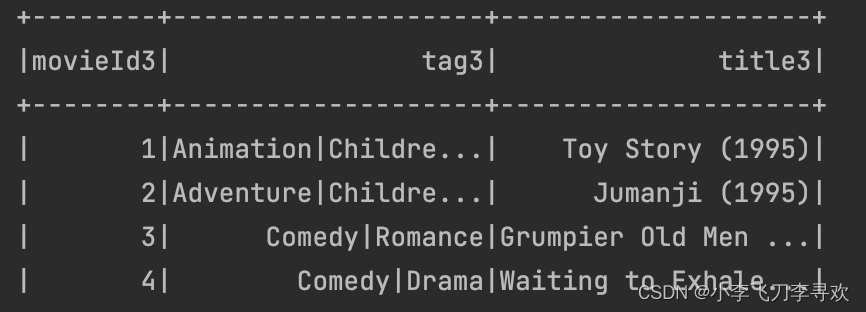
有一个定律,对于内容的访问遵循80/20原则,也就是20%的内容,会占有80%的访问量。就是zipf分布[1]。
根据MovieLens的数据集中的ratings.dat,我做了数据处理,获取得分最高的2000个条目。
ml-pro.py
import os
import heapq
from datetime import datetime
kMonthInSecond=30*24*60*60
def getUserInfo(filename,id,col,sep='::'):ret=[]with open(filename,'r') as f:for line in f.readlines():lineArr= line.strip().split(sep)if int(lineArr[0])==id:ret.append(lineArr[col])return ret
def unixTime2date(ts):return datetime.utcfromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
def getStartAndEnd(filename,col,sep='::'):minV=0maxV=0with open(filename,'r') as f:for line in f.readlines():lineArr= line.strip().split(sep)v=int(lineArr[col])if minV==0 and maxV==0:minV=maxV=velse:if v<minV:minV=vif v>maxV:maxV=vreturn minV,maxV
class Score(object):def __init__(self,id,v=0,c=0):self.id=idself.v=vself.count=cdef __lt__(self, other):if self.v<other.v:return Trueelse:return False
def processTopKRate(filename,dst,K,sep='::'):rate_dict={}heap=[]maxV=0poll_num=0with open(filename,'r') as f:for line in f.readlines():lineArr= line.strip().split(sep)id=int(lineArr[1])score=int(lineArr[2])obj=rate_dict.get(id)poll_num=poll_num+1if obj is None:rate_dict.update({id:Score(id,score,1)})else:obj.v=obj.v+scoreobj.count=obj.count+1if maxV is 0 or obj.v>maxV:maxV=obj.vif K>len(rate_dict):K=len(rate_dict)for item in rate_dict.items():heapq.heappush(heap, item[1])if len(heap)>K:heapq.heappop(heap)heap.sort(reverse=True)print(maxV)with open(dst,'w') as f:i=1accum=0for s in heap:accum=accum+s.countratio=100.0*accum/poll_numf.write(str(i)+"\t"+str(s.id)+"\t"+str(s.v)+"\t"+str(ratio)+"\n")i=i+1return heap
def processMovieTime(filename,movieId,col=3,sep='::'):minV=0maxV=0with open(filename,'r') as f:for line in f.readlines():lineArr= line.strip().split(sep)index=int(lineArr[1])v=int(lineArr[col])if index==movieId:if minV==0 and maxV==0:minV=maxV=velse:if v<minV:minV=vif v>maxV:maxV=vif maxV>minV:dst="movie_"+str(movieId)+".txt"slot=(maxV-minV+kMonthInSecond-1)/kMonthInSecondcount=[]for i in range(slot):count.append(0)with open(filename,'r') as f:for line in f.readlines():lineArr= line.strip().split(sep)index=int(lineArr[1])v=int(lineArr[col])if index==movieId: i=(v-minV)/kMonthInSecondcount[i]=count[i]+1with open(dst,'w') as f:i=1for v in count:f.write(str(i)+"\t"+str(v)+"\n")i=i+1return minV,maxV
if __name__=='__main__':filename="ratings.dat"data=getUserInfo(filename,1,3)minV,maxV=getStartAndEnd(filename,1)print(minV,maxV)res=processTopKRate(filename,"res.txt",2000)processMovieTime(filename,res[0].id)processMovieTime(filename,res[1].id)processMovieTime(filename,res[2].id)processMovieTime(filename,res[3].id)processMovieTime(filename,res[4].id)
绘图脚本score-plot.sh:
#! /bin/sh
file1=res.txt
output=out
gnuplot<<!
set xlabel "index"
set ylabel "score"
set xrange [0:2000]
set yrange [0:15000]
set term "png"
set output "${output}.png"
plot "${file1}" u 1:3 title "flow1" with lines lw 2 lc 1
set output
exit
!
结果out.png:

大概有4000个电影id。上图中,当index为1200时,已经累计有80%的用户打分。内容占据比例:1200/4000=30%。
函数processMovieTime处理用户对电影的打分时间,unix时间转化成月份序号。
绘图脚本,req-plot.sh
#! /bin/sh
file1=movie_260.txt
file2=movie_1196.txt
file3=movie_1210.txt
file4=movie_2028.txt
file5=movie_2858.txt
output=req
gnuplot<<!
set xlabel "index"
set ylabel "score"
set xrange [0:40]
set yrange [0:800]
set term "png"
set output "${output}.png"
plot "${file1}" u 1:2 title "movie1" with lines lw 2 lc 1,\
"${file2}" u 1:2 title "movie2" with lines lw 2 lc 2,\
"${file3}" u 1:2 title "movie3" with lines lw 2 lc 3,\
"${file4}" u 1:2 title "movie3" with lines lw 2 lc 4,\
"${file5}" u 1:2 title "movie3" with lines lw 2 lc 5
set output
exit
!
结果:

Reference
[1]Zipf分布
[2]推荐系统–MovieLens数据集