一、知识蒸馏简介
知识蒸馏是模型压缩方法中的一个大类,是一种基于“教师-学生网络(teacher-student-network)思想”的训练方法, 其主要思想是拟合教师模型(teacher-model)的泛化性等(如输出概率、中间层特征、激活边界等),而不是一个简简单单的0-1类别标签。
这一技术的理论来自于2015年Hinton发表的一篇论文: Distilling the Knowledge in a Neural Network。知识蒸馏,英文名为Knowledge Distillation, 简称KD,顾名思义,就是将已经训练好的模型包含的知识(“Knowledge”),蒸馏(“Distill”)提取到另一个模型里面去(通常是简单的模型、学生模型)。
知识蒸馏也可以看成是迁移学习的特例,工业界应用得比较广泛的是将BERT模型蒸馏到较少层的transformer, 或者LSTM、CNN等普通模型。BERT模型由于其强大的特征抽取能力,在很多NLP任务上能够达到soft-state-art的效果。 尽管如此,BERT还是有着超参数量大、占用空间大、占用计算资源大、推理时间长等缺点,即便是大公司等也不能随心所欲地使用。 因此,一个简单的想法便是通过BERT等获取一个简单、但性能更好地轻量级算法模型,知识蒸馏无疑是一种有效的方法。 巨大的BERT在很多业务场景下的线上inference都存在很大的性能瓶颈,于是就有了知识蒸馏的用武之地。
常见的使用方式是离线fintune BERT模型,训练一个离线指标明显优于小模型的模型, 然后用fintue好的BERT模型作为指导蒸馏一个小的模型,也可以看做是一个muti-task的训练任务。 最后上线用小模型即可,从而获得性能和效果双赢的局面。
二、知识蒸馏开山之作
知识蒸馏的开山之作是Hinton于2015年提出的论文: Distilling the Knowledge in a Neural Network,旨在把一个大模型或者多个模型ensemble学到的知识迁移到另一个轻量级单模型上,方便部署。简单的说就是用新的小模型去学习大模型的预测结果,改变一下目标函数。
为什么蒸馏可以work?好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让student学习到teacher的泛化能力,理论上得到的结果会比单纯拟合训练数据的student要好。另外,对于分类任务,如果soft targets的熵比hard targets高,那显然student会学习到更多的信息。
其soft targets学习(重点是温度)的主要公式(即softmax前除以一个整数T【一般在1-100间】)是:
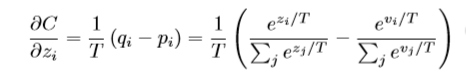
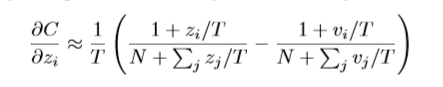
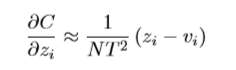
注意:
1. 很简单的方法,即预测标签概率 除以 T,真实标签概率 除以 T,最终loss结果需要 乘以 T的平方。
2. 自己实验中,更适用于半监督学习,以及均衡的、简单的分类问题等。
三、知识蒸馏思维导图
模型蒸馏的开山之作,其基本思路是让student-model学习teacher-model的输出概率分布,其主要是对输出目标的学习(如分类类别的概率分布)。
之后,陆续出现从teacher-model的中间层学习其特征feature的论文,主要是图像吧,这样可以学习到更加丰富的信息。
接着,出现了从teachea-model的激活边界进行学习的论文。
再然后,出现了student-model自学的论文,主要还是对数据集的操作,batch-size内数据的综合,数据增强等。
最后一个,是利用对抗神经网络的经验,将student模型看成生成模型,teachea-model看成判断模型......
借用别人的一张思维导图说明:

四、BERT模型蒸馏到简单网络、Tranformers
BERT蒸馏一般有两种方式,一种是BERT蒸馏到较少网络层的transformers,另外一种是BERT蒸馏到TextCNN、TextRNN等简单网络。
这里我们介绍一篇BERT蒸馏到BILSTM的论文:
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
论文的关键点在于:
1. 适用于少量标注、大批量无标签的数据集,也就是冷启动问题;
2. 同知识蒸馏的开山之作,该论文还是两阶段蒸馏;
3. 损失函数使用的是常规loss + 均方误差loss;
4. 使用[MASK]、N-GRAM等数据增强技术等。
再介绍一篇BERT蒸馏到少层的Transformer的论文:
TINYBERT: DISTILLING BERT FOR NATURAL LANGUAGE UNDERSTANDING
论文的关键点在于:
1、还是两阶段模型蒸馏,teacher-model到student-model层数有一个映射;
2、基于注意力的蒸馏和基于隐状态的蒸馏、基于Embedding的蒸馏;
3、MSE-loss损失函数,3个loss相加
自己实验效果:
1. 某任务二分类(有提升):
最终 (21 epoch) : mean-P R F
原始text-cnn 0.961 0.960 0.96
蒸馏text-cnn 0.97 0.97 0.97
原始Bert-base 0.98 0.98 0.98
2. 某任务11分类(长尾问题,效果不好)
最终 (21 epoch) :mean-P R F
原始text-cnn 0.901 0.872 0.879
蒸馏text-cnn 0.713 0.766 0.738
3. 某任务90分类(长尾问题,效果不好)
最终(21 epoch) :mean-P R F
原始text-cnn 0.819 0.8 0.809
蒸馏text-cnn 0.696 0.593 0.64 (样本最多的类别不能拟合)
原生Bert-base 0.85 0.842 0.846
总结:BERT蒸馏到Text-CNN,Bi-LSTM等简单模型,并不适合完全有监督分类的任务,
最好还是BERT蒸馏到较少层数的transforerm比较好。
五、TextBrewer
5.1 概述:
TextBrewer科大讯飞开源的一个基于PyTorch的、为实现NLP中的**知识蒸馏**任务而设计的工具包,融合并改进了NLP和CV中的多种知识蒸馏技术,提供便捷快速的知识蒸馏框架,用于以较低的性能损失压缩神经网络模型的大小,提升模型的推理速度,减少内存占用。
5.2 主要特点:
**TextBrewer** 为NLP中的知识蒸馏任务设计,融合了多种知识蒸馏技术,提供方便快捷的知识蒸馏框架,主要特点有:
* 模型无关:适用于多种模型结构(主要面向**Transfomer**结构)
* 方便灵活:可自由组合多种蒸馏方法;可方便增加自定义损失等模块
* 非侵入式:无需对教师与学生模型本身结构进行修改
* 支持典型的NLP任务:文本分类、阅读理解、序列标注等
5.3 支持的知识蒸馏技术:
* 软标签与硬标签混合训练
* 动态损失权重调整与蒸馏温度调整
* 多种蒸馏损失函数: hidden states MSE, attention-based loss, neuron selectivity transfer
* 任意构建中间层特征匹配方案
* 多教师知识蒸馏
5.4 自己实验:
某任务90分类数据集,ERNIE【一次推理0.1s】蒸馏到3层transofrmers【一次推理0.02s】
Ernie转Transformer(T3) 蒸馏实验(teacher-epochs-21, student-epochs-48)
lr batch_size loss T dropout Mean-P R F
ernie:
5e-5 16 bce 1 0.1 0.856 0.871 0.863
蒸馏:
5e-5 16 0.9-kl 1 0.1 0.818 0.818 0.818 (3 - layer)
原生transformers-3:
5e-5 16 bce 1 0.1 0.741 0.768 0.754 (3 - layer)
原始text-cnn
1e-3 16 bce 0.819 0.8 0.809
总结:TextBrewer还可以,BERT蒸馏到较少层数的transforerm对于简单的全监督分类还是有一定效果的。
希望对你有所帮助!