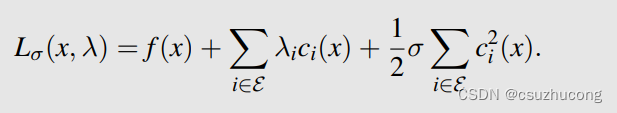增广拉格朗日函数法
在二次罚函数法中,为了保证可行性,罚因子必须趋于正无穷。此时,子问题因条件数爆炸而难以求解。那么,是否可以通过对二次罚函数进行某种修正,使得对有限的罚因子,得到的毕竟最优解也是可行的?增广拉格朗日函数法就是这样的一个方法。
一、等式约束优化问题的增广拉格朗日函数法
- 增广拉格朗日函数法的构造
增广拉格朗日函数法的每一步构造一个增广拉格朗日函数,而该函数的构造依赖于拉格朗日函数和约束的二次罚函数。具体地,对于等式约束优化问题,
min x f ( x ) s . t . c i ( x ) = 0 , i ∈ E (1) \begin{aligned} &\min_{x}f(x) \\ &s.t.\quad c_i(x)=0, i\in\mathcal{E} \end{aligned}\tag{1} xminf(x)s.t.ci(x)=0,i∈E(1)
其增广拉格朗日函数定义为
L σ ( x , λ ) = f ( x ) + ∑ i ∈ E λ i c i ( x ) + 1 2 ∑ i ∈ E c i 2 ( x ) , (2) L_{\sigma}(x,\lambda)=f(x)+\sum_{i\in\mathcal{E}}\lambda_ic_i(x)+\frac{1}{2}\sum_{i\in\mathcal{E}}c_i^2(x),\tag{2} Lσ(x,λ)=f(x)+i∈E∑λici(x)+21i∈E∑ci2(x),(2)
即在拉格朗日函数的基础上,添加约束的二次罚函数。在第k步迭代,给定罚因子 σ k \sigma_k σk和橙子 λ k \lambda^k λk,增广拉格朗日函数 L σ k ( x , λ k ) L_{\sigma_k}(x,\lambda^k) Lσk(x,λk)的最小值点 x k + 1 x^{k+1} xk+1满足
∇ x L σ k ( x k 1 , λ k ) = ∇ f ( x k + 1 ) + ∑ i ∈ E ( λ i k + σ k c i ( x k + 1 ) ) ∇ c i ( x k + 1 ) = 0 (3) \nabla_xL_{\sigma_k}(x^{k_1},\lambda^k)=\nabla f(x^{k+1})+\sum_{i\in\mathcal{E}}(\lambda_i^k+\sigma_kc_i(x^{k+1}))\nabla c_i(x^{k+1})=0\tag{3} ∇xLσk(xk1,λk)=∇f(xk+1)+i∈E∑(λik+σkci(xk+1))∇ci(xk+1)=0(3)
对于优化问题(1),其最优解 x ∗ x^* x∗以及相应的乘子 λ ∗ \lambda^* λ∗需要满足
∇ f ( x ∗ ) + ∑ i ∈ E λ i ∗ ∇ c i ( x ∗ ) = 0 (4) \nabla f(x^*)+\sum_{i\in\mathcal{E}}\lambda_i^*\nabla c_i(x^*)=0\tag{4} ∇f(x∗)+i∈E∑λi∗∇ci(x∗)=0(4)
为使增广拉格朗日函数法产生的迭代点列收敛到 x ∗ x^* x∗,需要保证等式(3)(4)在最优解处的一致性。因此,对于充分大的 k k k,
λ i ∗ ≈ λ i k + σ k c i ( x k + 1 ) , ∀ i ∈ E \lambda_i^*\approx\lambda_i^k+\sigma_kc_i(x^{k+1}),\forall i\in\mathcal{E} λi∗≈λik+σkci(xk+1),∀i∈E
上式等价于
c i ( x k + 1 ) ≈ 1 σ k ( λ i ∗ − λ i k ) (5) c_i(x^{k+1})\approx\frac{1}{\sigma_k}(\lambda_i^*-\lambda_i^k)\tag{5} ci(xk+1)≈σk1(λi∗−λik)(5)
所以,当 λ i k \lambda_i^k λik足够接近 λ i ∗ \lambda_i^* λi∗时,点 x k + 1 x^{k+1} xk+1处的约束违反度将会远小于 1 σ k \frac{1}{\sigma_k} σk1。注意,在(1)式中约束违反度式正比于 1 σ k \frac{1}{\sigma_k} σk1的。即增广拉格朗日函数法可以通过有效地更新乘子来降低约束违反度,(5)式表明,橙子的一个有效的更新格式为
λ i k + 1 = λ i k + σ k c i ( x k + 1 ) , ∀ i ∈ E \lambda_i^{k+1}=\lambda_i^k+\sigma_kc_i(x^{k+1}),\forall i\in\mathcal{E} λik+1=λik+σkci(xk+1),∀i∈E
那么,我们得到问题(1)的增广拉格朗日函数法,见算法1,其中 c ( x ) = [ c i ( x ) ] i ∈ E c(x)=[c_i(x)]_{i\in\mathcal{E}} c(x)=[ci(x)]i∈E,并且 ∇ c ( x ) = [ ∇ c i ( x ) ] i ∈ E \nabla c(x)=[\nabla c_i(x)]_{i\in\mathcal{E}} ∇c(x)=[∇ci(x)]i∈E
算法1:增广拉格朗日函数法
- 选取初始点 x 0 x^0 x0,乘子 λ 0 \lambda^0 λ0,罚因子更新常数 ρ > 0 \rho>0 ρ>0,约束违反度常数 ϵ > 0 \epsilon>0 ϵ>0和精度要求 η k > 0 \eta_k>0 ηk>0。并令 k = 0 k=0 k=0.
- for k=0,1,2, ⋯ \cdots ⋯do
- \quad 以 x k x^k xk为初始点,求解 min x L σ k ( x , λ k ) \min_x\quad L_{\sigma_k}(x,\lambda_k) minxLσk(x,λk),得到满足精度条件 ∣ ∣ ∇ x L σ k ( x , λ k ) ∣ ∣ ≤ η k ||\nabla_xL_{\sigma_k}(x,\lambda^k)||\le\eta_k ∣∣∇xLσk(x,λk)∣∣≤ηk的解 x k + 1 x^{k+1} xk+1
- \quad if ∣ ∣ c ( x k + 1 ) ∣ ∣ ≤ ϵ ||c(x^{k+1})||\le\epsilon ∣∣c(xk+1)∣∣≤ϵ then
- \qquad 返回近似解 x k + 1 , λ k x^{k+1},\lambda^k xk+1,λk,终止迭代
- \quad end if
- \quad 更新乘子: λ k + 1 = λ k + σ k c ( x k + 1 ) \lambda^{k+1}=\lambda^k+\sigma_kc(x^{k+1}) λk+1=λk+σkc(xk+1)
- \quad 更新罚因子: σ k + 1 = ρ σ k \sigma_{k+1}=\rho\sigma_k σk+1=ρσk
- end for
二、一般约束优化问题的增广拉格朗日函数法
对于一般约束优化问题
min f ( x ) s . t c i ( x ) = 0 , i ∈ E c i ( x ) ≤ 0 , i ∈ I (6) \begin{aligned} \min\quad&f(x)\\ s.t\quad &c_i(x)=0,i\in\mathcal{E}\\ &c_i(x)\le 0, i\in\mathcal{I} \end{aligned}\tag{6} mins.tf(x)ci(x)=0,i∈Eci(x)≤0,i∈I(6)
也可以定义其增广拉个蓝i函数以及涉及相应的增广拉格朗日函数法。在拉格朗日函数的定义中,往往倾向于将简单的约束保留,对复杂的约束引入乘子。这里,对于带不等式约束的优化问题,我们先通过引入松弛变量将不等式约束转化为等式约束和简单的非负约束,再对保留非负约束形式的拉格朗日函数添加等式约束的二次罚函数来构造拉格朗日函数。
-
增广拉格朗日函数
对于问题(6),引入松弛变量可以得到如下等价形式
min x , s f ( x ) , s . t c i ( x ) = 0 , i ∈ E , c i ( x ) + s i = 0 , i ∈ I , s i ≥ 0 , i ∈ I (7) \begin{aligned} \min_{x,s}\quad &f(x),\\ s.t\quad & c_i(x)=0,i\in\mathcal{E},\\ &c_i(x)+s_i=0,i\in\mathcal{I},\\ &s_i\ge 0,i\in\mathcal{I} \end{aligned}\tag{7} x,smins.tf(x),ci(x)=0,i∈E,ci(x)+si=0,i∈I,si≥0,i∈I(7)
保留非负约束,可以构造拉格朗日函数
L ( x , s , λ , μ ) = f ( x ) + ∑ i ∈ E λ i c i ( x ) + ∑ i ∈ I μ i ( c i ( x ) + s i ) , s i ≥ 0 , i ∈ I L(x,s,\lambda,\mu)=f(x)+\sum_{i\in\mathcal{E}}\lambda_ic_i(x)+\sum_{i\in\mathcal{I}}\mu_i(c_i(x)+s_i),s_i\ge0,i\in\mathcal{I} L(x,s,λ,μ)=f(x)+i∈E∑λici(x)+i∈I∑μi(ci(x)+si),si≥0,i∈I
记问题(7)中等式约束的二次罚函数为 p ( x , s ) p(x,s) p(x,s),则
p ( x , s ) = ∑ i ∈ E c i 2 ( x ) + ∑ i ∈ I ( c i ( x ) + s i ) 2 . p(x,s)=\sum_{i\in\mathcal{E}}c_i^2(x)+\sum_{i\in\mathcal{I}}(c_i(x)+s_i)^2. p(x,s)=i∈E∑ci2(x)+i∈I∑(ci(x)+si)2.
我们构造拉格朗日函数如下:
L ( x , s , λ , μ ) = f ( x ) + ∑ i ∈ E λ i c i ( x ) + ∑ i ∈ I μ i ( c i ( x ) + s i ) + σ 2 p ( x , s ) , s i ≥ 0 , i ∈ I L(x,s,\lambda,\mu)=f(x)+\sum_{i\in\mathcal{E}}\lambda_ic_i(x)+\sum_{i\in\mathcal{I}}\mu_i(c_i(x)+s_i)+\frac{\sigma}{2}p(x,s),s_i\ge0,i\in\mathcal{I} L(x,s,λ,μ)=f(x)+i∈E∑λici(x)+i∈I∑μi(ci(x)+si)+2σp(x,s),si≥0,i∈I
其中 σ \sigma σ为罚因子 -
增广拉格朗日函数法
在第 k k k步迭代中,给定乘子 λ k , μ k \lambda_k,\mu_k λk,μk和罚因子 σ k \sigma_k σk,我们需要求解如下问题:
min x , s L σ k ( x , s , λ k , μ k ) , s . t s ≥ 0 (8) \min_{x,s} L_{\sigma_k}(x,s,\lambda_k,\mu_k),s.t s\ge 0\tag{8} x,sminLσk(x,s,λk,μk),s.ts≥0(8)
以得到 x k + 1 , s k + 1 x^{k+1},s^{k+1} xk+1,sk+1。求解问题(8)的一个有效的方法是投影梯度法。另外一种方法是消去 s s s,求解只关于 x x x的优化问题。具体地,固定 x x x,关于 s s s的子问题可以表示为
min s ≥ 0 ∑ i ∈ I μ i ( c i ( x ) + s i ) + σ k 2 ∑ i ∈ I ( c i ( x ) + s i ) 2 \min_{s\ge 0}\sum_{i\in\mathcal{I}}\mu_i(c_i(x)+s_i)+\frac{\sigma_k}{2}\sum_{i\in\mathcal{I}}(c_i(x)+s_i)^2 s≥0mini∈I∑μi(ci(x)+si)+2σki∈I∑(ci(x)+si)2
根据凸优化问题的最优性理论, s s s为以上为题的一个全局最优解,当且仅当
s i = max { − μ i σ k − c i ( x ) , 0 } , i ∈ I (9) s_i=\max\{-\frac{\mu_i}{\sigma_k}-c_i(x),0\},\quad i\in\mathcal{I}\tag{9} si=max{−σkμi−ci(x),0},i∈I(9)
将 s i s_i si的表达式代入 L σ k L_{\sigma_k} Lσk我们有
L σ k ( x , λ k , s i m g a k ) = f ( x ) + ∑ i ∈ I λ i c i ( x ) + σ k 2 ∑ i ∈ E c i 2 + σ k 2 ∑ i ∈ I ( max { μ i σ k + c i ( x ) , 0 } 2 − m u i 2 σ k 2 ) (10) L_{\sigma_k}(x,\lambda_k,simga_k)=f(x)+\sum_{i\in\mathcal{I}}\lambda_ic_i(x)+\frac{\sigma_k}{2}\sum_{i\in\mathcal{E}}c_i^2+\frac{\sigma_k}{2}\sum_{i\in\mathcal{I}}(\max\{\frac{\mu_i}{\sigma_k}+c_i(x), 0\}^2-\frac{mu_i^2}{\sigma_k^2}) \tag{10} Lσk(x,λk,simgak)=f(x)+i∈I∑λici(x)+2σki∈E∑ci2+2σki∈I∑(max{σkμi+ci(x),0}2−σk2mui2)(10)
其为关于 x x x的连续可微函数。因此问题(8)等价于
min x ∈ R n L σ k ( x , λ k , μ k ) , \min_{x\in\mathcal{R^n}}\quad L_{\sigma_k}(x,\lambda_k,\mu_k), x∈RnminLσk(x,λk,μk),
并可以利用梯度法求解。这样做的一个好处是,我们小区了变量 s s s,从而在低维空间 R n R^n Rn中求解极小点。
对于问题(7),其最优解 x ∗ , s ∗ x^*,s^* x∗,s∗和乘子 λ ∗ , μ ∗ \lambda^*,\mu^* λ∗,μ∗满足KKT条件:
0 = ∇ f ( x ∗ ) + ∑ i ∈ E λ i ∗ ∇ c i ( x ∗ ) + ∑ i ∈ I m u i ∗ ∇ c i ( x ∗ ) , μ i ∗ ≥ 0 , i ∈ I , s i ∗ ≥ 0 , i ∈ I . \begin{aligned} 0&=\nabla f(x^*)+\sum_{i\in\mathcal{E}}\lambda_i^*\nabla c_i(x^*)+\sum_{i\in\mathcal{I}}mu_i^*\nabla c_i(x^*),\\ \mu_i^*&\ge 0,i\in\mathcal{I},\\ s_i^*&\ge 0,i\in\mathcal{I}. \end{aligned} 0μi∗si∗=∇f(x∗)+i∈E∑λi∗∇ci(x∗)+i∈I∑mui∗∇ci(x∗),≥0,i∈I,≥0,i∈I.
问题(8)的最优解 x k + 1 , s k + 1 x^{k+1},s^{k+1} xk+1,sk+1满足
0 = ∇ f ( x k + 1 ) + ∑ i ∈ E ( λ i k + σ k c i ( x k + 1 ) ) ∇ c i ( x k + 1 ) + ∑ i ∈ i ( μ i k + σ k ( c i ( x k + 1 ) + s i k + 1 ) ) ∇ c i ( x k + 1 ) , s i k + 1 = m a x { − m u i k σ k − c i ( x k + 1 ) , 0 } , i ∈ I . \begin{aligned} 0&=\nabla f(x^{k+1})+\sum_{i\in\mathcal{E}}(\lambda_i^k+\sigma_kc_i(x^{k+1}))\nabla c_i(x^{k+1})+\sum_{i\in\mathcal{i}}(\mu_i^k+\sigma_k(c_i(x^{k+1})+s_i^{k+1}))\nabla c_i(x^{k+1}),\\ s_i^{k+1}&=max\{-\frac{mu_i^k}{\sigma_k}-c_i(x^{k+1}), 0\},i\in\mathcal{I}. \end{aligned} 0sik+1=∇f(xk+1)+i∈E∑(λik+σkci(xk+1))∇ci(xk+1)+i∈i∑(μik+σk(ci(xk+1)+sik+1))∇ci(xk+1),=max{−σkmuik−ci(xk+1),0},i∈I.
对比问题(7)和问题(8)的KKT条件,易知乘子的更新格式为
λ i k + 1 = λ i k + σ k c i ( x k + 1 ) , i ∈ E μ i k + 1 = m a x { m u i k + σ k c i ( x k + 1 ) , 0 } , i ∈ I \begin{aligned} \lambda_i^{k+1}&=\lambda_i^k+\sigma_kc_i(x^{k+1}),i\in\mathcal{E}\\ \mu_i^{k+1}&=max\{mu_i^k+\sigma_kc_i(x^{k+1}), 0\},i\in\mathcal{I} \end{aligned} λik+1μik+1=λik+σkci(xk+1),i∈E=max{muik+σkci(xk+1),0},i∈I
对于等式约束,约束违反度定义为
v k ( x k + 1 ) = ∑ i ∈ E c i 2 ( x k + 1 ) + ∑ i ∈ I ( c i ( x k + 1 ) + s i k + 1 ) 2 v_k(x^{k+1})=\sqrt{\sum_{i\in\mathcal{E}}c_i^2(x^{k+1})+\sum_{i\in\mathcal{I}}(c_i(x^{k+1})+s_i^{k+1})^2} vk(xk+1)=i∈E∑ci2(xk+1)+i∈I∑(ci(xk+1)+sik+1)2
根据(9)式消去 s s s,约束违反度为
v k ( x k + 1 ) = ∑ i ∈ E c i 2 ( x k + 1 ) + ∑ i ∈ I m a x { c i ( x k + 1 ) , − μ i k σ k } v_k(x^{k+1})=\sqrt{\sum_{i\in\mathcal{E}}c_i^2(x^{k+1})+\sum_{i\in\mathcal{I}}max\{c_i(x^{k+1}),-\frac{\mu_i^k}{\sigma_k}\}} vk(xk+1)=i∈E∑ci2(xk+1)+i∈I∑max{ci(xk+1),−σkμik}
综上,我们给出优化问题(8)的增广拉格朗日函数法,见算法2,该算法与算法1结构相似,但它给出了算法参数的一种具体更新方式。每次计算出子问题的近似解 x k + 1 x^{k+1} xk+1后,算法需要判断约束违反度 v k k + 1 v_k^{k+1} vkk+1是否满足精度。若满足,则进行乘子更新,并提高子问题求解精度,此时罚因子不变;若不满足,则不进行乘子的更新,并适当增大罚因子以便得到约束违反度更小的解。
算法2:一般约束优化问题的增广拉格朗日函数法
- 选取初始点 x 0 x^0 x0,乘子 λ 0 , μ 0 \lambda^0,\mu^0 λ0,μ0,罚因子 σ 0 > 0 \sigma_0>0 σ0>0,约束违反度常数 ϵ > 0 \epsilon>0 ϵ>0,精度常数 η > 0 \eta>0 η>0,以及常数 0 < α ≤ β ≤ 1 0\lt\alpha\le\beta\le 1 0<α≤β≤1和 ρ > 1 \rho>1 ρ>1。令 η 0 = 1 σ 0 , ϵ 0 = 1 σ 0 α \eta_0=\frac{1}{\sigma_0},\epsilon_0=\frac{1}{\sigma_0^\alpha} η0=σ01,ϵ0=σ0α1以及 k = 0 k=0 k=0.
- for k=0,1,2, ⋯ \cdots ⋯do
- \quad 以 x k x^k xk为初始点,求解 min x L σ k ( x , λ k , m u k ) \min_x L_{\sigma_k}(x,\lambda_k,mu_k) minxLσk(x,λk,muk)得到满足精度条件 ∣ ∣ min x L σ k ( x , λ k , m u k ) ∣ ∣ 2 ≤ η k ||\min_x L_{\sigma_k}(x,\lambda_k,mu_k)||_2\le\eta_k ∣∣minxLσk(x,λk,muk)∣∣2≤ηk的解 x k + 1 x^{k+1} xk+1
- \quad if v k ( x k + 1 ) ≤ ϵ k v_k(x^{k+1})\le\epsilon_k vk(xk+1)≤ϵk then
- \qquad if v k ( x k + 1 ) ≤ ϵ v_k(x^{k+1})\le\epsilon vk(xk+1)≤ϵ且 ∣ ∣ min x L σ k ( x , λ k , m u k ) ∣ ∣ 2 ≤ η ||\min_x L_{\sigma_k}(x,\lambda_k,mu_k)||_2\le\eta ∣∣minxLσk(x,λk,muk)∣∣2≤η then
- \qquad \quad 得到逼近解 x k + 1 , λ k , μ k x^{k+1},\lambda^k,\mu^k xk+1,λk,μk,终止迭代。
- \qquad end if
- \qquad 更新乘子:
λ i k + 1 = λ i k + σ k c i ( x k + 1 ) , i ∈ E , μ i k + 1 = m a x { m u i k + σ k c i ( x k + 1 ) , 0 } , i ∈ I \begin{aligned} \lambda_i^{k+1} &= \lambda_i^k+\sigma_kc_i(x^{k+1}),i\in\mathcal{E},\\ \mu_i^{k+1} &= max\{mu_i^k+\sigma_kc_i(x^{k+1}), 0\}, i\in\mathcal{I} \end{aligned} λik+1μik+1=λik+σkci(xk+1),i∈E,=max{muik+σkci(xk+1),0},i∈I - \qquad 罚因子不变: σ k + 1 = σ k \sigma_{k+1}=\sigma_k σk+1=σk
- \qquad 减小子问题求解误差和约束违反度: η k + 1 = η k σ k + 1 , ϵ k + 1 = ϵ k σ k + 1 β \eta_{k+1}=\frac{\eta_k}{\sigma_{k+1}},\epsilon_{k+1}=\frac{\epsilon_k}{\sigma_{k+1}^\beta} ηk+1=σk+1ηk,ϵk+1=σk+1βϵk
- \quad else
- \qquad 乘子不变: λ k + 1 = λ k \lambda_{k+1}=\lambda_k λk+1=λk.
- \qquad 更新罚因子: σ k + 1 = ρ σ k \sigma_{k+1}=\rho\sigma_k σk+1=ρσk.
- \qquad 调整子问题求解误差和约束违反度: η k + 1 = 1 σ k + 1 , ϵ k + 1 = 1 σ k + 1 β \eta_{k+1}=\frac{1}{\sigma_{k+1}},\epsilon_{k+1}=\frac{1}{\sigma_{k+1}^\beta} ηk+1=σk+11,ϵk+1=σk+1β1
- \quad end if
- end for
三、凸优化问题的增广拉格朗日函数法
考虑凸优化问题:
min x ∈ R n f ( x ) , s . t c i ( x ) ≤ 0 , i = 1 , 2 , ⋯ , m , (11) \begin{aligned} \min_{x\in R^n}\quad &f(x),\\ s.t\quad &c_i(x)\le 0, i=1,2,\cdots,m, \end{aligned}\tag{11} x∈Rnmins.tf(x),ci(x)≤0,i=1,2,⋯,m,(11)
其中 f : R n → R , c i : R n → R , i = 1 , 2 , ⋯ , m f:R^n\rightarrow R,c_i:R^n\rightarrow R,i=1,2,\cdots,m f:Rn→R,ci:Rn→R,i=1,2,⋯,m为闭凸函数。为了叙述的方便,这里考虑不等式形式的凸优化问题。定义可行域为 χ = { x ∣ c i ( x ) ≤ 0 , i = 1 , 2 , ⋯ , m } \chi=\{x|c_i(x)\le 0, i=1,2,\cdots,m\} χ={x∣ci(x)≤0,i=1,2,⋯,m}.
对于问题(11),根据上街介绍的不等式约束的增广拉格朗日函数表达式,其增广拉格朗日函数为:
L σ ( x , λ ) = f ( x ) + σ 2 ∑ i = 1 m ( m a x { λ i σ + c i ( x ) , 0 } − λ i 2 σ 2 ) L_{\sigma}(x,\lambda)=f(x)+\frac{\sigma}{2}\sum_{i=1}^{m}(max\{\frac{\lambda_i}{\sigma}+c_i(x), 0\}-\frac{\lambda_i^2}{\sigma^2}) Lσ(x,λ)=f(x)+2σi=1∑m(max{σλi+ci(x),0}−σ2λi2)
其中 λ \lambda λ和 σ \sigma σ分别为乘子以及罚因子。
给定一系列单调递增的乘子 σ k ↑ σ ∞ \sigma_k\uparrow\sigma_{\infty} σk↑σ∞以及初始乘子 λ 0 \lambda_0 λ0,问题(11)的增广拉格朗日函数法为
x k + 1 ≈ a r g min x ∈ R n L σ k ( x , λ k ) , λ k + 1 = λ k + σ k ∇ λ L σ k ( x k + 1 , λ k ) = max { 0 , λ k + σ k c ( x k + 1 ) } (12) \begin{aligned} &x^{k+1}\approx arg\min_{x\in R^n}L_{\sigma_k}(x,\lambda_k),\\ &\lambda^{k+1}=\lambda^k+\sigma_k\nabla_{\lambda}L_{\sigma_k}(x^{k+1},\lambda_k)=\max\{0,\lambda_k+\sigma_kc(x^{k+1})\} \end{aligned}\tag{12} xk+1≈argx∈RnminLσk(x,λk),λk+1=λk+σk∇λLσk(xk+1,λk)=max{0,λk+σkc(xk+1)}(12)
为了方便叙述,一下定义 ϕ k ( x ) = L σ k ( x , λ k ) \phi_k(x)=L_{\sigma_k}(x,\lambda_k) ϕk(x)=Lσk(x,λk).由于 ϕ k ( x ) \phi_k(x) ϕk(x)的最小值点的显示表达式通常式未知的,我们往往调用迭代算法求其一个近似解。为了保证收敛性,我们要求该近似解至少满足如下非精确条件之一:
ϕ k ( x k + 1 ) − i n f ϕ k ≤ ϵ k 2 2 σ k , ϵ k ≥ 0 , ∑ k = 1 ∞ ϵ k < + ∞ (13) \phi_k(x^{k+1})-inf\phi_k\le\frac{\epsilon_k^2}{2\sigma_k},\epsilon_k\ge 0,\sum_{k=1}^{\infty}\epsilon_k\lt+\infty \tag{13} ϕk(xk+1)−infϕk≤2σkϵk2,ϵk≥0,k=1∑∞ϵk<+∞(13)
ϕ k ( x k + 1 ) − i n f ϕ k ≤ δ k 2 2 σ k ∣ ∣ λ k + 1 − λ k ∣ ∣ 2 2 , δ k > 0 , ∑ k = 1 ∞ δ k < + ∞ (14) \phi_k(x^{k+1})-inf\phi_k\le\frac{\delta_k^2}{2\sigma_k}||\lambda_{k+1}-\lambda_k||_2^2,\delta_k\gt 0,\sum_{k=1}^{\infty}\delta_k\lt+\infty \tag{14} ϕk(xk+1)−infϕk≤2σkδk2∣∣λk+1−λk∣∣22,δk>0,k=1∑∞δk<+∞(14)
d i s t ( 0 , ∂ ϕ k ( x k + 1 ) ) ≤ δ k ′ δ k ∣ ∣ λ k + 1 − λ k ∣ ∣ 2 , 0 ≤ δ k ′ → 0 , (15) dist(0,\partial\phi_k(x^{k+1}))\le\frac{\delta_k^{'}}{\delta_k}||\lambda_{k+1}-\lambda_k||_2,0\le\delta_k^{'}\rightarrow 0,\tag{15} dist(0,∂ϕk(xk+1))≤δkδk′∣∣λk+1−λk∣∣2,0≤δk′→0,(15)
其中 ϵ k , δ k , δ k ′ \epsilon_k,\delta_k,\delta_k^{'} ϵk,δk,δk′是认为设定的参数, d i s t ( 0 , ∂ ϕ k ( x k + 1 ) ) dist(0,\partial\phi_k(x^{k+1})) dist(0,∂ϕk(xk+1))表示0到集合 ∂ ϕ k ( x k + 1 ) \partial\phi_k(x^{k+1}) ∂ϕk(xk+1)的欧几里得距离,根据 λ k + 1 \lambda_{k+1} λk+1的更新格式(12)容易得知
∣ ∣ λ k + 1 − λ k ∣ ∣ 2 = ∣ ∣ m a x { 0 , λ k + σ k c ( x k + 1 ) } − λ k ∣ ∣ 2 = ∣ ∣ m a x { − λ k , σ k c ( x k + 1 ) } ∣ ∣ 2 \begin{aligned} ||\lambda_{k+1}-\lambda_k||_2 &=||max\{0,\lambda_k+\sigma_kc(x^{k+1})\}-\lambda_k||_2 \\ &=||max\{-\lambda_k,\sigma_kc(x^{k+1})\}||_2 \end{aligned} ∣∣λk+1−λk∣∣2=∣∣max{0,λk+σkc(xk+1)}−λk∣∣2=∣∣max{−λk,σkc(xk+1)}∣∣2
由于 inf ϕ k \inf\phi_k infϕk是位置的,直接验证上述不精确条件是数值上不可行的。但是,如果 ϕ k \phi_k ϕk是 α − \alpha- α−强凸函数,那么
ϕ k ( x ) − inf ϕ k ≤ 1 2 α d i s t 2 ( 0 , ∂ ϕ k ( x ) ) (16) \phi_k(x)-\inf\phi_k\le\frac{1}{2\alpha}dist^2(0,\partial\phi_k(x))\tag{16} ϕk(x)−infϕk≤2α1dist2(0,∂ϕk(x))(16)
根据(16)式,可以进一步构造如下数值可验证的不精确条件:
d i s t ( 0 , ∂ ϕ k ( x k + 1 ) ) ≤ α σ k ϵ k , ϵ k ≥ 0 , ∑ k = 1 ∞ ϵ k < + ∞ d i s t ( 0 , ∂ ϕ k ( x k + 1 ) ) ≤ α σ k δ k ∣ ∣ λ k + 1 − λ k ∣ ∣ 2 , δ k ≥ 0 , ∑ k = 1 ∞ δ k < + ∞ d i s t ( 0 , ∂ ϕ k ( x k + 1 ) ) ≤ δ k ′ σ k ∣ ∣ λ k + 1 − λ k ∣ ∣ 2 , 0 ≤ δ k ′ → 0. \begin{aligned} &dist(0,\partial\phi_k(x^{k+1}))\le\sqrt{\frac{\alpha}{\sigma_k}}\epsilon_k,\epsilon_k\ge 0,\sum_{k=1}^{\infty}\epsilon_k\lt+\infty \\ &dist(0,\partial\phi_k(x^{k+1}))\le\sqrt{\frac{\alpha}{\sigma_k}}\delta_k||\lambda_{k+1}-\lambda_k||_2,\delta_k\ge 0,\sum_{k=1}^{\infty}\delta_k\lt+\infty \\ &dist(0,\partial\phi_k(x^{k+1}))\le\frac{\delta_k^{'}}{\sigma_k}||\lambda_{k+1}-\lambda_k||_2,0\le\delta_k^{'}\rightarrow 0. \end{aligned} dist(0,∂ϕk(xk+1))≤σkαϵk,ϵk≥0,k=1∑∞ϵk<+∞dist(0,∂ϕk(xk+1))≤σkαδk∣∣λk+1−λk∣∣2,δk≥0,k=1∑∞δk<+∞dist(0,∂ϕk(xk+1))≤σkδk′∣∣λk+1−λk∣∣2,0≤δk′→0.
不精确条件下的增广拉格朗日函数法的收敛性证明这里省略。
四、基追踪问题的增广拉格朗日函数法
本小节以基追踪(BP)问题为例讨论增广拉格朗日函数法。我们见看到针对一些凸问题,增广拉格朗日函数法会有比较特殊的性质,比如固定罚因子也能保证算法的收敛性甚至有限终止性等。
设 A ∈ R m × n , b ∈ R m , x ∈ R n A\in R^{m\times n},b\in R^m,x\in R^n A∈Rm×n,b∈Rm,x∈Rn,BP问题为
min x ∈ R n ∣ ∣ x ∣ ∣ 1 , s . t . A x = b . (17) \min_{x\in R^n}\quad ||x||_1,\quad s.t.\quad Ax=b.\tag{17} x∈Rnmin∣∣x∣∣1,s.t.Ax=b.(17)
引入拉格朗日乘子 y ∈ R m y\in R^m y∈Rm,BP问题的拉格朗日函数为
L ( x , y ) = ∣ ∣ x ∣ ∣ 1 + y T ( A x − b ) L(x,y)=||x||_1+y^T(Ax-b) L(x,y)=∣∣x∣∣1+yT(Ax−b)
那么对偶函数
KaTeX parse error: Unknown column alignment: - at position 43: … \begin{array} -̲b^Ty, &||A^Ty||…
因此我们得到如下对偶问题:
min y ∈ R m b T y , s . t . ∣ ∣ A T y ∣ ∣ ∞ ≤ 1 (18) \min_{y\in R^m} b^Ty,\quad s.t. ||A^Ty||_{\infty}\le 1\tag{18} y∈RmminbTy,s.t.∣∣ATy∣∣∞≤1(18)
通过引入变量 s s s,上述问题可以等价地携程
min y ∈ R m , s ∈ R n b T y , s . t . A T y − s = 0 , ∣ ∣ s ∣ ∣ ∞ ≤ 1 (19) \min_{y\in R^m, s\in R^n} b^Ty,\quad s.t.\quad A^Ty-s=0,||s||_{\infty}\le 1 \tag{19} y∈Rm,s∈RnminbTy,s.t.ATy−s=0,∣∣s∣∣∞≤1(19)
下面讨论如何对原始问题和对偶问题应用拉格朗日函数法。
- 原始问题的增广拉格朗日函数法
引入罚因子 σ \sigma σ和乘子 λ \lambda λ,问题(17)的增广拉格朗日函数为
L σ ( x , λ ) = ∣ ∣ x ∣ ∣ 1 + λ T ( A x − b ) + σ 2 ∣ ∣ A x − b ∣ ∣ 2 2 (20) L_{\sigma}(x,\lambda)=||x||_1+\lambda^T(Ax-b)+\frac{\sigma}{2}||Ax-b||_2^2 \tag{20} Lσ(x,λ)=∣∣x∣∣1+λT(Ax−b)+2σ∣∣Ax−b∣∣22(20)
在增广拉格朗日函数法的一般理论中,需要罚因子 σ \sigma σ足够大来保证迭代收敛。对于BP问题,可以证明,对于固定的非负罚因子也能够保证收敛性(尽管在实际中动态调整罚因子可能会使算法更快收敛)。现在考虑固定罚因子 σ \sigma σ情形的增广拉格朗日函数法。在第 k k k步迭代,更新格式为
{ x k + 1 = a r g min x ∈ R n L σ ( x , λ k ) = a r g min x ∈ R n { ∣ ∣ x ∣ ∣ 1 + σ 2 ∣ ∣ A x − b + λ k σ ∣ ∣ 2 2 } λ k + 1 = λ k + σ ( A x k + 1 − b ) . (21) \left\{ \begin{array}{rcl} &x^{k+1}&=arg\min_{x\in R^n}L_{\sigma}(x,\lambda_k)=arg\min_{x\in R^n}\{||x||_1+\frac{\sigma}{2}||Ax-b+\frac{\lambda_k}{\sigma}||_2^2\} \\ &\lambda_{k+1}&=\lambda_k+\sigma(Ax^{k+1}-b). \end{array} \right.\tag{21} {xk+1λk+1=argminx∈RnLσ(x,λk)=argminx∈Rn{∣∣x∣∣1+2σ∣∣Ax−b+σλk∣∣22}=λk+σ(Axk+1−b).(21)
设迭代的初始点为 x 0 = λ 0 = 0 x^0=\lambda^0=0 x0=λ0=0。考虑迭代格式(21)中的第一步,假设 x k + 1 x^{k+1} xk+1为 L σ ( x , λ k ) L_{\sigma}(x,\lambda^k) Lσ(x,λk)的一个全局极小解,那么
0 ∈ ∂ ∣ ∣ x k + 1 ∣ ∣ 1 + σ A T ( A x k + 1 − b + λ k σ ) 0\in\partial||x^{k+1}||_1+\sigma A^T(Ax^{k+1}-b+\frac{\lambda_k}{\sigma}) 0∈∂∣∣xk+1∣∣1+σAT(Axk+1−b+σλk)
因此
− A T λ k + 1 ∈ ∂ ∣ ∣ x k + 1 ∣ ∣ 1 (22) -A^T\lambda_{k+1}\in\partial||x^{k+1}||_1\tag{22} −ATλk+1∈∂∣∣xk+1∣∣1(22)
满足上式的 x k + 1 x^{k+1} xk+1往往是不能显式得到的,因此需要采用迭代算法来进行求解,比如次梯度法或者近似点梯度法等等。
这里我们沿用之前的A和b的生成方式,选取不同的稀疏度 r = 0.1 r=0.1 r=0.1和 r = 0.2 r=0.2 r=0.2。我们固定罚因子 σ \sigma σ,并采用近似点梯度法作为求解器,不精确地求解关于 x x x的子问题得到 x k + 1 x^{k+1} xk+1。具体地,设置求解精度 η k = 1 0 − k \eta_k=10^{-k} ηk=10−k,并且使用BB步长作为线搜索的初始步长,下图展示了算法产生的迭代点与最优点的举例变化以及约束违反度的走势。从图中可以看出:对于BP问题,固定的 σ \sigma σ也可以保证增广拉格朗日函数法的收敛性
%% 基追踪问题的增广拉格朗日函数法%% 初始化和迭代准备
% 输入信息: 初始迭代点 $x^0$ 和数据 $A$, $b$,以及停机准则参数结构体 |opts| 。
%
% 输出信息: 迭代得到的解 $x$ 和包含算法求解中的相关迭代信息结构体 |out| 。
%
% * |out.feavec| :每一步外层迭代的约束违反度 $\|Ax-b\|_2$
% * |out.inn_itr| :总的内层迭代的步数(即近似点梯度法的迭代步数)
% * |out.tt| :程序运行时间
% * |out.fval| :迭代结束时的目标函数值
% * |out.itr| :外层迭代步数
% * |out.itervec| :迭代点列 $x$function [x, out] = BP_ALM(x0, A, b, opts)
%%%
% 从输入的结构体 |opts| 中读取参数或采取默认参数。
%
% * |opts.itr| :外层迭代的最大迭代步数
% * |opts.itr_inn| :内层迭代的最大迭代步数
% * |opts.sigma| :罚因子
% * |opts.tol0| :初始的收敛精度
% * |opts.gamma| :线搜索参数
% * |opts.verbose| :表示输出的详细程度, |>1| 时每一步输出, |=1| 时每一次外层循环输出, |=0| 时不输出
if ~isfield(opts, 'itr'); opts.itr = 20; end
if ~isfield(opts, 'itr_inn'); opts.itr_inn = 2500; end
if ~isfield(opts, 'sigma'); opts.sigma = 1; end
if ~isfield(opts, 'tol0'); opts.tol0 = 1e-1; end
if ~isfield(opts, 'gamma'); opts.gamma = 1; end
if ~isfield(opts, 'verbose'); opts.verbose = 2; end
sigma = opts.sigma;
gamma = opts.gamma;%%%
% 迭代准备。
k = 0;
tt = tic;
out = struct();%%%
% 计算并记录初始时刻的约束违反度。
out.feavec = norm(A*x0 - b);
x = x0;
lambda = zeros(size(b));
out.itr_inn = 0;%%%
% 记录迭代过程的优化变量 $x$ 的值。
itervec = zeros(length(x0),opts.itr);%%%
% $\sigma A^\top A$ 的最大特征值,用于估计步长。
L = sigma*eigs(A'*A,1);%% 迭代主循环
% 以 |opts.itr| 为最大迭代次数。
while k < opts.itr Axb = A*x - b;c = Axb + lambda/sigma;g = sigma*(A'*c);tmp = .5*sigma*norm(c,2)^2;f = norm(x,1) + tmp;nrmG = norm(x - prox(x - g,1),2);tol_t = opts.tol0*10^(-k);t = 1/L;Cval = tmp; Q = 1;k1 = 0;%%%% 内层循环,当最优性条件违反度小于阈值,或者超过最大内层迭代次数限制时,退出内层循环。while k1 < opts.itr_inn && nrmG > tol_t%%%% 记录上一步的结果。gp = g;xp = x;x = prox(xp - t*gp, t);nls = 1;while 1tmp = 0.5 *sigma*norm(A*x - b + lambda/sigma, 2)^2;if tmp <= Cval + g'*(x-xp) + .5*sigma/t*norm(x-xp,2)^2 || nls == 5break;end%%%% 如果没有达到线搜索标准,衰减步长,重新试探。t = 0.2*t;nls = nls + 1;x = prox(xp - t * g, t);end%%%% 退出线搜索后,更新各量的值。f = tmp + norm(x,1);nrmG = norm(x - xp,2)/t;Axb = A*x - b;c = Axb + lambda/sigma;g = sigma*(A' * c);dx = x - xp;dg = g - gp;dxg = abs(dx'*dg);if dxg > 0if mod(k,2) == 0t = norm(dx,2)^2/dxg;elset = dxg/norm(dg,2)^2;endend%%%% 取步长为上述 BB 步长和 $1/L$中的较大者,并限制在 $10^{12}$ 范围内。t = min(max(t,1/L),1e12);%%%% 计算 (Zhang & Hager) 线搜索准则中的递推常数,其满足 $C_0=f(x^0),\ C_{k+1}=(\gamma% Q_kC_k+f(x^{k+1}))/Q_{k+1}$,序列 $Q_k$ 满足 $Q_0=1,\ Q_{k+1}=\gamma% Q_{k}+1$。Qp = Q; Q = gamma*Qp + 1; Cval = (gamma*Qp*Cval + tmp)/Q;%%%% 当需要详细输出时,输出每一步的结果,利用 |k1| 记录内层迭代的迭代步数。k1 = k1 + 1;if opts.verbose > 1fprintf('itr_inn: %d\tfval: %e\t nrmG: %e\n', k1, f,nrmG);endend%%%% 每一次内层迭代结束输出当前的结果。if opts.verbosefprintf('itr_inn: %d\tfval: %e\t nrmG: %e\n', k1, f,nrmG);end%% 更新拉格朗日乘子% 在通过近似点梯度法对 $x$ 进行更新之后,对拉格朗日乘子 $\lambda$ 进行更新,迭代格式为% $\lambda^{k+1}=\lambda^k+\sigma(Ax^{k+1}-b)$。lambda = lambda + sigma*Axb;%%%% 迭代步数加 1,依次记录外层迭代后的约束违反度、每一步迭代的 $x$ 的值,更新内层迭代的总次数。k = k + 1;out.feavec = [out.feavec; norm(Axb)];itervec(:,k) = x;out.itr_inn = out.itr_inn + k1;
end%%%
% 外层迭代结束,记录输出。
out.tt = toc(tt);
out.fval = f;
out.itr = k;
out.itervec = itervec;
end%% 辅助函数
function y = prox(x,mu)
y = max(abs(x) - mu, 0);
y = sign(x) .* y;
end
主函数
%% 构造基追踪问题
% 设定随机种子。
clear;
seed = 97006855;
ss = RandStream('mt19937ar','Seed',seed);
RandStream.setGlobalStream(ss);
%%%
% 构造基追踪问题, $u$ 为问题的真实解(其稀疏度为 $0.1$),使得 $b=Au$, $x^0$ 为随机的迭代初始点。
m = 512;
n = 1024;
A = randn(m, n);
u = sprandn(n, 1, 0.1);
b = A * u;
x0 = randn(n, 1);
%%%
% 参数设定。
opts.verbose = 0;
opts.gamma = 0.85;
opts.itr = 7;
%% 求解基追踪问题
% 调用算法 |BP_ALM| 求解 BP 问题。
[x, out] = bp_alm(x0, A, b, opts);figure
stem(u)
hold on
stem(x, 'rx')
axis tight
legend('u', 'x')
求解结果如下