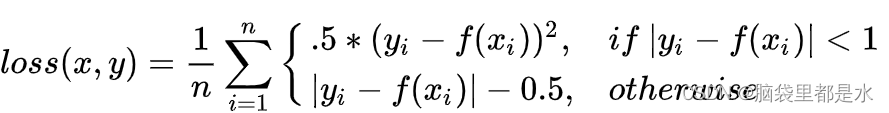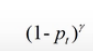文章目录
- focal loss的整体理解
- 易分辨样本、难分辨样本的含义
- focal loss的出现过程
- focal loss 举例说明
- focal loss的 α \alpha α变体
focal loss的整体理解
focal loss 是一种处理样本分类不均衡的损失函数,它侧重的点是根据样本分辨的难易程度给样本对应的损失添加权重,即给容易区分的样本添加较小的权重 α 1 \alpha_1 α1,给难分辨的样本添加较大的权重 α 2 \alpha_2 α2.那么,损失函数的表达式可以写为:
L s u m = α 1 × L 易 区 分 + α 2 × L 难 区 分 L_{sum}=\alpha_1\times L_{易区分}+\alpha_2\times L_{难区分} Lsum=α1×L易区分+α2×L难区分
因为 α 1 \alpha_1 α1小而 α 2 \alpha_2 α2大,那么上述的损失函数中 L 难 区 分 L_{难区分} L难区分主导损失函数,也就是将损失函数的重点集中于难分辨的样本上,对应损失函数的名称:focal loss。
表达式为 F L ( p t ) = − ( 1 − p t ) γ log ( p t ) FL(p_t)=-(1-p_t)^\gamma \log(p_t) FL(pt)=−(1−pt)γlog(pt).含义后文会讲。
易分辨样本、难分辨样本的含义
在本损失函数中数次出现难分辨和易分辨的词语,那么何为易分辨、何为难分辨?
其实这个区别隐藏在分类置信度上!
通常将分类置信度接近1或接近0的样本称为易分辨样本,其余的称之为难分辨样本。换句话说,也就是我们有把握确认属性的样本称为易分辨样本,没有把握确认属性的样本称之为难分辨样本。
比如在一张图片中,我们获得是人的置信度为0.9,那么我们很有把握它是人,所以此时认定该样本为易分辨样本。同样,获得是人的置信度为0.6,那么我们没有把握它是人,所以称该样本为难分辨样本。
focal loss的出现过程
- 首先,在分类损失中最经典的损失函数为标准交叉熵,以二分类为例可以写为:
C E ( p , y ) = { − log ( p ) i f y = 1 − log ( 1 − p ) o t h e r w i s e CE(p,y)= \begin{cases} -\log(p)&if\space y=1\\ -\log(1-p)&otherwise \end{cases} CE(p,y)={−log(p)−log(1−p)if y=1otherwise
其中 y = 1 或 − 1 y=1或-1 y=1或−1. p ϵ [ 0 , 1 ] p\epsilon[0,1] pϵ[0,1]是判断是正样本( y = 1 y=1 y=1)的概率。为了统一 p 、 1 − p p、1-p p、1−p,我们设置 p t p_t pt函数:
p t = { p i f y = 1 1 − p o t h e r w i s e p_t=\begin{cases}p&if\space y=1\\1-p&otherwise\end{cases} pt={p1−pif y=1otherwise
于是可以得到 C E ( p , y ) = C E ( p t ) = − log ( p t ) CE(p,y)=CE(p_t)=-\log(p_t) CE(p,y)=CE(pt)=−log(pt)
但是这种损失函数在处理类不均衡问题时非常糟糕,会因为某类的冗余,而主导损失函数,使模型失去效果。 - 为了解决类不平衡问题,常见的做法是添加权重因子,即平衡交叉熵。在 α ϵ [ 0 , 1 ] \alpha\epsilon[0,1] αϵ[0,1]的前提下,对class 1添加 α \alpha α,对class -1添加 1 − α 1-\alpha 1−α。为了形式上的方便,我们采用 α t \alpha_t αt,从而可以得到
C E ( p t ) = − α t log ( p t ) CE(p_t)=-\alpha_t\log(p_t) CE(pt)=−αtlog(pt)
但是,当我们处理大量负样本、少量正样本的情况时( e g eg eg 50000:20),即使我们把负样本的权重设置的很低,但是因为负样本的数量太多,积少成多,负样本的损失函数也会主导损失函数。 - 后来作者做实验,得到下面的数据:

可以从图中发现,那些即使置信度很高的样本在标准交叉熵里也会存在损失。而且在实际中,置信度很高的负样本往往占总样本的绝大部分,如果将这部分损失去除或者减弱,那么损失函数的效率会更高。
于是,作者想到减少置信度很高的样本损失在总损失中的比重,即在标准交叉熵前添加了权重因子 ( 1 − P t ) γ (1-P_t)^\gamma (1−Pt)γ,形成focal loss:
F L ( p t ) = − ( 1 − p t ) γ log ( p t ) FL(p_t)=-(1-p_t)^\gamma \log(p_t) FL(pt)=−(1−pt)γlog(pt)
focal loss 举例说明
当 γ = 0 \gamma=0 γ=0时,focal loss等于标准交叉熵函数。
当 γ > 0 \gamma>0 γ>0时,因为 ( 1 − p t ) > = 0 (1-p_t)>=0 (1−pt)>=0,所以focal loss的损失应该是小于等于标准交叉熵损失。所以,我们分析的重点应该放在难、易分辨样本损失在总损失中所占的比例。
假设有两个 y = 1 y=1 y=1的样本,它们的分类置信度分别为0.9和0.6,取 γ = 2 \gamma=2 γ=2。按照公式计算可得它们的损失分别为: − ( 0.1 ) 2 log ( 0.9 ) -(0.1)^2\log(0.9) −(0.1)2log(0.9)和 − ( 0.4 ) 2 log ( 0.6 ) -(0.4)^2\log(0.6) −(0.4)2log(0.6).
将它们的权重相除: 0.16 0.01 = 16 \frac{0.16}{0.01}=16 0.010.16=16,可得到分类置信度为0.6的样本损失大大增强,分类置信度为0.9的样本损失大大抑制,从而使得损失函数专注于这些难分辨的样本上,这也是函数的中心思想。
focal loss的 α \alpha α变体
之前我们提到了解决类不均衡的平衡交叉熵,那么将平衡交叉熵和focla loss两者混合就可以得到focal loss的 α \alpha α变体,如下:
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) FL(p_t)=-\alpha_t(1-p_t)^\gamma\log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
这个损失函数不光考虑了“容易分辨”,还考虑了“正负样本”的问题。在处理类不均衡问题上,可以发挥出巨大的作用。