前言
GNN领域最经典的论文之一是Kipf同学2016年发布的GCN。
经典的GCN做了四个数据集的实验,后续工作基本会在这4个数据集上也做一次。
但是由于年代久远,和一些历史问题,
后来者想做对比实验难免遇到一些“从哪里获取"与"是这个东西吗”之类的困惑。
本文记录一些现在还能找到的基本事实供后续入坑的初学者参考。
主要厘清几个数据集的存在形式与变迁。
一、4个基本数据集
Cora, Citeseer, Pubmed, Nell。
Nell数据集比较简单,下面给出链接。
http://www.cs.cmu.edu/~zhiliny/data/nell_data.tar.gz
记住这个zhilin y.
我们重点关注前三个。
1.1 御三家的作者是谁
Cora, Citeseer与Pubmed,并称御三家,
在GCN论文中号称御三家来自这篇Sen先生2008年的工作。
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad.Collective classification in network data. AI magazine, 29(3):93, 2008.
原文句子We report results on a 5-fold cross-validation experiment on the Cora, Citeseer and Pubmed datasets (Sen et al., 2008) using all labels.
然而我们去寻找这篇2008年的文献,可以找到他被收录于
https://www.aaai.org/ojs/index.php/aimagazine/article/view/2157
主页上还能下载到pdf。
打开pdf一看,读到这么一句。
We experimented with two real-world bibliographic data sets: Cora (McCallum et al. 2000) and CiteSeer (Giles, Bollacker, and Lawrence 1998).

也就是说,御三家根本不是Sen先生在2008年的工作产出。
- Cora是M先生2000年发布的
- CiteSeer是G先生1998年发布的。
- 而Sen先生根本没有提到任何关于Pubmed的事情。
后来的研究学者们却在引用的时候全部一起归功给Sen先生了(引用量就是这样涨的…?)
1.2 第一个犯人
既然截止我写下本文的2020年,所有学者都犯错了,那应该总能找到第一个犯错的人,简称第一个犯人。
所有人都是从ICLR2017这篇GCN鼻祖开始引用的,鼻祖自己都错了,鼻祖的错误又来自哪里呢?
答案是这位
Zhilin Yang,.etc, Revisiting Semi-Supervised Learning with Graph Embeddings. ICML2016
github repo:https://github.com/kimiyoung/planetoid
就是提出XLNET那位杨植麟。
逻辑关系很容易查找,16年3月在CMU读博的Mr.Yang挂了这篇文章中了ICML2016,16年9月Kipf先生参考了他的数据处理格式写下GCN中了ICLR2017。
我们看看yang的原文
We first considered three text classification datasets5, Citeseer, Cora and Pubmed (Sen et al., 2008).

后世所有文章用到御三家时都是跟Yang保持一致的。
从目前掌握的证据来看,可以认为Yang是第一个犯人。
记住这个标号5的链接。
截止目前(2020.10.29),标号5的这个umd.edu链接已失效。
但不妨碍我们考察它的正确性。
容易找到,这个链接属于一个叫LINQS(Lise’s INQuisitive Students)的实验室,带头人是Professor Lise Getoor.
进而可以找到,LINQS实验室维护了一个名叫LBC(Link-Based Classification)的project,简称LBC计划。
这个计划是在Getoor教授还任教于CMU时提出来的,(所以被当时在CMU读博的yang同学用上了?)
该计划的CMU首页目前(2020.10.29)还能访问
http://www.cs.umd.edu/~sen/lbc-proj/LBC.html
从主页中能找到该计划下属的3个数据集,
- CiteSeer: The CiteSeer dataset consists of 3312 scientific publications classified into one of six classes. The citation network consists of 4732 links. Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 3703 unique words. The README file in the dataset provides more details. Click here to download the tarball containing the dataset.
- Cora: The Cora dataset consists of 2708 scientific publications classified into one of seven classes. The citation network consists of 5429 links. Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 1433 unique words. The README file in the dataset provides more details. Click here to download the tarball containing the dataset.
- WebKB: The WebKB dataset consists of 877 scientific publications classified into one of five classes. The citation network consists of 1608 links. Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 1703 unique words. The README file in the dataset provides more details. Click here to download the tarball containing the dataset.
对的,如你所见,
真正的御三家应该是cora,citeseer 和 webKB,
pubmed并不配有姓名。
为什么特意提到LBC是在CMU时发布的,因为Geetor阿姨现在率领LINQS实验室集体挥师UCSC。
她现在的主页https://getoor.soe.ucsc.edu/ ,
实验室现在的主页https://linqs.soe.ucsc.edu/home
事实上这也不是第一次有人给来路不明的数据集乱套LBC的名字。
比如清华NLP的这个repo(https://github.com/thunlp/OpenNE)里,
用到了一个叫Wiki的数据集,自称来自LBC计划。

然后被LBC的Ph.D Candidate在issue里质疑了,也没有改正。

参考链接https://github.com/thunlp/OpenNE/issues/18
我们在LINQS实验室首页能找到这位Eriq同学。

所以我现在困惑的问题在于,Yang当时是 【使用了LBC的WebKB数据集但文章写成Pubmed,还是单纯的用了Pubmed但写错了来源】?
如果是前者无疑略可怕的事情,等于带歪了后世一连串的实验。
大家如穿皇帝的新衣,虚空与错误的数据集做对比?
想解答我的困惑,我们显然需要找出来Pubmed数据集到底是什么东西,找到它的真正来源,再跟Yang代码里提供的数据作对比,来验证他使用的确实是Pubmed。
1.3 可能被凭空捏造的Pubmed
很遗憾,经过漫长的搜寻,我以手上掌握的信息,向阅读此文的后来人沉痛宣告,
我们这些GNN科研人员口中的Pubmed数据集或许本不存在。
断言:从未有任何学术机构/个人,以正规形式发布过可以与Yang对应的、名字精确匹配、字字吻合
Pubmed的数据集。
其原因在于,PubMed 是一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库(百度百科)。
理解了吗? 这是一个生物医学领域的论文搜索引擎。
所以任何一个人写任何一个爬虫在任何一天去爬这个搜索引擎得到的结果,都可以自称Pubmed数据集。
一般对这种过于宽泛的东西呢,我们需要一个带头人,以他写的爬虫结果为benchmark。
这个带头人需要发一篇文章,说我今天爬了这个搜索引擎,整理了一个数据集,并提供一个access方式。
很遗憾,个人能力有限,找不到这么一篇足以自成benchmark的文章。
提供几个相近的结果供读者自行评判。
1.3.1 美国NIH发布的Annual Baseline
美国政府的健康部门(NIH,National Institution of Health)发布的 XML格式的Annual Baseline
https://www.nlm.nih.gov/databases/download/pubmed_medline.html
按照该主页的说法,每年都会更新。
The annual baseline is released in December of each year. Each day, NLM produces update files that include new, revised and deleted citations
我下载了这个数据集,包含1015个xml文件,大小2.27GB。
而Yang提供的处理后的Pubmed数据集,八个文件加起来只有8.31MB。
显然不可能是NIH这份。

1.3.2 Sun Kim的爬虫工作
Sun Kim同学在16年8月挂出的文章里,自己爬了一份PubMed的数据。
Bridging the Gap: Incorporating a Semantic Similarity Measure for
Effectively Mapping PubMed Queries to Documents
link :https://arxiv.org/pdf/1608.01972.pdf
前面已经说过,反正任何人去爬一下PubMed都可以自称Pubmed数据集。

帮助Yang获得ICML2016的文章在16年3月就挂上了arxiv,而Kim同学的文章16年8月才挂出来,时间上就不太可能成立Yang引用Kim的数据集。
其次是结点数量,Kim的描述也对不上Yang文章里提供的数据集基本描述。

类似Kim的还有17年的,也是自己爬。
这些时间关系上都不可能成为Yang所使用的Pubmed数据集。
https://arxiv.org/pdf/1709.02116.pdf
https://arxiv.org/pdf/1701.04273.pdf.
We select over 300,000 documents articles published between 2012 to 2015 from PubMed.
总而言之,我的结论是,
现存的唯一一份能吻合Yang与GCN论文所述的Pubmed数据集,就是Yang自己在github仓库里提供的8MB这份。
但这份数据集来路不明,除了Yang之外没有人知道怎么来的。
二、作为后人的应尽之事
Yang的文章16年所铸之错业已覆水难收。
2.1 放弃使用Pubmed
毕竟这两年GNN着实火热,监控GNN关键词的文章成百上千,不可能通知后世那么多GNN文章的作者一一订正。
有缘见到我这篇文章的GNN研究者,请记住。
首先,Pubmed不属于LBC计划。
其次,Pubmed是一个来路不明的,可以被任何人爬取产生的未定名数据集。
我们不能去订正前人,只能从现在开始,从自己开始,放弃使用Pubmed数据集做实验。
但Cora和CiteSeer还是可以使用的。
(这份倡议或者也显得多余。未来可能这些数据集也会因为太玩具而被抛弃,下一代GNN研究者可能会有新的benchmark数据集,而自动放弃使用Pubmed。)
2.2 关于cora和citeseer的对比实验
原始的LBC发布的这两个数据集,包含了.content和 .cite两个文件。
这是第一版格式。
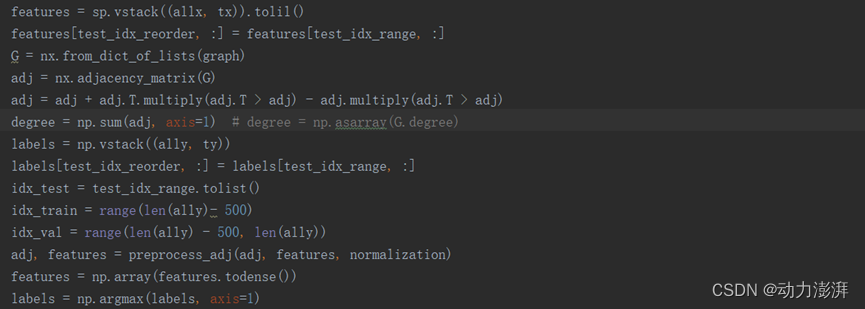
而Yang提供了一种既定的数据处理方式,划分好了训练与验证集。
这是第二版格式,即.x, .y, .tx, .ty这些,一共八个文件。
关于第二版的格式,已经有一篇很好的文章介绍了@yyl424525:《GCN使用的数据集Cora、Citeseer、Pubmed、Tox21格式》。
鼻祖GCN的实验是在Yang的格式上做的。
但后续也有些工作并不是,
比如GAT(Graph Attention Network, ICLR2018)
看作者开源代码(https://github.com/PetarV-/GAT)可以知道,
他所采用的源数据是第一版格式的 cora.content和cora.cite 。
用了自己的处理和划分方法。
这就导致对比实验很不公平。
你拿自己的划的训练集测试集结果,去跟Yang划的训练集测试集结果比,能一样吗。
但由于Yang的论文会误导后人,我并不推荐大家继续采用他的划分标准,因为在论文里引用他的文章,会导致其他人顺着索引去读,进而犯错。
后续实验应该避开Yang的结果,统一用cora.content和cora.cite 为源数据,用自己的处理方式划分,然后再跑其他模型,而不是直接引用其他模型在论文里展示的结果(GAT是这么搞的)。
#21.07.13更新
发现一篇2012的文章里有介绍PubMed也是LBC计划的一部分。
但不知道为什么现在LBC主页不再提供该数据集。
https://dtai.cs.kuleuven.be/events/mlg2012/papers/11_querying_namata.pdf