jstorm安装配置
- 前言
- 下载
- 配置启动
前言
jstorm介绍
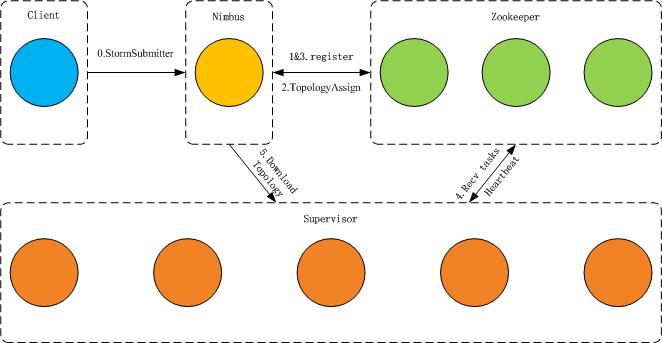
jstorm
JStorm 是一个类似Hadoop MapReduce的系统, 用户按照指定的接口实现一个任务,然后将这个任务递交给JStorm系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个Worker 发生意外故障, 调度器立即分配一个新的Worker替换这个失效的Worker。
因此,从应用的角度,JStorm应用是一种遵守某种编程规范的分布式应用。从系统角度, JStorm是一套类似MapReduce的调度系统。 从数据的角度,JStorm是一套基于流水线的消息处理机制。
实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的Hadoop MapReduce,逐渐满足不了需求,因此在这个领域需求不断。
storm组件和Hadoop组件对比
| storm | Hadoop | |
| 角色 | Nimbus | JobTracker |
| Supervisor | TaskTracker | |
| Worker | Child | |
| 应用名称 | Topology | Job |
| 编程接口 | Spout/Bolt | Mapper/Reducer |
优点
在storm和jstorm出现之前,市面上有很多实时计算引擎,但自Storm和Jstorm出现之后,基本上可以说一统江湖,其具有以下优点:
- 开发迅速:接口简单,容易上手,只要遵守Topology、Spout、Bolt的编程规范即可开发出一个扩展性极好的应用,底层Rpc、Worker之间冗余、数据分流之类的动作完全不用考虑。
- >扩展性极好:配置一下并发数,即可线性扩展性能
- >健壮性强:但worker失效或者机器出现故障时,自动分配新的worker替换失效的worker
- >数据准确性:可以采用Ack机制,保证数据不丢失。如果对精度有更高要求,采用事物机制,保证数据准确
应用场景
JStorm处理数据的方式是基于消息的流水线处理,因此特别适合无状态计算,也就是计算单元依赖的数据全部在接受的消息中可以找到,并且最好一个数据流不依赖于另一个数据流。
因此,jstorm常用于:
- >日志分析:从日志中分析出特定的数据,并将分析结果存入外部存储器,如数据库
- >管道系统:如将数据从一个系统输出到另一个系统,比如将数据从数据库同步到Hadoop
- >消息转化器:将接收到的消息按照某种格式进行转化,存储到另外一个系统,如消息中间件
- >统计分析器:从日志或消息中,提炼出某个字段,然后做count或sum计算,最后将统计值植入外部存储器
安装环境
环境:ubuntu14-64位,jdk1.7,tomcat7,zookeeper-3.4.6,jstorm2.1.0
下载
jstorm下载
从这里下载最新版Jstorm(我下载的时候是2.1.0),文件名为jstorm-2.1.0.tar.bz2。
zookeeper下载
从这里下载zookeeper3.4.6
配置
zookeeper安装配置
文件解压
cd命令进入zookeeper3.4.6所在目录,解压文件:
sudo tar -zxvf zookeeper-3.4.6.tar.gz配置环境变量
vim /etc/profile加入以下内容:
export ZOOKEEPER_HOME=/home/yyp/developTools/jstorm/zookeeper-3.4.6
export PATH=$PATH:$JSTORM_HOME/bin:$ZOOKEEPER_HOME/bin
CLASSPATH=$ZOOKEEPER_HOME/lib进入$ZOOKEEPER_HOME/conf目录,将zoo_sample.cfg重命名为zoo.cfg:
cd $ZOOKEEPER_HOME/conf
mv zoo_sample.cfg zoo.cfg对比zoo.cfg文件,将里面的内容和下面的保持一致:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=yourIP:2888:3888启动zookeeper
cd $ZOOKEEPER_HOME/bin
./zkServer.sh start 用
./zkServer.sh status 命令看到如图所示,表示我们启动成功。

jstorm安装
文件解压
进入jstorm2.1.0的压缩包所在目录,
tar -jxvf jstorm-2.1.0.tar.bz2 /the palace you want to unzip配置环境变量
打开文件~/.bashrc
vim ~/.bashrc添加如下内容:
export JSTORM_HOME=/home/yyp/developTools/jstorm/jstorm2.1.0/deploy/jstorm
export PATH=$PATH:$JSTORM_HOME/bin:$ZOOKEEPER_HOME/binJstorm配置文件
进入$JSTORM_HOME的conf目录:
cd $JSTORM_HOME/conf
vim storm.yaml我本机的内容如下:
########### These MUST be filled in for a storm configurationstorm.zookeeper.servers:- "localhost"storm.zookeeper.root: "/jstorm"# cluster.name: "default"#nimbus.host/nimbus.host.start.supervisor is being used by $JSTORM_HOME/bin/start.sh#it only support IP, please don't set hostname# For example# nimbus.host: "10.132.168.10, 10.132.168.45"#nimbus.host: "localhost"#nimbus.host.start.supervisor: false# %JSTORM_HOME% is the jstorm home directorystorm.local.dir: "%JSTORM_HOME%/data"# please set absolute path, default path is JSTORM_HOME/logs
# jstorm.log.dir: "absolute path"# java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib"# if supervisor.slots.ports is null,
# the port list will be generated by cpu cores and system memory size
# for example,
# there are cpu_num = system_physical_cpu_num/supervisor.slots.port.cpu.weight
# there are mem_num = system_physical_memory_size/(worker.memory.size * supervisor.slots.port.mem.weight)
# The final port number is min(cpu_num, mem_num)
# supervisor.slots.ports.base: 6800
# supervisor.slots.port.cpu.weight: 1.2
# supervisor.slots.port.mem.weight: 0.7
# supervisor.slots.ports: null
# supervisor.slots.ports:
# - 6800
# - 6801
# - 6802
# - 6803# Default disable user-define classloader
# If there are jar conflict between jstorm and application,
# please enable it
# topology.enable.classloader: false# enable supervisor use cgroup to make resource isolation
# Before enable it, you should make sure:
# 1. Linux version (>= 2.6.18)
# 2. Have installed cgroup (check the file's existence:/proc/cgroups)
# 3. You should start your supervisor on root
# You can get more about cgroup:
# http://t.cn/8s7nexU
# supervisor.enable.cgroup: false### Netty will send multiple messages in one batch
### Setting true will improve throughput, but more latency
# storm.messaging.netty.transfer.async.batch: true### if this setting is true, it will use disruptor as internal queue, which size is limited
### otherwise, it will use LinkedBlockingDeque as internal queue , which size is unlimited
### generally when this setting is true, the topology will be more stable,
### but when there is a data loop flow, for example A -> B -> C -> A
### and the data flow occur blocking, please set this as false
# topology.buffer.size.limited: true### default worker memory size, unit is byte
# worker.memory.size: 2147483648# Metrics Monitor
# topology.performance.metrics: it is the switch flag for performance
# purpose. When it is disabled, the data of timer and histogram metrics
# will not be collected.
# topology.alimonitor.metrics.post: If it is disable, metrics data
# will only be printed to log. If it is enabled, the metrics data will be
# posted to alimonitor besides printing to log.
# topology.performance.metrics: true
# topology.alimonitor.metrics.post: false# UI MultiCluster
# Following is an example of multicluster UI configuration
# ui.clusters:
# - {
# name: "jstorm",
# zkRoot: "/jstorm",
# zkServers:
# [ "localhost"],
# zkPort: 2181,
# }storm.yaml配置文件介绍
- storm.zookeeper.servers: 表示zookeeper 的地址,
- nimbus.host: 表示nimbus的地址
- storm.zookeeper.root: 表示jstorm在zookeeper中的根目录,当多个JStorm共享一个ZOOKEEPER时,需要设置该选项,默认即为“/jstorm”
- storm.local.dir: 表示jstorm临时数据存放目录,需要保证jstorm程序对该目录有写权限
- java.library.path: zeromq 和java zeromq library的安装目录,默认”/usr/local/lib:/opt/local/lib:/usr/lib”
- supervisor.slots.ports: 表示supervisor 提供的端口slot列表,注意不要和其他端口发生冲突,默认是68xx,而storm的是67xx
- supervisor.disk.slot: 表示提供数据目录,当一台机器有多块磁盘时,可以提供磁盘读写slot,方便有重IO操作的应用。
- topology.enable.classloader: false, 默认关闭classloader,如果应用的jar与jstorm的依赖的jar发生冲突,比如应用使用thrift9,但jstorm使用thrift7时,就需要打开classloader
- nimbus.groupfile.path: 如果需要做资源隔离,比如数据仓库使用多少资源,技术部使用多少资源,无线部门使用多少资源时,就需要打开分组功能, 设置一个配置文件的绝对路径,改配置文件如源码中group_file.ini所示
- storm.local.dir: jstorm使用的本地临时目录,如果一台机器同时运行storm和jstorm的话, 则不要共用一个目录,必须将二者分离开
安装jstorm web-UI
在提交 topology.jar的节点上(我这里是单机模式,就在当前计算机了,如果是集群模式,要在安装web-UI的机器上执行),执行以下命令:
mkdri ~/.jstorm
cp $JSTORM_HOME/conf/storm.yaml ~/.jstorm进入tomcat下面的webapps目录,
cp $JSTORM_HOME/jstorm-2.1.0.war ./
mv ROOT ROOT.old
ln -s jstorm-2.1.0 ROOT(注意,不是ln -s jstorm-2.1.0.war ROOT)
cd ../bin
./startup.sh启动jstorm
在nimbus节点上执行
jstorm nimbus &在supervisor节点上执行
jstorm supervisor &访问localhost:8080,看到如下界面,表示我们启动成功