掌握pandas基本语法操作「pandas基础入门中有详细语法格式」后,就可以利用pandas做一些简单实例的数据处理。
Movie电影数据分析
首先需要下载电影数据集MovieLens,这个数据集中包含用户数据;电影数据;电影评分表。电影数据中包含了电影id,电影名,电影类型。这个数据集中的数据都经过了预处理,保证一个用户至少对20个电影进行了评分。
导入数据
首先,通过pandas将电影数据导入程序中。
要想读用户信息,需要把用户表数据的标题先表示出来;读列表的第一个参数是文件名,因为没有表头,因此需要设置header为空。
unames = ['user_id','gender','age','occupation','zip']
users = pd.read_table('ml-1m/users.dat',sep = '::',header = None,names = unames)
同理将电影数据和电影评分数据也导入到程序;
rating_names = ['users_id','movie_id','rating','timestamp']
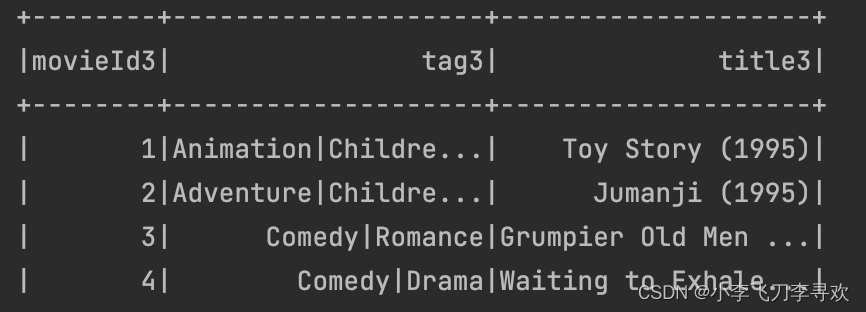
ratings = pd.read_table('ml-1m/users.dat',sep = '::',header = None,names = rating_names)movie_names = ['movie_id','title','genres']
movies = pd.read_table('ml-1m/users.dat',sep = '::',header = None,names = movie_names)
通过print (len( ))可以返回导入数据的总数量,可以设置显示数据条数;
数据合并
pandas中,需要吧数据合并起来更利于分析,用merge函数先合并用户表和评分表,再合并电影表;
data = pd.merge(pd.merge(users,ratings),movies)
使用merge函数需要注意被合并表格需要有相同行/列名;当不指定合并行时,默认按照相同行/列名进行合并。

当没有相同的可以用于合并的行/列名时,运行报错:No common columns to perform merge on
merge函数会将两个表中的电影id一一对应进行匹配,通过data[data.users_id == 1可以查看用户id为1的用户看的所有电影的评分;

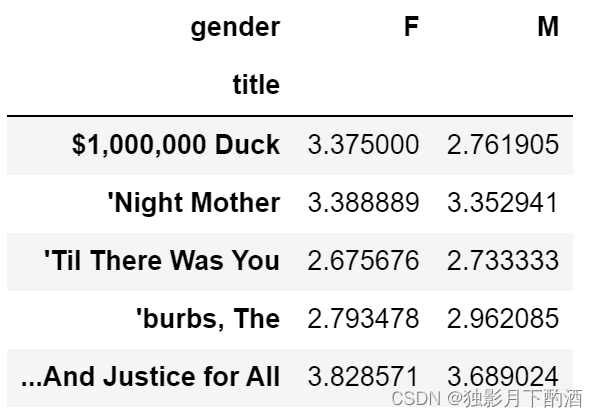
用到的是pandas中数据透视的函数;查询值是评分,行索引是电影名,列索引是性别,通过平均值来聚合数据
计算每一部电影,不同性别的评分对比
ratings_by_gender = data.pivot_table(values = 'rating',\
index = 'title',columns = 'gender',aggfunc = 'mean')
ratings_by_gender.head(10)# check the top 10 movies of men and women
其中,pandas.pivot_table是pandas中数据透视表函数。
语法格式如下:
DataFrame.pivot_table(values=None, index=None, columns=None, \aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
其中参数:
- values 列:可选;
- index索引:如果传递数组,则其长度必须与数据长度相同。该列表可以包含任何其他类型(列表除外)。在数据透视表索引上进行分组的键。如果传递数组,则其使用方式与列值相同;
- columns行:如果传递数组,则其长度必须与数据长度相同。该列表可以包含任何其他类型(列表除外)。在数据透视表索引上进行分组的键。如果传递数组,则其使用方式与列值相同;
- aggfunc函数,函数列表,字典,默认为numpy.mean:如果传递了函数列表,则生成的数据透视表将具有层次结构列,其顶层是函数名称(从函数对象本身推断出)。如果传递了dict,则键为要聚合的列,值是函数或函数列表;
- fill_value标量,默认无:用于替换缺失的值(在汇总后的结果数据透视表中);
- margins,类型为bool,默认为False:添加所有行/列;
- dropna,类型为bool,默认为True:不要包括所有条目均为NaN的列;
- margins_name str,默认为“All”:当margins为True时将包含总计的行/列的名称。
在上述代码中,查询值是评分,行索引是电影名,列索引是性别,通过平均值来聚合数据
由此我们可以去分析哪些电影的男女观影分歧最大。要想算出分歧最大,就要算平均得分差异越大的数据,就需要加一列数据,用于存放男女评分数据差异值。
ratings_by_gender['diff'] = ratings_by_gender.F-ratings_by_gender.M
ratings_by_gender.head(10)# show 10 movies with big differences in ratings
diff:计算差异与所述数据帧另一元件相比,数据帧元件的erence(默认为前一行中元素)。
通过对diff进行排序,找出最大值,就可以找出分歧最大的电影,ascending是排序方式,默认升序。
ratings_by_gender.sort_values(by = 'diff',ascending = True).head(10)

数据分组
通过分析电影评分数据,看看那些电影看的人最多。给电影评分的人最多,说明看的人最多,就可以找出热门电影;
ratings_by_title = data.groupby('title').size()
按照电影名title来进行数据分组,通过size分别获取每个title下评分个数;按照title来进行分组;接着按照评分数量给数据进行排序(降序)找出最热门的10部电影.
ratings_by_title.sort_values(ascending = False).head(10)

从另一排序维度来看,我们可以通过数据透视表查看评分最高的电影。这里聚合函数还是选取求平均值;通过value=获取评分的数据,利用电影标题进行索引。
mean_ratings = data.pivot_table(values = 'rating',index = 'title',aggfunc = 'mean')

对上述平均评分数据进行排序,就可以得出评分最高的10部电影
mean_ratings.sort_values(by = 'rating',ascending = False).head(10)

通过评分最高的方式选出高分电影后,发现有些电影是很小众和陌生的,可以却是评分很高的电影,原因是看的人很少但看完后给了高分。因此,评价一部电影是否为好电影,不仅仅看评分还需要有足够大的观看人数。所以,我们可以说一部好电影,既要是热门电影,又要是评分很高的电影。
查看观看人数最多的top10电影的评分:
top_10_hot = ratings_by_title.sort_values(ascending = False).head(10)
mean_ratings.loc[top_10_hot.index]

同理查看评分最高top10电影的观看人数:
top_10_score = mean_ratings.sort_values(by = 'rating',ascending = False).head(10)
ratings_by_title.loc[top_10_score.index]

可见两个数据毫无重合,因此首先需要找出热度足够高的电影,即评分次数较多的电影。假设大于2000评分就代表热度足够高;接着需要从热度足够高的电影中排序查找评分足够搞得电影,即针对热门电影的评分数据进行降序排序处理,取top10即是真正的好电影了。
hot_movies = ratings_by_title[ratings_by_title > 2000]
print(len(hot_movies))
hot_movies.head(10)
hot_movies_rating = mean_ratings.loc[hot_movies.index]
top_10_good_movies = hot_movies_rating.sort_values(by = 'rating',ascending = False).head(10)
top_10_good_movies