文章目录
- 基于协同过滤的电影推荐系统
- 数据集
- HTML页面分析
- 爬虫代码
- 运行时间
- 百度网盘链接
基于协同过滤的电影推荐系统
用这个数据集实现了一个小型的电影推荐网站,GitHub代码
数据集
数据集是MovieLens提供的ml-latest-small
https://grouplens.org/datasets/movielens/
试了几个数据集,这个数据集效果比较好
10万条评分记录,3600个用户对电影打的标签,9000部电影,600个用户
数据集的格式是这样的
link.csv :存放电影的imdb id和tmdb id
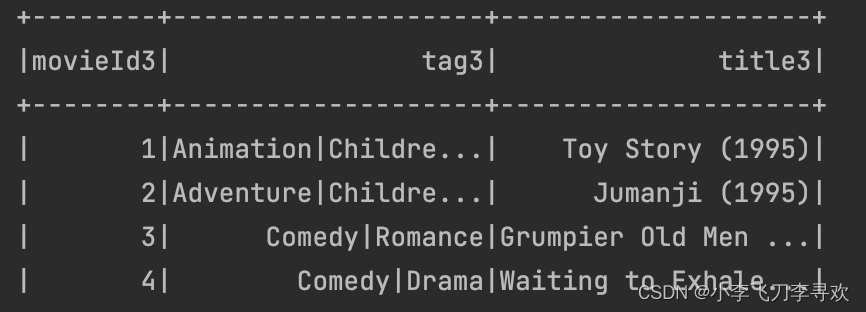
movies.csv :存放电影的id 名称 类型
ratings.csv :用户对电影的评分,范围是0.5~5
tags.csv :用户对电影打的标签
link.csv文件是这样的格式:

HTML页面分析
我刚看的时候不明白imdbID是什么意思,后面访问IMBD网站发现,这里的imdbID就是URL里面的标识符
有了link.csv文件里面的imdbID,我们就可以访问到这部电影在IMDB上面的详情页面了(这个数据集也太爽了😄👍)
仔细看这个页面,红框里面是我们需要爬取的信息

这里就不分析了,不然篇幅有点长了,具体看代码就行。自己可以f12看一下页面的组织结构
爬虫代码
爬虫我用的库是requests和BeautifulSoup,其它库没有用的原因是不会,BS4用起来挺顺手的
需要注意的是,我们爬到的是海报的URL,所以在爬信息的过程中还需要再爬一次,发起请求把海报下载下来。下图中,src存储的就是海报的链接

上述分析过程中可以知道,构造请求应该独立成一个函数,因为第一次爬电影信息要用,第二次爬电影海报要用
下面贴一下代码:
我都是把爬虫包装在一个类里面,这个类的函数结构:

解释一下为什么有white_lst和black_lst这两个奇怪的东西:
下面的爬虫代码我改了很多遍,它的异常处理结构是最后才改好的,也就是说中途会有报错,我需要把bug改好然后继续运行爬虫爬取剩下的电影信息。但是呢,没报错之前已经爬取了一些电影了,我就不需要重头爬了,因此我用一个white_lst来存放已经爬取完成的电影信息。
black_lst是用来存放爬取过程中出错的电影,例如ImdbID失效啊(很少),没有海报信息啊(有几部是这样的),整个数据集爬取完后,再处理这个black_lst里面的电影(最后我发现大概就十部不到的电影出错,于是我就手动处理了)
下图是运行日志中记录的爬取出错的电影

import requests
from bs4 import BeautifulSoup
import unicodedata
import logging
import csv
import timeclass Model():def __init__(self):# 请求头self.headers = {'User-Agent': 'Mozilla/5.o (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'}# 存放每一步电影的id和imdb的idself.movie_dct = {}# 存放已经处理完的movie idself.white_lst = []# 电影详情的初始urlself.url = 'https://www.imdb.com/title/'self.movie_csv_path = '../ml-latest-small/links.csv'# 海报的保存路径self.poster_save_path = './poster'# 电影信息的保存文件self.info_save_path = './info/info.csv'# logging的配置,记录运行日志logging.basicConfig(filename="run.log", filemode="a+", format="%(asctime)s %(name)s:%(levelname)s:%(message)s",datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)# 表示当前处理的电影self.cur_movie_id = Noneself.cur_imdb_id = Nonedef get_white_lst(self):'''获取处理完的白名单'''with open('white_list') as fb:for line in fb:line = line.strip()self.white_lst.append(line)def get_movie_id(self):'''获取电影的id和imdb的id'''with open(self.movie_csv_path) as fb:fb.readline()for line in fb:line = line.strip()line = line.split(',')# 电影id 对应 imdbidself.movie_dct[line[0]] = line[1]def update_white_lst(self, movie_id):'''更新白名单'''with open('white_list', 'a+') as fb:fb.write(movie_id + '\n')def update_black_lst(self, movie_id, msg=''):with open('black_list.txt', 'a+') as fb:# 写入movie id 和imdb id,并且加上错误原因# msg=1是URL失效,msg=2是电影没有海报fb.write(movie_id + ' ' + self.movie_dct[movie_id] + ' ' + msg + '\n')def get_url_response(self, url):'''访问网页请求,返回response'''logging.info(f'get {url}')i = 0# 超时重传,最多5次while i < 5:try:response = requests.get(url, timeout=6)if response.status_code == 200:logging.info(f'get {url} sucess')# 正常获取,直接返回return response# 如果状态码不对,获取失败,返回None,不再尝试logging.error(f'get {url} status_code error: {response.status_code} movie_id is {self.cur_movie_id}')return Noneexcept requests.RequestException:# 如果超时logging.error(f'get {url} error, try to restart {i + 1}')i += 1# 重试5次都失败,返回Nonereturn Nonedef process_html(self, html):'''解析html,获取海报,电影信息'''soup = BeautifulSoup(html, 'lxml')# 名字和发布日期 如:Toy Story (1995)name = soup.find(class_='title_wrapper').h1.get_text()# 去掉html的一些/x20等空白符name = unicodedata.normalize('NFKC', name)# print(name)poster_url = ''try:# 海报的URLposter_url = soup.find(class_='poster').a.img['src']poster_re = self.get_url_response(poster_url)# 保存图片self.save_poster(self.cur_movie_id, poster_re.content)except AttributeError as e:# 如果没有海报链接,那么在黑名单中更新它# msg=2表示没有海报链接self.update_black_lst(self.cur_movie_id, '2')# 电影的基本信息 1h 21min | Animation, Adventure, Comedy | 21 March 1996 (Germany)info = []try:# 时长时间info.append(soup.find(class_='subtext').time.get_text().strip())except AttributeError as e:# 没有则添加空字符串info.append('')# 基本信息和详细发布时间 Animation, Adventure, Comedy | 21 March 1996 (Germany)for tag in soup.find(class_='subtext').find_all('a'):info.append(tag.get_text().strip())# 简介intro = soup.find(class_='summary_text').get_text().strip()intro = unicodedata.normalize('NFKC', intro)# 卡司。D W S C,分别表示 导演,编剧,明星,导演case_dict = {'D': [], 'W': [], 'S': [], 'C': []}for i, tags in enumerate(soup.find_all(class_='credit_summary_item')):for h4 in tags.find_all('h4'):title = h4.get_text()ch = title[0]for _, a in enumerate(h4.next_siblings):if a.name == 'a':case_dict[ch].append(a.get_text())for k, v in case_dict.items():# 去掉多余的信息,只保留关键人名。# 例如Pete Docter (original story by) | 6 more credits »。我们不需要|后面的字符if v and (v[-1].find('credit') != -1 or v[-1].find('full cast') != -1):case_dict[k] = case_dict[k][:-1]# 有时候导演名会用Creator代替if 'C' in case_dict.keys():case_dict['D'].extend(case_dict['C'])# id,电影名称,海报链接,时长,类型,发行时间,简介,导演,编剧,演员detail = [self.cur_movie_id, name, poster_url, info[0], '|'.join(info[1:-1]),info[-1], intro,'|'.join(case_dict['D']), '|'.join(case_dict['W']), '|'.join(case_dict['S'])]self.save_info(detail)def save_poster(self, movie_id, content):with open(f'{self.poster_save_path}/{movie_id}.jpg', 'wb') as fb:fb.write(content)def save_info(self, detail):# 存储到CSV文件中with open(f'{self.info_save_path}', 'a+', encoding='utf-8', newline='') as fb:writer = csv.writer(fb)writer.writerow(detail)def run(self):# 开始爬取信息# 先读入文件self.get_white_lst()self.get_movie_id()for movie_id, imdb_id in self.movie_dct.items():if movie_id in self.white_lst:continueself.cur_movie_id = movie_idself.cur_imdb_id = imdb_id# 休眠,防止被封IP,大概3秒处理完一部电影的信息,如果注释掉,会减少大约2.5小时的运行时间# IMDB好像没有反爬机制,可以放心的注释掉time.sleep(1)response = self.get_url_response(self.url + 'tt' + self.cur_imdb_id)# 找不到电影详情页的url,或者超时,则仅仅保留id,之后再用另一个脚本处理if response == None:self.save_info([self.cur_movie_id, '' * 9])# 仍然更新白名单,避免重复爬取这些失败的电影self.update_white_lst(self.cur_movie_id)# 更新黑名单,爬完之后用另一个脚本再处理self.update_black_lst(self.cur_movie_id, '1')continue# 处理电影详情信息self.process_html(response.content)# 处理完成,增加movie id到白名单中self.update_white_lst(self.cur_movie_id)logging.info(f'process movie {self.cur_movie_id} success')if __name__ == '__main__':s = Model()s.run()运行时间
一部电影爬取大概要3~5秒的时间,因为中间额外的保存海报,所以会花1到2s的时间,写日志、写文件也需要一些时间。
最快时间: 9700 ∗ 3 / 3600 ≈ 8 h 9700*3/3600 \approx 8h 9700∗3/3600≈8h 所以最好放到云服务器上面跑。如果你会多进程加速的话也可以试着改进一下(顺便贴在评论教我一下😄)
百度网盘链接
ok看到这里,如果你不想花那么多时间自己跑,我提供我运行后的文件和代码,你可以直接使用
下图中的info.csv和poster,分别是电影的详细信息和电影的海报
海报的命名都是用imdbID来标识的
链接:https://pan.baidu.com/s/1qByOgO0sisL-lkn1hzsM-g
提取码:nd8b
复制这段内容后打开百度网盘手机App,操作更方便哦