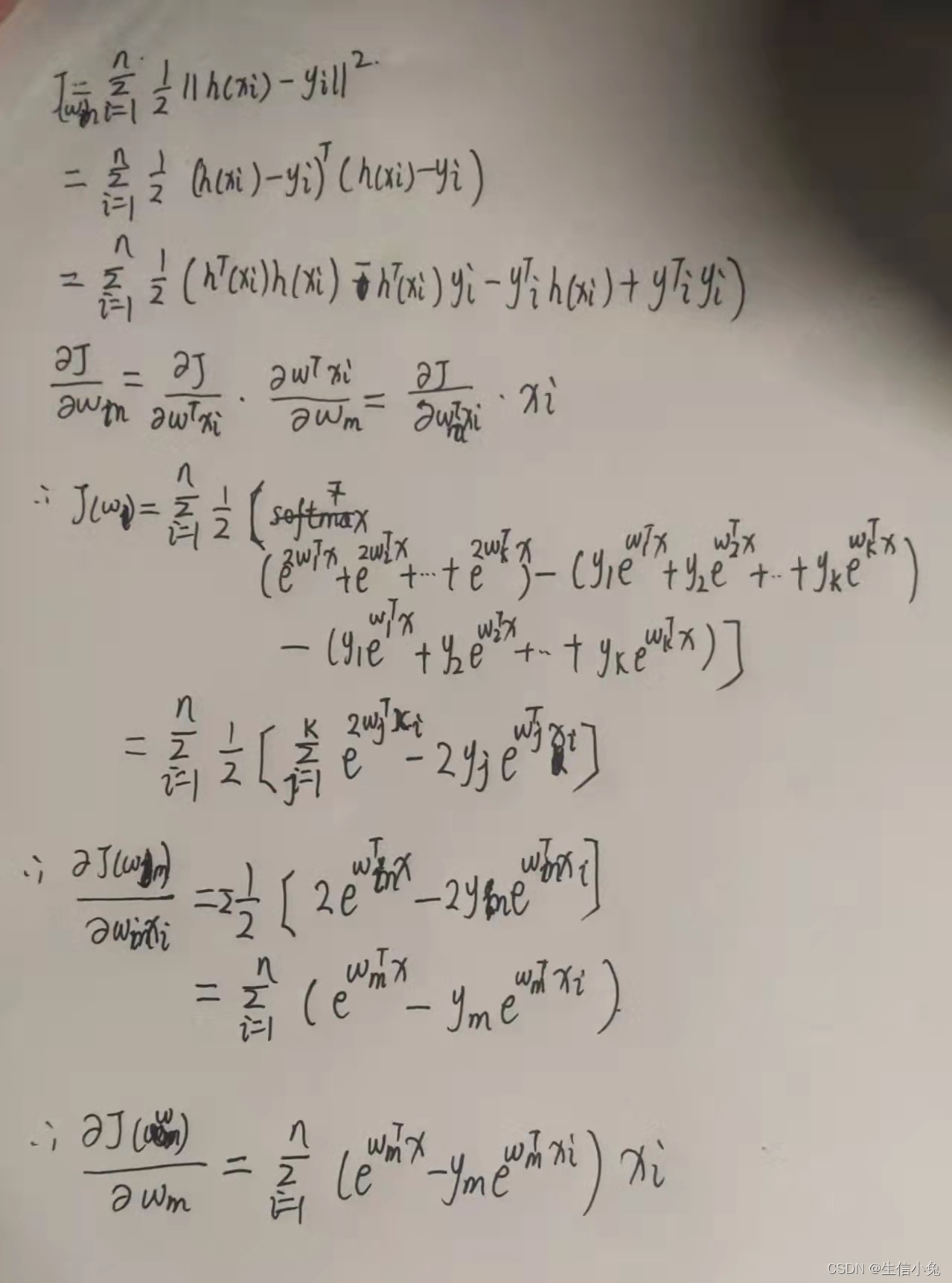文章目录
- 一、逻辑回归(Logistic Regression)
- 二、样本不均衡问题处理
- 1 、过采样方法
- (一)、随机过采样法
- (二)、SMOTE算法
- 2 、欠采样方法
- (一)、随机欠采样
- 三、网格搜索快速调优
- 损失函数(对数似然损失)
- 四、模型评价
- ROC曲线
一、逻辑回归(Logistic Regression)
逻辑回归是一种分类算法,逻辑回归就是解决二分类问题的利器。
算法原理:将线性回归的输出作为逻辑回归的输入,然后经过sigmoid函数变换将整体的值映射到[0,1],再设定阈值进行分类。
常用参数:
random_state:随机种子。
class_weight:各类别样本的权重。样本需要加权时,使用该参数。
max_iter:最大迭代次数。
tol:停止标准。如果求解不理想,可尝试设置更小的值。
正则化相关参数:
penalty:惩罚项,默认用L2
C:正则化力度
solver:求解器。
solver:{‘newton-cg’,’lbfgs’,’liblinear’,’sag’,’saga’}
1、‘newton-cg’,‘lbfgs’和’sag’只处理L2惩罚,而’liblinear’和’saga’处理L1惩罚。
2、对于小型数据集,使用’liblinear’即可。
3、对于多类问题,只有’newton-cg’, ‘sag’, 'saga’和’lbfgs’可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
二、样本不均衡问题处理
增加一些少数类样本使得正、反例数目接近,然后再进行学习。
关于类别不平衡的问题,主要有两种处理方式:
1 、过采样方法
增加数量较少那一类样本的数量,使得正负样本比例均衡。
(一)、随机过采样法
原理:通过复制所选择的样本生成样本集
缺点:易产生模型过拟合问题
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
(二)、SMOTE算法
原理:对于少数类样本,从它的最近邻中随机选择一个样本,然后在两个样本之间的连线上随机选择一点作为新合成的少数类样本。(用合理的方式产生新样本,防止随机过采样中容易过拟合的问题)
# SMOTE过采样
from imblearn.over_sampling import SMOTE
X_resampled, y_resampled = SMOTE().fit_resample(X, y)
2 、欠采样方法
减少数量较多那一类样本的数量,使得正负样本比例均衡。
(一)、随机欠采样
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
原理:通过改变多数类样本比例以达到修改样本分布的目的,从而使样本分布较为均衡
缺点:由于采样的样本集合要少于原来的样本集合,因此会造成一些信息缺失,即将多数类样本删除有可能会导致分类器丢失有关多数类的重要信息。
三、网格搜索快速调优
from sklearn.linear_model import LogisticRegression as LR # 逻辑回归
from sklearn.metrics import precision_score, recall_score, f1_score,accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV # 网格搜索
# 把整体数据集进行切分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 40)
#在l2范式下,判断C和solver的最优值
p = {'C':list(np.linspace(0.05,1,19)),'solver':['liblinear','sag','newton-cg','lbfgs']}model = LR(penalty='l2',max_iter=10000)
GS = GridSearchCV(model,p,cv=5)
GS.fit(X_train,y_train)
#输出最优参数
GS.best_params_
损失函数(对数似然损失)

四、模型评价
1、精确率(Accuracy)
精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。一般情况下,模型的精度越高,说明模型的效果越好。
Accuracy=(TP+TN)/(TP+FN+FP+TN)
2、 准确率(Precision)
表示在模型识别为正类的样本中,真正为正类的样本所占的比例。一般情况下,查准率越高,说明模型的效果越好。
Precision=TP/(TP+FP)
3、 召回率(Recall)
召回率表示模型正确识别出为正类的样本的数量占总的正类样本数量的比值。一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。
Recall=TP/(TP+FN)
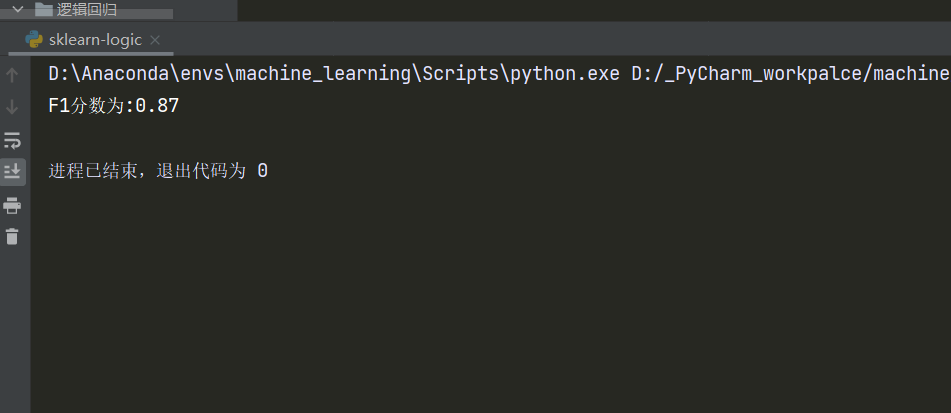
4、 F1 值
F1值是精确度和召回率的调和平均值。
F1=(2*Precision*Recall)/(Precision+Recall)
精确度和召回率都高时,F1值也会高。F1值在1时达到最佳值(完美的精确度和召回率),最差为0。在二分类模型中,F1值是测试准确度的量度。
from sklearn.metrics import classification_report
# 返回每个类别精确率与召回率
ret = classification_report(y_test, y_predict,target_names=("流失", "不流失"))
#target_names:目标类别名称
ROC曲线
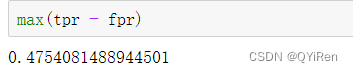
TPR = TP / (TP + FN)
所有真实类别为真的样本中,预测类别为真的比例
FPR = FP / (FP + TN)
所有真实类别为假的样本中,预测类别为真的比例
AUC指标
1、AUC的概率意义是随机取一对正负样本,正样本得分大于负样本得分的概率
2、AUC的范围在[0, 1]之间,并且越接近1越好,越接近0.5属于乱猜
3、AUC=1,完美分类器,绝大多数预测的场合,不存在完美分类器。
4、0.5<AUC<1,优于随机猜测。妥善设定阈值的话,能有预测价值。