介绍
movielens数据集是电影推荐数据集,数据集有多种大小和目的使用的数据集。按照使用目的可以分为两类,一类数据集适用于推进最新研究的数据,一类数据集是用于高校研究和教育科研使用的数据集。本次介绍三个数据集的使用和处理。
数据集下载链接:MovieLens | GroupLens
数据集
每个数据集都有readme.txt文件介绍,每列数据的用途和含义。
1. MovieLens Latest Datasets数据集
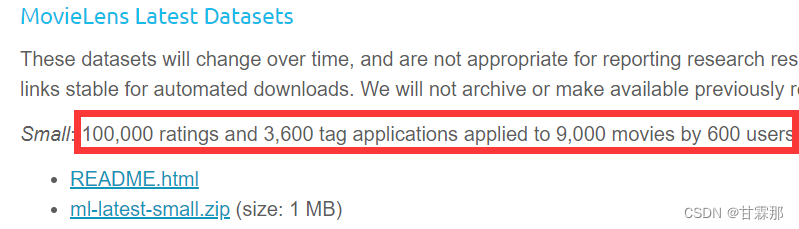
该数据集包含的文件如下:
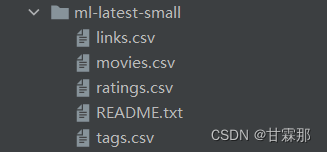
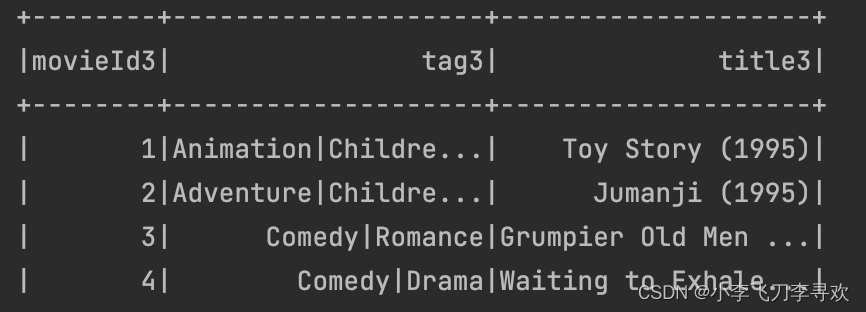
其中的links包含的是不同的url对电影的标签,这在readme.txt文件里有所介绍。movies.csv文件里包含的是电影标签、标题和电影类型,rating则包含的是用户对电影的评分,数据是整数,tags是用户对电影的评价。
2.MovieLens 1M Dataset数据集

该数据集包含的数据文件如下:
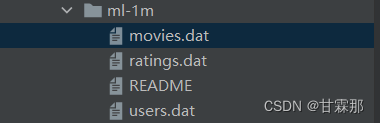
movies.dat文件里包含的是电影标签、标题和电影类型,rating则包含的是用户对电影的评分,数据是整数,还包含的评论的时间戳。user.dat包含的是对用户信息的保存,包括以下内容:
即包含了ID、年龄、性别、职业等,其中年龄是按照年龄段区分的。
3.MovieLens 100k Dataset数据集

100k数据集有点不同,其用户属性是单独一个文件。另外还有u1到u5五份数据(五折交叉验证,已经给分好了)。该数据集包括了943位用户对1682部电影的评分信息(总共100,000),评分也是1-5的整数
数据集结构如下:
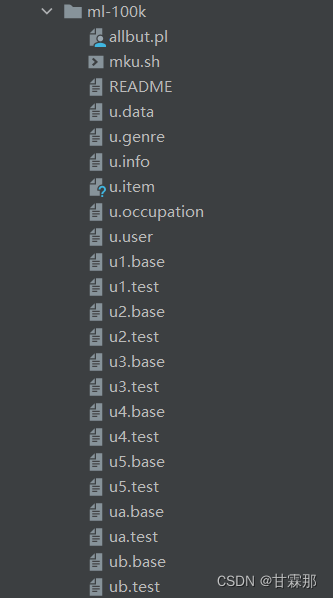
u.data文件包含了100,000条评分信息,每条记录的形式:user id | item id | rating | timestamp.(分隔符是一个tab),u1.base和u1.test是一组训练集和测试集,u1到u5是把u.data分成了5份(用于五折交叉验证实验)。可以通过运行mku.sh重新生成一组u1到u5(原来的会被覆盖), ua和ub是把u.data分成了两份。每一份又分成了训练集和测试集。同样可以通过mku.sh重新生成一组ua和ub,mku.sh文件, 每运行一次,就会随机生成一组u1--u5、ua、ub的数据集。(所以非必要不要用,不然每次实验的数据都不一样)
处理代码
对100k数据集的处理代码如下,分别对数据集进行了输出,对年龄段进行分类,对性别进行映射,对工作和职业进行了数字映射。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ = 'QiuZiXian' http://blog.csdn.net/qqzhuimengren/ 1467288927@qq.com
# @time :2020/9/14 0:07
# @abstract :import pandas as pd# 粗略查看数据信息
u_data = pd.read_csv('D:/d/python/ml-100k/u.data')
u_genre = pd.read_csv('D:/d/python/ml-100k/u.genre')
u_info = pd.read_csv('D:/d/python/ml-100k/u.info')
#u_item = pd.read_csv('D:/d/python/ml-100k/u.item')
u_occupation = pd.read_csv('D:/d/python/ml-100k/u.occupation')
u_user = pd.read_csv('D:/d/python/ml-100k/u.user')print(u_data.head())
print(u_user.head())# 去掉occupation为none的记录
nones = u_user[u_user['occupation'] == 'none']
u_user = u_user.drop(nones.index)# gender中的m、f映射成0、 1
u_user['gender'] = u_user['gender'].map({'M':1, 'F':0})
print(u_user.head())# 对age进行分段,映射成7组
def age_map(age):if age >= 1 and age <= 7: return 1if age >= 8 and age <=16: return 2if age >=17 and age <= 29: return 3if age >= 30 and age <= 39: return 4if age >= 40 and age <= 49: return 5if age >= 50 and age <= 59: return 6if age >= 60: return 7u_user['age'] = u_user['age'].apply(lambda age : age_map(age))
print(u_user.head())# occupation字段数值化
def occupations_map(occupation):occupations_dict = {'technician': 1,'other': 0,'writer': 2,'executive': 3,'administrator': 4,'student': 5,'lawyer': 6,'educator': 7,'scientist': 8,'entertainment': 9,'programmer': 10,'librarian': 11,'homemaker': 12,'artist': 13,'engineer': 14,'marketing': 15,'none': 16,'healthcare': 17,'retired': 18,'salesman': 19,'doctor': 20}return occupations_dict[occupation]
u_user['occupation'] = u_user['occupation'].apply(lambda occupation : occupations_map(occupation))
print(u_user.head())
# zip_code提取前3位
u_user['zip_code'] = u_user['zip_code'].apply(lambda zip_code : str(zip_code)[:3])
# 处理好的数据保存,留待后续直接使用
对MovieLens Latest Datasets数据集,即最新的小数据集提取出用户的点击关系的代码如下:
import pandas as pd
import numpy as npdf = pd.read_csv('ratings.csv')
users=set(df['userId'].tolist())
movies=set(df['movieId'].tolist())
print("一共有{}条数据 {}个用户 {}部电影".format(len(df),len(users),len(movies)))
print("评分在0~1之间有{}条数据".format(len(df.loc[(df['rating']>=0.0)&(df['rating']<=1.0)])))
print("评分在1~2之间有{}条数据".format(len(df.loc[(df['rating']>1.0)&(df['rating']<=2.0)])))
print("评分在2~3之间有{}条数据".format(len(df.loc[(df['rating']>2.0)&(df['rating']<=3.0)])))
print("评分在3~4之间有{}条数据".format(len(df.loc[(df['rating']>3.0)&(df['rating']<=4.0)])))
print("评分在4~5之间有{}条数据".format(len(df.loc[(df['rating']>4.0)&(df['rating']<=5.0)])))with open("train.txt", "w") as f1:with open("test.txt", "w") as f2:for i in range(0,len(users),1):temp_list=df.loc[df['userId']==i+1]temp_list=temp_list.sample(frac=1,random_state=2022)train_list=pd.concat(np.array_split(temp_list,10)[0:8],axis=0).sort_values(by='rating',ascending=False)test_list=pd.concat(np.array_split(temp_list,10)[8:],axis=0).sort_values(by='rating',ascending=False)train=train_list['movieId'].tolist()test=test_list['movieId'].tolist()f1.write(str(i)+' '+(str(train).replace('[','').replace(']','')).replace("'",'').replace(',','') +'\n')f2.write(str(i)+' '+(str(test).replace('[','').replace(']','')).replace("'",'').replace(',','') +'\n')f2.close()
f1.close()数据集中的电影的ID并非连续,如果要转化为连续的电影ID需要经过以下处理:
import pandas as pd
import numpy as npdf = pd.read_csv('ratings.csv')
users=set(df['userId'].tolist())
movies=set(df['movieId'].tolist())
print("一共有{}条数据 {}个用户 {}部电影".format(len(df),len(users),len(movies)))
print("评分在0~1之间有{}条数据".format(len(df.loc[(df['rating']>=0.0)&(df['rating']<=1.0)])))
print("评分在1~2之间有{}条数据".format(len(df.loc[(df['rating']>1.0)&(df['rating']<=2.0)])))
print("评分在2~3之间有{}条数据".format(len(df.loc[(df['rating']>2.0)&(df['rating']<=3.0)])))
print("评分在3~4之间有{}条数据".format(len(df.loc[(df['rating']>3.0)&(df['rating']<=4.0)])))
print("评分在4~5之间有{}条数据".format(len(df.loc[(df['rating']>4.0)&(df['rating']<=5.0)])))df.sort_values("movieId", inplace=True)
pointer=0
movies=sorted(movies)
for i in movies:df.loc[df['movieId'] == i,'movieId']=pointerpointer+=1with open("train.txt", "w") as f1:with open("test.txt", "w") as f2:for i in range(0,len(users),1):temp_list=df.loc[df['userId']==i+1]temp_list=temp_list.sample(frac=1,random_state=2022)train_list=pd.concat(np.array_split(temp_list,10)[0:8],axis=0).sort_values(by='rating',ascending=False)test_list=pd.concat(np.array_split(temp_list,10)[8:],axis=0).sort_values(by='rating',ascending=False)train=train_list['movieId'].tolist()test=test_list['movieId'].tolist()f1.write(str(i)+' '+(str(train).replace('[','').replace(']','')).replace("'",'').replace(',','') +'\n')f2.write(str(i)+' '+(str(test).replace('[','').replace(']','')).replace("'",'').replace(',','') +'\n')f2.close()
f1.close()参考链接:movielens数据集介绍及使用python简单处理_PythonJavaC++go的博客-CSDN博客_movielens数据处理