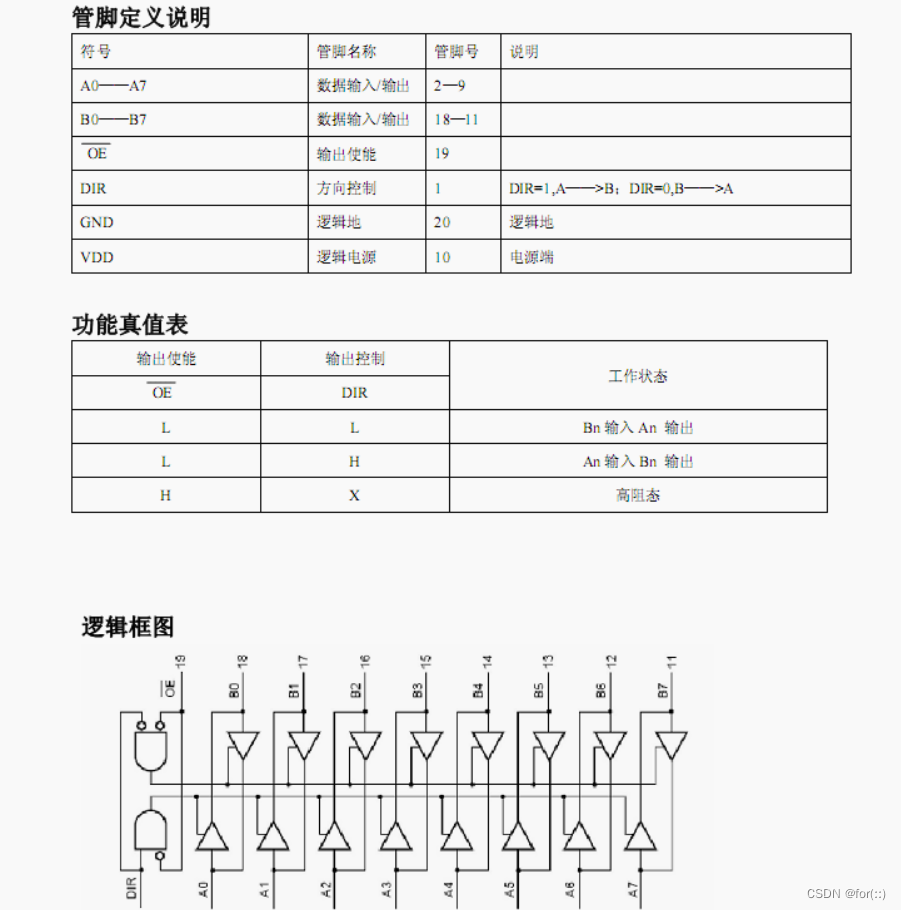
国家统计局指标数据深入分析
- 统计局指标数据结构分析
- 国家统计局数据集
- 行政区划
- 指标数据
- 常见指标id
- 如何从统计局网站获取指标ID
- 查询示例
- 开始查询
国家统计局的数据给许多人的工作和学习提供了丰富且权威的数据。但提供的数据获取方式不尽如人意,因此在网上能找到各种爬取数据的教程。
但这些教程也未必就方便使用,原因有2:
- 爬取教程涉及到代码,通常为PYTHON,使用者需要有一定的编程基础,并且需要安装相对于的包,还是有一定的门槛。
- 即便代码能运行起来,爬取数据本身也耗费人力,而且还经常容易出错
数据爬取教程是授人以渔,本文则授人以鱼。直接给数据,不仅给数据,还提供在线分析和可视化的能力,一站式解决各位数据下载分析的需求。
统计局指标数据结构分析
国家统计局数据集
数据采集自中国国家统计局网站(http://www.stats.gov.cn/),表名以nbs开头。
行政区划
表名为nbs_regions, 该数据为中国5级行政区划信息,包含地区之间律属关系。分省指标数据引用该数据,reg字段即为该表的code字段。数据采集自这个2021版公告。数据示例:
+--------------+-------+--------------+---------------+--------------------------+
| code | level | parent_code | classify_code | name |
+--------------+-------+--------------+---------------+--------------------------+
| 11 | 1 | | | 北京市 |
| 110100000000 | 2 | 11 | | 市辖区 |
| 110101000000 | 3 | 110100000000 | | 东城区 |
| 110101001000 | 4 | 110101000000 | | 东华门街道 |
| 110101001001 | 5 | 110101001000 | 111 | 多福巷社区居委会 |
+--------------+-------+--------------+---------------+--------------------------+
注意:对于level=1的数据有一份重复的,例如北京市有两条记录,分别是code=11和code=110000,这主要是为了与分省数据配合,分省数据中的reg采用的是6位code,而行政区划数据本身是2位。
数据表的定义(DDL)为:
CREATE TABLE `nbs_regions` (`code` varchar(16) COLLATE utf8_unicode_ci NOT NULL COMMENT '统计用区划代码',`level` tinyint(4) DEFAULT NULL COMMENT '行政级别,如湖北省是1级,武汉市是2级,以此类推',`parent_code` varchar(16) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '上一级行政区划的代码,例如黄冈市的代码为421100000000, 它的上级为湖北省,代码42',`classify_code` varchar(8) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '城乡分类代码',`name` varchar(64) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '名称,如多福巷社区居委会',PRIMARY KEY (`code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='全国统计用区划代码和城乡划分代码'
查询示例,例如需要查询北京东城区的行政区划代码:
select code from nbs_regions where name='东城区';
+--------------+
| code |
+--------------+
| 110101000000 |
+--------------+
查询北京东城区所有的街道:
select name from nbs_regions where parent_code='110101000000';
+--------------------+
| name |
+--------------------+
| 东华门街道 |
| 景山街道 |
| 交道口街道 |
| 安定门街道 |
| 北新桥街道 |
| 东四街道 |
| 朝阳门街道 |
| 建国门街道 |
| 东直门街道 |
| 和平里街道 |
| 前门街道 |
| 崇文门外街道 |
| 东花市街道 |
| 龙潭街道 |
| 体育馆路街道 |
| 天坛街道 |
| 永定门外街道 |
+--------------------+
指标数据
指标数据为国民经济和社会各项指标的数据,例如CPI, GDP, PPI等。根据时间和地区维度,又分为如下6类:
- 宏观年度(hgnd)
- 宏观季度(hgjd)
- 宏观月度(hgyd)
- 分省年度(fsnd)
- 分省季度(fsjd)
- 分省月度(fsyd)
每一类又分为指标定义表,和数据表。指标定义表定义了指标的含义、度量单位、在指标体系中的层级等信息;数据表即为指标的具体数据。两者通过id字段关联。
| 类别 | 指标定义表 | 指标数据表 |
|---|---|---|
| 宏观年度 | nbs_zb_hgnd_dim | nbs_zb_hgnd_data |
| 宏观季度 | nbs_zb_hgjd_dim | nbs_zb_hgjd_data |
| 宏观月度 | nbs_zb_hgyd_dim | nbs_zb_hgyd_data |
| 分省年度 | nbs_zb_fsnd_dim | nbs_zb_fsnd_data |
| 分省季度 | nbs_zb_fsjd_dim | nbs_zb_fsjd_data |
| 分省月度 | nbs_zb_fsyd_dim | nbs_zb_fsyd_data |
6类指标定义表的结构完全一致,这里仅展示nbs_zb_hgnd_dim表:
CREATE TABLE `nbs_zb_hgnd_dim` (`id` varchar(16) COLLATE utf8_unicode_ci NOT NULL COMMENT '指标的唯一id',`level` tinyint(4) DEFAULT NULL COMMENT '指标的层级,越小层级越高',`name` varchar(96) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '指标的 名称',`unit` varchar(16) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '单位',`node_sort` int(11) DEFAULT NULL,`sort_code` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='宏观年度统计指标的定义'
数据示例:
select * from nbs_zb_hgnd_dim limit 3;
+---------+-------+-----------------+------+-----------+-----------+
| id | level | name | unit | node_sort | sort_code |
+---------+-------+-----------------+------+-----------+-----------+
| A01 | 1 | 综合 | | 0 | 0 |
| A0101 | 2 | 行政区划 | | 0 | 0 |
| A010101 | 3 | 地级区划数 | 个 | 1 | 2 |
+---------+-------+-----------------+------+-----------+-----------+
注意:id相同的指标,在不同的类别中具有不同的含义。 例如id=A020102的指标,在不同表的含义如下:
- nbs_zb_hgnd_dim: 国内生产总值
- nbs_zb_hgjd_dim: 农业总产值_累计值
- nbs_zb_hgyd_dim: 工业增加值_累计增长
- nbs_zb_fsnd_dim: 第一产业增加值
- nbs_zb_fsjd_dim: 装饰装修产值_累计值
- nbs_zb_fsyd_dim: 工业增加值_累计增长
宏观数据表与分省数据表定义不一致,分省数据表多了一个地区字段(reg)。这里以宏观年度和分省年度表作为示例。
CREATE TABLE `nbs_zb_hgnd_data` (`id` varchar(16) COLLATE utf8_unicode_ci NOT NULL COMMENT '指标id',`sj` date NOT NULL COMMENT '时间,如2020-01-01,表示2020年',`val` double DEFAULT NULL COMMENT '指标的值,NULL表示没有数据',PRIMARY KEY (`id`,`sj`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='宏观年度指标数据'
数据示例
select * from nbs_zb_hgnd_data limit 3;
+---------+------------+------+
| id | sj | val |
+---------+------------+------+
| A010101 | 1980-01-01 | 318 |
| A010101 | 1981-01-01 | 316 |
| A010101 | 1982-01-01 | 322 |
+---------+------------+------+
CREATE TABLE `nbs_zb_fsnd_data` (`id` varchar(16) COLLATE utf8_unicode_ci NOT NULL COMMENT '指标id',`reg` varchar(13) COLLATE utf8_unicode_ci NOT NULL COMMENT '省份id, 如北京为110000, 河北为130000',`sj` date NOT NULL COMMENT '时间,如2020-01-01,表示2020年',`val` double DEFAULT NULL COMMENT '指标的值,NULL表示没有数据',PRIMARY KEY (`id`,`reg`,`sj`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='分省年度指标数据'
数据示例
select * from nbs_zb_fsnd_data limit 3;
+---------+--------+------------+------+
| id | reg | sj | val |
+---------+--------+------------+------+
| A010101 | 110000 | 1970-01-01 | NULL |
| A010101 | 110000 | 1971-01-01 | NULL |
| A010101 | 110000 | 1972-01-01 | NULL |
+---------+--------+------------+------+
其中reg字段为nbs_regions表的code字段。
常见指标id
为了方便大家查找常用的指标,现将常用指标的id列举如下:
| 表名 | id | 含义 | 单位 |
|---|---|---|---|
| nbs_zb_hgnd_dim | A020102 | 国内生产总值 | 亿元 |
| nbs_zb_hgnd_dim | A02020102 | 国内生产总值指数(上年=100) | |
| nbs_zb_hgyd_dim | A01010101 | 居民消费价格指数(上年同月=100) | |
| nbs_zb_hgyd_dim | A01080101 | 工业生产者出厂价格指数(上年同月=100) | |
| nbs_zb_hgyd_dim | A0B0101 | 制造业采购经理指数 | % |
| nbs_zb_hgyd_dim | A070101 | 社会消费品零售总额_当期值 | 亿元 |
| nbs_zb_hgyd_dim | A070103 | 社会消费品零售总额_同比增长 | % |
| nbs_zb_hgyd_dim | A080101 | 进出口总值_当期值 | 千美元 |
| nbs_zb_hgyd_dim | A080102 | 进出口总值_同比增长 | % |
| nbs_zb_fsjd_dim | A030101 | 居民人均可支配收入_累计值 | 元 |
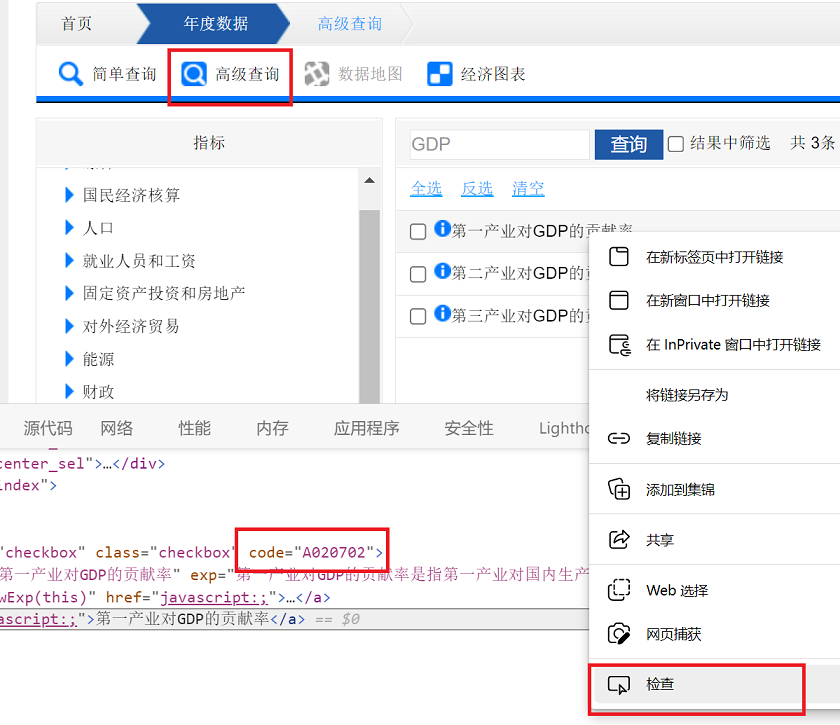
如何从统计局网站获取指标ID
在国家统计局网站的高级查询页面,选择一个指标,通过浏览器的右键菜单的检查功能,可以查看到指标的ID。具体操作如下:
第一步,打开对应指标的高级查询页面 六类指标的高级查询页面地址分别如下:
- 宏观年度
- 宏观季度
- 宏观月度
- 分省年度
- 分省季度
- 分省月度
第二步,选择指标 可以通过左边导航栏,或者搜索找到目标指标
第三步,右击指标,并选择检查菜单
第四步,在打开的网页代码中,找到对应的指标ID 如下图所示
查询示例
示例1:自2010年以来GDP增长指数,按时间升序排列
select * from data.nbs_zb_hgnd_data where id='A02020102' and sj >='2010' order by sj;
+-----------+------------+-------+
| id | sj | val |
+-----------+------------+-------+
| A02020102 | 2010-01-01 | 110.6 |
| A02020102 | 2011-01-01 | 109.6 |
| A02020102 | 2012-01-01 | 107.9 |
| A02020102 | 2013-01-01 | 107.8 |
| A02020102 | 2014-01-01 | 107.4 |
| A02020102 | 2015-01-01 | 107 |
| A02020102 | 2016-01-01 | 106.8 |
| A02020102 | 2017-01-01 | 106.9 |
| A02020102 | 2018-01-01 | 106.7 |
| A02020102 | 2019-01-01 | 106 |
| A02020102 | 2020-01-01 | 102.2 |
| A02020102 | 2021-01-01 | 108.1 |
+-----------+------------+-------+
示例2:对比自2021年以来CPI和PMI指数,按时间升序排列
select cpi.sj, cpi.val cpi , pmi.val pmi from data.nbs_zb_hgyd_data cpi join
(select sj, val from data.nbs_zb_hgyd_data where id='A0B0101' and sj >='2021-01-01') pmi
on (cpi.sj = pmi.sj) where cpi.id='A01030101' and cpi.sj >='2021-01-01' order by cpi.sj+------------+-------+------+
| sj | cpi | pmi |
+------------+-------+------+
| 2021-01-01 | 101 | 51.3 |
| 2021-02-01 | 100.6 | 50.6 |
| 2021-03-01 | 99.5 | 51.9 |
| 2021-04-01 | 99.7 | 51.1 |
| 2021-05-01 | 99.8 | 51 |
| 2021-06-01 | 99.6 | 50.9 |
| 2021-07-01 | 100.3 | 50.4 |
| 2021-08-01 | 100.1 | 50.1 |
| 2021-09-01 | 100 | 49.6 |
| 2021-10-01 | 100.7 | 49.2 |
| 2021-11-01 | 100.4 | 50.1 |
| 2021-12-01 | 99.7 | 50.3 |
+------------+-------+------+
示例3:查询江苏省自2020年来季度居民人均可支配收入,按时间升序排列
select sj, val from data.nbs_zb_fsjd_data where id='A030101'
and reg in (select code from data.nbs_regions where name='江苏省') and sj >='2020-01-01' order by sj;2020-01-01 13588
2020-04-01 22126
2020-07-01 32667
2020-10-01 43390
2021-01-01 15500
2021-04-01 25119
2021-07-01 36227
2021-10-01 47498
2022-01-01 16490
开始查询
所有的数据,kaifangshuju.com 都已经提供,我们只需去查询,去分析、去下载即可。
在网站的首页,点击国家统计局开始查询链接,在页面的文本框,输入sql语句就可以查了。
- 不仅可以查单表,还可以多表联合查询。
- 查询结果可以下载(DOWNLOAD TO CSV),可以可视化(EXPLORE),或者复制到粘贴板(COPY TO CLIPBOARD)
- 以任意灵活的行列格式输出,无需在EXCEL做烦琐的格式整理了
查询页面如图所示