逻辑回归通常用于解决分类问题,比如:客户是否该买某个商品,借款人是否会违约等。实际上,“分类”是逻辑回归的目的和结果,中间过程依旧是“回归”,因为通过逻辑回归模型,我们得到的是0-1之间的连续数字,即概率,类似借款人违约的可能性。然后给这个可能性加上一个阈值,就变成了分类。
逻辑回归与线性模型的关系
逻辑回归是线性模型,但属于广义线性模型。普通线性模型与广义线性模型的联系:
1、普通线性模型
普通线性模型的表达式:
是截距项,
是未知参数。
普通线性模型具备以下特点:
- 响应变量y服从正太分布;
- 误差
具有正太性,与x的变化无关;
具有非随机性,可测并不存在误差,
虽然未知,但不具有随机性;
- 特征
2、广义线性模型
- 响应变量y的分布从正太分布扩展到指数分布族:比如正态分布、泊松分布、二项分布、负二项分布、伽玛分布等,这和
- 特征
可知,逻辑回归是响应变量y服从伯努利分布的广义线性模型。
逻辑回归和线性回归的区别与联系
区别
- 线性回归假设响应变量服从正态分布,逻辑回归假设响应变量服从伯努利分布
- 线性回归优化的目标函数是均方差(最小二乘),而逻辑回归优化的是似然函数(交叉熵)
- 线性归回要求自变量与因变量呈线性关系,而逻辑回归没有要求
- 线性回归分析的是因变量自身与自变量的关系,而逻辑回归研究的是因变量取值的概率与自变量的概率
- 逻辑回归处理的是分类问题,线性回归处理的是回归问题,这也导致了两个模型的取值范围不同:0-1和实数域
- 参数估计上,都是用极大似然估计的方法估计参数(高斯分布导致了线性模型损失函数为均方差,伯努利分布导致逻辑回归损失函数为交叉熵)
联系
- 两个都是线性模型,线性回归是普通线性模型,逻辑回归是广义线性模型
- 表达形式上,逻辑回归是线性回归套上了一个Sigmoid函数
最大似然估计
sigmod的函数为,该函数具备很好的鲁棒性,并将输出映射到(0,1)之间且具有概率意义,解决了线性回归拟合设置阈值受到离群点的影响。函数形式可表现为:
P(y=0|w,x) = 1 – g(z) # 预测负例的概率
P(y=1|w,x) = g(z) # 预测正例的概率
# 预测结果的正确率
若想让预测出的结果全部正确的概率最大,根据最大似然估计,就是所有样本预测正确的概率相乘得到的P(总体正确)最大,数学形式为:
,其中,
,
现在对公式求解,最大值就是最优解。我们知道,一个连乘的函数是不好计算的,我们可以通过两边同时取log的形式让其变成连加。
这个函数就是逻辑回归的损失函数,我们叫它交叉熵损失函数。
求解逻辑回归模型
1、梯度下降法
2、牛顿法
正则化项
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般称作 L1正则化 和 L2正则化,或者 L1范数 和 L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
L1正则化的数学公式为: ,直接在原来的损失函数基础上加上权重参数的绝对值。
L2正则化的数学公式为:,直接在原来的损失函数基础上加上权重参数的平方和。
一般回归分析中w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制),权值的绝对值。
L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为
。可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为
。可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
1、L1正则化和稀疏矩阵的关系
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
2、L2正则化和过拟合的关系
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
LR中特征相关问题
1、特征离散化目的
- 离散特征可以one-hot, 而稀疏向量内积运算速度快,结果易存储
- 离散后数据鲁棒性强,不会因为数据发生一点小的变动而表现出完全不同的性质,使模型更稳定
- 离散后可以进行特征交叉,引入非线性特征
- 增强模型的表达能力,离散化后,原来的一个特征变成N个特征,加大了模型的拟合能力
- 特征离散后相当于简化了特征,一定程度上减轻了过拟合
总的来说,特征离散化以后起到了加快计算,简化模型和增加泛化能力的作用。
2、特征的共线性
LR模型中特征的共线性不会影响模型的最优解,但是会影响系数的稳定性。比如两个特征,分别表示米和厘米,这两个长度高度共线性。
的系数发生质的翻转,但是表达能力没变。
所以,LR模型中特征的共线性不会影响模型的最优解,但是会使得系数不稳定,从而解释性变差。
删除共线性的原因:
- 提高模型的可解释性;
- 提高模型的训练速度
3、特征权重的绝对值是否可以衡量特征的重要性
不一定,首先特征可能没有归一化,系数受到量级的影响(1m=1cm*100),其次,特征之间可能存在共线性,导致特征系数不稳定,可解释性差。
4、逻辑回归的分类问题
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归
5、线性
对于线性方程y=ax+b,当b=0时,我们说y=ax,y和x的大小始终符合y/x=a,图像上任意一点的坐标,y值都是x值的a倍。我们把这种横纵坐标始终呈固定倍数的关系叫做"线性"。
6、阈值选定
逻辑回归解决分类问题,其输出的概率结果需要确定阈值来分类。对于逻辑回归预测的(0,1)之间的值,第一印象是以0.5为阈值,大于0.5为正例,小于0.5为负例子。但是阈值的设定往往是根据实际情况来判断的,做一个肿瘤的良性恶性判断,选定阈值为0.5就意味着,如果一个患者得恶性肿瘤的概率为0.49,模型依旧认为他没有患恶性肿瘤,结果就是造成了严重的医疗事故。此类情况我们应该将阈值设置的小一些,如0.,一个人患恶性肿瘤的概率超过0.3我们的算法就会报警,造成的结果就是这个人做一个全面检查,比起医疗事故显然这个更容易接受。再比如识别验证码,输出的概率为这个验证码识别正确的概率,此时我们大可以将概率设置的高一些,因为即便识别错了又能如何,造成的结果就是在一个session时间段内重试一次。机器识别验证码就是一个不断尝试的过程,错误率本身就很高。
7、评估方法
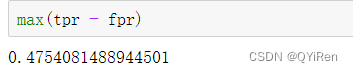
对于LR分类模型的评估,常用AUC来评估