文章主要内容
本人是想做推荐算法相关的一名在校生,目前想做多模态融合,而MovieLens-1m数据集只有电影信息和用户信息,于是有想法能否在原有的电影推荐公开数据集中而外获取电影海报(图片信息)和电影简介(文本信息)做融合,为原有数据增添而外的信息,应该能提升一定推荐的准确率吧。
本文就以此为出发点,参考了一篇博客,在他的基础上补充了缺失的电影海报和简介信息。
1、数据集介绍
MovieLens-1m:
用户信息(users.dat)
人口统计学数据(用户id、年龄、职业、邮编)
6040名用户信息

电影信息(movies.dat)
这里只用了电影的部分信息(电影id、电影名、电影类型)

用户对电影的评分信息(ratings.dat)
(用户id、电影id、评分(1-5分))

2、爬取
(1)数据获取
参考该博客,其中中提供了作者爬好的大部分的电影海报和简介:
链接:https://pan.baidu.com/s/1qByOgO0sisL-lkn1hzsM-g
提取码:nd8b
该链接下载的文件格式如下:

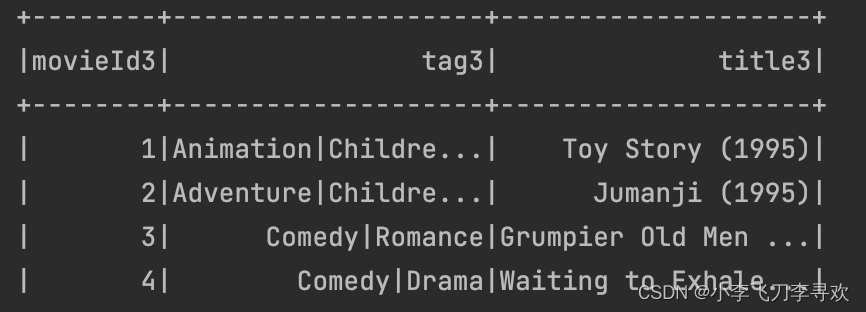
其中在info.csv中有包含电影简介(intro):

在poster文件夹下包含电影海报图片,而文件名则为电影id:

(2)检查数据的完整性
# 电影信息
import csv
import pandas as pd
import os# # 下面是按照列属性读取的
# d = pd.read_csv('./data/info.csv', usecols=['MovieID', 'intro'])
# print(d)# 这是表示读取前10行
d = pd.read_csv('./data/info.csv', usecols=['MovieID', 'name', 'intro'])
# print(d)movies_title = ['MovieID', 'Title', 'Genres']
movies = pd.read_csv('./data/movies.dat', sep='::', header=None, names=movies_title, engine = 'python')
# movies.head()data =pd.merge(movies, d)
data.head()miss_movie_id = []for x in movies['MovieID'].values:if x not in d['MovieID'].values:miss_movie_id.append(x)
print(miss_movie_id)
print(len(miss_movie_id)) # 934miss_movie_id2 = []
for x in movies['MovieID'].values:# D:\data\IMDBPoster\poster\3952.jpgimg_name = os.path.join(r'D:\data\IMDBPoster\poster',str(x)+'.jpg')if x not in d['MovieID'].values or not os.path.exists(img_name):miss_movie_id2.append(x)
print(miss_movie_id2)
print(len(miss_movie_id2)) # 945more_miss=[]
for i in miss_movie_id2:if i not in miss_movie_id:more_miss.append(i)print(more_miss)
print(len(more_miss)) # 11

由此发现,上一步获得的数据集缺失了945部电影的海报图片和简介,因此,接下来需要根据电影的id来获取电影名,在imdb网站重新根据电影名爬取电影海报和图片。
(3)获取缺失电影的url
依旧根据该博客作者提供的源码,运行该代码能获得black_list.txt文件,
这里是引用
import requests
from bs4 import BeautifulSoup
import unicodedata
import logging
import csv
import timeclass Model():def __init__(self):# 请求头self.headers = {'User-Agent': 'Mozilla/5.o (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'}# 存放每一步电影的id和imdb的idself.movie_dct = {}# 存放已经处理完的movie idself.white_lst = []# 电影详情的初始urlself.url = 'https://www.imdb.com/title/'self.movie_csv_path = '../ml-latest-small/links.csv'# 海报的保存路径self.poster_save_path = './poster'# 电影信息的保存文件self.info_save_path = './info/info.csv'# logging的配置,记录运行日志logging.basicConfig(filename="run.log", filemode="a+", format="%(asctime)s %(name)s:%(levelname)s:%(message)s",datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)# 表示当前处理的电影self.cur_movie_id = Noneself.cur_imdb_id = Nonedef get_white_lst(self):'''获取处理完的白名单'''with open('white_list') as fb:for line in fb:line = line.strip()self.white_lst.append(line)def get_movie_id(self):'''获取电影的id和imdb的id'''with open(self.movie_csv_path) as fb:fb.readline()for line in fb:line = line.strip()line = line.split(',')# 电影id 对应 imdbidself.movie_dct[line[0]] = line[1]def update_white_lst(self, movie_id):'''更新白名单'''with open('white_list', 'a+') as fb:fb.write(movie_id + '\n')def update_black_lst(self, movie_id, msg=''):with open('black_list.txt', 'a+') as fb:# 写入movie id 和imdb id,并且加上错误原因# msg=1是URL失效,msg=2是电影没有海报fb.write(movie_id + ' ' + self.movie_dct[movie_id] + ' ' + msg + '\n')def get_url_response(self, url):'''访问网页请求,返回response'''logging.info(f'get {url}')i = 0# 超时重传,最多5次while i < 5:try:response = requests.get(url, timeout=6)if response.status_code == 200:logging.info(f'get {url} sucess')# 正常获取,直接返回return response# 如果状态码不对,获取失败,返回None,不再尝试logging.error(f'get {url} status_code error: {response.status_code} movie_id is {self.cur_movie_id}')return Noneexcept requests.RequestException:# 如果超时logging.error(f'get {url} error, try to restart {i + 1}')i += 1# 重试5次都失败,返回Nonereturn Nonedef process_html(self, html):'''解析html,获取海报,电影信息'''soup = BeautifulSoup(html, 'lxml')# 名字和发布日期 如:Toy Story (1995)name = soup.find(class_='title_wrapper').h1.get_text()# 去掉html的一些/x20等空白符name = unicodedata.normalize('NFKC', name)# print(name)poster_url = ''try:# 海报的URLposter_url = soup.find(class_='poster').a.img['src']poster_re = self.get_url_response(poster_url)# 保存图片self.save_poster(self.cur_movie_id, poster_re.content)except AttributeError as e:# 如果没有海报链接,那么在黑名单中更新它# msg=2表示没有海报链接self.update_black_lst(self.cur_movie_id, '2')# 电影的基本信息 1h 21min | Animation, Adventure, Comedy | 21 March 1996 (Germany)info = []try:# 时长时间info.append(soup.find(class_='subtext').time.get_text().strip())except AttributeError as e:# 没有则添加空字符串info.append('')# 基本信息和详细发布时间 Animation, Adventure, Comedy | 21 March 1996 (Germany)for tag in soup.find(class_='subtext').find_all('a'):info.append(tag.get_text().strip())# 简介intro = soup.find(class_='summary_text').get_text().strip()intro = unicodedata.normalize('NFKC', intro)# 卡司。D W S C,分别表示 导演,编剧,明星,导演case_dict = {'D': [], 'W': [], 'S': [], 'C': []}for i, tags in enumerate(soup.find_all(class_='credit_summary_item')):for h4 in tags.find_all('h4'):title = h4.get_text()ch = title[0]for _, a in enumerate(h4.next_siblings):if a.name == 'a':case_dict[ch].append(a.get_text())for k, v in case_dict.items():# 去掉多余的信息,只保留关键人名。# 例如Pete Docter (original story by) | 6 more credits »。我们不需要|后面的字符if v and (v[-1].find('credit') != -1 or v[-1].find('full cast') != -1):case_dict[k] = case_dict[k][:-1]# 有时候导演名会用Creator代替if 'C' in case_dict.keys():case_dict['D'].extend(case_dict['C'])# id,电影名称,海报链接,时长,类型,发行时间,简介,导演,编剧,演员detail = [self.cur_movie_id, name, poster_url, info[0], '|'.join(info[1:-1]),info[-1], intro,'|'.join(case_dict['D']), '|'.join(case_dict['W']), '|'.join(case_dict['S'])]self.save_info(detail)def save_poster(self, movie_id, content):with open(f'{self.poster_save_path}/{movie_id}.jpg', 'wb') as fb:fb.write(content)def save_info(self, detail):# 存储到CSV文件中with open(f'{self.info_save_path}', 'a+', encoding='utf-8', newline='') as fb:writer = csv.writer(fb)writer.writerow(detail)def run(self):# 开始爬取信息# 先读入文件self.get_white_lst()self.get_movie_id()for movie_id, imdb_id in self.movie_dct.items():if movie_id in self.white_lst:continueself.cur_movie_id = movie_idself.cur_imdb_id = imdb_id# 休眠,防止被封IP,大概3秒处理完一部电影的信息,如果注释掉,会减少大约2.5小时的运行时间# IMDB好像没有反爬机制,可以放心的注释掉time.sleep(1)response = self.get_url_response(self.url + 'tt' + self.cur_imdb_id)# 找不到电影详情页的url,或者超时,则仅仅保留id,之后再用另一个脚本处理if response == None:self.save_info([self.cur_movie_id, '' * 9])# 仍然更新白名单,避免重复爬取这些失败的电影self.update_white_lst(self.cur_movie_id)# 更新黑名单,爬完之后用另一个脚本再处理self.update_black_lst(self.cur_movie_id, '1')continue# 处理电影详情信息self.process_html(response.content)# 处理完成,增加movie id到白名单中self.update_white_lst(self.cur_movie_id)logging.info(f'process movie {self.cur_movie_id} success')if __name__ == '__main__':s = Model()s.run()black_list.txt文件就是作者没有爬取到的电影的url:

由于之前没有注意作者提供了缺失电影的官网url,因此我手动根据电影名来获得url,构建了名为miss_movies.csv数据集:

链接:https://pan.baidu.com/s/1rR9z2RAJWAPMWPcX8T5RrA
提取码:0zh1
爬取电影海报
有了电影的url就可以正式开始爬取电影海报了:
首先先打开第一个电影链接观察网页源码:

1)发现左边的海报图片是个超链接,因此寻找其超链接的位置:即发现在{‘main’ , class_=‘ipc-page-wrapper ipc-page-wrapper–base’}里,链接的位置:{‘a’ , class_=‘ipc-lockup-overlay ipc-focusable’}中,因此得到了新的url:https://www.imdb.com/title/tt0114952/mediaviewer/rm1510947072/?ref_=tt_ov_i
2)再次访问新的url,观察网页源码,如下图:

即海报包在{‘main’ , class_=‘ipc-page-wrapper ipc-page-wrapper–baseAlt’}里,图片的链接在{‘img’,‘src’}中,因此就可以根据该链接直接下载电影海报。
爬取电影海报的完整代码如下:
from bs4 import BeautifulSoup
import requests
import urllib.request
import time
import logging
import random
import urllib3
from lxml import etree
from fake_useragent import UserAgentblack_list_name = []
black_list_img = []
white_list_name = []
white_list_img = []def update_white_lst(movie_id , filename):'''更新白名单'''with open('./white_black_file/' + filename, 'a+') as fb:fb.write(movie_id + '\n')def update_black_lst(movie_id , filename):with open('./white_black_file/' + filename, 'a+') as fb:# 写入movie id 和imdb id,并且加上错误原因# msg=1是URL失效,msg=2是电影没有海报fb.write(movie_id + '\n')def get_url(filename):url_dict = {}with open(filename, encoding='utf-8') as fb:fb.readline()for line in fb:if line.strip() == '':continue# print(line.strip().split(','))movie_id = line.strip().split(',')[0]# print(movie_id)movie_url = line.strip().split(',')[-1]# print(movie_url)url_dict[movie_id] = movie_urlreturn url_dictdef save_poster(id , url):# 获取表头session = requests.session()headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36','Connection': 'close'}# headers = {'user-agent': 'Mozilla/5.0 (Windows Phone 10.0; Android 4.2.1; Microsoft; Lumia 550) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Mobile Safari/537.36 Edge/14.14263','Connection': 'close'}# # 更换usa:表头# headers = {}# user_agent_list = [# "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",# "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",# "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",# "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",# "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",# "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",# ]# headers['User-Agent'] = random.choice(user_agent_list)# # imdb网页搜索电影名的网页url# url = "https://www.imdb.com/title/tt0020697/?ref_=nv_sr_srsg_0"# 模仿浏览器请求网页申请requests.adapters.DEFAULT_RETRIES = 5# 读取ip池f = open("./useful_ip.txt", "r")file = f.readlines()# 遍历并分别存入列表,方便随机选取IPitems = []for a in file:items.append('HTTP://' + a)ip = random.choice(items) # 随机选取一个IPproxies = {}proxies['HTTP'] =ip[:-1]proxies['HTTPS'] = 'HTTPS://'+ ip[7:-1]f.close()print(proxies)urllib3.disable_warnings()try:r = session.get(url, headers=headers, proxies=proxies , verify=False)print(r.status_code) # 输出状态码 200,表示访问成功except:r = session.get(url, headers=headers, proxies=proxies , verify=False)time.sleep(1)requests.adapters.DEFAULT_RETRIES = 5# 获取html源码并转为utf-8格式html = r.content.decode('utf-8', 'ignore')# 使用BeautifulSoup对html以lxml格式保存,方便检索my_page = BeautifulSoup(html, 'lxml')# imdb首页urlurl_header = 'https://www.imdb.com'# 获取html源码中所有的'main',class='ipc-page-wrapper ipc-page-wrapper--base'部分的源码print('--------------------'+str(id)+'-----------------------')for tag in my_page.find_all('main' , class_='ipc-page-wrapper ipc-page-wrapper--base'):# 获取电影名部分的源码try:name_h1 = tag.find('h1' , class_='sc-b73cd867-0 eKrKux')# 获取包含的文本,即电影名name = name_h1.textprint('name:'+name)white_list_name.append(id)update_white_lst(id , 'white_list_name.txt')except AttributeError as e:black_list_name.append(id)update_black_lst(id , 'black_list_name.txt')try:# 获取电影海报部分的源码img = tag.find('a' , class_='ipc-lockup-overlay ipc-focusable')# 获取该部分中'href'的内容:即海报的urlimg_url_tail = img.get('href')# 获得完整的海报urlimg_url = url_header + img_url_tailprint('img_url:'+img_url)white_list_img.append(id)update_white_lst(id, 'white_list_img.txt')except AttributeError as e:black_list_img.append(id)update_black_lst(id, 'black_list_img.txt')# if id in black_list_img:# continueprint('再次获取海报url网页')# 再次获取海报url网页的请求session2 = requests.session()requests.adapters.DEFAULT_RETRIES = 5try:r2 = session2.get(img_url, headers=headers, proxies=proxies , verify=False)print('r2 status_code:'+r2.status_code) # 输出状态码 200,表示访问成功except:r2 = session2.get(img_url, headers=headers, proxies=proxies, verify=False)html2 = r2.content.decode('utf-8' , 'ignore')img_page = BeautifulSoup(html2, 'lxml')print('获取海报图片的源码')print('$$$$$$$$$$$')# print(img_page.find_all('main' , class_='ipc-page-wrapper ipc-page-wrapper--baseAlt'))# 获取海报图片的源码for tag2 in img_page.find_all('main' , class_='ipc-page-wrapper ipc-page-wrapper--baseAlt'):try:img2 = tag2.find('img')# print('img2:'+img2)time.sleep(1)# 获取图片的可下载urlimg2_url = img2.get('src')print('img2_url:'+img2_url)# url = 'https://m.media-amazon.com/images/M/MV5BZTI4OTkzOWYtZjhiMi00YTYzLThkYWUtMWMwNmQzOTkxOGU3XkEyXkFqcGdeQXVyNDE5MTU2MDE@._V1_.jpg'# 将海报图片下载到filename中urllib.request.urlretrieve(img2_url,filename=r"./image/" + id + ".jpg")# 清除缓存urllib.request.urlcleanup()except AttributeError as e:print(' in black_list_img.txt')black_list_img.append(id)update_black_lst(id, 'black_list_img.txt')def run(filename = r'./miss_movies.csv'):url_dict = get_url(filename)for movie_id , movie_url in url_dict.items():if int(movie_id) != 3935:continueprint("!!!!!!!!!!"+str(movie_id)+"!!!!!!!!")save_poster(movie_id , movie_url)if __name__ == '__main__':run()这里需要注意的问题是由于imdb网站有反爬机制,因此用到以下四种方式来解决:
(1)构建黑白名单:【白名单:保存已经爬到的电影海报id】、【黑名单:保存爬取失败的电影海报id】
(2)使用多个表头(usa)
(3)通过构建ip池,从而每次爬取时都更换不同的ip
(4)使用不同手机开热点(其本质应该也是第三点,实际效果比第二第三个方法有效)
第三点中的useful_ip.txt文件链接:
链接:https://pan.baidu.com/s/1WgMI95evnbqVJ9-XKifjUQ
提取码:swyj
该文件保存了目前有效的几个ip地址,你也可以构建自己的ip池。
(4)爬取电影简介
其基本原理和爬取电影海报基本一样,不同的就是简介在网页源码的位置不同罢了,可以自己照着第三步尝试,不懂的也可以私信我。