文章目录
- 一、Spark简介
- Spark与Hadoop的区别
- 部署模式
- 二、 Spark架构
- 1.Driver
- 2.Executor
- 3.Master & Worker
- 4.Cluster manager
- 5.ApplicationMaster
- 补充点:Stage
- 执行过程
- 三、Shuffle机制
- shuffle介绍
- Shuffle的影响
- 导致Shuffle的操作
- 四、RDD(弹性分布式数据集)
- 宽依赖和窄依赖
- 五、Spark算子
一、Spark简介
Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎。

Spark主要由五部分组成:
- Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL,
Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的 - Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL
或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。 - Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理
数据流的 API。 - Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等
额外的功能,还提供了一些更底层的机器学习原语。 - Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
Spark与Hadoop的区别
Spark一直被认为是Hadoop的升级版,在数据处理方面,基于内存,优于hadoop的MapReduce框架,但需要注意的是Spark取代不了Hadoop,Spark没有存储,只是负责处理,而且Spark可以独立运行,也可以集成到Hadoop中,去替代MapReduce。
- Spark和Hadoop的根本差异是多个作业之间的数据通信问题 :
Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。 - Spark提供了更加丰富的数据处理模型,而MapReduce提供的Mapper和Reducer这样简单的模型无法满足一定场景下的业务需求,且MapReduce对迭代式处理支持不是很友好。
- Hadoop的task是一个个进程,spark是一个个线程
- Hadoop容错性低,spark可以根据RDD之间的血缘关系重算;
- spark有transform和action算子,只有遇到action才会触发job,会做流水线层面的优化;
- 对于多次使用的RDD,spark可以基于其块管理器,进行缓存
- 有利也有弊,Spark基于内存,可能会出现资源不足的情况
部署模式

二、 Spark架构
Spark架构是一个标准的Master-slave架构。
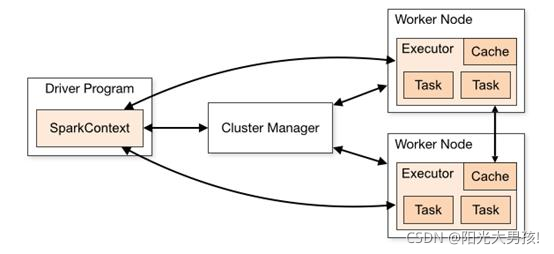
1.Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在 Executor 之间调度任务(task)
- 跟踪 Executor 的执行情况
- 通过 UI 展示查询运行情况
实际上,我们无法准确地描述 Driver 的定义,因为在整个的编程过程中没有看到任何有关Driver 的字眼。所以简单理解,所谓的 Driver 就是驱使整个应用运行起来的程序,也称之为Driver 类。
2.Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。
Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
3.Master & Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对
数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
4.Cluster manager
集群资源管理器(例如,Standlone Manager,Mesos,YARN)
5.ApplicationMaster
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
说的简单点就是,ResourceManager(资源)和 Driver(计算)之间的解耦合靠的就是ApplicationMaster。
如果Driver需要资源,那么会向ApplicationMaster进行申请,AM 会进而向ResourceManager进一步申请资源。
补充点:Stage
每个job被划分为多个stage,一个stage中包含一个taskset
执行过程
- 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
- Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
- Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
三、Shuffle机制
shuffle介绍
在 Spark 中,一个任务对应一个分区,通常不会跨分区操作数据。但如果遇到 reduceByKey 等操作,Spark 必须从所有分区读取数据,并查找所有键的所有值,然后汇总在一起以计算每个键的最终结果 ,这称为 Shuffle。
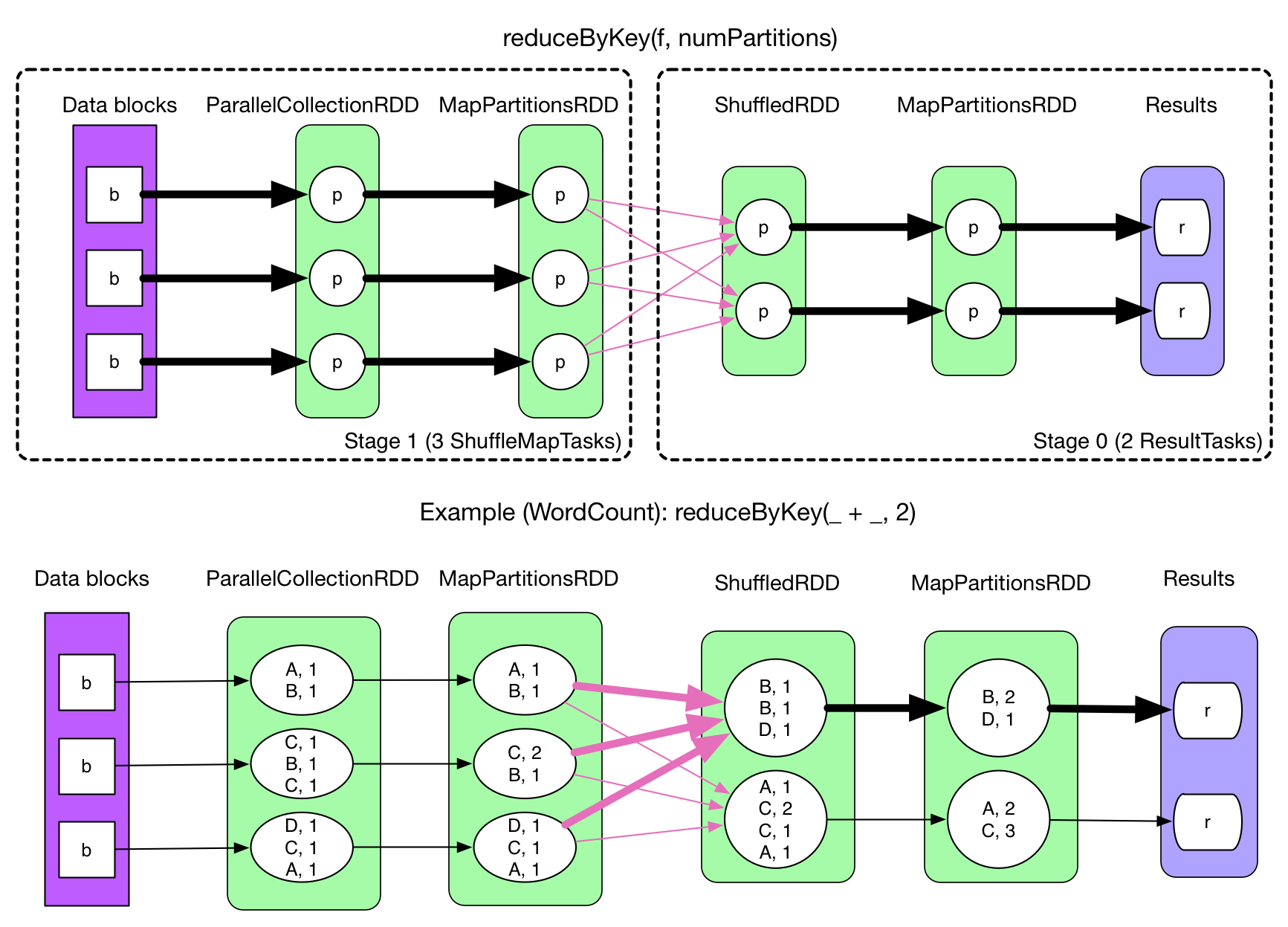
Shuffle的影响
Shuffle 是一项昂贵的操作,因为它通常会跨节点操作数据,这会涉及磁盘 I/O,网络 I/O,和数据序列化。某些 Shuffle 操作还会消耗大量的堆内存,因为它们使用堆内存来临时存储需要网络传输的数据。Shuffle 还会在磁盘上生成大量中间文件,从 Spark 1.3 开始,这些文件将被保留,直到相应的 RDD 不再使用并进行垃圾回收,这样做是为了避免在计算时重复创建 Shuffle 文件。如果应用程序长期保留对这些 RDD 的引用,则垃圾回收可能在很长一段时间后才会发生,这意味着长时间运行的 Spark 作业可能会占用大量磁盘空间,通常可以使用 spark.local.dir 参数来指定这些临时文件的存储目录。
导致Shuffle的操作
由于 Shuffle 操作对性能的影响比较大,所以需要特别注意使用,以下操作都会导致 Shuffle:
- 涉及到重新分区操作: 如
repartition和coalesce; - 所有涉及到 ByKey 的操作:如
groupByKey和reduceByKey,但countByKey除外; - 联结操作:如
cogroup和join。
四、RDD(弹性分布式数据集)
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
宽依赖和窄依赖
RDD 和它的父 RDD(s) 之间的依赖关系分为两种不同的类型:
- 窄依赖 (narrow dependency):父 RDDs 的一个分区最多被子 RDDs 一个分区所依赖;
- 宽依赖 (wide dependency):父 RDDs 的一个分区可以被子 RDDs 的多个子分区所依赖。
如下图,每一个方框表示一个 RDD,带有颜色的矩形表示分区:
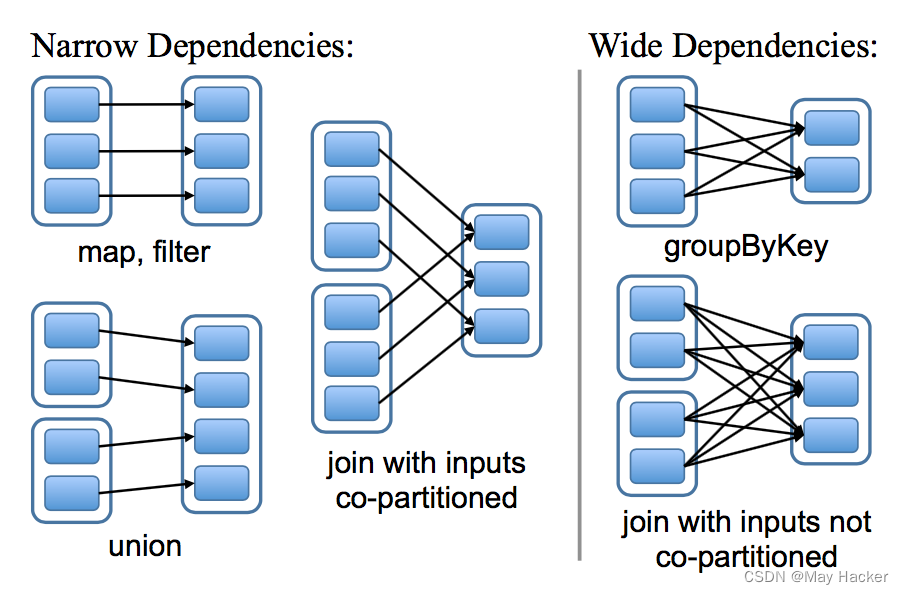
区分这两种依赖是非常有用的:
- 首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)对父分区数据进行计算,例如先执行 map 操作,然后执行 filter 操作。而宽依赖则需要计算好所有父分区的数据,然后再在节点之间进行 Shuffle,这与 MapReduce 类似。
- 窄依赖能够更有效地进行数据恢复,因为只需重新对丢失分区的父分区进行计算,且不同节点之间可以并行计算;而对于宽依赖而言,如果数据丢失,则需要对所有父分区数据进行计算并再次 Shuffle。
五、Spark算子
-
1、Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据。
-
2、Key-Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Key-Value型的数据。
-
3、Action算子,这类算子会触发SparkContext提交作业。