ChatGPT调研
- 背景:ChatGPT简单介绍
- FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
- Fine-Tuning Language Models from Human Preferences
- Learning to Summarize with Human Feedback
- Training language models to follow instructions with human feedback
- ChatGPT
- ChatGPT能力探究
- GLUE
- 推理
- 自然语言推理任务
- 命名实体识别
- 情感分析
- 小结
- ChatGPT对知识图谱的影响
- 受到影响的领域
- 暂时不受影响的领域
- 两者可以结合的点
- 需要的调整
- 小结
- 总结
导师要调研ChatGPT,正好蹭热点看一看相关原理,看能不能在这里面找到研究的点,分四个方面讲一下ChatGPT
背景:ChatGPT简单介绍
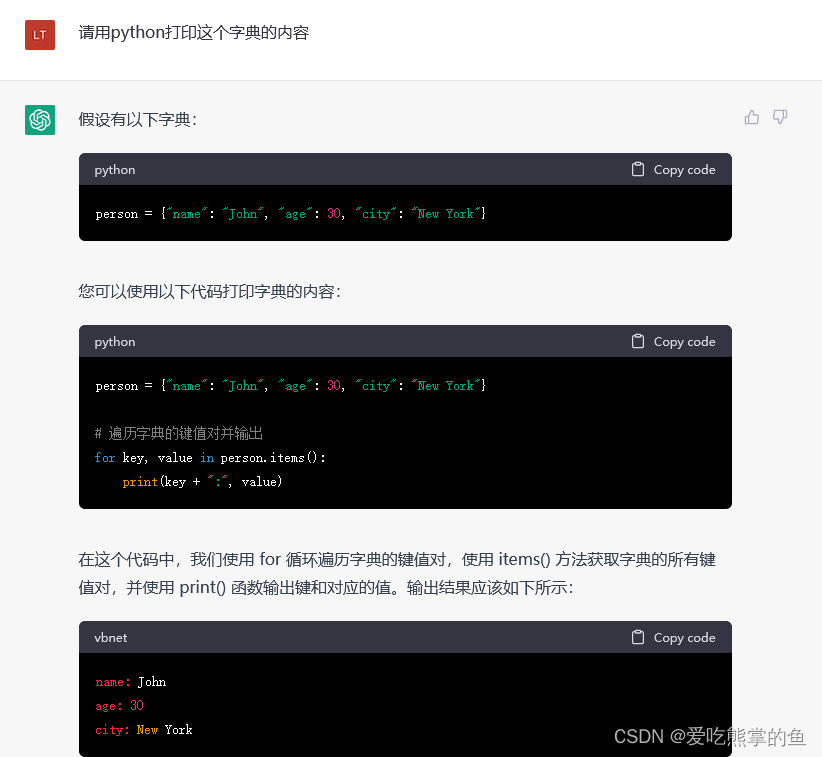
ChatGPT是一个人工智能聊天机器人,由OpenAI开发,于2022年11月发布。它基于OpenAI的GPT-3.5大型语言模型,并使用监督学习和强化学习技术进行了微调。它可以回答一般性和技术性的问题,也可以进行有趣的对话。所展现出的理解力和文本生成能力相较于以前的模型产生了肉眼可见的质变,首先介绍ChatGPT的技术实现。
ChatGPT的新技术主要集中于几篇论文,先不看具体实现公式,只看思路
FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
- 第一篇是谷歌在22年发的FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS

这篇文章介绍了ChatGPT的技术之一instruction-tuning(指令微调)技术,该文章提出的FLAN模型是基于transformer decoder的大模型,其本质是想让NLP任务的输入转化为自然语言指令,再将其投入模型进行训练,增强其理解输入意图的能力,通过给模型提供指令和选项的方式,使其能够提升Zero-Shot任务的性能表现。
其文章主要动机为传统的大语言模型以及提示学习(GPT3等),在Zero-Shot和few-shot上性能表现差距较大,论文中认为原因是,在没有少量示例微调的情况下,Zero-Shot条件其输入与训练中的输入存在差距,导致在不可见任务上表现不佳,简单来说就是理解输入意图的能力不够。
本文旨在增强模型这方面能力,于是提出了一个符合直觉的想法,就是直接将任务转化为自然语言进行输入,通过训练提升其在Zero-Shot条件下的表现,如下图所示,各种任务都可以在预训练模型的基础上转化为指令微调,经过这样训练,在不可见任务上也可以较为准确理解任务意图。
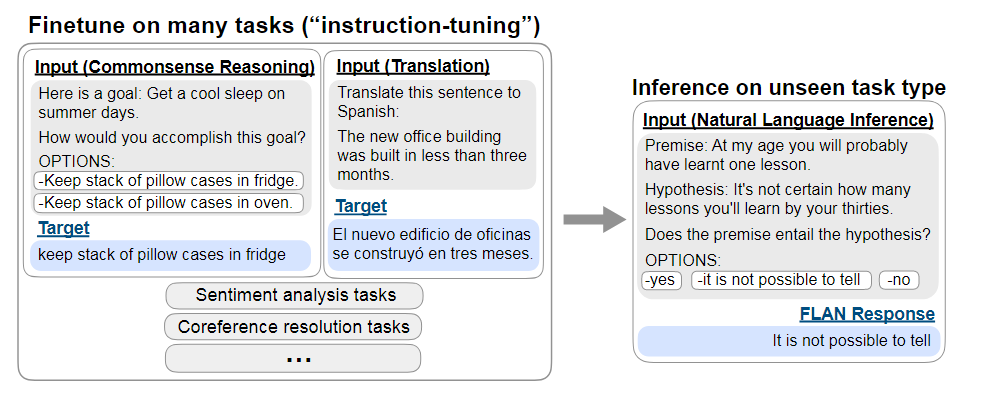
该模型与预训练-微调,提示学习方法的区别主要如下图所示
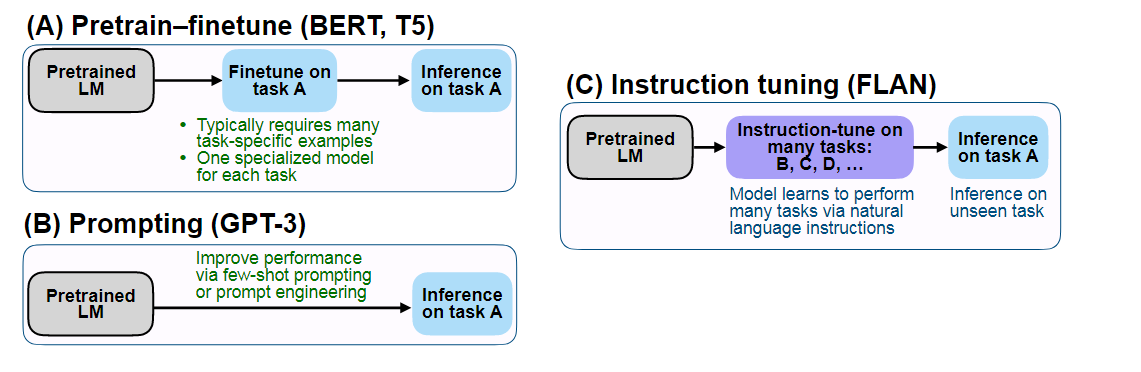
简单概括上图就是:
- Fine-tuning:先在大规模语料上进行预训练,然后再在某个下游任务上进行微调,如BERT、T5
- Prompt-tuning:先选择某个通用的大规模预训练模型,然后为具体的任务生成一个prompt模板以适应大模型进行微调,如GPT-3,需要few-shot或者提示工程师
- Instruction-tuning:相当于结合前两者的特点,仍然在预训练语言模型的基础上,先在多个已知任务上进行微调(通过自然语言的形式),这里是有监督学习,然后再推理某个新任务上进行zero-shot
后面作者实验主要是讲这个指示模板怎么选,具体是个什么形式,简单来说就是找了大量数据集并改编,做成符合FLAN的数据集,数据量也是惊人的,这些都是大公司才能干的事情,在此不多赘述,主要的模板也就是训练数据的形式如下:
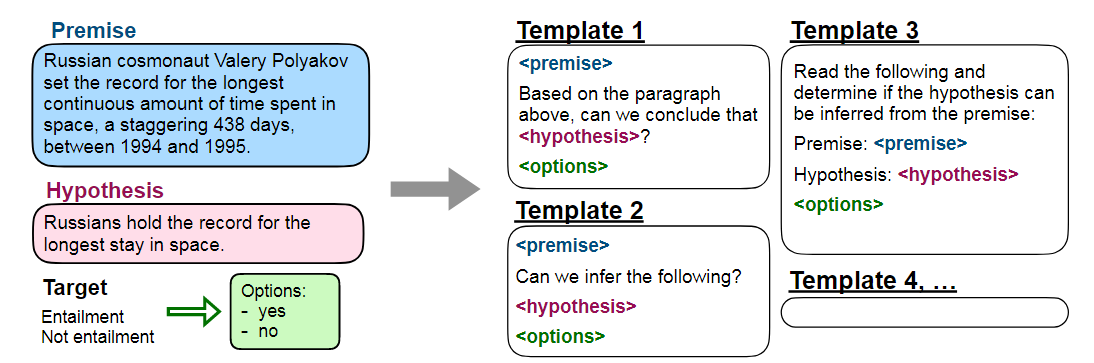
注意这个过程是在预训练好的大语言模型上进行微调,具体是采用的LaMDA-PT模型,意思就是基础已经很强大了,再加点理解输入语言的能力,在Zero-Shot场景下准确率大幅提高,当然前提是Zero-Shot场景也用自然语言提问,instruction-tuning也就是增强理解输入语言的能力,后面又做了一系列消融实验,证明确实是instruction-tuning有用,而不是多任务微调有用,确实很有说服力
一个简单的例子:原来的大模型是教你具体的科目,比如说生物,那你就只能考生物,教你考物理就是0分,但指令微调是教你怎么看书,考试的时候把书给你,考什么都可以考的比较好
注意:论文研究显示instruction-tuning只有模型到达一定数量级效果才会产生质变,否则是负提升,可能理解输入文本的参数就已经占满模型了,阈值在8B~68B,所以说在学校实现这种东西不现实
Fine-Tuning Language Models from Human Preferences
- 第二篇论文是OPEN AI在21年发的Fine-Tuning Language Models from Human Preferences

也就是ChatGPT中使用到的另一个技术:Reinforcement Learning from Human Feedback (RLHF),如何从用户的明确需要中学习。该文章提出了一种利用人类反馈来微调大型语言模型(LLMs)的方法,使其能够生成更符合人类偏好的文本,应该是第一次用强化学习而不是监督学习微调大模型,具体的过程如下
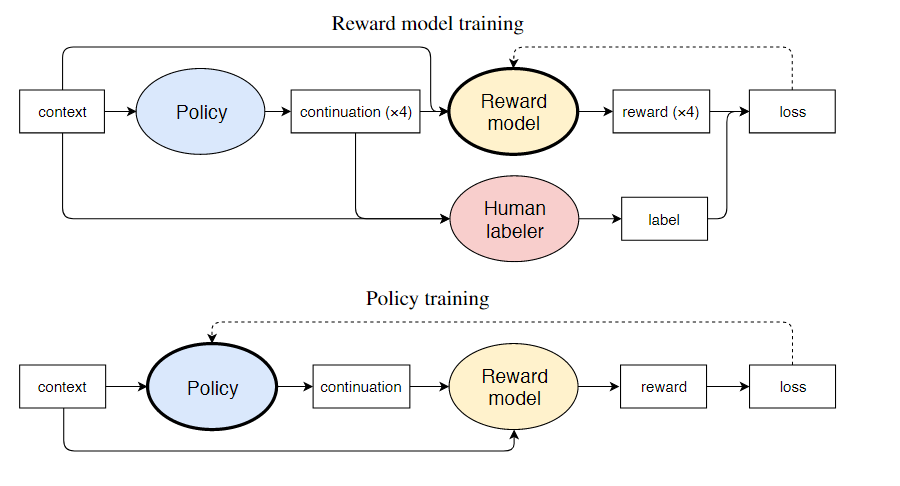
1、首先,从一个预训练的语言模型(如GPT-2)开始,用一个大规模的文本数据集(如WebText)进行微调,得到一个基础模型。
2、为了适应特定的任务(如故事生成),用一个小规模的任务相关数据集(如WritingPrompts)进行微调,得到一个任务模型。
3、设计一些人类反馈的问题(如哪个文本更有趣、更合理、更流畅等),并用一个在线平台(如Scale API)让人类标注者对任务模型生成的不同文本进行比较和评分。
4、用这些人类反馈作为奖励信号,用强化学习(RL)的方法对任务模型进行进一步微调,得到一个偏好模型。
这个模型还有online模式,是指在微调偏好模型的过程中,实时地收集人类反馈,并用它们来更新奖励信号。这种模式有以下几个特点:
1、它可以更快地适应人类偏好的变化,因为每次迭代都会使用最新的反馈数据。
2、它可以更好地利用人类标注者的时间,因为每次都会给他们展示最有信息量的文本对比。
3、它可以更容易地探索不同的文本风格和内容,因为每次都会根据当前的奖励信号来生成新的文本
简而言之,这篇文章提出了一种利用人类反馈来微调大型语言模型的方法,使其利用强化学习拟合人类偏好,让其输出更符合人类的直观感觉,并可以持续更新。
Learning to Summarize with Human Feedback
- 第三篇论文是OPEN AI 在22年发的Learning to Summarize with Human Feedback

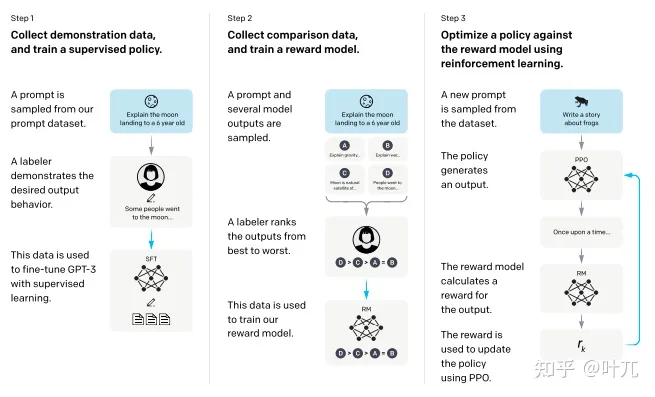
这篇论文的整体结构就有点像ChatGPT的系统工程了,只不过在一个小范围内先试验一下,目标是训练一个能够生成高质量摘要的语言模型,而不依赖于特定任务的数据和指标。他们的方法是使用人类反馈来指导强化学习,从而优化一个预训练的语言模型,具体过程如下:
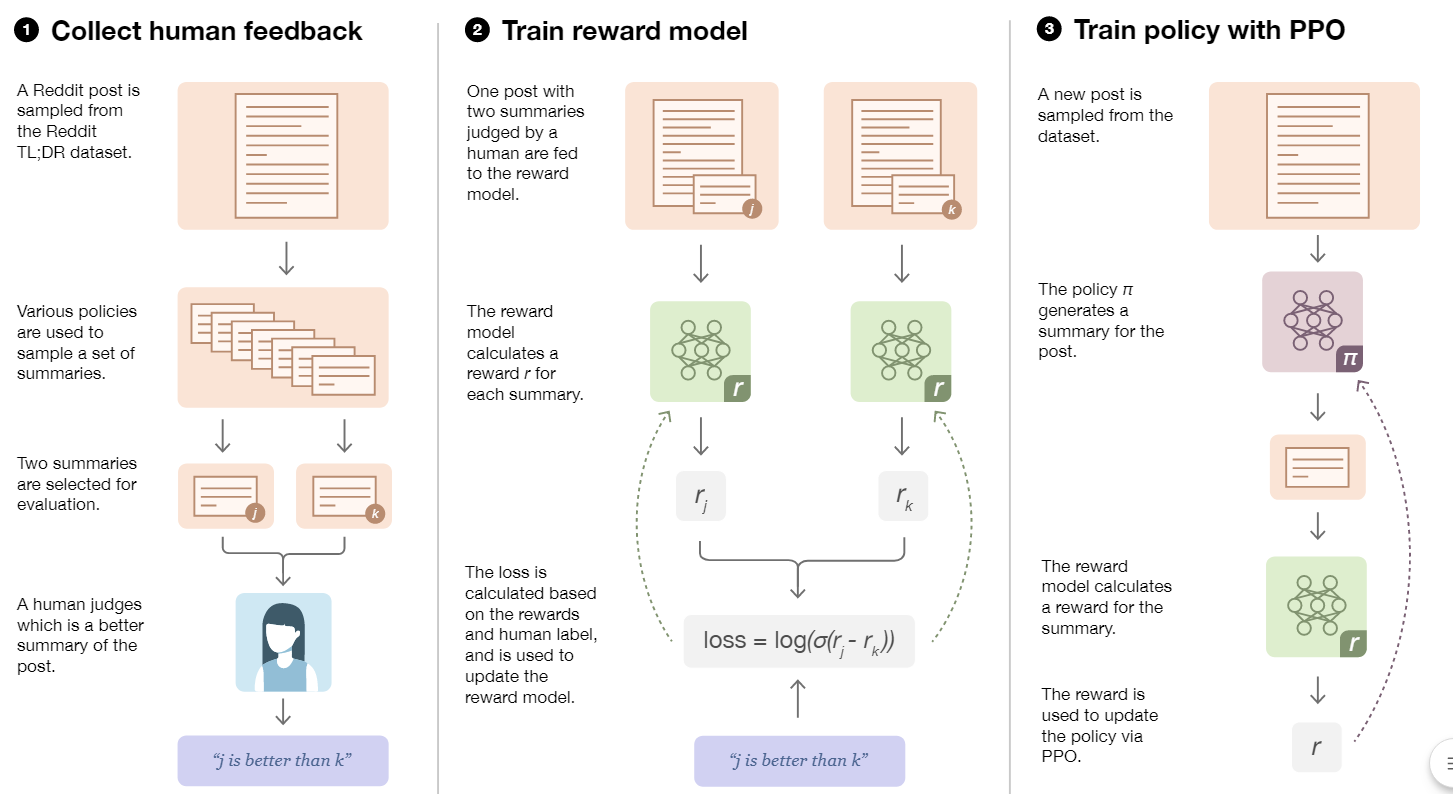
分为以下三步:
1、收集人类偏好数据集,让标注员在两篇摘要之间选择一个更好的。
2、使用人类偏好数据集,通过监督学习训练一个奖励模型(RM),给每篇摘要打分。
3、使用奖励模型(RM),通过强化学习(RL)微调一个预训练的语言模型,使其生成高分的摘要。
这个过程可以循环进行,使用新的摘要样本收集更多的人类反馈数据
总的来说,拿PPO方法微调预训练大语言模型的系统方法在这篇文章就有所呈现,只是仅仅运用在了摘要生成上
Training language models to follow instructions with human feedback
- 第四篇论文是由OPEN AI 在22年发的大名鼎鼎的Training language models to follow instructions with human feedback

也就是InstructGPT了,ChatGPT的前身,该论文的目的是提高大型语言模型,如GPT-3,与用户意图的对齐度,即让模型能够按照用户给出的指令来生成满意的输出。这篇论文其实跟上一篇类似,主要的训练过程如下:
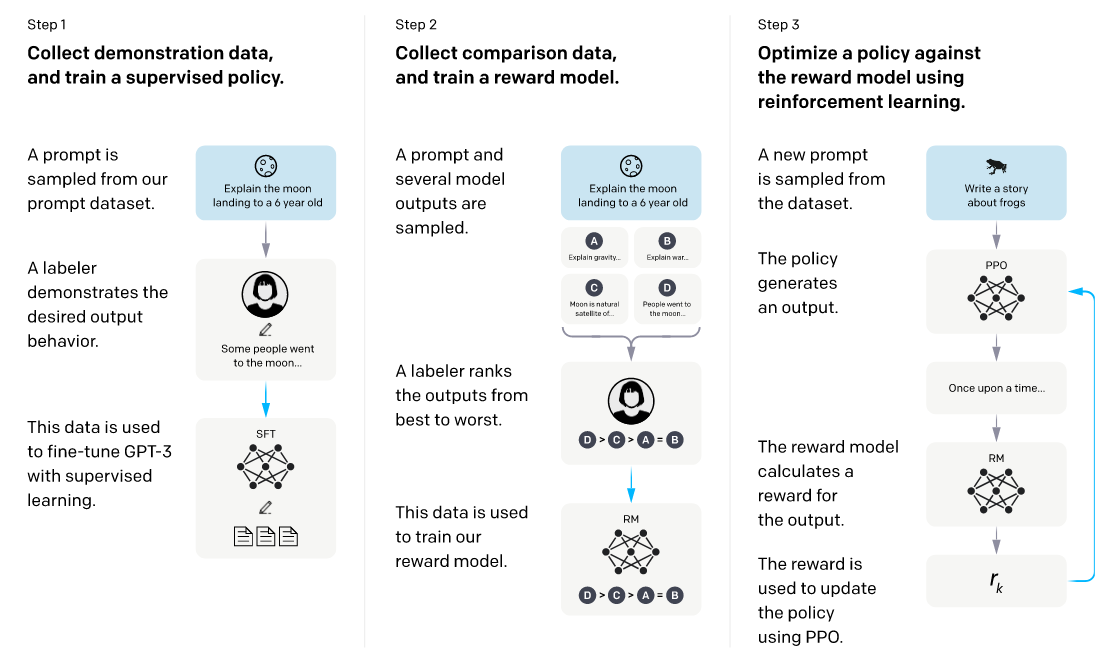
这篇论文的方法是利用人类反馈来对语言模型进行微调,即让人类标注者给出一些指令和示例输出,并用它们作为监督信号来更新模型参数。
该论文的创新点是提出了一个新的算法HIR(Human Instruction Relabeling),它可以将人类反馈转化为指令,并用它们来重新标注原始指令,从而提高模型对指令的理解和遵循能力。
HIR的过程如下:首先,从一个指令集合中随机选择一个指令,并用偏好模型生成一个输出。然后,用在线平台让人类标注者对这个输出进行评分,即给出一个反馈信号。接着,用这个反馈信号来判断是否需要对原始指令进行重新标注,即将其替换为一个更合适的指令。最后,用这个新的指令和输出对作为监督数据来更新偏好模型的参数,其实HIR说的很厉害,就是升级版的RLHF
该论文的实验结果表明,使用人类反馈微调后的语言模型在多个任务上都有显著提升,例如故事生成、问答、摘要等,并且HIR算法可以超越基线算法和监督微调算法,相比于前一篇论文,其应用域更广了。
ChatGPT
说了这么多,虽然没开源,其实ChatGPT应该是将前面若干技术结合到一起了,其官网给出的图和InstructGPT几乎一样,改了个颜色,就不放出来了,在预训练阶段使用了指示微调的方法,增加其理解输入的能力,后面使用RLHF,增强其输出流畅且符合人类要求的能力,最后进行PPO强化学习提升模型整体能力,前几天听一个某机构的公开课,曰:官网的图3.5分,他这个图9分,有一说一确实挺简洁,易于直观理解,将第一个微调改为指示微调,后面进化过的GPT-3和进化过的RM进行强化学习,最终形成了ChatGPT

ChatGPT能力探究
ChatGPT能力究竟怎么样,横空出世之后也有很多人探究,其究竟在NLP任务上的表现如何,和原来的BERT和GPT之类的比较效果怎么样,也是一个值得探究的问题,有几篇论文进行了详细的调研
- Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-tuned BERT
- IS CHATGPT A GENERAL-PURPOSENATURAL LANGUAGE PROCESSING TASK SOLVER?
- ChatGPT: Jack of all trades, master of none
自然语言处理(NLP)主要有自然语言理解(NLU)和自然语言生成(NLG)任务。ChatGPT的自然语言生成(NLG)任务自然是地表最强,无需多说,跟以往的大模型主要的比较就是在自然语言理解这一块。
GLUE
为了让NLU任务发挥最大的作用,来自纽约大学、华盛顿大学等机构创建了一个多任务的自然语言理解基准和分析平台,也就是GLUE(General Language Understanding Evaluation)
GLUE共有九个任务,分别是CoLA、SST-2、MRPC、STS-B、QQP、MNLI、QNLI、RTE、WNLI。如下图所示,可以分为三类,分别是单句任务,相似性和释义任务。简介具体如下图所示

也就是说通过这个任务可以客观评价ChatGPT的自然语言理解能力,显然,ChatGPT工作需要instruction,所以实验前需要将对应任务设计一套模板,具体转换如下
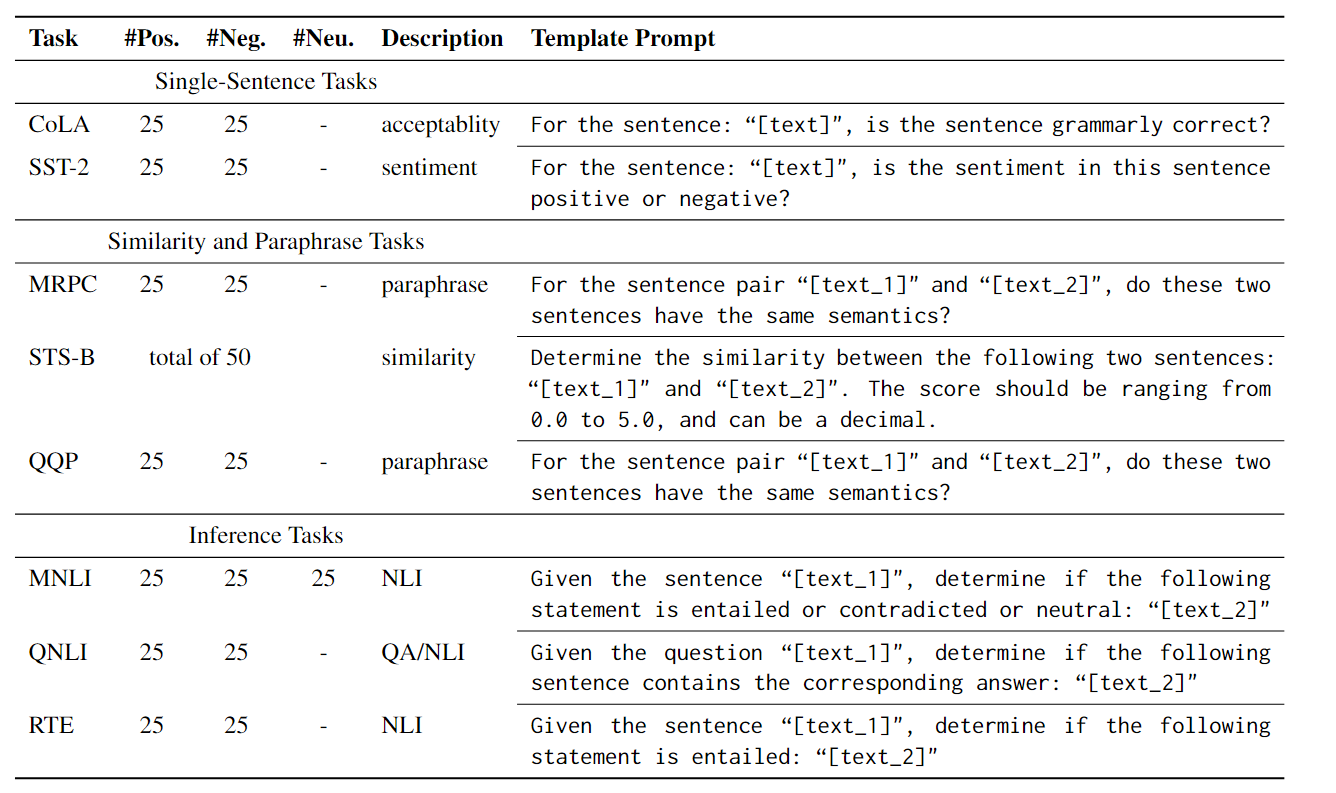
详细实验过程可以参考论文,这里只综合说上述论文的实验结果和猜想
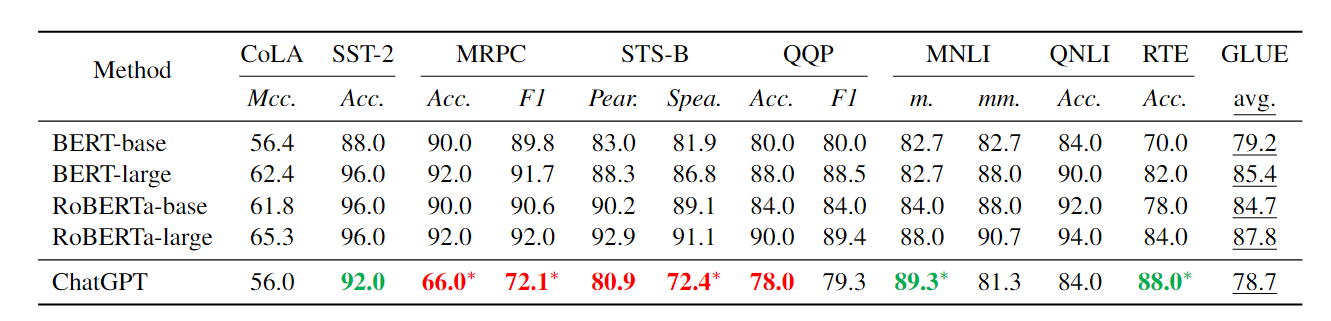
文中得出结论在特定任务上将 ChatGPT 与 BERTbase 进行比较,我们可以发现:
- 1、ChatGPT 在释义和相似性任务上的表现很差,即 MRPC 和 STS-B,性能下降高达 24% 分。
- 2、ChatGPT 在自然语言推理任务(即 MNLI 和 RTE)上超越了所有 BERT 风格的模型,表明它在推理/推理方面具有优势。
- 3、ChatGPT 在单个句子分类任务上与 BERT-base 相当,即情感分析 (SST-2) 和语言可接受性 (CoLA) 和 QA 相关任务,即 QNLI。
具体结果如下表所示
对上面每一类问题进行分析,首先是表现最差的相似性任务

在MPRC中ChatGPT对一对句子之间语义差异不敏感,可能是模型训练缺乏这方面人工反馈

BERT-base 和 ChatGPT 在 STS-B 上的比较。x轴表示STS-B的相似度分布,y轴表示预测和真实情况之间的绝对差。在相似度较低的条件下误差较大,其中差不多相似的(评分中间的)误差最大,与前一个任务较吻合,原因之一是 ChatGPT 在 STS-B 任务上没有进行微调,无法确定正确的决策边界。
推理
再来看表现较好的推理部分,实验在推理任务上每一类精度进行评估,*代表超越所有BERT类模型
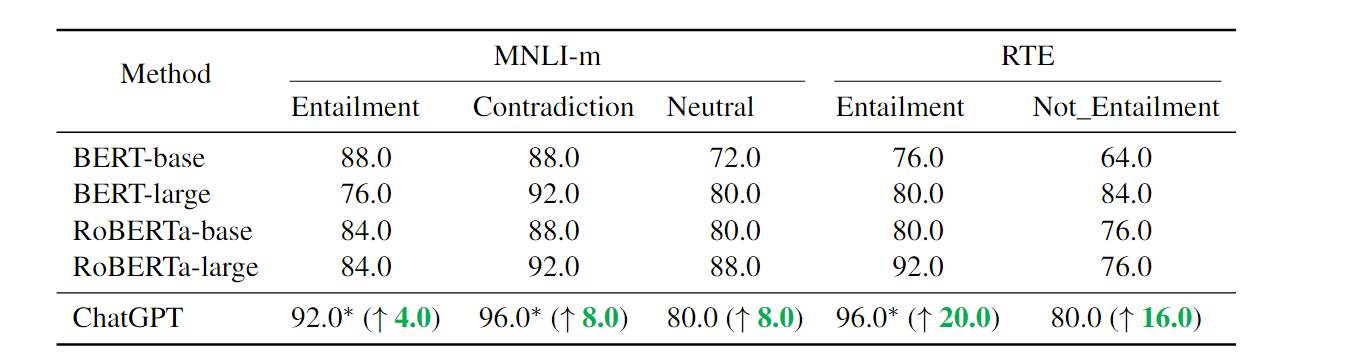
可以观察到虽然其整体推理能力较强,但是对于正样本和负样本的准确度明显不同,详细探究其推理种类,具体分为算数,常识,符号和逻辑推理。
这里又可以在实验的时候分为有COT和无COT,也就是说是否有提示帮助大模型进行思考,COT往往显示着模型的内在潜力,比较的时候同样用instruct的方法
Chain-of-Thought Prompting
提示链思考 (CoT) 促使 LLM 在回答之前生成中间推理步骤
最近的研究主要集中在如何改进手动COT,包括优化prompt选择和优化推理链的质量[Khotet al.,2022,Chen等人,2022]。此外,研究人员还研究了在多语言场景中采用COT的可行性和在较小的语言模型中采用COT的可行性。最近提出了将视觉特征融入到COT推理中的多模态COT
在算数推理的数据集上测试
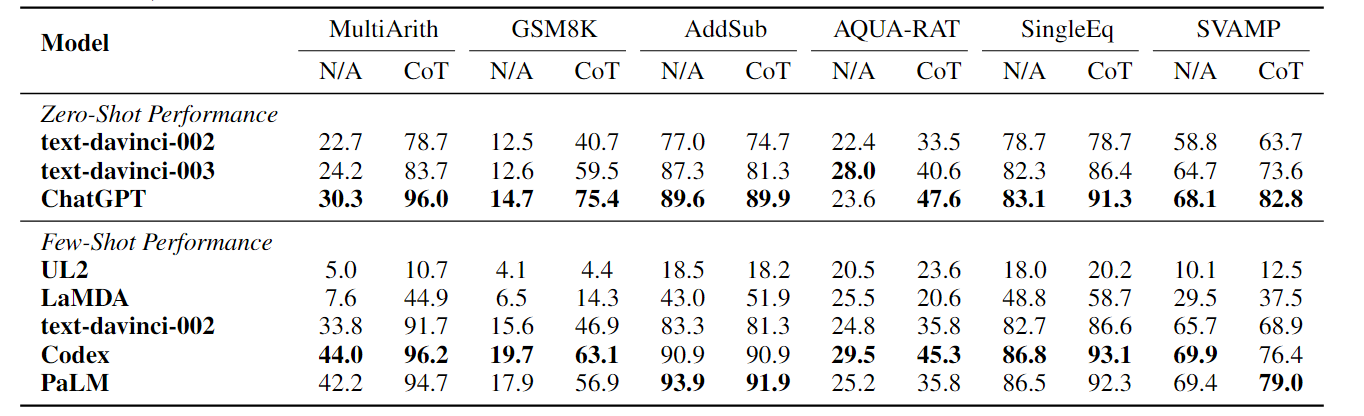
算数强于普通大模型,理解问题能力更强,文字掺杂数字的可以理解的很好,但是纯算数准确率一直不是很高,也就是说对数学公式缺乏规则,具体算数示例如下:

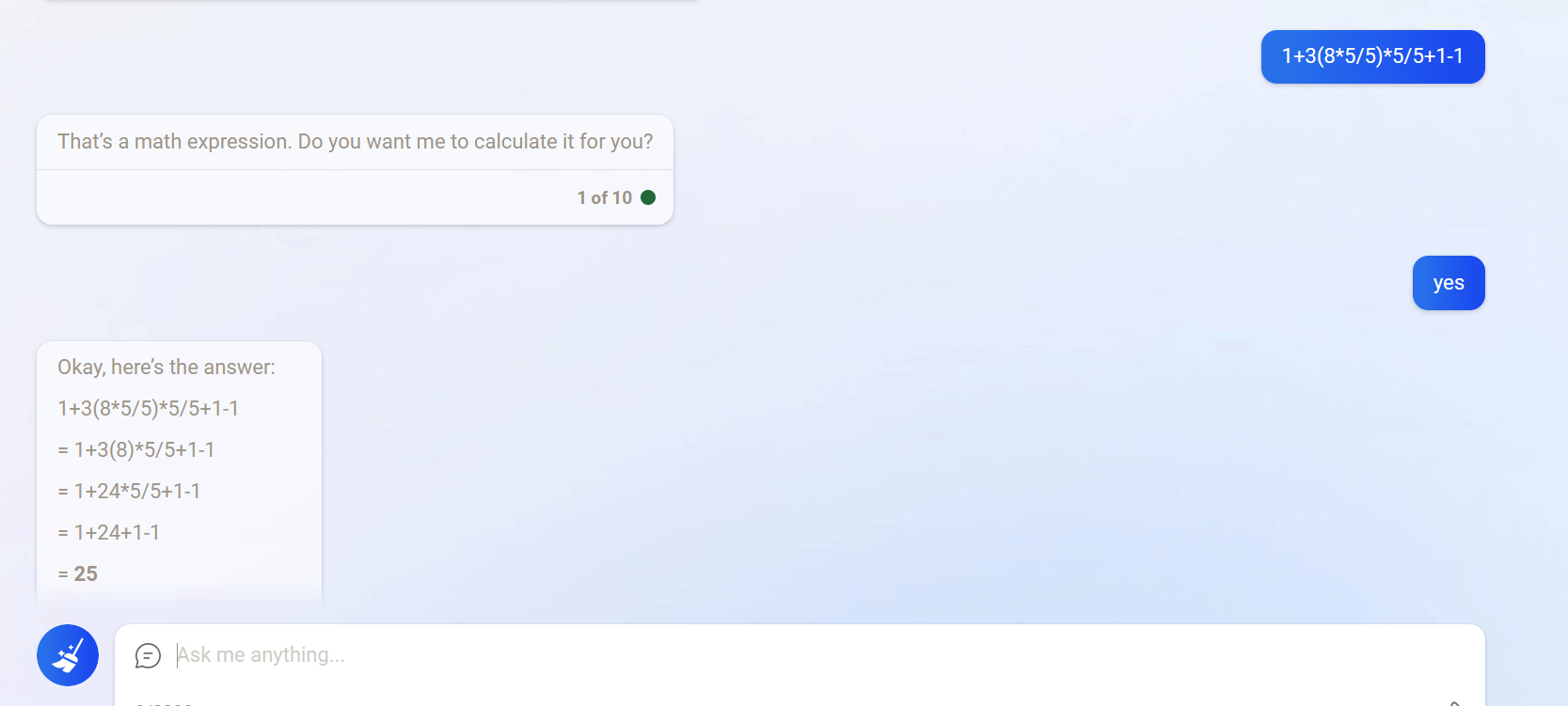
原来困扰大模型的数值运算似乎也有成效,现在在bing上也可以算对了,是不是调用了外部的规则?
在其它三种推理上的性能如下
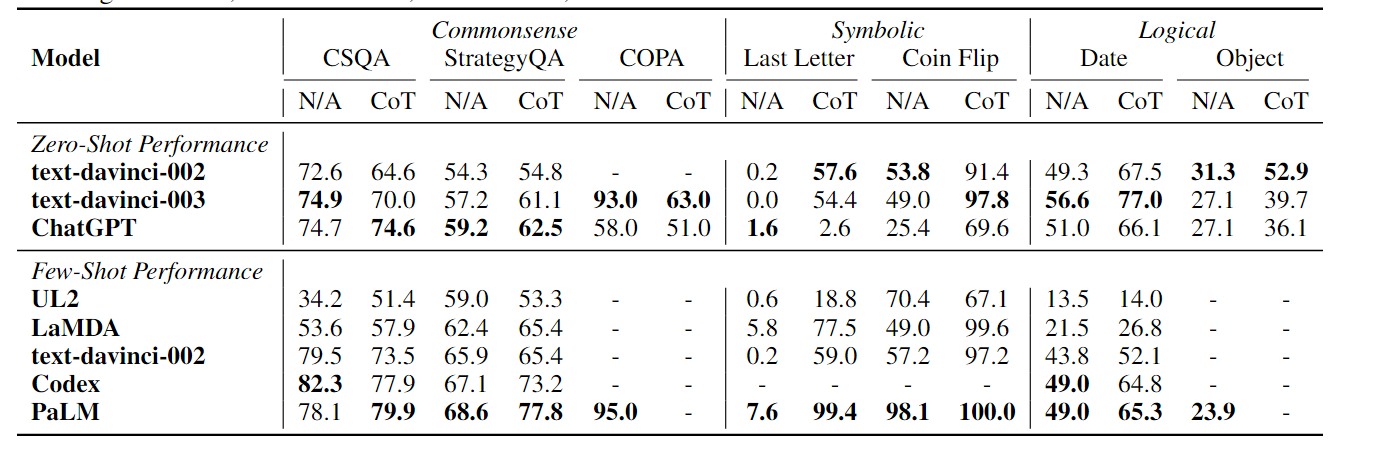
上图显示 ChatGPT 在七个常识、符号和逻辑推理数据集上与流行的 LLM 相比的准确性。以上结果得出两点:
- 使用 CoT 在常识推理任务中可能并不总是提供更好的性能。CoT 方法通常会产生灵活合理的基本原理,但在常识推理任务中最终预测并不正确。结果表明,常识推理任务可能需要更细粒度的背景知识。
- 与算术推理不同,ChatGPT 在许多情况下的表现比 GPT-3.5 差,这表明 GPT-3.5 的相应能力更强。注意到 ChatGPT 在需要常识推理能力的 COPA 上的表现比 GPT-3.5 差得多。下图中展示了 ChatGPT 的几个失败案例。我们可以观察到 ChatGPT 可以轻松生成不确定的响应,从而导致性能不佳。

再来看其它一些常见的任务
自然语言推理任务


可以看到,ChatGPT 在零样本设置下可以达到比 GPT-3.5、FLAN、T0 和 PaLM 更好的性能。这证明了 ChatGPT 推断句子关系的卓越零样本能力。为了仔细研究为什么 ChatGPT 在很大程度上优于 GPT-3.5,在表 5 中报告了两个模型的每类准确性。当前提确实包含假设时,ChatGPT 的性能优于 GPT-3.5,然而,它在“Not Entailment”类(-14%)上的表现不如 GPT-3.5。因此,可以看到 ChatGPT 更适合处理事实输入(通常也受人类青睐),这可能与人类反馈在模型训练期间自己的 RLHF 设计中的偏好有关。
具体样例如下图所示,缺乏常识,这很奇怪。如果简真的饿了,简不会给琼糖果,而是自己把糖吃了。在小写中也有类似的现象,ChatGPT的回答逻辑混乱。一般来说,ChatGPT能够按照一定的模式生成流畅的回答,但在真正推理句子方面似乎有局限性。一个证据是,ChatGPT甚至无法回答人类容易回答的问题


命名实体识别
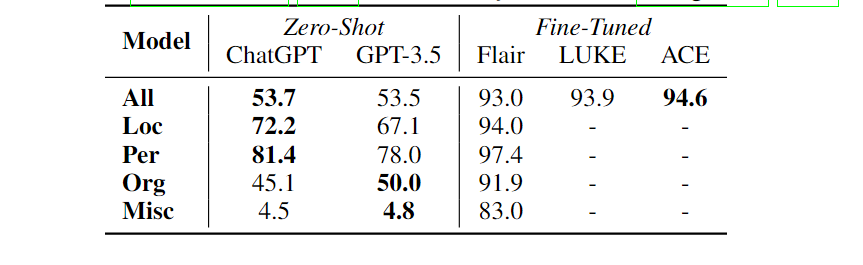
不如微调模型,序列标注仍然有问题,具体来说,ChatGPT 在“Loc”(“Location”)和“Per”(“Person”)类上的表现优于 GPT-3.5,而在“Org”(“Organization”)类上的表现比 GPT-3.5 差。两种模型在识别“杂项”(“杂项实体”)类方面表现出实用价值。上图说明了“杂项”的几个失败案例。在图的左侧部分,LLM 将“Bowling”识别为杂项实体,而基本事实是“None”。但是,“Bowling”确实属于实体类型“ball”,可以看作是一种杂项类型。在右侧,虽然“AMERICAN FOOTBALL CONFERENCE”确实是一个组织,但基本事实注释无法识别,这表明基本事实注释可能需要清理(尽管在极少数情况下)。因此,“杂项实体”类性能不佳部分是由于对 LLM 之间实体范围和特定任务数据集的基本事实注释的不同理解。下面是示例:

情感分析
负的预测的准,不均衡,整体上3.5更均衡更准,可以观察到 ChatGPT 在不同类上的性能相当不平衡。它在负样本上的表现几乎完美,而正标记数据的性能要差得多,这导致整体性能较差。相比之下,GPT-3.5 的结果更加平衡,表明 GPT-3.5 可以比 ChatGPT 更有效地解决情感分析。这种差异是由 ChatGPT 和 GPT-3.5 的不同训练数据引起的。

实验中解释尽管明确指定答案在任务指令中应该是精确的“正”或“负”,但 ChatGPT 和 GPT-3.5 仍然输出其他一些答案,例如“中性”和“混合”,这部分解释了为什么它们的性能比 FLAN 差得多。
下图是第二个测试的汇总表
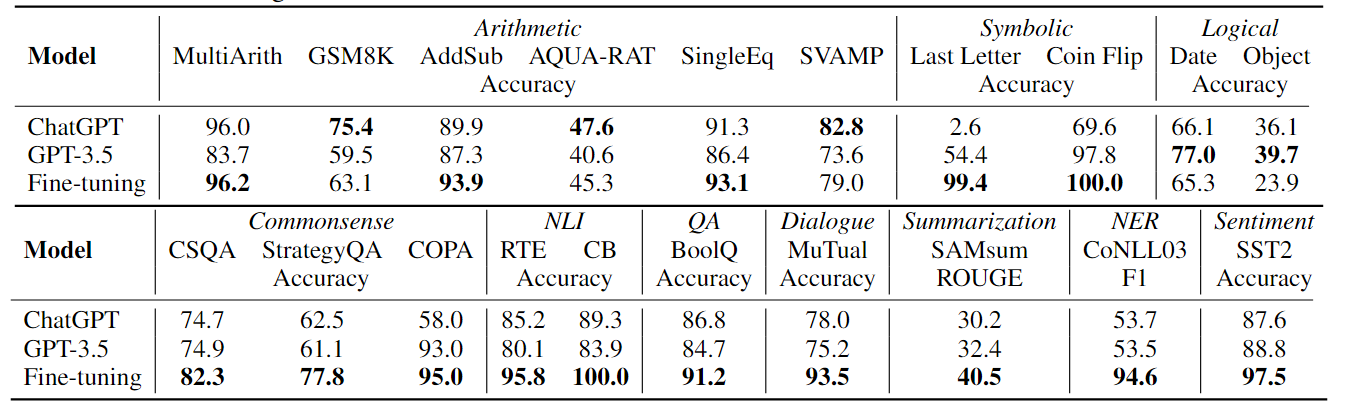
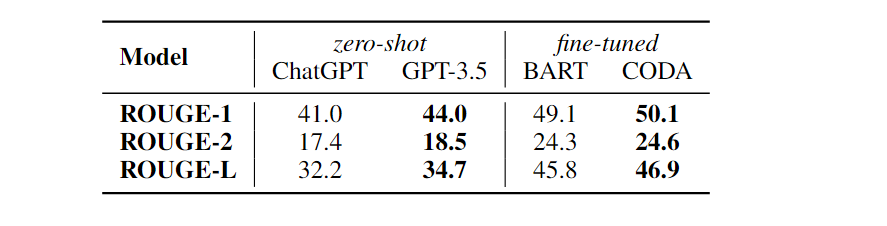
对话,总结等生成式任务,ChatGPT碾压zero-shot的其它模型,但仍然不及微调模型。
小结
总的来说,可以用第三篇评估文章的一句话“Jack of all trades, master of none”,也就是博而不精来总结,什么都能做,但是什么都做不到最好,可以看到在zero-shot领域,ChatGPT几乎秒杀所有LLM,但都不如经过具体领域微调的最新LLM。虽然在语言流畅度,理解问题能力,多轮对话,QA等方面大幅领先其它模型,但是其落到具体自然语言理解任务上,推理能力总体较强,但仍旧缺乏常识,在符号和逻辑推理方面表现不如普通LLM,命名实体识别正负样本不均衡,情感分析负面倾向较严重,分类问题表现良好,回归问题表现不佳。总结为以下几点:
- 提供假信息容易被误导
- 任务越复杂,准确率越低
- 缺乏常识
- 相似内容无法区分
- 需要理解语义做指定工作的任务(情感分析,命名实体识别)准确度比单纯的理解语义任务准确度低,受RLHF影响大
- 输出不稳定,仍有错误理解指令的情况发生
- 每个领域都达到能用的水准,但是都不如最新的微调LLM
ChatGPT对知识图谱的影响
参考刘焕勇的博客与王昊奋老师的采访
ChatGPT或LLM的出现其实本质来说,对于是否我们需要完全结构化(符号)表达的传统图谱会有反思。甚至很多传统的KG任务,比如知识抽取,知识融合,知识推理与计算,以及上层的问答、搜索、推荐其实都会受到影响。
受到影响的领域
- 短时间内,百科类通用知识图谱构建意义已经不大,因为搜索的范式已经产生了较大的变化,知识图谱在这方面落地仍然不如ChatGPT,new bing这类新一代搜索引擎。
- 搜索、问答、推荐,这几个领域使用知识图谱的意义短期内不大
- 知识抽取与构建,应当全面拥抱LLM
暂时不受影响的领域
- 图分析,图结构可视化,因为是离散的
- 时序图谱的未来归纳范式预测,这种规则化的预测暂时还是比ChatGPT要准确,但可能需要其辅助收集信息及更新。
- 多模态
两者可以结合的点
- 结合其在推理(常识和领域推理),业务系统交互,超自动化,时效性内容的接入和更新等方面,有不少可以做的。
- 各种图谱任务的text generation映射,以及prompt engineering。
- retrieval augmented DL的实现,这里retrieval的库包含大的KG,这样对选择example,对于约束prompt,对于提升推理能力都有可以做。也就是KG约束ChatGPT推理,检索增强,推理辅助,决策支持等功能,缓解缺乏常识等缺点
- KG本身往更多适合符号来做,包括数值计算,包括规则推理等方向去做深,因为这块对于LLM来说,其实是相对薄弱,或者说学习效率太低了。
- KG作为一个meta ontology来进行各种AI特别是Maas的编排和整合,形成更加完整的链条。
- 用LLM挖schema
- DB或KRR关联的部分,这块相对可以思考如何在图数据管理的同时,可以更好管理LLM,并进行有效协同,而KRR应该考虑更广义的推理,以及新的知识表示
需要的调整
科研口应该要调整,改变之前一个任务,一个模型的思路,思考一下如何站在巨人肩膀上做新的创新,尤其是对于LLM的评测,比较,发现其优点和不足,避免因为其优点产生的收益再去做一遍伪科研,这个其实和当时BERT打天下之后大家要做的调整一样。短期可以做原来的KG,中期应该是chatGPT enhanced或based KG,长期应该是新的KG研制和发展路线。竞合总是存在的,是好事。Gartner曲线中KG早就过了峰值,在走下坡路,应该更多从KG research往KG toolset甚至KG ecosystem发展,让他类似互联网,变成更好用,更易用,ChatGPT出圈也是这个道理。
小结
以大规模预训练语言模型为基础的chatgpt成功出圈,在近几日已经给人工智能板块带来了多次涨停,这足够说明这一风口的到来。而作为曾经的风口“知识图谱”而言,如何找到其与chatgpt之间的区别,找好自身的定位显得尤为重要。
形式化知识和参数化知识在表现形式上一直都是大家考虑的问题,两种技术都应该有自己的定位与价值所在。
知识图谱构建往往是抽取式的,而且往往包含一系列知识冲突检测、消解过程,整个过程都能溯源。以这样的知识作为输入,能在相当程度上解决当前ChatGPT的事实谬误问题,并具有可解释性。基于知识图谱的推理也能增强当前模型的推理能力。除此之外,ChatGPT还能提升知识获取的能力,因此这两项技术能够相互迭代、共同提升。
从根本上讲,知识图谱本质上是一种知识表示方式,其通过定义领域本体,对某一业务领域的知识结构(概念、实体属性、实体关系、事件属性、事件之间的关系)进行了精确表示,使之成为某个特定领域的知识规范表示。随后,通过实体识别、关系抽取、事件抽取等方法从各类数据源中抽取结构化数据,进行知识填充,最终以属性图或RDF格式进行存储。
从问题角度大模型在语义理解上的路线是对的,但不是真正理解背后的意思,事实正确性上有待提升,人构建的知识图谱事实正确性会可控一些但成本高不好用。
当然,ChatGPT也有明显的不足。文献一中认为,大家公认的,是它善于一本正经地胡说八道,因为ChatGPT是一个黑盒计算,当下在内容的可信性和可控性上有一定局限。“我们要给它足够正确的知识,再引入知识图谱这类知识管理和信息注入技术,还要限定它的数据范围和应用场景,使得它生成的内容更为可靠”。
而就chatgpt而言,其的缺陷也是存在的。
首先,无法联网使用,因此缺乏最新信息。 答案中常有事实谬误:例如认为alphago是OpenAI的技术,把历史人物和作品张冠李戴,对莫须有的技术词张口就来、解释得头头是道。(bing已经解决了)
其次,推理计算能力不足,难以给出靠谱的预测推断和建立潜在的关联。 对稍有复杂的数学计算题也常给出无比自信的错误答案。
另外,可解释性弱,无法给出知识和信息的来源。 同时也缺乏实体,也就无法真正触达人类的现实世界,只能通过”语言接口“与人类沟通交流。缺乏隐私保护机制。
但如果chatgpt创造出大量的内容之后,并作为数据源导入到知识图谱当中,那么就会影响知识图谱的准确性,这无疑有需要引起重视。
总结
ChatGPT已经改变了每一个人的生活,可以说是第四次工业革命,虽然在具体的专业任务上距离SOTA有差距,哪怕很多专家说没创新,大力出奇迹,就是已有技术的商业化而已,但是在每一个普通人看来已经是足够惊艳,技术就是如此,只有最终能落地才能掀起改革的浪潮,否则永远只是纸上谈兵,ChatGPT是属于我们这个时代的浪潮之巅,也是AI下一个十年的光明起点,乘势而上吧。