文章目录
- 一、总述
- 二、处理流程
- 1. 处理 users 数据
- 2. 处理 movies 数据
- 3. 处理 ratings 数据
- 4. 将 users、movies 和 ratings 数据合并
- 5. one-hot 处理
- 6. 完整代码
一、总述
该文记录处理 MovieLens-1m 数据集的步骤,首先分别处理用户、电影和评分数据,接着将这三部分数据进行合并,最后 one-hot 处理。
二、处理流程
1. 处理 users 数据
users 数据描述:
用户文件有以下字段,分别是用户ID、性别、年龄、职业和邮编( UserID::Gender::Age::Occupation::Zip-code )
处理思路:
- 将用户性别 M、F 进行 label encoding 编码
- 将年龄 label encoding 编码
- 邮编取前3位
代码:
# 处理用户
users = pd.read_table('../../dataset/ml-1m/users.dat', sep='::', header=None, engine='python', encoding='utf-8').to_numpy()# 处理用户年龄和邮编
le = LabelEncoder()
users[:, 1] = le.fit_transform(users[:, 1]) # 将性别 label Encodingfor user in users: # 将年龄 Lable Encodingif user[2] == 1:user[2] = 0elif user[2] == 18:user[2] = 1 elif user[2] == 25:user[2] = 2elif user[2] == 35:user[2] = 3elif user[2] == 45:user[2] = 4elif user[2] == 50:user[2] = 5elif user[2] == 56:user[2] = 6user[4] = int(user[4][0:3]) - 1 # 取邮编的前3位user[0] -= 1 // 从 0 开始
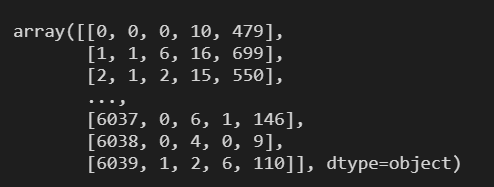
users 处理结果:
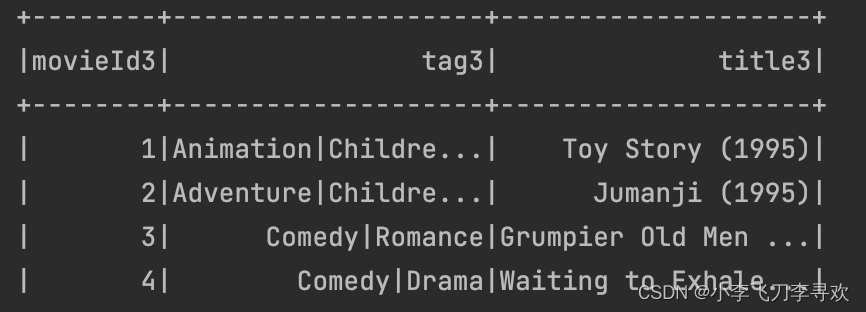
2. 处理 movies 数据
movies 数据描述:
电影文件包含三个字段,分别是电影ID、电影名、电影类型( MovieID::Title::Genres )
处理思路:
将电影名称删除,电影类型在合并users、movies和ratings之后做 one-hot 处理。
代码:
# 处理电影
movies = pd.read_table('../../dataset/ml-1m/movies.dat', sep='::', header=None, engine='python', encoding='ISO-8859-1').to_numpy()
movies = np.delete(movies, 1, axis=1) # 删除电影名称列
movies[:, 0] -= 1
movies 处理结果:

3. 处理 ratings 数据
ratings 数据描述:
电影评分文件包含用户ID、电影ID、评分和时间戳( UserID::MovieID::Rating::Timestamp )
处理思路:
- 将时间戳字段删除
- 将评分大于3的作为正样本(记为1),评分小于等于3的作为负样本(记为0)
代码:
# 处理用户评分
ratings = pd.read_table('../../dataset/ml-1m/ratings.dat', sep='::', header=None, engine='python', encoding='utf-8').to_numpy()[:, :3]
ratings[:, 0:2] -= 1for i in range(len(ratings)):ratings[i][2] = 1 if ratings[i][2] > 3 else 0
4. 将 users、movies 和 ratings 数据合并
代码:
unames = ['userId', 'gender', 'age', 'occupation', 'zipCode']
mnames = ['movieId', 'genres']
rnames = ['userId', 'movieId', 'rating']users = pd.DataFrame(users, columns=unames)
movies = pd.DataFrame(movies, columns=mnames)
ratings = pd.DataFrame(ratings, columns=rnames)data = pd.merge(movies, ratings, on=['movieId'])
data = pd.merge(users, data, on=['userId'])
数据合并结果:

5. one-hot 处理
处理思路:
- 将电影类型单独手动 one-hot 处理
- 然后将 data 中的电影类型删除,再做 one-hot 处理
代码:
data = data.values // dataframe 转 numpy
y = data[:, 7]
x = np.delete(data, -1, axis=1) # 将评分列删除
typelist = x[:, -1]
x = np.delete(x, -1, axis=1) # 将电影类型列删除# 将电影类型 one-hot 编码
genres = [] # 电影类型 ont-hot 编码
genresDict = {'Action' : 0, 'Adventure' : 1, 'Animation' : 2, "Children's" : 3, 'Comedy' : 4, 'Crime' : 5, 'Documentary' : 6, 'Drama' : 7, 'Fantasy' : 8, 'Film-Noir' : 9, 'Horror' : 10, 'Musical' : 11, 'Mystery' : 12, 'Romance' : 13, 'Sci-Fi' : 14, 'Thriller' : 15, 'War' : 16, 'Western' : 17}
for types in typelist:strs = types.split('|')tmp = np.zeros(18)for str in strs:tmp[genresDict[str]] = 1genres.append(tmp)
genres = np.array(genres)# 将 userId, gender, age, occupation, zipCode, movieId one-hot 编码
encoder = OneHotEncoder(handle_unknown='ignore')
x = encoder.fit_transform(x).toarray()
x = np.concatenate((x, genres),axis=1)
x one-hot 结果:
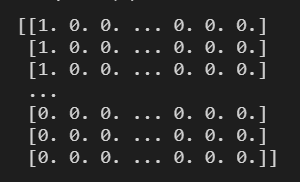
y one-hot 结果:

6. 完整代码
import numpy as np
import pandas as pd
from sklearn.preprocessing import OneHotEncoder, LabelEncoder# 处理用户
users = pd.read_table('../../dataset/ml-1m/users.dat', sep='::', header=None, engine='python', encoding='utf-8').to_numpy()# 处理用户年龄和邮编
le = LabelEncoder()
users[:, 1] = le.fit_transform(users[:, 1]) # 将性别 label Encodingfor user in users: # 将年龄 Lable Encodingif user[2] == 1:user[2] = 0elif user[2] == 18:user[2] = 1 elif user[2] == 25:user[2] = 2elif user[2] == 35:user[2] = 3elif user[2] == 45:user[2] = 4elif user[2] == 50:user[2] = 5elif user[2] == 56:user[2] = 6user[4] = int(user[4][0:3]) - 1 # 取邮编的前3位user[0] -= 1# 处理电影
movies = pd.read_table('../../dataset/ml-1m/movies.dat', sep='::', header=None, engine='python', encoding='ISO-8859-1').to_numpy()
movies = np.delete(movies, 1, axis=1) # 删除电影名称列
movies[:, 0] -= 1# 处理用户评分
ratings = pd.read_table('../../dataset/ml-1m/ratings.dat', sep='::', header=None, engine='python', encoding='utf-8').to_numpy()[:, :3]
ratings[:, 0:2] -= 1for i in range(len(ratings)):ratings[i][2] = 1 if ratings[i][2] > 3 else 0unames = ['userId', 'gender', 'age', 'occupation', 'zipCode']
mnames = ['movieId', 'genres']
rnames = ['userId', 'movieId', 'rating']
users = pd.DataFrame(users, columns=unames)
movies = pd.DataFrame(movies, columns=mnames)
ratings = pd.DataFrame(ratings, columns=rnames)
data = pd.merge(movies, ratings, on=['movieId'])
data = pd.merge(users, data, on=['userId'])data = data.values
y = data[:, 7]
x = np.delete(data, -1, axis=1) # 将评分列删除
typelist = x[:, -1]
x = np.delete(x, -1, axis=1) # 将电影类型列删除# 将电影类型 one-hot 编码
genres = [] # 电影类型 one-hot 编码
genresDict = {'Action' : 0, 'Adventure' : 1, 'Animation' : 2, "Children's" : 3, 'Comedy' : 4, 'Crime' : 5, 'Documentary' : 6, 'Drama' : 7, 'Fantasy' : 8, 'Film-Noir' : 9, 'Horror' : 10, 'Musical' : 11, 'Mystery' : 12, 'Romance' : 13, 'Sci-Fi' : 14, 'Thriller' : 15, 'War' : 16, 'Western' : 17}
for types in typelist:strs = types.split('|')tmp = np.zeros(18)for str in strs:tmp[genresDict[str]] = 1genres.append(tmp)
genres = np.array(genres)# 将 userId, gender, age, occupation, zipCode, movieId one-hot 编码
encoder = OneHotEncoder(handle_unknown='ignore')
x = encoder.fit_transform(x).toarray()
x = np.concatenate((x, genres),axis=1)