背景:
上一篇推荐系统实战中LR模型训练(一) 中完成了LR模型训练的代码部分。本文中将详细讲解数据准备部分,即将文本数据数值化为稀疏矩阵的形式。
- 文本数据:

- 稀疏矩阵:

实现过程:
文本数据格式如下:
用户ID / 物品ID / 收听时长 / 收听的时间点 / 性别 / 年龄段 / 收入 / 籍贯 / 物品名称 / 物品总时长 / 物品标签

LR模型在此处的目的是用户对某个物品(音乐)的点击率,本文中将通过用户对物品(音乐)的收听时长占比来表示用户对物品的喜好程度。本文中抽取的特征分为两类:
- 用户特征(user_feature):性别、年龄段、收入
- 物品特征(item_feature):物品名称
1.从原始数据中抽取相应的特征部分,得到dataset.tmp
代码如下:(1_fromMetaDataTofeatureData.py)
#coding=utf-8
import sysmeta_data = sys.argv[1]with open(meta_data, 'r') as fd:for line in fd:ss = line.strip().split('^A')if len(ss) != 11:continueuser_id = ss[0].strip()item_id = ss[1].strip()watch_time = ss[2].strip()total_time = ss[9].strip()#用户特征gender = ss[4].strip()age = ss[5].strip()income = ss[6].strip()#物品特征item_name = ss[8].strip()user_feature = '^A'.join([user_id, gender, age, income])item_feature = '^A'.join([item_id, item_name])label = round((float(watch_time) / float(total_time)), 1)final_label = '0'if label >= 1.0:final_label = '1'print '^B'.join([final_label, user_feature, item_feature])
得到的dataset.tmp部分数据如下图所示:

2.对dataset.tmp进行操作,数值化用户(user)特征,得到user_feature.data
代码如下:(gen_user_feature.py)
#coding=utf-8
import sysinput_file = sys.argv[1]#性别
# 0:女 1:男#年龄段
# 0-18 = 0
# 19-25 = 1
# 26-35 = 2
# 36-45 = 3
# 46-100 = 4#收入
# 0-2000 = 0
# 2000-5000 = 1
# 5000-10000 = 2
# 10000-20000 = 3
# 20000-100000 = 4user_feature_set = set()
with open(input_file, 'r') as fd:for line in fd:ss = line.strip().split('^B')if len(ss) != 3:continuelabel = ss[0].strip()user_feature = ss[1].strip()item_feature = ss[2].strip()user_feature_set.add(user_feature)for line in user_feature_set:user_id, gender, age, income = line.strip().split('^A')#genderindex = 0if gender == '男':index = 1gender_fea = ':'.join([str(index), '1'])#ageindex = 0if age == '0-18':index = 0elif age == '19-25':index = 1elif age == '26-35':index = 2elif age == '36-45':index = 3else:index = 4#gender偏移index += 2age_fea = ':'.join([str(index), '1'])#incomeindex = 0if income == '0-2000':index = 0elif income == '2000-5000':index = 1elif income == '5000-10000':index = 2elif income == '10000-20000':index = 3else:index = 4#gender和age偏移index += 7income_fea = ':'.join([str(index), '1'])print user_id, gender_fea, age_fea, income_fea
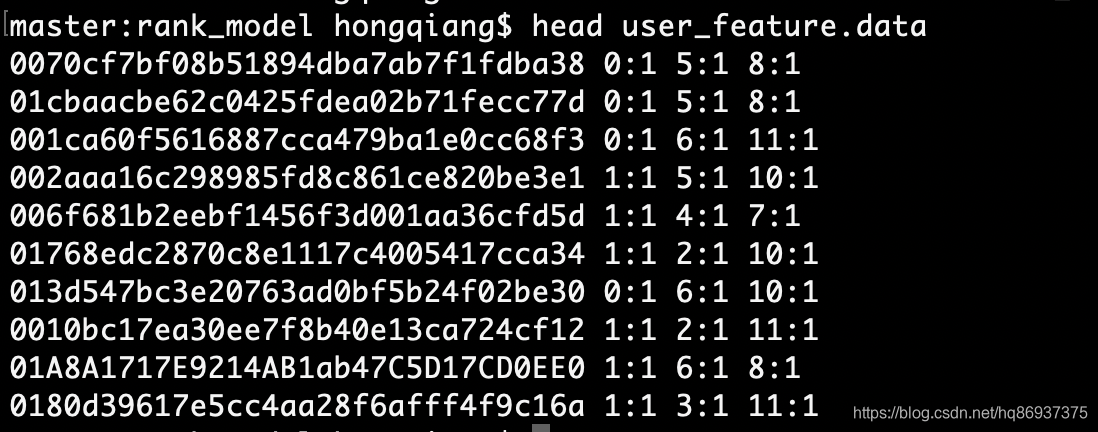
得到的user_feature.data部分数据如下图所示:
3.数值化物品特征
物品的特征主要通过物品名称来抽取,在本文中将运用jieba分词技术进行特征抽取和评分
第一步:物品名称去重,得到item.set
代码如下:(1_gen_item_set.py)
#coding=utf-8
import sysinput_file = sys.argv[1]item_feature_set = set()
with open(input_file, 'r') as fd:for line in fd:ss = line.strip().split('^B')if len(ss) != 3:continuelabel = ss[0].strip()user_feature = ss[1].strip()item_feature = ss[2].strip()item_feature_set.add(item_feature)for line in item_feature_set:item_id, item_name = line.strip().split('^A')print item_name
得到的item.set部分数据如下图所示:
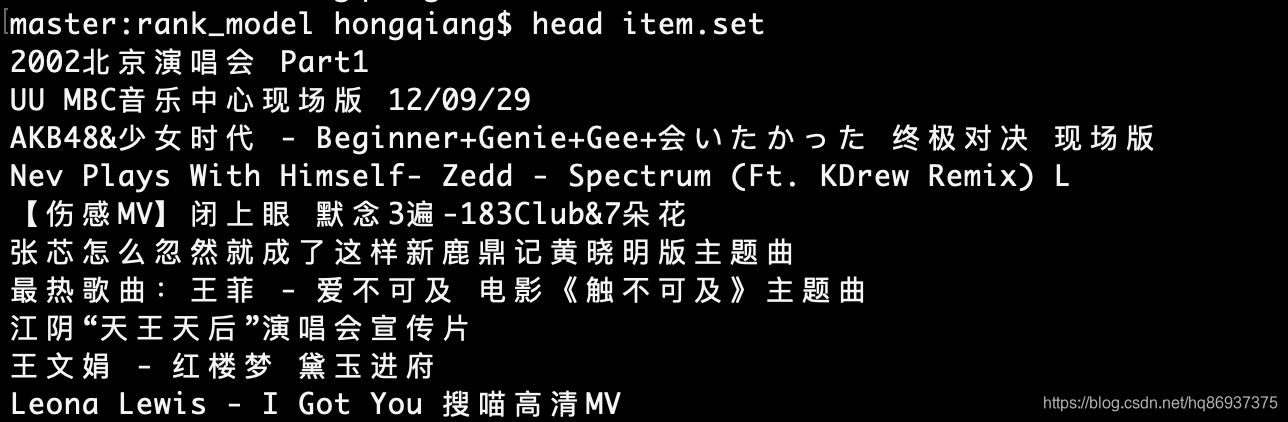
第二步:jieba分词并打分,得到item的token:score列表(item_tokenlist.raw)
代码如下:(2_gen_item_tokenlist.py)
import sys
reload(sys)
sys.setdefaultencoding('utf-8')sys.path.append("./")
import jieba
import jieba.posseg
import jieba.analysein_meta_file = sys.argv[1]with open(in_meta_file, 'r') as fd:for line in fd:name = line.strip()token_score_list = []for x, w in jieba.analyse.extract_tags(name, withWeight=True):token_score_list.append('^A'.join([x, str(w)]))fea = '^B'.join(token_score_list)print ' '.join([name, fea])
得到的item_tokenlist.raw部分数据如下图所示:
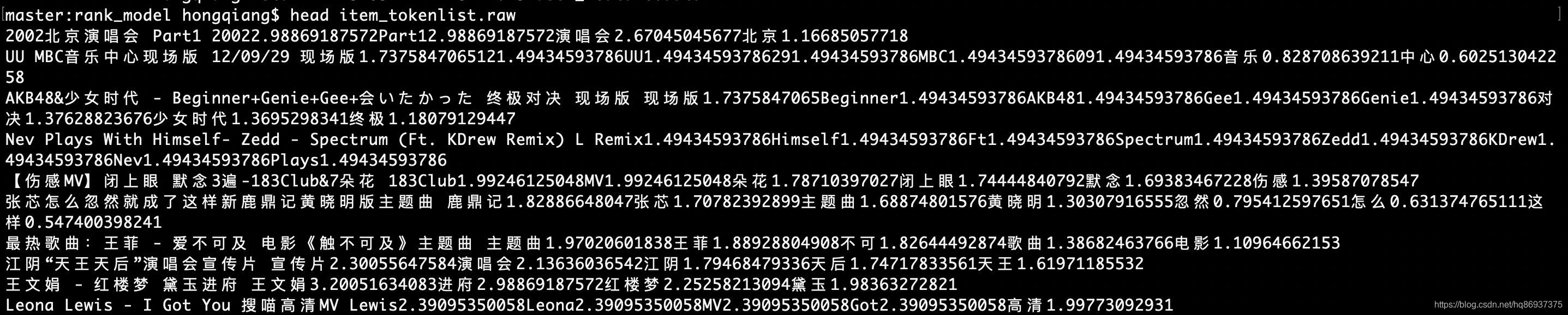
第三步:对分词后的每一个token进行编号,得到tokenid_token.data
代码如下:(3_gen_uniq_token.py)
import sys
reload(sys)
sys.setdefaultencoding('utf-8')sys.path.append("./")
import jieba
import jieba.posseg
import jieba.analysein_meta_file = sys.argv[1]token_set = set()
with open(in_meta_file, 'r') as fd:for line in fd:name = line.strip()for x, w in jieba.analyse.extract_tags(name, withWeight=True):token_set.add(x)token_list = list(token_set)for tu in enumerate(token_list):print ' '.join([str(tu[0]), tu[1]])
得到的tokenid_token.data部分数据如下图所示:
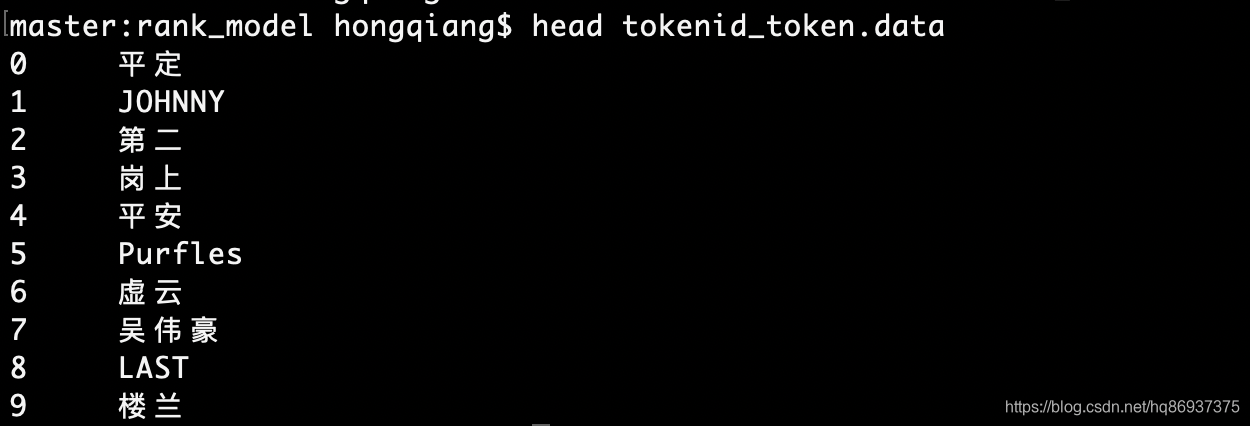
第四步:结合第三步的结果tokenid_token.data将第二步item_tokenlist.raw中的token换成tokenid,进一步得到name_tokenid.fea
代码如下:(4_gen_item_tokenid_format.py)
#coding=utf-8
import sysin_token_dict_file = sys.argv[1]
in_item_tokenlist_file = sys.argv[2]#user_feature特征偏移:gender(2)+age(5)+income(5)
offset = 12token_dict = {}
with open(in_token_dict_file, 'r') as fd:for line in fd:ss = line.strip().split(' ')if len(ss) != 2:continuetokenid, token = sstoken_dict[token] = tokenidwith open(in_item_tokenlist_file, 'r') as fd:for line in fd:ss = line.strip().split(' ')if len(ss) != 2:continuename, ts_list_str = sstmp_list = []for ts in ts_list_str.strip().split('^B'):sss = ts.strip().split('^A')if len(sss) != 2:continuetoken, score = sssif token not in token_dict:continuetokenid = token_dict[token]tmp_list.append(':'.join([str(int(tokenid) + 12), str(round(float(score), 2))]))print '\t'.join([name, ' '.join(tmp_list)])
得到的name_tokenid.fea部分数据如下图所示:

第五步:得到物品名称和物品ID的对应数据name_id.dict
代码如下:(5_gen_itemid_name.py)
#coding=utf-8
import sysraw_input_file = sys.argv[1]item_info_set = set()
with open(raw_input_file, 'r') as fd:for line in fd:ss = line.strip().split('^B')if len(ss) != 3:continuelabel = ss[0].strip()user_info = ss[1].strip()item_info = ss[2].strip()item_info_set.add(item_info)for i_info in item_info_set:itemid, name = i_info.strip().split('^A')print ' '.join([name, itemid])
得到的name_id.dict部分数据如下图所示:
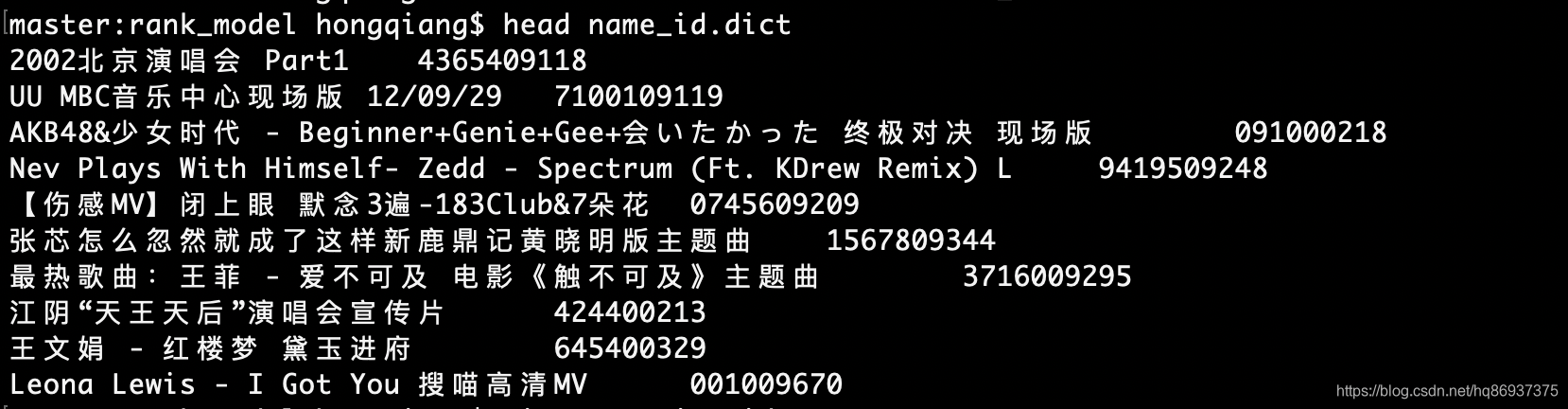
第六步:结合第四步和第五步的数据,得到item_id token_id的对应数据itemid_tokenid_fea.data
代码如下:(6_gen_itemid_tokenidfea.py)
#coding=utf-8
import sysname_id_dict_input_file = sys.argv[1]
name_tokenid_input_file = sys.argv[2]name_id_dict = {}
with open(name_id_dict_input_file, 'r') as fd:for line in fd:ss = line.strip().split(' ')if len(ss) != 2:continuename = ss[0].strip()itemid = ss[1].strip()name_id_dict[name] = itemidwith open(name_tokenid_input_file, 'r') as fd:for line in fd:ss = line.strip().split(' ')if len(ss) != 2:continuename = ss[0].strip()tokenid_fea = ss[1].strip()if name not in name_id_dict:continueitemid = name_id_dict[name]print '\t'.join([itemid, tokenid_fea])
自此终于得到数值化后的物品特征数据itemid_tokenid_fea.data,如下图所示:
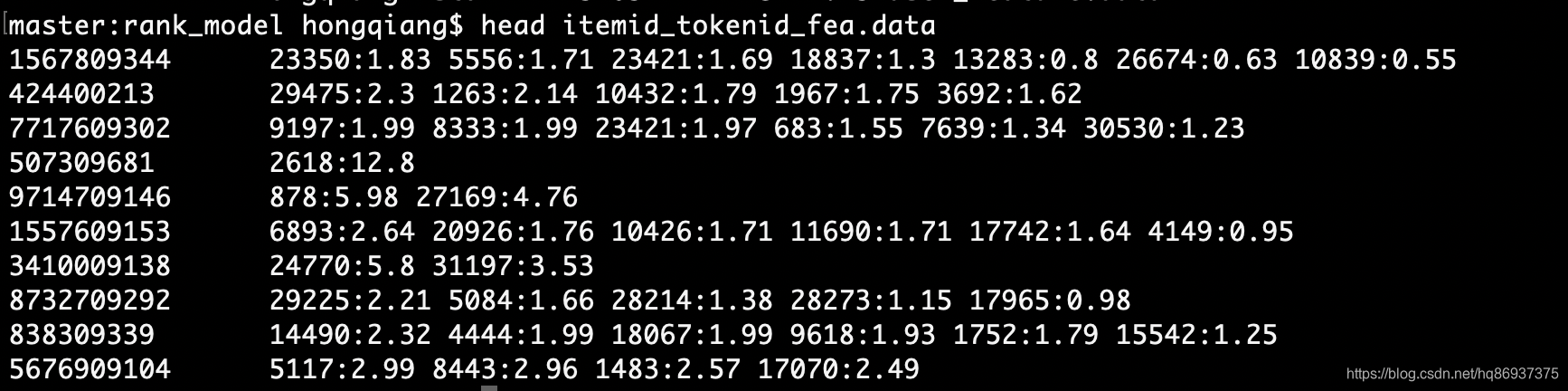
4.将数值化后的用户特征数据和物品特征数据组合起来,得到最终的训练数据dataset.final
代码如下:(final_merge_feature.py)
import sysuser_fea_file = sys.argv[1]
item_fea_file = sys.argv[2]
base_file = sys.argv[3]user_dict = {}
with open(user_fea_file, 'r') as fd:for line in fd:ss = line.strip().split(' ')if len(ss) != 4:continueuserid, gender_fea, age_fea, income_fea = ssuser_dict[userid] = ' '.join([gender_fea, age_fea, income_fea])item_dict = {}
with open(item_fea_file, 'r') as fd:for line in fd:ss = line.strip().split('\t')if len(ss) != 2:continueitemid, item_fea = ssitem_dict[itemid] = item_feawith open(base_file, 'r') as fd:for line in fd:ss = line.strip().split('^B')if len(ss) != 3:continuelabel, user_info, item_info = ssuserid = user_info.strip().split('^A')[0]itemid = item_info.strip().split('^A')[0]if userid not in user_dict:continueif itemid not in item_dict:continueprint ' '.join([label, user_dict[userid], item_dict[itemid]])
最终得到的训练集数据dataset.final如下图所示:
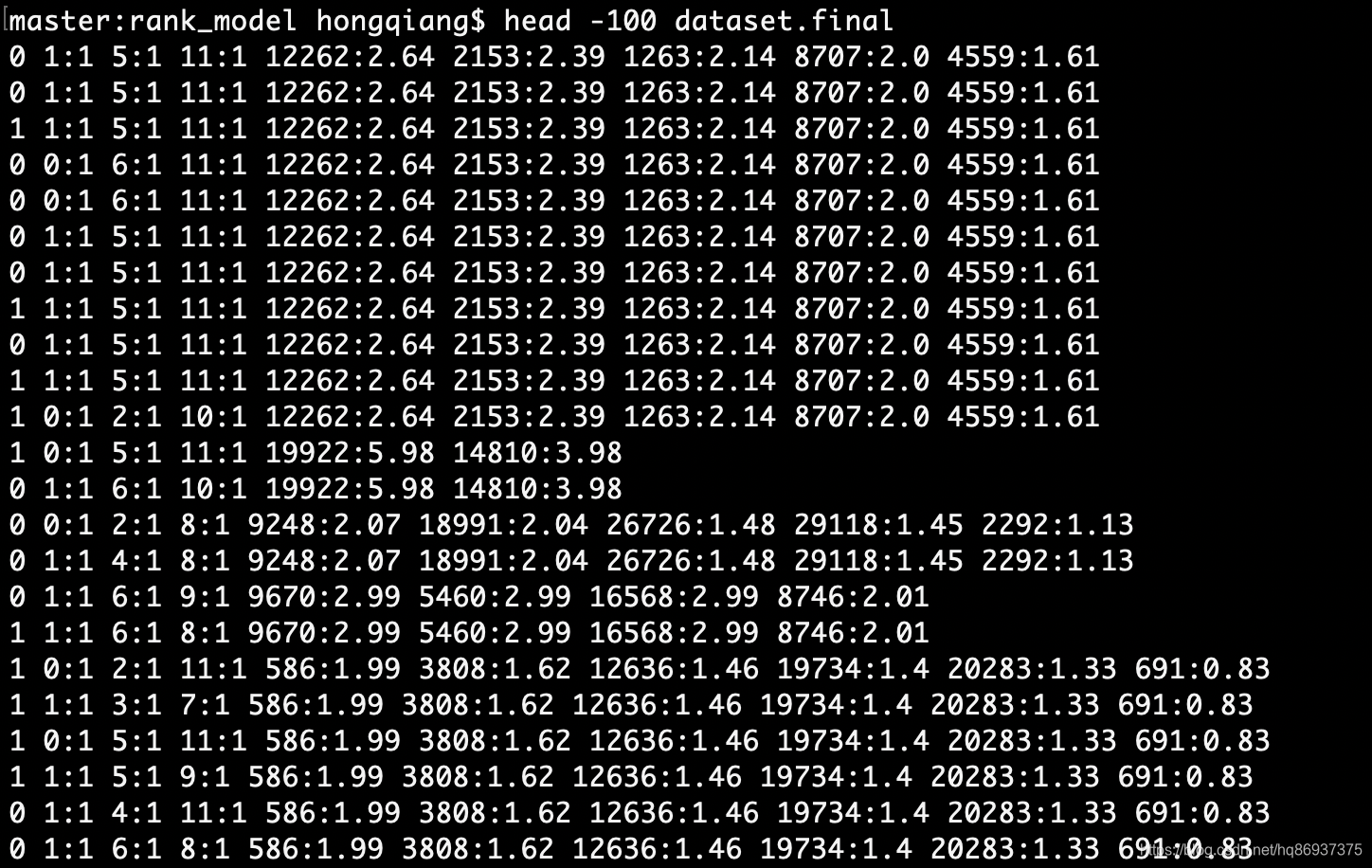
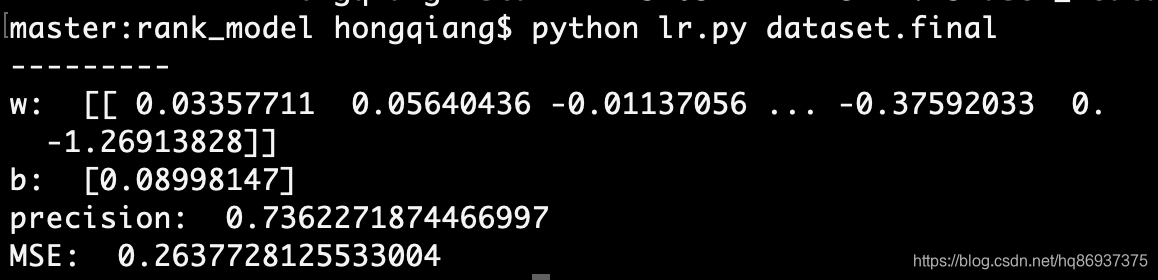
自此完成了将文本数据数值化为稀疏矩阵工作,最终得到的数据dataset.final可以直接输入到推荐系统实战中LR模型训练(一)LR模型中进行训练,训练结果如下图所示: