without locking */
#endif#ifdef CONFIG_SLUBunsigned long nr_partial;struct list_head partial;
#ifdef CONFIG_SLUB_DEBUGatomic_long_t nr_slabs;atomic_long_t total_objects;struct list_head full;
#endif
#endif};1) list_lock:自旋锁,保护数据。
2) nr_partial:Node中部分空闲slab的数量。
3) partial:slab Node的slab partial链表,链表上的有部分空闲的slab object,和struct kmem_cache_cpu的partial链表功能类似。
4) nr_slabs:Node所有slab的数量。
5) total_objects:Node所有slab的所有object数量。
6) full:slab Node的slab full链表,链表上都是obj全部分配出去的的slab,使能了slub debug才有
对于struct page,代码在include/linux/mm_types.h
1.4 slub接口
除去系统启动阶段,slub内存管理的初始化函数kmem_cache_init(),slub主要有如下4个接口函数。后面会有4篇文章单独详细介绍,SLUB内存管理的4个主要接口函数介绍(1)~(4)。
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *);
void *kmem_cache_alloc(struct kmem_cache *cachep, int flags);
void kmem_cache_free(struct kmem_cache *cachep, void *objp);1) kmem_cache_create是创建kmem_cache数据结构,参数描述:name:kmem_cache的名称;size :slab管理对象(object)的大小;align:slab分配器分配内存的对齐字节数(以align字节对齐);flags:分配内存掩码;ctor :分配对象的构造回调函数
2) kmem_cache_destroy作用和kmem_cache_create相反,就是销毁创建的kmem_cache。
3) kmem_cache_alloc是从cachep参数指定的kmem_cache管理的slab缓存池中分配一个对象,其中flags是分配掩码,标志位用GFP_KERNEL比较多
4) kmem_cache_free是kmem_cache_alloc的反操作
如何使用slub分配器提供的接口,大概包括如下几步:
1) kmem_cache_create创建一个kmem_cache数据结构slab缓存池。
2) 使用kmem_cache_alloc接口从slab缓存池中选一个空闲object。
3) kmem_cache_free释放alloc选中的objects。
4) kmem_cache_destroy释放整个缓存池
如下是个demo
void slab_demo(void)
{struct kmem_cache *kmem_cache_16 = kmem_cache_create("kmem_cache_16", 16, 8, ARCH_KMALLOC_FLAGS, NULL);// now you can alloc memory, the buf points to 16 bytes of memorychar *buf = kmeme_cache_alloc(kmem_cache_16, GFP_KERNEL);// do something what you what, don't forget to release the memory after usekmem_cache_free(kmem_cache_16, buf);kmem_cache_destroy(kmem_cache_16);
}1) 首先使用kmem_cache_create创建名称为kmem_cache_16的kmem_cache数据结构,用于管理objs,其实就是slab的布局。每个obj都是16B,且分配的对象地址按照8B对齐,也就是说从kmem_cache_16中分配的对象大小全是16B。当然,kmem_cache_create仅仅是创建了一个描述slab缓存池布局的数据结构,并没有从伙伴系统申请内存,具体的申请内存操作是在kmeme_cache_alloc中完成的。
2) kmeme_cache_alloc从kmem_cache_16分配一个16B obj。
3) 内存使用结束后,调用kmem_cache_free释放这个16B的obj
4) 如果不需要这个kmem_cache的话,就可以调用kmem_cache_destroy进行销毁。在释放kmem_cache之前要保证从该kmem_cache中分配的对象全部释放了,否则无法释放kmem_cache。
二、SLUB数据结构之间的关系
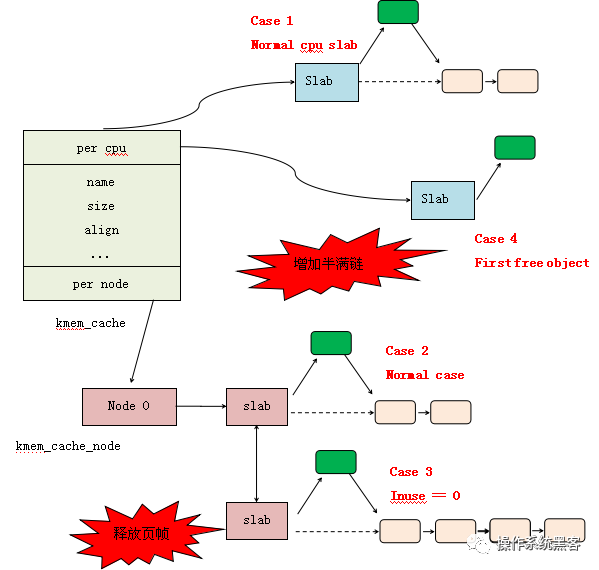
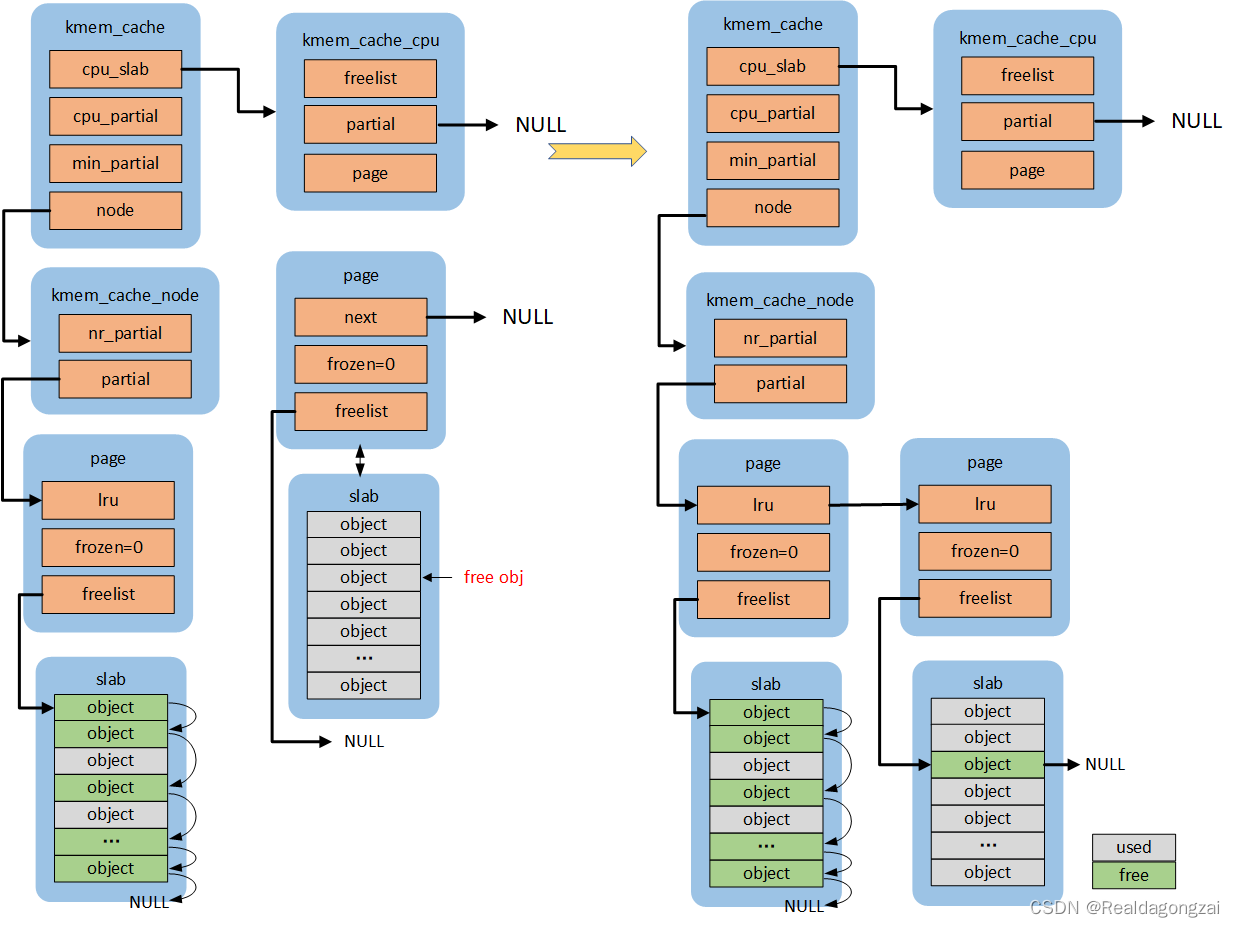
什么是slab缓存池呢?可以将使用struct kmem_cache结构描述的一段内存称作一个slab缓存池。一个slab缓存池就像是一箱牛奶,一箱牛奶中有很多瓶牛奶,每瓶牛奶就是一个object。分配内存的时候,就相当于从牛奶箱中拿一瓶。总有拿完的一天。当箱子空的时候,你就需要去超市再买一箱回来。超市就相当于partial链表,超市存储着很多箱牛奶。如果超市也卖完了,自然就要从厂家进货,然后出售给你。厂家就相当于伙伴系统。这里直接使用图解slub的框图介绍,非常经典的一张流程图,非常感谢作者。
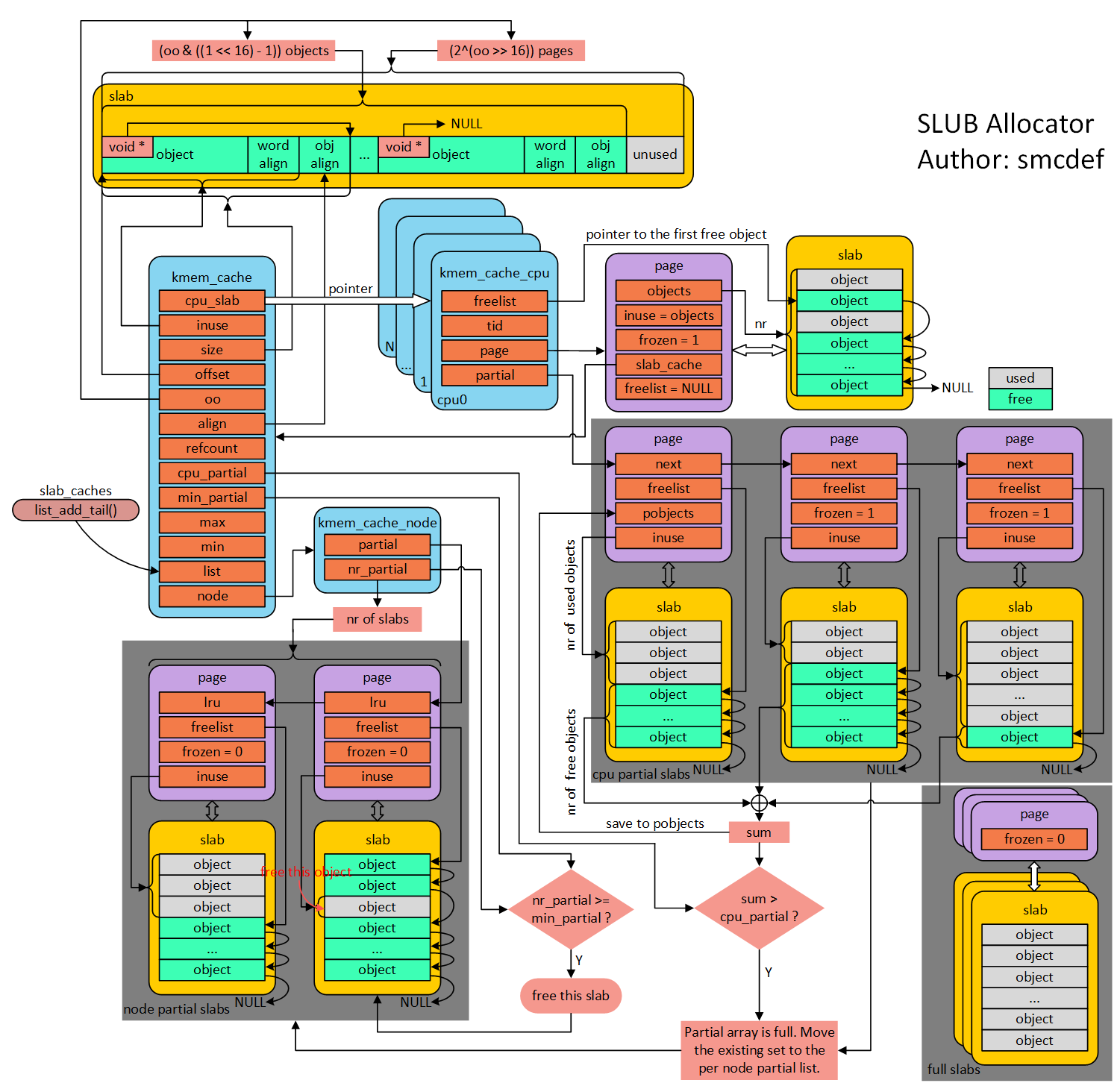
2.1 slub管理object方法
在图片的左上角就是一个slab缓存池中object的分布以及数据结构和kmem_cache之间的关系。首先一个slab缓存池包含的页数是由oo决定的。oo拆分为两部分,低16位代表一个slab缓存池中object的数量,高16位代表包含的页数。使用kmem_cache_create()接口创建kmem_cache的时候需要指出obj的size和对齐align。kmem_cache_create()主要是填充kmem_cache结构体成员。既然从伙伴系统得到(2^(oo >> 16)) pages大小内存,按照size大小进行平分。一般来说都不会整除,因此剩下的就是图中灰色所示(unused)。由于每一个object的大小至少8字节,当然可以用来存储下一个object的首地址。就像图中所示的,形成单链表。图中所示下个obj地址存放的位置位于每个obj首地址处,在内核中称作指针内置式。同时,下个obj地址存放的位置和obj首地址之间的偏移存储在kmem_cache的offset成员。另外一种方式是指针外置式,即下个obj的首地址存储的位置位于obj尾部,也就是在obj尾部再分配sizeof(void *)字节大小的内存。对于外置式则offset就等于kmem_cache的inuse成员。开启slub debug后会是内置式。
2.2 per cpu freelist
针对每一个cpu都会分配一个struct kmem_cache_cpu的结构体。可以称作是本地内存缓存池。当内存申请的时候,优先从本地cpu缓存池申请。在分配初期,本地缓存池为空,需要从伙伴系统分配一定页数的内存。内核会为物理页帧创建一个struct page的结构体。kmem_cache_cpu中page就会指向正在使用的slab的页帧。freelist成员指向第一个空闲可用obj首地址。处于正在使用的slab的struct page结构体中的freelist会置成NULL。struct page结构体中inuse代表已经使用的obj数量。这地方有个很有意思的点,在分配初期从伙伴系统得到内存开始初始化slab时会将inuse置成obj的总数,后面会刷新它。对于full slab就像图的右下角,就像无人看管的孩子,没有任何链表来管理,如果开启了slub debug,在node pratial中会有full链表来管理它们。
2.3 per cpu partial
当图中右下角full slab释放obj的时候,首先就会将slab挂入per cpu partial链表管理。通过struct page中next成员形成单链表。per cpu partial链表指向的第一个page中会存放一些特殊的数据。例如:pobjects存储着per cpu partial链表中所有slab可供分配obj的总数,如图所示。当然还有一个图中没有体现的pages成员存储per cpu partial链表中所有slab的个数。pobjects到底有什么用呢?我们从释放obj,如果要往per cpu partial中添加,不是无限制添加的。因此,每次添加的时候都会判断当前的pobjects是否大于kmem_cache的cpu_partial成员,如果大于,那么就会将此时per cpu partial链表中所有的slab移送到kmem_cache_node的partial链表,然后再将刚刚释放obj的slab插入到per cpu partial链表。如果不大于,则更新pobjects和pages成员,并将slab插入到per cpu partial链表的头部(之所以放头部是提高cache的命中率,减少data load进cpu时间)。frozen等于1表示该slab在kmem_cache_cpu中;等于0,表示该slab在kmem_cach_node中。
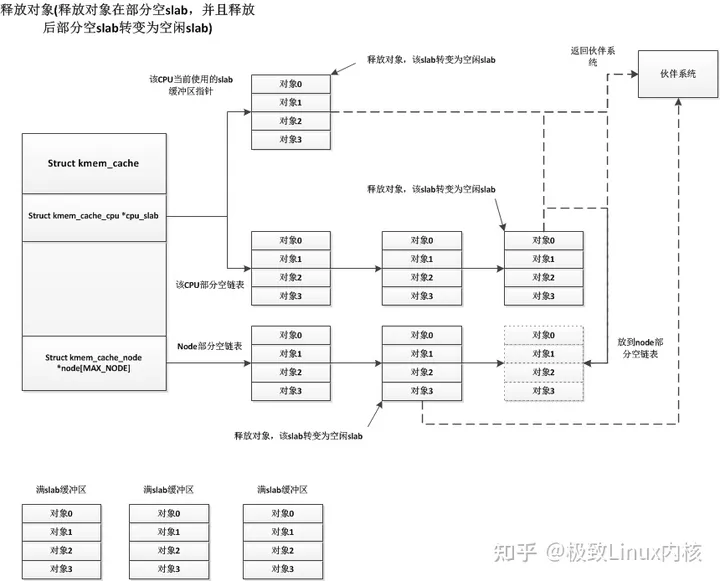
2.4 per node partial
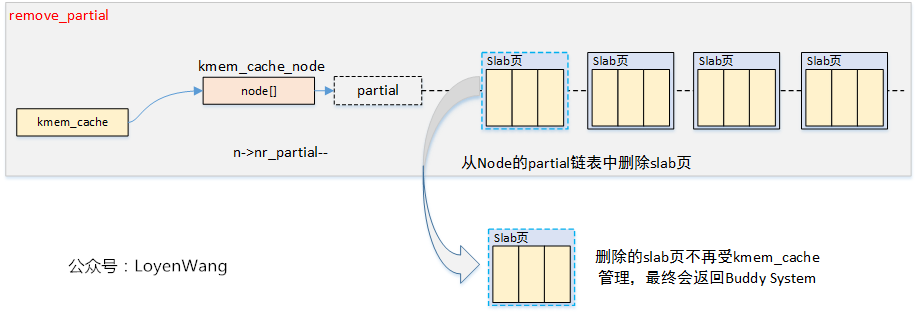
per node partia链表类似per cpu partial,区别是node中的slab是所有cpu共享的,而per cpu是每个cpu独占的。假如现在的slab布局如上图所示。假如现在如红色箭头指向的obj将会释放,那么就是一个empty slab(page->inuse = 0,slab里面均是空闲obj),此时判断kmem_cache_node的nr_partial是否大于kmem_cache的min_partial,如果大于则会释放该slab的内存,还给buddy system。
三、SLUB分配内存原理
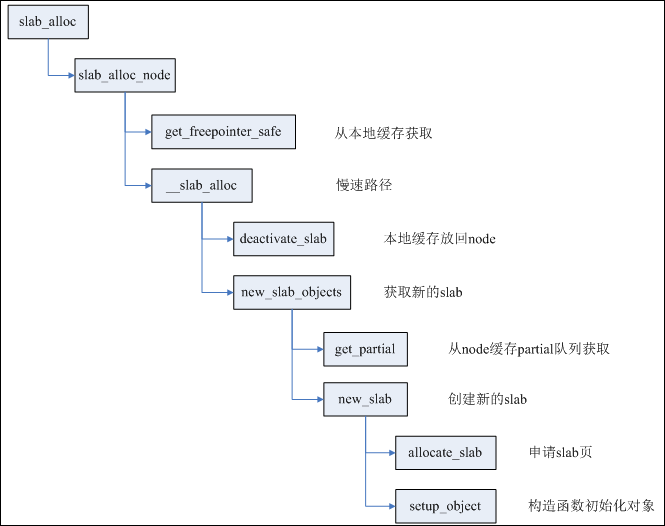
当调用kmem_cache_alloc()分配内存的时候,可以考虑分别从正在使用slab分配,从per cpu page分配,从per cpu partial分配,从per node partial分配和从buddy system中申请新的page进行分配。下图是alloc obj的流程图,更详细alloc obj介绍可以看SLUB内存管理的4个主要接口函数介绍(2)。
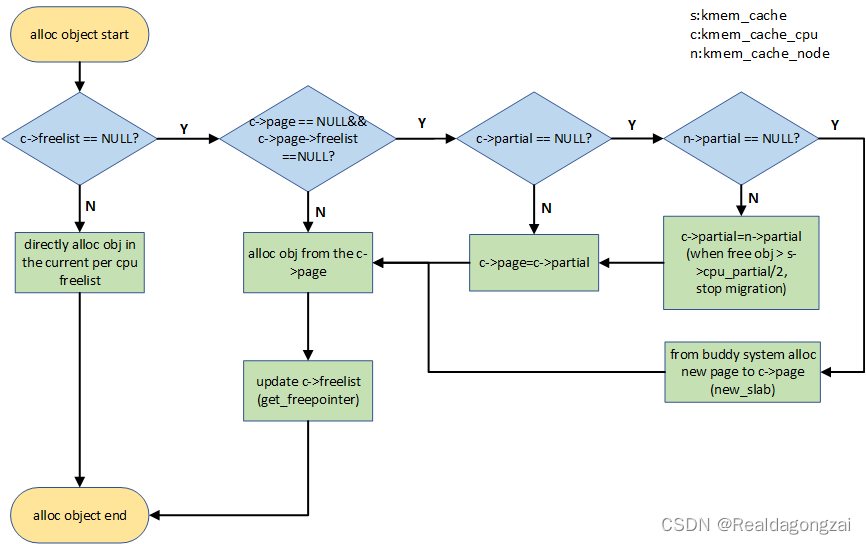
首先从cpu 本地内存缓存池分配,如果c->freelist为NULL,会考虑c->page。如果c->page为NULL,就会转向per cpu partial分配。如果还没有,就会看per node partial,如果还是没有空闲对象的话,最后只能向buddy system申请一个新的page,并更新c->page和c->freelist。如下是这几种情况。
3.1 fastpath
如果c->freelist不为空,则走的是fastpath,直接从c->freelist分配一个空闲object,同是将c->freelist指向下一个空闲object,状态:ALLOC_FASTPATH++。如果c->freelist为NULL,则跳转到slowpath。

3.2 slowpath-1
如果c->freelist为空,slowpath首先判断c->page->freelist,如果不为空,走slowpath-1,从page->freelist中得到空闲object,分配出去,再利用get_freepointer更新c->freelist。代码流程:get_freelist->get_freepointer。状态:ALLOC_REFILL++,ALLOC_SLOWPATH++

3.3 slowpath-2
如果c-page为NULL,则无法走slowpath-1,若此时c->partial不为空,则走slowpath-2,将c->partial链表中的第一个page及对应的slab迁移到c->page中。然后在重新走一遍slowpath-1。代码流程:slub_percpu_partial->get_freelist->get_freepointer。状态:CPU_PARTIAL_ALLOC++,ALLOC_REFILL++,ALLOC_SLOWPATH++

3.4 slowpath-3
如果c->freelist,page->freelist和c->partial均为NULL,则从s->node->partial链表中找寻空闲object。如果能够找到,则进入slowpath-3。这个慢速路径分配会从Node管理的partial链表中迁移部分slab到c->partial中,同时更新c->page和c->freelist。同时,会判断当前迁移的空闲object对象数目是否超过s->cpu_partial的一半,如果是,停止继续迁移到c->partial。代码流程:new_slab_objects->get_partial->get_partial_node(get_any_partial)->get_freepointer。状态:ALLOC_FROM_PARTIAL++,CPU_PARTIAL_NODE++,ALLOC_SLOWPATH++

3.5 slowpath-4
如果Node partial中无法得到空闲的object,那么只能从Buddy system分配新的页面,根据alloc_gfp和s->oo,初始化struct page,然后直接添加到c->page,更新c->freelist。代码流程:new_slab_objects->new_slab->allocate_slab->alloc_slab_page->get_freepointer。状态:ALLOC_SLAB++,ALLOC_SLOWPATH++。

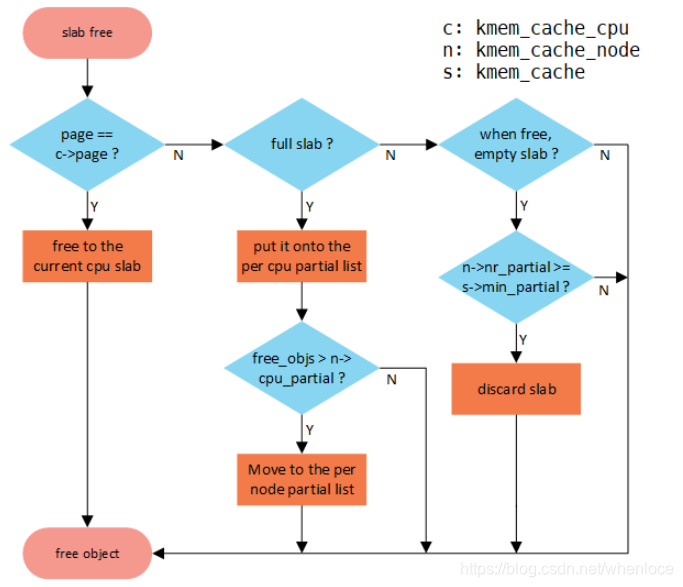
四、SLUB释放内存原理
我们可以通过kmem_cache_free()接口释放申请的obj对象。释放对象的流程如下图所示,更详细free obj介绍可以看SLUB内存管理的4个主要接口函数介绍(3)。
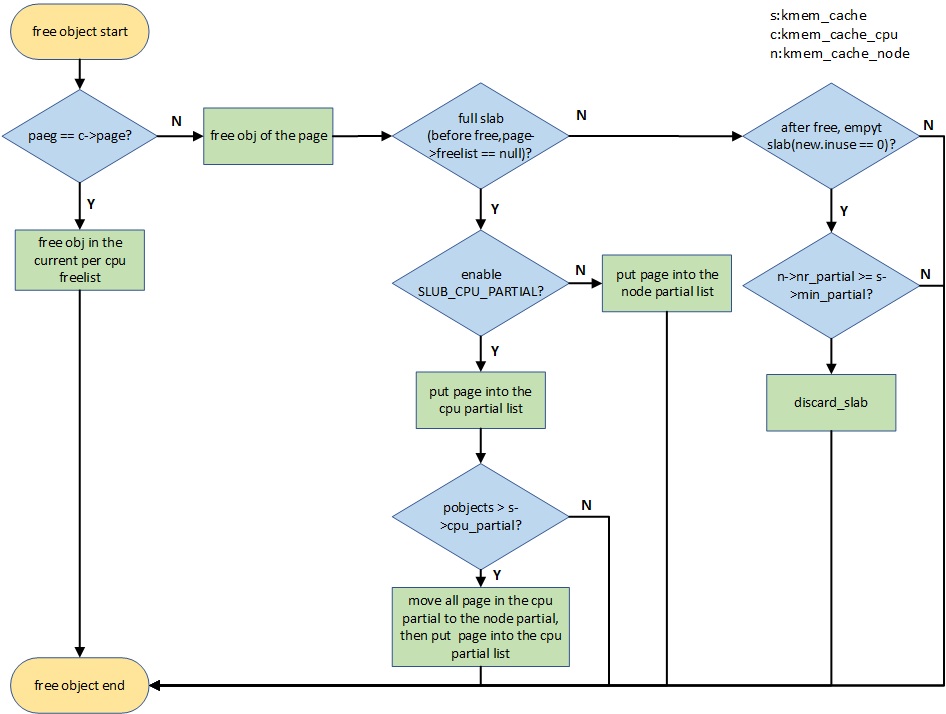
如果释放的ob就属于current per cpu上的slab,那么直接释放即可,属于快速释放路径。如果不是的话,进入慢速释放路径,首先free obj,后面开始对所属page(slab)进行情况判断。首先判断所属slab是不是full slab,因为对于full slab,释放之后就变成partial empty,急需要找个partial链表,如果enable SLUB_CPU_PARTIAL了(默认是enable),此时就考虑per cpu partial链表,否则考虑node partial。如果per cpu partial链表管理的所有slab的free object数量(pobjects)超过kmem_cache的cpu_partial成员的话,就需要将per cpu partial链表管理的所有slab移动到per node partial链表管理;如果不是full slab的话,继续判断释放obj后的slab是否为empty slab,如果是empty slab,那么在满足kmem_cache_node的nr_partial大于kmem_cache的min_partial的情况下,则会释放该slab的内存还给buddy system。其他情况就直接释放即可。
4.1 fastpath(快速释放路径)
如果obj对应的page跟kmem_cache *s所属的per cpu的page是匹配的,是可以直接释放的,进入obj快速释放路径,更新了c->freelist,否则进入慢速释放路径。代码流程:set_freepointer->this_cpu_cmpxchg_double。状态:FREE_FASTPATH++
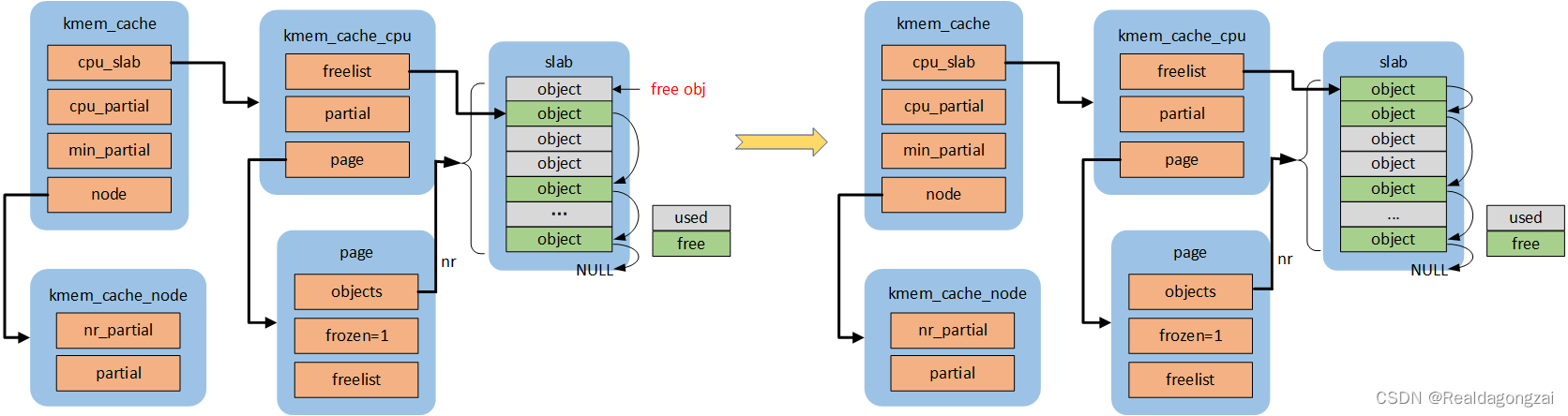
4.2 slowpath-1
(慢速路径释放,统一是对page->freelist操作,而不是c->freelist)
如果这个page对应的page->freelist为空(slab是full slab)且new.frozen =1,那么释放obj变成partial empty slab后,按照规则需要将其放到kmem_cache *s对应的per cpu partial链表的头部,但是在添加之前会判断per cpu partial链表中所有的空闲obj数目(pobjects)是否会大于s->cpu_partial,如果不会直接添加到per cpu partial链表头部即可;否则,会调用unfreeze_partials函数,将per cpu partial上的所有page解冻(frozen置0),然后将per cpu partial链表上所有page,添加到各自对应的node partial上,最后在将这个page添加到per cpu partial。代码流程:put_cpu_partial->unfreeze_partials(pobjects>s->cpu_partial)。状态:FREE_SLOWPATH++,CPU_PARTIAL_FREE++,(可能还会涉及CPU_PARTIAL_DRAIN++,FREE_ADD_PARTIAL++,DEACTIVATE_EMPTY++)
(1)pobjects <= s->cpu_partial

(2)pobjects > s->cpu_partial

4.3 slowpath-2
如果这个page对应的was_frozen初始值就是1,说明该page是属于其他CPU的,当前CPU无法对其进行任何操作(添加到CPU partial或者node partial),直接return。状态:FREE_SLOWPATH++,FREE_FROZEN++
4.4 slowpath-3
如果释放obj后,slab是empty slab(new.inuse为0),首先会得到这个page对应的node,然后按照规则判断n->nr_partial 是否小于s->min_partial,如果是,则直接执行释放操作即可;否则会调用remove_partial/remove_full将其从node partial/full链表(开启slub debug时,需要考虑full链表)中删除,还给buddy system。代码流程:remove_partial/remove_full->discard_slab。状态:FREE_SLOWPATH++,FREE_REMOVE_PARTIAL++/FREE_SLAB++
(1)n->nr_partial < s->min_partial

(2)n->nr_partial >= s->min_partial
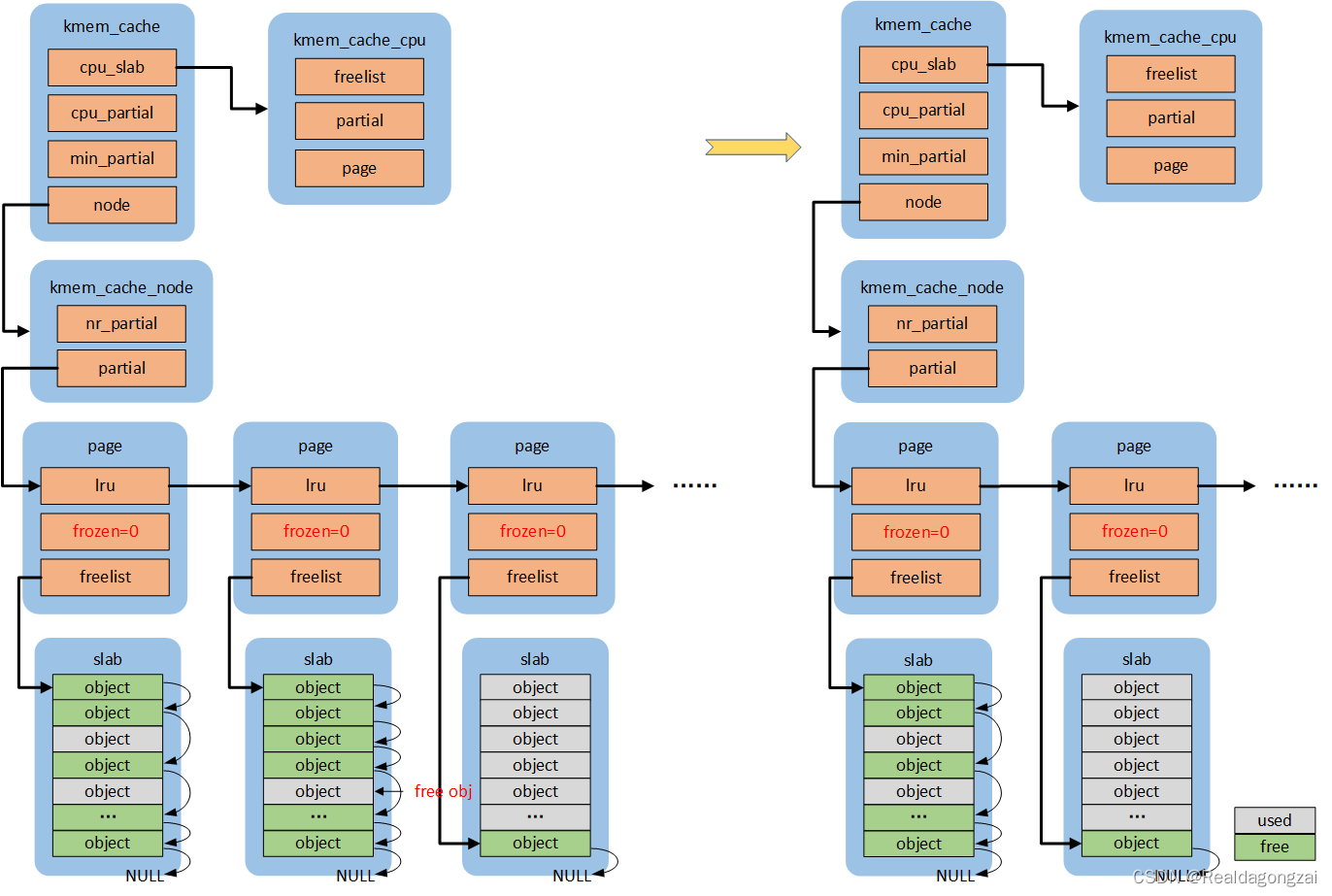
4.5 slowpath-4
如果未使能SLUB_CPU_PARTIAL,虽然是full slab,但是由于没有CPU partial,只能将这个page添加到该page对应node partial尾部,如果开启了slub debug,首先还会执行remove_full操作。代码流程:remove_full->add_partial。状态:FREE_SLOWPATH++,FREE_ADD_PARTIAL++
五、kmalloc
kmalloc的内存分配就是基于slab分配器,通用的slab分配需求可以直接通过kmalloc来分配,对于专用于某个模块或者进程的slab分配,就要使用我前面介绍的SLUB内存管理的4个主要接口函数来试下slab的管理。在系统启动初期kmem_cache_init调用create_kmalloc_caches()创建多个管理不同大小对象的kmem_cache(mm/slab_common.c)保存在kmalloc_caches全局变量中以备后续kmalloc分配内存。当然默认配置情况下,系统系统启动之后创建的最大size的kmem_cache是kmalloc-8192。因此,通过slab接口分配的最大内存是8192 bytes(8K=2*page,1page=4K)。那么通过kmalloc接口申请的内存大于8192 bytes该怎么办呢?其实kmalloc会判断申请的内存是否大于8192 bytes,如果大于的话就会通过alloc_pages接口申请内存,认为是大内存了,用buddy system按照page来分配内存,不用slub。kmem_cache的名称以及大小使用struct kmalloc_info_struct管理,在mm/slab.h文件中。在mm/slab_commom.c文件中包含所有管理不同大小对象的kmem_cache的名称,至于为什么有kmalloc-96和kmalloc-192在SLUB内存管理之slub初始化中有介绍。 现在假如通过kmalloc(17, GFP_KERNEL)申请内存,系统会从名称“kmalloc-32”管理的slab缓存池中分配一个对象,即使浪费了15Byte。
/* A table of kmalloc cache names and sizes */
extern const struct kmalloc_info_struct {const char *name;unsigned int size;
} kmalloc_info[];/** kmalloc_info[] is to make slub_debug=,kmalloc-xx option work at boot time.* kmalloc_index() supports up to 2^26=64MB, so the final entry of the table is* kmalloc-67108864.*/
const struct kmalloc_info_struct kmalloc_info[] __initconst = { //__initconst 用于初始化数据{NULL, 0}, {"kmalloc-96", 96},{"kmalloc-192", 192}, {"kmalloc-8", 8},{"kmalloc-16", 16}, {"kmalloc-32", 32},{"kmalloc-64", 64}, {"kmalloc-128", 128},{"kmalloc-256", 256}, {"kmalloc-512", 512},{"kmalloc-1k", 1024}, {"kmalloc-2k", 2048},{"kmalloc-4k", 4096}, {"kmalloc-8k", 8192},{"kmalloc-16k", 16384}, {"kmalloc-32k", 32768},{"kmalloc-64k", 65536}, {"kmalloc-128k", 131072},{"kmalloc-256k", 262144}, {"kmalloc-512k", 524288},{"kmalloc-1M", 1048576}, {"kmalloc-2M", 2097152},{"kmalloc-4M", 4194304}, {"kmalloc-8M", 8388608},{"kmalloc-16M", 16777216}, {"kmalloc-32M", 33554432},{"kmalloc-64M", 67108864}
};现在来看看kmalloc的实现方式,在include/linux/slab.h中,因为目前默认配置的slab分配器是slub。
#ifdef CONFIG_SLUB
/** SLUB directly allocates requests fitting in to an order-1 page* (PAGE_SIZE*2). Larger requests are passed to the page allocator.*/
#define KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1)
#define KMALLOC_SHIFT_MAX (MAX_ORDER + PAGE_SHIFT - 1)
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 3
#endif
#endif/* Maximum allocatable size */
#define KMALLOC_MAX_SIZE (1UL << KMALLOC_SHIFT_MAX)
/* Maximum size for which we actually use a slab cache */
#define KMALLOC_MAX_CACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH)
/* Maximum order allocatable via the slab allocagtor */
#define KMALLOC_MAX_ORDER (KMALLOC_SHIFT_MAX - PAGE_SHIFT)/** Kmalloc subsystem.*/
#ifndef KMALLOC_MIN_SIZE
#define KMALLOC_MIN_SIZE (1 << KMALLOC_SHIFT_LOW)
#endif
/** ZERO_SIZE_PTR will be returned for zero sized kmalloc requests.** Dereferencing ZERO_SIZE_PTR will lead to a distinct access fault.** ZERO_SIZE_PTR can be passed to kfree though in the same way that NULL can.* Both make kfree a no-op.*/
#define ZERO_SIZE_PTR ((void *)16)//正主来了......
/** kmalloc - allocate memory* @size: how many bytes of memory are required.* @flags: the type of memory to allocate.** kmalloc is the normal method of allocating memory* for objects smaller than page size in the kernel.*
*/
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{//是gcc工具用来判断参数编译时是否为一个常数,如果为常数,返回1,否则返回0,如size是一个变量。
//毕竟有些操作对于常数来说是可以优化的if (__builtin_constant_p(size)) {
#ifndef CONFIG_SLOBunsigned int index;
#endif//KMALLOC_MAX_CACHE_SIZE表示系统创建的slab cache的最大size,kmalloc_caches数组中预保存了很多kmem cache(kmem_cache_init时创建的),
//如果大于,则使用kmalloc_large进行大内存分配,走buddy system;否则,直接从kmalloc_caches数组中分配kmem cacheif (size > KMALLOC_MAX_CACHE_SIZE) //KMALLOC_MAX_CACHE_SIZE = 8K(8192bit)return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB//根据size,得到kmalloc_caches数组中的索引index = kmalloc_index(size);//如果size为0,直接返回ZERO_SIZE_PTR,指针地址为16的指针,解引用这个地址会报错if (!index)return ZERO_SIZE_PTR;
//如果使能了kmalloc_debug_enable,则从kmalloc_debug_caches中得到对应的kmem cache
#if defined(MEMLEAK_DETECT) && defined(CONFIG_KMALLOC_DEBUG)/* try to kmalloc from kmalloc_debug caches fisrt.*/if (unlikely(kmalloc_debug_enable)) {struct kmem_cache *s;s = (struct kmem_cache *)atomic64_read(&kmalloc_debug_caches[kmalloc_type(flags)][index]);if (s)return kmem_cache_alloc_trace(s, flags, size);}
#endif
//否则从kmalloc_caches得到kmem cache,然后通过kmem_cache_alloc_trace从这个slab cache中分配得到对应的obj
//kmem_cache_alloc_trace几乎跟kmem_cache_alloc一样, 无非就是多了一个kasan的tag设置 return kmem_cache_alloc_trace(kmalloc_caches[kmalloc_type(flags)][index],flags, size);
#endif}
//如果size是变量,则走这里,通过__kmalloc分配size大小的objreturn __kmalloc(size, flags);
}static __always_inline int kmalloc_index(size_t size)
{if (!size)return 0;if (size <= KMALLOC_MIN_SIZE) //KMALLOC_MIN_SIZE ==8return KMALLOC_SHIFT_LOW;if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)return 1;if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)return 2;if (size <= 8) return 3;if (size <= 16) return 4;if (size <= 32) return 5;if (size <= 64) return 6;if (size <= 128) return 7;if (size <= 256) return 8;if (size <= 512) return 9;if (size <= 1024) return 10;if (size <= 2 * 1024) return 11;if (size <= 4 * 1024) return 12;if (size <= 8 * 1024) return 13;if (size <= 16 * 1024) return 14;if (size <= 32 * 1024) return 15;if (size <= 64 * 1024) return 16;if (size <= 128 * 1024) return 17;if (size <= 256 * 1024) return 18;if (size <= 512 * 1024) return 19;if (size <= 1024 * 1024) return 20;if (size <= 2 * 1024 * 1024) return 21;if (size <= 4 * 1024 * 1024) return 22;if (size <= 8 * 1024 * 1024) return 23;if (size <= 16 * 1024 * 1024) return 24;if (size <= 32 * 1024 * 1024) return 25;if (size <= 64 * 1024 * 1024) return 26;/* Will never be reached. Needed because the compiler may complain */return -1;
} 5.1 kmem_cache_alloc_trace
kmem_cache_alloc_trace这个函数的实现,slub分配器使用的是在mm/slub.c里面。看代码实现,kmalloc直接使用的就是....._trace,应该默认是开启CONFIG_TRACING的,其中slab_alloc是核心函数,其余是一些debug调试会用到的信息,相比kmem_cache_alloc多了一个kasan,其余一样,关于kmem_cache_alloc在SLUB内存管理的4个主要接口函数介绍(2)中有介绍。
//mm/slub.c
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t gfpflags)
{void *ret = slab_alloc(s, gfpflags, _RET_IP_); //核心函数trace_kmem_cache_alloc(_RET_IP_, ret, s->object_size,s->size, gfpflags); //用于跟踪调试return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc);#ifdef CONFIG_TRACING
void *kmem_cache_alloc_trace(struct kmem_cache *s, gfp_t gfpflags, size_t size)
{void *ret = slab_alloc(s, gfpflags, _RET_IP_); //核心函数trace_kmalloc(_RET_IP_, ret, size, s->size, gfpflags); //用于跟踪调试ret = kasan_kmalloc(s, ret, size, gfpflags);//用于跟踪调试,相比kmem_cache_alloc多了一个kasan功能,进行了一个kasan tag的检查return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc_trace);
#endif5.1.1 kasan_kmalloc
include/linux/kernel.h
/** This looks more complex than it should be. But we need to* get the type for the ~ right in round_down (it needs to be* as wide as the result!), and we want to evaluate the macro* arguments just once each.*/
#define __round_mask(x, y) ((__typeof__(x))((y)-1))
/*** round_up - round up to next specified power of 2* @x: the value to round* @y: multiple to round up to (must be a power of 2)** Rounds @x up to next multiple of @y (which must be a power of 2).* To perform arbitrary rounding up, use roundup() below.*/
//取整,将非y倍数的整数x上调到y的倍数。
#define round_up(x, y) ((((x)-1) | __round_mask(x, y))+1)mm/kasan/kasan.h
#define KASAN_SHADOW_SCALE_SHIFT 3
#define KASAN_SHADOW_SCALE_SIZE (1UL << KASAN_SHADOW_SCALE_SHIFT) //8B#ifndef arch_kasan_get_tag
#define arch_kasan_get_tag(addr) 0
#endif#define get_tag(addr) arch_kasan_get_tag(addr)/** This function assigns a tag to an object considering the following:* 1. A cache might have a constructor, which might save a pointer to a slab* object somewhere (e.g. in the object itself). We preassign a tag for* each object in caches with constructors during slab creation and reuse* the same tag each time a particular object is allocated.* 2. A cache might be SLAB_TYPESAFE_BY_RCU, which means objects can be* accessed after being freed. We preassign tags for objects in these* caches as well.* 3. For SLAB allocator we can't preassign tags randomly since the freelist* is stored as an array of indexes instead of a linked list. Assign tags* based on objects indexes, so that objects that are next to each other* get different tags.*/
//输入参数中init=false,keep_tag=true
static u8 assign_tag(struct kmem_cache *cache, const void *object,bool init, bool keep_tag)
{/** 1. When an object is kmalloc()'ed, two hooks are called:* kasan_slab_alloc() and kasan_kmalloc(). We assign the* tag only in the first one.* 2. We reuse the same tag for krealloc'ed objects.*/
//为true,说明这个对象是kmalloc创建的,已经分配过一次了,直接复用即可if (keep_tag)return get_tag(object);//默认是返回0/** If the cache neither has a constructor nor has SLAB_TYPESAFE_BY_RCU* set, assign a tag when the object is being allocated (init == false).*/
//如果slab缓存的构造函数为空且flags不是SLAB_TYPESAFE_BY_RCU,则需要分配if (!cache->ctor && !(cache->flags & SLAB_TYPESAFE_BY_RCU))return init ? KASAN_TAG_KERNEL : random_tag();/* For caches that either have a constructor or SLAB_TYPESAFE_BY_RCU: */
#ifdef CONFIG_SLAB/* For SLAB assign tags based on the object index in the freelist. */
//slab allocator跟slub allocator不太一样return (u8)obj_to_index(cache, virt_to_page(object), (void *)object);
#else/** For SLUB assign a random tag during slab creation, otherwise reuse* the already assigned tag.*/return init ? random_tag() : get_tag(object);
#endif
}//正主来了。。。。
void * __must_check kasan_kmalloc(struct kmem_cache *cache, const void *object,size_t size, gfp_t flags)
{return __kasan_kmalloc(cache, object, size, flags, true);
}static void *__kasan_kmalloc(struct kmem_cache *cache, const void *object,size_t size, gfp_t flags, bool keep_tag)
{unsigned long redzone_start;unsigned long redzone_end;u8 tag = 0xff;//kasan 影子内存如果为0xFF,则标识全部 8 bytes data 都不能被访问,(8B分配1B的影子内存)if (gfpflags_allow_blocking(flags))quarantine_reduce();if (unlikely(object == NULL))return NULL;
//将object + size大小按照8B字节倍数向上取整redzone_start = round_up((unsigned long)(object + size),KASAN_SHADOW_SCALE_SIZE);
//将object + cache->object_size大小按照8B字节倍数向上取整redzone_end = round_up((unsigned long)object + cache->object_size,KASAN_SHADOW_SCALE_SIZE);
//只有设置了CONFIG_KASAN_SW_TAGS才会执行kasan的shadow tag标记,否则后面两个kasan函数不会执行if (IS_ENABLED(CONFIG_KASAN_SW_TAGS))tag = assign_tag(cache, object, false, keep_tag);//根据前面给的参数keep_tag=true,根据分析,这个tag=0,表示影子内存对应的data内存都可以访问/* Tag is ignored in set_tag without CONFIG_KASAN_SW_TAGS */
//把数据区域的 shadow 设置成 0,可以访问kasan_unpoison_shadow(set_tag(object, tag), size);
//把数据后 redzone 区域的 shadow 设置成 0xFC (KASAN_KMALLOC_REDZONE),不能访问kasan_poison_shadow((void *)redzone_start, redzone_end - redzone_start,KASAN_KMALLOC_REDZONE);
//记录alloc trace信息if (cache->flags & SLAB_KASAN)set_track(&get_alloc_info(cache, object)->alloc_track, flags);
//返回指向shadow标记了tag的object的指针return set_tag(object, tag);
}5.2 __kmalloc
void *__kmalloc(size_t size, gfp_t flags)
{struct kmem_cache *s;void *ret;
//同样首先判断size是否大于系统预创建的slab cache的最大size,如果是,则继续走kmalloc_large,通过buddy system来分配内存if (unlikely(size > KMALLOC_MAX_CACHE_SIZE))return kmalloc_large(size, flags);
//否则,根据size,得到对应的index,直接从kmalloc_caches分配kmem caches = kmalloc_slab(size, flags);if (unlikely(ZERO_OR_NULL_PTR(s)))return s;
//后面三个函数,实现的功能跟前面的kmem_cache_alloc_trace函数完全一样,从s中分配到指定的objret = slab_alloc(s, flags, _RET_IP_);trace_kmalloc(_RET_IP_, ret, size, s->size, flags);ret = kasan_kmalloc(s, ret, size, flags);return ret;
}
EXPORT_SYMBOL(__kmalloc);/*Find the kmem_cache structure that serves a given size of allocation*/
struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags)
{unsigned int index;
//这里同样根据size,得到indexif (size <= 192) {if (!size)return ZERO_SIZE_PTR;
//如果申请大小小于192,且不为0,将通过size_index_elem转换为下标后,经size_index全局数组取得索引值
//size_index数组和size_index_elem函数在SLUB内存管理之slub初始化里面介绍过index = size_index[size_index_elem(size)];} else {if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) {WARN_ON(1);return NULL;}
// asm-generic/bitops/fls.h返回输入参数的最高有效bit位(从低位往左数最后的有效bit位)的序号,
//该序号与常规0起始序号不同,它是1起始的(当没有有效位时返回0) index = fls(size - 1);}
//如果使能了kmalloc_debug_enable,则从kmalloc_debug_caches中得到对应的kmem cache
#if defined(MEMLEAK_DETECT) && defined(CONFIG_KMALLOC_DEBUG)// try to kmalloc from kmalloc_debugcaches fisrt.if (unlikely(kmalloc_debug_enable)) {struct kmem_cache *s;s = (struct kmem_cache *)atomic64_read(&kmalloc_debug_caches[kmalloc_type(flags)][index]);if (unlikely(s))return s;}
#endif
//否则从kmalloc_caches得到kmem cachereturn kmalloc_caches[kmalloc_type(flags)][index];
}5.3 kmalloc_large
static __always_inline void *kmalloc_large(size_t size, gfp_t flags)
{
//获取页面的阶数,即这个size需要几个page(1page=4K)unsigned int order = get_order(size);
//kmalloc_order_trace->kmalloc_order->alloc_pages->page_address,通过这个调用链,从buddy system中直接分配内存,
//这里暂时不细讲buddy system的内存分配,后面关于buddy system会有单独篇幅讲述return kmalloc_order_trace(size, flags, order);
}include/asm-generic/getorder.h
static inline __attribute_const__ int get_order(unsigned long size)
{if (__builtin_constant_p(size)) {//__builtin_constant_p判断size是否是常量,如果是,走if语句if (!size)return BITS_PER_LONG - PAGE_SHIFT;if (size < (1UL << PAGE_SHIFT))//PAGE_SHIFT=12,size<4Kreturn 0;
//如果size>=4k,执行如下语句,log2((size)-1) -12+1return ilog2((size) - 1) - PAGE_SHIFT + 1;}//这个做法跟函数kmalloc_slab的fls用法一样 size--;size >>= PAGE_SHIFT;
#if BITS_PER_LONG == 32return fls(size);
#elsereturn fls64(size);
#endif
}static __always_inline void *
kmalloc_order_trace(size_t size, gfp_t flags, unsigned int order)
{return kmalloc_order(size, flags, order);
}/** To avoid unnecessary overhead, we pass through large allocation requests* directly to the page allocator. We use __GFP_COMP, because we will need to* know the allocation order to free the pages properly in kfree.*/
void *kmalloc_order(size_t size, gfp_t flags, unsigned int order)
{void *ret;struct page *page;flags |= __GFP_COMP;page = alloc_pages(flags, order);ret = page ? page_address(page) : NULL;ret = kasan_kmalloc_large(ret, size, flags);kmemleak_alloc(ret, size, 1, flags);return ret;
}
EXPORT_SYMBOL(kmalloc_order);六、kfree
kfree的实现相对kmalloc要简单一些,而且很多操作都是复用了kmem_cache_free函数的,这个函数在SLUB内存管理的4个主要接口函数介绍(3)
/* ZERO_SIZE_PTR can be passed to kfree though in the same way that NULL can.
* Both make kfree a no-op.
*/
#define ZERO_SIZE_PTR ((void *)16)#define ZERO_OR_NULL_PTR(x) ((unsigned long)(x) <= \(unsigned long)ZERO_SIZE_PTR)
//正主.....
void kfree(const void *x)
{struct page *page;void *object = (void *)x;
//ftrace, 记录kfree轨迹trace_kfree(_RET_IP_, x);//与指针16(等价于NULL)进行判断,如果指针地址小于等于指针16,直接返回,认为是NULLif (unlikely(ZERO_OR_NULL_PTR(x)))return;
//通过object地址x得到对应的page,在SLUB内存管理的4个主要接口函数介绍(3)里有讲page = virt_to_head_page(x);//如果不作为slab分配管理,PageSlab返回0if (unlikely(!PageSlab(page))) {//复合页:将物理上连续的两个或多个页看成一个独立的大页
//判断是否是复合页(通过PG_head标志或者page->compound_head参数来确定),如果不是复合页会BUG_ON,打印bug信息BUG_ON(!PageCompound(page));//做释放前kmemleak处理(该函数主要是封装了kmemleak_free())kfree_hook(object);
//下面开始执行buddy system的页操作了
//把shadow_memory设置成0,可以访问,因为这块内存要释放了kasan_alloc_pages(page, compound_order(page));
//buddy system的page释放页面块,从给定的page开始,释放的页面块个数为2的compound_order(page)次方个__free_pages(page, compound_order(page));return;}
//如果作为slab分配管理,走slab_free,这个是kmem_cache_free的核心函数,在SLUB内存管理的4个主要接口函数介绍(3)中有细讲slab_free(page->slab_cache, page, object, NULL, 1, _RET_IP_);
}
EXPORT_SYMBOL(kfree);//include/linux/page-flags.h PageSlab定义的地方
/** Macros to create function definitions for page flags*/
#define TESTPAGEFLAG(uname, lname, policy) \
static __always_inline int Page##uname(struct page *page) \{ return test_bit(PG_##lname, &policy(page, 0)->flags); }//根据上面描述规则,可得到,如下函数原型
static __always_inline int PageSlab(struct page *page)
{
//原子操作,返回page->flags所指对象的PG_slab比特位的值,用于判断该页面是否作为slab分配管理
//返回1,则表示作为slab分配管理,否则不是return test_bit(PG_slab, &page->flags);
}static __always_inline int PageTail(struct page *page)
{return READ_ONCE(page->compound_head) & 1;
}static __always_inline int PageCompound(struct page *page)
{return test_bit(PG_head, &page->flags) || PageTail(page);
}参考资料
mm-slab对象的分配
【Linux内存源码分析】kmalloc与kfree实现
Linux mem 2.7 内存错误检测 (KASAN) 详解_pwl999的博客-CSDN博客_kasan
复合页( Compound Page )
内存分配[三] - Linux中Buddy系统的实现
图解slub
linux内核中percpu变量的实现
SLUB内存管理之slub初始化
SLUB内存管理的4个主要接口函数介绍(1)
SLUB内存管理的4个主要接口函数介绍(2)
SLUB内存管理的4个主要接口函数介绍(3)