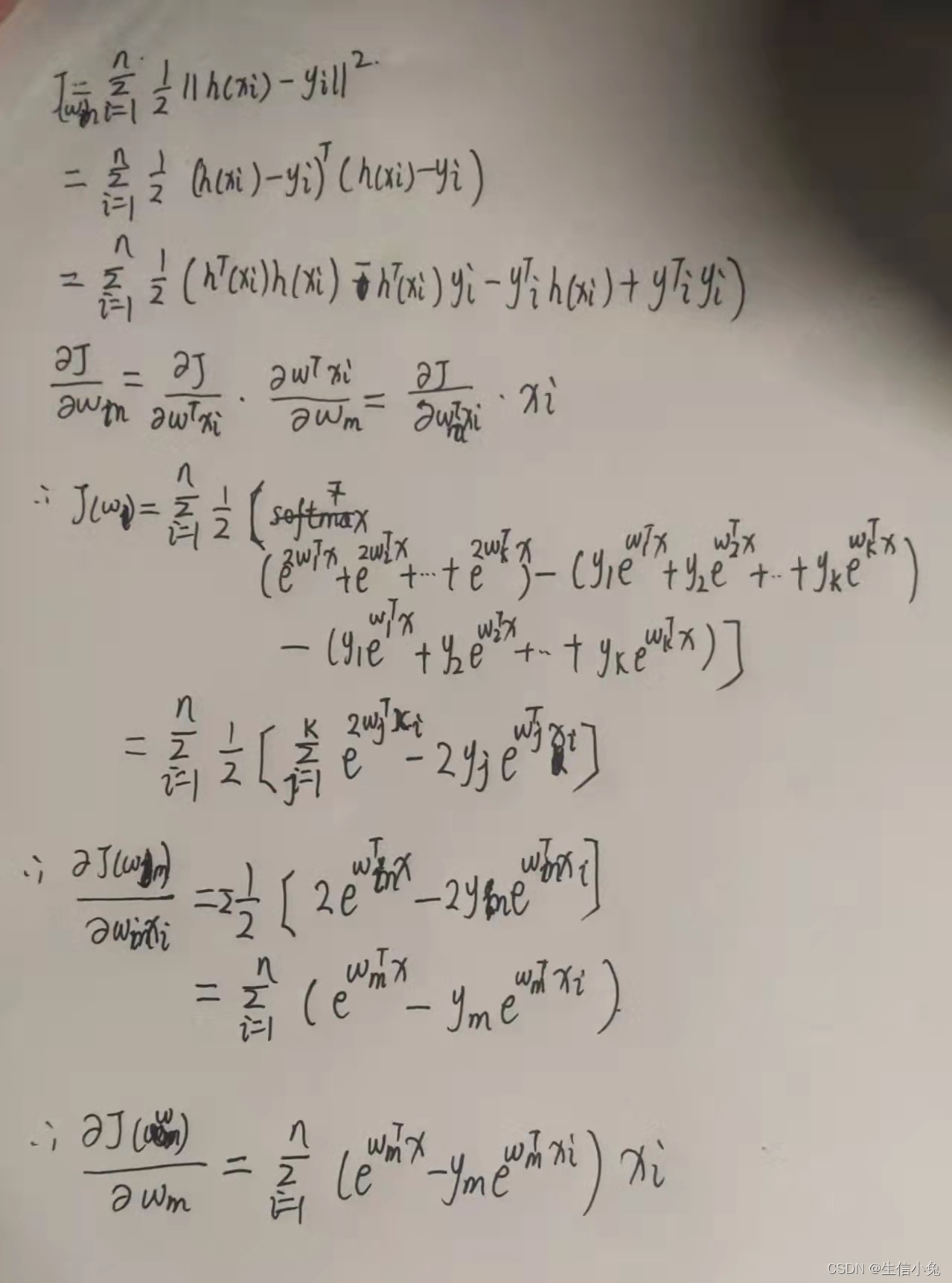目录
- 前言
- 从对数变换到逻辑回归
- 二项逻辑回归模型
- 逻辑回归模型的应用
- 逻辑回归模型的评价
- 实践案例
前言
从这一期开始,我们准备介绍一系列经典机器学习算法模型,主要包括逻辑回归,支持向量机,决策树,因子分析,主成分分析,K-Means聚类,多元线性回归,时间序列,关联规则,朴素贝叶斯,隐式马尔可夫,协同过滤,随机森林,XGBoost,LightGBM等,一般会涵盖算法模型的引入背景,算法模型依赖的数学原理,算法模型的应用范围,算法模型的优缺点及改进建议,工程实践案例等。既适合刚入门机器学习的新手,也适合有一定基础想要进一步掌握算法模型核心要义的读者,其中不免会涵盖许多数学符号,公式以及推导过程,如果你觉得晦涩难懂,可以来"三行科创"微信交流群和大家一起讨论交流。
从对数变换到逻辑回归
逻辑回归是最常见的一种用于二分类的算法模型,由于其数学原理简单易懂,作用高效,实际应用非常广泛,虽然带回归二字,实则是分类模型,下面从logit变换开始。
我们在研究某一结果 y y y与一系列因素 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn)之间的关系的时候,最直白的想法是建立因变量和自变量的多元线性关系模型
y = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n y=\theta_0+\theta_1x_1+\theta_2x_2+\cdots +\theta_nx_n y=θ0+θ1x1+θ2x2+⋯+θnxn
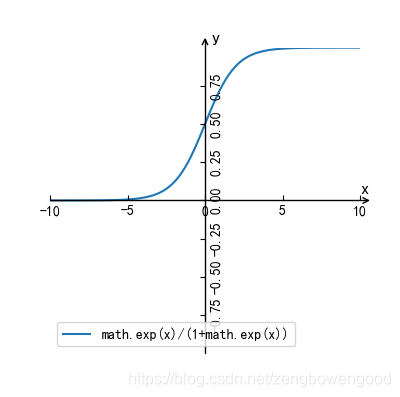
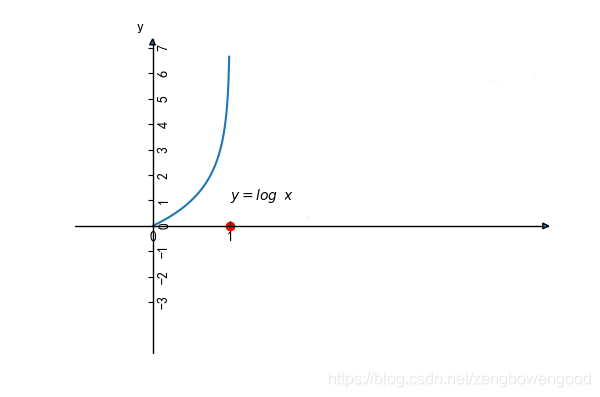
其中 ( θ 0 , θ 1 , ⋯ , θ n ) (\theta_0,\theta_1,\cdots,\theta_n) (θ0,θ1,⋯,θn) 为模型的参数,如果因变量是数值型的话,可以解释成某某因素 x i x_i xi ( 0 ≤ i ≤ n ) (0\leq i \leq n) (0≤i≤n)变化了多少导致结果 y y y 发生了多少变化,如果因变量 y y y 是用来刻画结果是否(0-1)发生?或者更一般的来刻画特定结果发生的概率(0~1)呢?这时候因素 x i x_i xi ( 0 ≤ i ≤ n ) (0\leq i \leq n) (0≤i≤n)变化导致结果 y y y 的变化恐怕微乎其微,有时候甚至忽略不计。然而现实生活中,我们知道某些关键因素会直接导致某一结果的发生,如亚马逊雨林一只蝴蝶偶尔振动翅膀,就会引起两周后美国德克萨斯州的一场龙卷风。于是,我们需要让不显著的线性关系变得显著,使得模型能够很好解释随着因素的变化,结果也会发生显著的变化,这时候,人们想到了对数(logit)变换,下图是对数函数图像

从对数函数的图像来看,其在 ( 0 , 1 ) (0,1) (0,1)之间的因变量的变化是很迅速的,也就是说自变量的微小变化会导致因变量的巨大变化,这就符合了之前想要的效果。于是,对因变量进行对数变换,右边依然保持线性关系,有下面式子
l o g ( y ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n log(y)=\theta_0+\theta_1x_1+\theta_2x_2+\cdots +\theta_nx_n log(y)=θ0+θ1x1+θ2x2+⋯+θnxn
虽然上式解决了因变量随着自变量变化的敏感性问题,同时也约束了 y y y 的取值范围在 ( 0 , + ∞ ) (0,+\infty) (0,+∞)。我们知道概率是用来描述某件事发生的可能性,一件事情发生与否,更应该是调和对称的,也就是说该事件发生与不发生有对立性,结果可以走向必然发生(发生概率为1),也可以走向必然不发生(发生概率为0),概率的取值范围为 [ 0 , 1 ] [0,1] [0,1],而等式左边 y y y 的取值范围是 ( 0 , + ∞ ) (0,+\infty) (0,+∞),所以需要进一步压缩,又引进了几率。
几率(odd)是指事件发生的概率与不发生的概率之比,假设事件 A 发生的概率为 p p p,不发生的概率为 1 − p 1-p 1−p,那么事件 A 的几率为
o d d ( A ) = p 1 − p odd(A)=\frac{p}{1-p} odd(A)=1−pp
几率恰好反应了某一事件两个对立面,具有很好的对称性,下面我们再来看一下概率和几率的关系
首先,我们看到概率从0.01不断增大到 0.99,几率也从0.01随之不断变大到99,两者具有很好的正相关系,我们再对 p p p 向两端取极限有
lim p → 0 + ( p 1 − p ) = 0 \lim\limits _ {p \to 0^+}(\frac{p}{1-p})=0 p→0+lim(1−pp)=0
lim p → 1 − ( p 1 − p ) = + ∞ \lim\limits _ {p \to 1^-}(\frac{p}{1-p})=+\infty p→1−lim(1−pp)=+∞
于是,几率的取值范围就在 ( 0 , + ∞ ) (0, +\infty) (0,+∞),这就符合我们之前的因变量取值范围的假设。
正因为概率和几率有如此密切对等关系,于是想能不能用几率来代替概率刻画结果发生的可能性大小,这样既能满足结果对影响因素的敏感性,又能满足发生与否的对称性 ,便有了下面式子
l o g ( p 1 − p ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n log(\frac{p}{1-p}) =\theta_0+ \theta_1x_1+\theta_2x_2+\cdots +\theta_nx_n log(1−pp)=θ0+θ1x1+θ2x2+⋯+θnxn
现在,我们稍微改一下,让等式左边对数变成自然对数 l n = l o g e ln=log_e ln=loge,等式右边改成向量乘积形式,便有
l n ( p 1 − p ) = θ X ln(\frac{p}{1-p})=\theta X ln(1−pp)=θX
其中 θ = ( θ 0 , θ 1 , ⋯ , θ n ) \theta=(\theta_0,\theta_1,\cdots,\theta_n) θ=(θ0,θ1,⋯,θn), X = ( 1 , x 1 , x 2 , ⋯ , x n ) T X=(1,x_1,x_2,\cdots,x_n)^T X=(1,x1,x2,⋯,xn)T,我们解得
p = e θ X 1 + e θ X p=\frac{e^{\theta X}} {1+ e^{\theta X}} p=1+eθXeθX
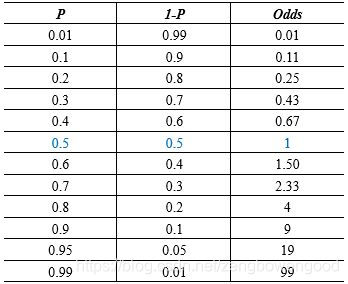
其中 e e e 是自然常数,保留5位小数是2.71828。这就是我们常见的逻辑模型表达式,作出其函数图像如下
我们看到逻辑模型的函数图像是一条S型曲线,又名sigmoid曲线,以 ( 0 , 0.5 ) (0,0.5) (0,0.5) 为对称中心,随着自变量 x x x 不断增大,其函数值不断增大接近1,随自变量 x x x 不断减小,其函数值不断降低接近0,函数的取值范围在 ( 0 , 1 ) (0,1) (0,1) 之间,且函数曲线在中心位置变化速度最快,在两端的变化速率最慢。
从上面的操作,我们可以看到逻辑回归模型从最初的线性回归模型基础上对因变量进行 对数变换,使得因变量对自变量显著,同时约束因变量取值范围为0到 + ∞ +\infty +∞,然后用几率表示概率,最后求出概率关于自变量的表达式,把线性回归的结果压缩在 ( 0 , 1 ) (0,1) (0,1) 范围内,这样最后计算出的结果是一个0到1之间的概率值,表示某事件发生的可能性大小,可以做概率建模,这也是为什么逻辑回归叫逻辑回归,而不叫逻辑分类了。
二项逻辑回归模型
既然逻辑回归把输出结果压缩到连续的区间 ( 0 , 1 ) (0,1) (0,1),而不是离散的 0 或者1,然后我们可以取定一个阈值,通常以0.5为阈值,通过对比输出结果与阈值的大小关系而定,如果计算出来的概率大于等于0.5,则将结果归为一类 (1),如果计算出来的概率小于0.5,则将结果归为另一类 (0),用分段函数写出来便是
y = { 1 , p >= 0.5 0 , p < 0.5 y= \begin{cases} 1,&\text{p >= 0.5} \\ 0, & \text{p < 0.5} \end{cases} y={1,0,p >= 0.5p < 0.5
这样逻辑回归就可以用来进行2分类了,在本文中,不特别指出,均指二项逻辑回归,假设数据结构如下
| 样本 | x 1 x_1 x1 | x 2 x_2 x2 | … | x n x_n xn | y y y |
|---|---|---|---|---|---|
| 1 | x 11 x_{11} x11 | x 12 x_{12} x12 | … | x 1 n x_{1n} x1n | y 1 y_1 y1 |
| 2 | x 21 x_{21} x21 | x 22 x_{22} x22 | … | x 2 n x_{2n} x2n | y 2 y_2 y2 |
| ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | … | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ |
| m | x m 1 x_{m1} xm1 | x m 2 x_{m2} xm2 | … | x m n x_{mn} xmn | y m y_m ym |
其中 m m m表示样本个数, n n n表示影响因素的个数, y i ( 1 ≤ i ≤ m ) y_i (1\leq i \leq m) yi(1≤i≤m) 取 0 或者 1。现在我们结合数据,利用条件概率分布模型给出基于概率的二项逻辑回归模型如下
p ( y = 1 ∣ X ; θ ) = e θ X 1 + e θ X p(y=1|X;\theta)=\frac{e^{\theta X}}{1+e^{\theta X}} p(y=1∣X;θ)=1+eθXeθX
p ( y = 0 ∣ X ; θ ) = 1 1 + e θ X p(y=0|X;\theta)=\frac{1}{1+e^{\theta X}} p(y=0∣X;θ)=1+eθX1
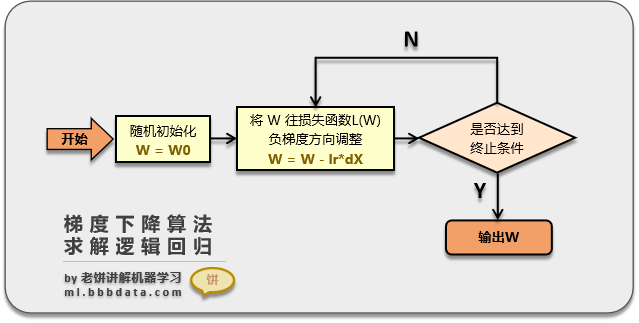
其中, y y y 表示因变量所属的类别, X X X 表示自变量, θ \theta θ 为模型待求的参数,模型解释为在特定的因素( X ; θ X; \theta X;θ)下,模型结果取1的概率和取0的概率。模型有了,接下来就需要进行机器训练,而怎么来给训练一种恰当反馈呢?答案就是损失函数,通过损失函数来评估模型学习的好坏和改进机制。
由前面阈值的取定原则,我们知道相当于我们用一个类别值代替概率值,而类别值是sigmoid 函数的两个最值,概率不可能时时刻刻都取到最值,这势必会造成误差,我们把这种误差称为损失,为了给出损失函数表达式,我们假设模型第 i i i 个样本所求的概率值为 p i p_i pi,而真实类别值可能是 0 或者 1。
当类别真实值是 1 的情况下,所求的概率值 p i p_i pi 越小,越接近0,被划为类别 0 的可能性越大,被划为类别 1 的可能性越小,导致的损失越大。反之,所求的概率值 p i p_i pi 越大,越接近1,被划为类别 1 的可能性越大,被划为类别 0 的可能性越小,导致的损失越小。我们用下面的函数来描述这种变化关系
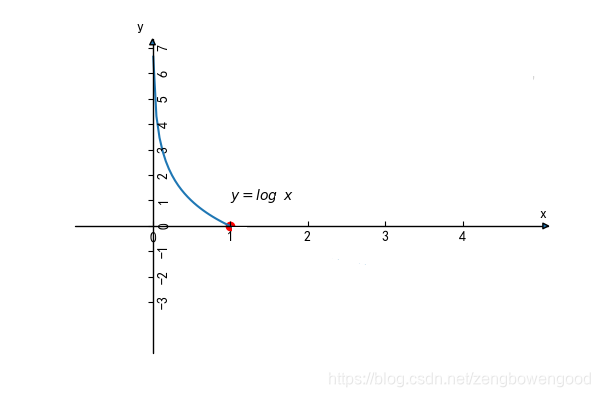
− l o g p i -log p_i −logpi
其中 p i ∈ ( 0 , 1 ) p_i\in(0,1) pi∈(0,1) ,其图像大致如下
当类别真实值是0的情况下,所求的概率值 p i p_i pi 越大,越接近1,其结果的类别判定更偏向于1,导致的损失越大。反之,所求的概率值 p i p_i pi 越小,越接近0,其结果的类别判断更偏向于 0,导致的损失越小。我们用下面的函数来描述这种变化关系
− l o g ( 1 − p i ) -log(1-p_i) −log(1−pi)
现在就要把两种情况结合起来,就不需要分真实值是 1 还是 0 两种情况讨论,求出其期望值,做成一个交叉熵(cross entropy)的整体损失函数如下
c o s t i = − y i l o g ( p i ) − ( 1 − y i ) l o g ( 1 − p i ) cost_i = -y_ilog(p_i)-(1-y_i)log(1-p_i) costi=−yilog(pi)−(1−yi)log(1−pi)
其中 y i y_i yi 表示第 i i i 个样本的真实值(取0或者1), p i p_i pi 是根据模型计算出来的概率值,当 y i = 1 y_i=1 yi=1 时, c o s t i = − l o g ( p i ) cost_i= -log(p_i) costi=−log(pi),当 y i = 0 y_i=0 yi=0时, c o s t i = − l o g ( 1 − p i ) cost_i = -log(1-p_i) costi=−log(1−pi),这符合前面两种情况。
假设现在有 m m m 个样本,总体的损失函数为
C o s t = ∑ i = 1 m c o s t i = ∑ i = 1 m [ − y i l o g ( p i ) − ( 1 − y i ) l o g ( 1 − p i ) ] \begin{aligned} Cost &= \sum\limits_{i=1}^m cost_i \\ &=\sum\limits_{i=1}^m[-y_ilog(p_i)-(1-y_i)log(1-p_i)]\\ \end{aligned} Cost=i=1∑mcosti=i=1∑m[−yilog(pi)−(1−yi)log(1−pi)]
代入 p i = e θ X 1 + e θ X p_i=\frac{e^{\theta X}}{1+e^{\theta X}} pi=1+eθXeθX
C o s t = ∑ i = 1 m [ − y i l o g ( e θ X 1 + e θ X ) − ( 1 − y i ) l o g ( 1 − e θ X 1 + e θ X ) ] (1) \begin{aligned} Cost &=\sum\limits_{i=1}^m[-y_ilog(\frac{e^{\theta X}}{1+e^{\theta X}})-(1-y_i)log(1-\frac{e^{\theta X}}{1+e^{\theta X}})] \end{aligned} \tag{1} Cost=i=1∑m[−yilog(1+eθXeθX)−(1−yi)log(1−1+eθXeθX)](1)
上式就是二项逻辑回归的损失函数,是一个关于参数 θ \theta θ 和 X X X的二元函数,也叫对数似然函数,现在问题转化为以对数似然函数为目标函数的最优化问题,其中 θ \theta θ 为模型待求的参数,为了求参数 θ \theta θ ,可以对目标函数求关于 θ \theta θ的偏导数,记
L ( X ∣ θ ) = C o s t = ∑ i = 1 m [ − y l o g ( e θ X 1 + e θ X ) − ( 1 − y ) l o g ( 1 − e θ X 1 + e θ X ) ] \mathcal{L}(X|\theta)=Cost =\sum\limits_{i=1}^m[-ylog(\frac{e^{\theta X}}{1+e^{\theta X}})-(1-y)log(1-\frac{e^{\theta X}}{1+e^{\theta X}})] L(X∣θ)=Cost=i=1∑m[−ylog(1+eθXeθX)−(1−y)log(1−1+eθXeθX)]
对 L ( X ∣ θ ) \mathcal{L} (X|\theta) L(X∣θ) 求关于 θ \theta θ 的偏导,主要是里面对数函数关于 θ \theta θ 的偏导数求解
∂ L ( X ∣ θ ) ∂ θ = ∂ { ∑ i = 1 m [ − y i l o g ( e θ X 1 + e θ X ) − ( 1 − y i ) l o g ( 1 − e θ X 1 + e θ X ) ] } ∂ θ = ∑ i = 1 m [ ( − y i ) ∂ l o g ( e θ X 1 + e θ X ) ∂ θ − ( 1 − y i ) ∂ l o g ( 1 − e θ X 1 + e θ X ) ∂ θ ] = ∑ i = 1 m [ ( − y i ) c X 1 + e θ X − ( 1 − y i ) ( − c X e θ X 1 + e θ X ) ] \begin{aligned} &\frac{\partial \mathcal{L}(X|\theta)}{ \partial \theta} \\&=\frac{ \partial \{\sum\limits_{i=1}^m[-y_ilog(\frac{e^{\theta X}}{1+e^{\theta X}})-(1-y_i)log(1-\frac{e^{\theta X}}{1+e^{\theta X}})]\}}{\partial \theta}\\ &= \sum\limits_{i=1}^m[(-y_i)\frac{\partial log(\frac{e^{\theta X}}{1+e^{\theta X}})}{\partial \theta}-(1-y_i)\frac{\partial log(1-\frac{e^{\theta X}}{1+e^{\theta X}})}{\partial \theta}]\\ &= \sum\limits_{i=1}^m [ (-y_i)\frac{cX}{1+e^{\theta X}}-(1-y_i)(-\frac{cXe^{\theta X}}{1+e^{\theta X}})] \end{aligned} ∂θ∂L(X∣θ)=∂θ∂{i=1∑m[−yilog(1+eθXeθX)−(1−yi)log(1−1+eθXeθX)]}=i=1∑m[(−yi)∂θ∂log(1+eθXeθX)−(1−yi)∂θ∂log(1−1+eθXeθX)]=i=1∑m[(−yi)1+eθXcX−(1−yi)(−1+eθXcXeθX)]
其中 c = l n a c=ln a c=lna, a a a 为对数底数,令 ∂ L ( ( X ∣ θ ) ∂ θ = 0 \frac{\partial \mathcal{L}((X|\theta)}{ \partial \theta}=0 ∂θ∂L((X∣θ)=0,求出 θ \theta θ 值,然后代入模型便得到二项逻辑回归模型方程,假设 θ ^ \hat{\theta} θ^ 是上式子所求的值,那么原二项逻辑回归模型方程为
p ( y = 1 ∣ X , θ ^ ) = e θ ^ X 1 + e θ ^ X p(y=1|X,\hat{\theta})=\frac{e^{\hat{\theta} X}}{1+e^{\hat{\theta} X}} p(y=1∣X,θ^)=1+eθ^Xeθ^X
p ( y = 0 ∣ X , θ ^ ) = 1 1 + e θ ^ X p(y=0|X,\hat{\theta})=\frac{1}{1+e^{\hat{\theta} X}} p(y=0∣X,θ^)=1+eθ^X1
逻辑回归模型的应用
既然逻辑回归模型主要用来二分类,那么凡是涉及到二分类的场景都有逻辑回归的用武之地,同时,我们还可以用逻辑回归模型预测某件事情的发生概率,我们常见的逻辑回归模型的应用场景有
(1) 在P2P,汽车金融等领域,根据申请人的提供的资料,预测其违约的可能性大小,进而决定是否给其贷款。
(2) 电商平台根据用户购买记录预测用户下一次是否会购买某件商品。
(3) 天涯,bbs,微博,豆瓣短评等舆论平台做情感分类器。如根据某网友对某些特定主题的历史评论数据,预测其下次对某类型的主题是否会给出正面的评论。
(4) 在医疗领域,根据病人症状,预测其肿瘤是良性的还是恶性的。
(5) 根据CT,流行病学,旅行史,检测试剂结果等特点预测某位疑似病人是否真感染新型冠状病毒。
(6) 在交通物流领域,预测某趟运输是否会拉货。
逻辑回归模型的评价
从逻辑回归模型的数学原理,以及就阈值取定的时候一刀切的做法,我们能够根据逻辑回归的这些特点给出模型优缺点评价
优点:
- 原理简单,模型清晰,操作高效,背后的概率的推导过程经得住推敲,在研究中,通常以逻辑回归模型作为基准,再尝试使用更复杂的算法,可以在大数据场景中使用;
- 使用online learning的方式更新轻松更新参数,不需要重新训练整个模型;
- 基于概率建模,输出值落在0到1之间,并且有概率意义;
- 求出来的参数 θ i \theta_i θi 代表每个因素对输出结果的影响,可解释性强;
- 解决过拟合的方法很多,如L1、L2正则化,L2正则化就可以解决多重共线性问题;
缺点:
- 对数据依赖性强,很多时候需要做特征工程,且主要用来解决线性可分问题;
- 因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况,对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转,正号变负号;
- 对数变换过程是非线性的,在两端随着变化率微乎其微,而中间的变化很大,很敏感。 导致很多区间的变量变化对目标概率的影响没有区分度,很难确定阀值;
- 当特征空间很大时,性能不好;
- 容易欠拟合,精度不高;
实践案例
逻辑回归算法模型的理论学了一通,是时候上一道硬菜,来一个实践案例好下饭,我们利用吴恩达机器学习系列课程里面的一个案例来展开。
本次实践目的是利用下列数据训练出逻辑回归算法模型并给出模型的评估,从ex2data1的数据来看,这份数据是没有表头的,一共100个样本,前2列是特征值表示某位申请者两门课程的评分,第三列是标签列表示该申请者是否被接收,其中1表示被接收,0表示不被接收。
针对低维(小于等于3)数据我们可以进行可视化处理,这样可以让原数据的有些分布特征看起来更直观
def visualization(): #数据可视化plt.figure(figsize = (6,4)) #新建画布plt.scatter(pos[:,1], pos[:, 2], marker='+', label='admitted') #正性散点plt.scatter(neg[:,1], neg[:,2], marker='x', label = 'unadmitted') #负性散点plt.xlabel("exam1_score")plt.ylabel("exam2_score")plt.pause(2)

通过数据可视化,我们可以很直白的看到申请者是否被接收大致可以分为2类,分界还是很清晰的,我们可以试着手动画一条直线将其分开

同时,我们可以利用前面的公式(1)把损失函数写出来
def cost(mytheta, myx, myy): #定义损失函数return np.dot(-myy, np.log(np.exp(np.dot(myx, mytheta))/(1+np.exp(np.dot(myx, mytheta)))))+\-np.dot((1-myy), np.log(1-np.exp(np.dot(myx, mytheta))/(1+np.exp(np.dot(myx, mytheta)))))
损失函数里面的mytheta是我们要求解的参数,这时可以调用scipy.optimize模块中的fmin函数进行求解
def optima(mytheta, myx, myy): #求最优解参数result = fmin(cost, x0 = mytheta, args = (myx, myy), maxiter = 500, full_output= True)return result
假设我们求出来的参数为 θ 0 , θ 1 , θ 2 \theta_0, \theta_1, \theta_2 θ0,θ1,θ2,从而可以把边界函数表示出来
θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 = 0 \theta_0+\theta_1*x_1+\theta_2*x_2 = 0 θ0+θ1∗x1+θ2∗x2=0
学过线性规划的同学知道,这条直线可以将一个平面一分为二,大于0的划分为一边,小于0的划分为另一边。

把边界函数的参数求解出来其实二项逻辑回归算法模型算是初步搭建完成了,因为这时候任给一个样本输入进来就可以判定其到底落于边界函数图形的左半边还是右半边。但一个优秀的算法模型不能仅仅做出来就算完事,还需要对其进行评估和优化,这时候混肴矩阵和ROC曲线就派上用场了。


对比图7和图6,图7是通过数据学到的边界函数,而图6是我们随手画的分界线,两者有几分相似,说明通过逻辑回归算法模型达到我们最初的预期效果,也说明前期的数据可视化为我们提供很多有意义的线索,然而仔细观察图7,有些不被接收的点落入被接收的类里面,有些被接收的点落入不被接收的类里面,出现了串类,我们知道平面里两点确定一条直线,在这个实例中,显然利用直线作为分类边界肯定不能分干净,需要寻求曲线边界我们试着手动画一条曲线把中间那些容易混肴的点也尽可能的画到一边去

考虑到原始特征只有exam1_score和exam2_score2一共2个,为了后续表述方便起见,简记为 x 1 , x 2 x_1,x_2 x1,x2,想要制作曲线边界可以考虑利用特征映射对特征进行扩充,具体做法是利用 x 1 , x 2 x_1,x_2 x1,x2生成 x 1 、 x 2 、 x 1 x 2 、 x 1 2 、 x 2 2 、 x 1 2 x 2 、 . . . 、 x 1 n 、 x 2 n x_1、x_2、x_1x_2、x_1^2、x_2^2、x_1^2x_2、... 、x_1^n、x_2^n x1、x2、x1x2、x12、x22、x12x2、...、x1n、x2n,因为更多的特征进行逻辑回归时,得到的边界曲线更具表现力。为了方便,我们设定其中的n=2,此时的决策函数如下,到时候求出来的参数也会有6个
θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 + θ 3 x 1 x 2 + θ 4 x 1 2 + θ 5 x 2 2 \theta_0+\theta_1*x_1+\theta_2*x_2+\theta_3x_1x_2+\theta_4x_1^2+\theta_5x_2^2 θ0+θ1∗x1+θ2∗x2+θ3x1x2+θ4x12+θ5x22
这时候有读者就会问,你这由原来2个特征一下构造出来5个特征,结果还能可视化吗?高维空间直接可视化肯定是不行的,但是可以将高维的曲面投影到二维平面画出其对应的等值线。
def project(mytheta): #特征映射后投影边界plt.figure(figsize=(6, 4))visualization()xs = np.linspace(25, 105, 100)ys = np.linspace(25, 105, 100)zs = np.zeros((len(xs), len(ys)))for i in range(len(xs)):for j in range(len(ys)):fij = fmap(np.array([xs[i]]), np.array([ys[j]]))zs[i][j] = np.dot(fij, mytheta)zs = zs.transpose()u, v = np.meshgrid(xs, ys)plt.contour(xs, ys, zs, [0])plt.title("Decision boundary")plt.pause(5)

至此,关于逻辑回归算法模型我们除了正则化没讨论外几乎该讨论的都讨论了,其中在算法模型评估环节涉及到混肴矩阵,ROC曲线等概念后面我们会专门出一期博文,敬请期待。
附所有代码
# -*- encoding: utf-8 -*-
'''
@Project : logistic_regression
@Desc : 利用逻辑回归算法模型预测学生是否会被接收
@Time : 2022/03/26 13:43:53
@Author : 帅帅de三叔,zengbowengood@163.com
'''
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import fmin
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_curve, aucdata = pd.read_csv("D:\项目\机器学习\吴恩达机器学习课件\CourseraML\ex2\data\ex2data1.txt", header = None, names=["exam1_score", "exam2_score", "label"]) #读取数据
X = np.array(data[["exam1_score", "exam2_score"]]) #自变量
y = data["label"] #因变量
X = np.insert(X, 0, 1, axis = 1) #插入虚拟变量,纳入常数项
m = len(data) #样本量
pos = np.array([X[i] for i in range(len(X)) if y[i]==1]) #正性特征
neg = np.array([X[i] for i in range(len(X)) if y[i]==0]) #负性特征def visualization(): #可视化#plt.figure(figsize = (6,4)) #新建画布plt.scatter(pos[:,1], pos[:, 2], marker='+', label='admitted') #正性散点plt.scatter(neg[:,1], neg[:,2], marker='x', label = 'unadmitted') #负性散点plt.xlabel("exam1_score")plt.ylabel("exam2_score")plt.legend()plt.pause(2)def cost(mytheta, myx, myy): #损失函数return np.dot(-myy, np.log(np.exp(np.dot(myx, mytheta))/(1+np.exp(np.dot(myx, mytheta)))))+\-np.dot((1-myy), np.log(1-np.exp(np.dot(myx, mytheta))/(1+np.exp(np.dot(myx, mytheta)))))def optima(mytheta, myx, myy): #求最优解result = fmin(cost, x0 = mytheta, args = (myx, myy), maxiter = 500, full_output= True)return resultdef boundary(mytheta, myx): #边界函数xs = np.array([np.min(myx[:,1]), np.max(myx[:,1])]) #横坐标2个点ys = -(mytheta[0][0] + mytheta[0][1]*xs)/mytheta[0][2] #纵坐标2个点plt.plot(xs, ys, label = 'decision boundary') #决策边界plt.xlabel("exam1_score")plt.ylabel("exam2_score")plt.legend()plt.pause(2)def descision(mytheta, myx): #决策函数y_score = np.dot(X, mytheta) #概率得分(0~1)y_pred = np.zeros(len(myx)) #用来存预测值(0,1)for i in range(len(myx)):if np.dot(mytheta, myx[i, :]) >=0.5:y_pred[i] = 1else:y_pred[i] = 0return y_score, y_preddef conf_matrix(y_pred, y_true): #混肴矩阵tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel() #plt.matshow([[tn, fp], [fn, tp]])plt.title("confusion matrix")plt.xlabel("predict")plt.ylabel("acutual")plt.colorbar()plt.pause(2)def roc(y_true, y_pred): #绘制roc曲线plt.figure(figsize = (6,4)) #新建画布fpr, tpr, thresholds = roc_curve(np.array(y_true), np.array(y_pred))auc_ = auc(fpr, tpr)plt.plot(fpr, tpr, label = "ROC curve (area = %0.2f)"%auc_)plt.xlabel("False positive rate")plt.ylabel("true positive rate")plt.title("ROC curve")plt.legend()plt.pause(2)def fmap(x1, x2): #特征映射n = 2 #最高阶out = np.ones((x1.shape[0], 1)) #100*1的向量for i in range(1, n+1):for j in range(0, i+1):term1 = x1**(i-j)term2 = x2**(j)term = (term1*term2).reshape(term1.shape[0], 1)out = np.hstack((out, term)) #水平平铺return outdef project(mytheta): #特征映射后投影边界plt.figure(figsize=(6, 4))visualization() #把原来散点也画进来观察效果xs = np.linspace(25, 105, 100)ys = np.linspace(25, 105, 100)zs = np.zeros((len(xs), len(ys)))for i in range(len(xs)):for j in range(len(ys)):fij = fmap(np.array([xs[i]]), np.array([ys[j]])) #调用特征映射zs[i][j] = np.dot(fij, mytheta)zs = zs.transpose()u, v = np.meshgrid(xs, ys)plt.contour(xs, ys, zs, [0]) #等值线plt.title("Decision boundary")plt.pause(5)if __name__=="__main__":visualization() #原数据可视化inital_theta = np.zeros((X.shape[1], 1)) #参数初始化,3*1的零向量result = optima(inital_theta, X, y) #参数,当前函数值,迭代次数和function evaluationboundary(result, X) #画出决策边界y_score, y_pred = descision(result[0], X) #预测值conf_matrix(y, y_pred) #混肴矩阵#roc(y,y_pred) #ROC曲线roc(y, y_score) #ROC曲线X_map = fmap(X[:,1], X[:,2]) #特征映射initial_theta_map = np.zeros((X_map.shape[1], 1))result_map = optima(initial_theta_map, X_map, y) ##参数,当前函数值project(result_map[0])
参考文献
1,对数函数
2,python绘制对数函数
3,如何理解logistic函数
4,logit究竟是个啥?
5,逻辑回归
6,从原理到代码,轻松深入逻辑回归
7,https://www.zybuluo.com/frank-shaw/note/143260
8,混肴矩阵