Prophet参数介绍
growth:趋势函数-默认是线性趋势(linear),还可以选非线性(logistic).
changepoints:突变点-默认是none,可以手动选择,如6-18节日有活动,就可以指点突变点在6-18。
n_changepoints:突变点个数-若未指定,Prophet自动从数据前80%选择25个默认突变点,若已经指定了chagepoints参数,则本参数已失效。
changepoint_range:突变点范围-若未指定,Prophet默认是数据前80%,若已经制定了chagepoints参数,则本参数已失效。
changepoint_prior_scale: 调节changepoints灵敏度-默认值为0.05,值越大对历史数据拟合程度越强,但会增加过拟合的风险。
yearly_seasonality: 是否有年季节性-默认自动检测。
weekly_seasonality: 数据是否有周季节性-默认自动检测。
daily_seasonality: 数据是否有天季节性-默认自动检测。
holidays:指定节假日-默认值为None,可以手动输入指定节假日。以DataFrame格式输入,包含:必选列[holiday(string)、ds(date)]、可选列[lower_window(int)、upper_window(int)],指定影响的前后窗口期。
入门案例
案例数据为佩顿 · 曼宁的维基百科主页每日访问量的时间序列数据(2007/12/10 - 2016/01/20),已对数据log化。
Tips:对数据进行log化的原因:
对数函数特点:在其定义域内是单调增加函数,取对数不会改变数据相对关系。
取对数可以将乘法转换成加法,方便计算。log(AB)=log(A)+log(B)
缩小数据的绝对数值,方便计算。
要注意的是,如果数据集中存在负数就不能取对数。
首先看数据源,ds:访问日期 y:经过对数化后的访问量
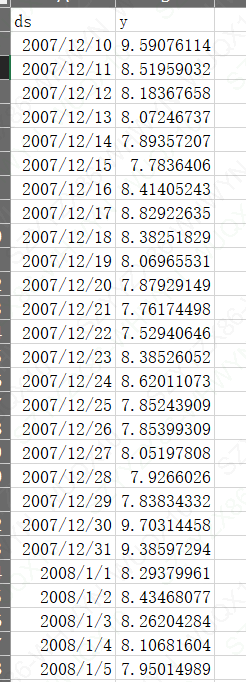
构建模型之前,一般先对我们的历史数据绘制趋势图,对数据历史趋势有一个了解。下面对比一下取对数和未取对数的区别:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from fbprophet import Prophetdf = pd.read_csv(r'C:\Users\Desktop\example_wp_log_peyton_manning.csv')
df['y2'] = 2.71**df['y']
df.plot(x='ds',y='y',figsize=(12,3),color = 'red')
df.plot(x='ds',y='y2',figsize=(12,3))
plt.show()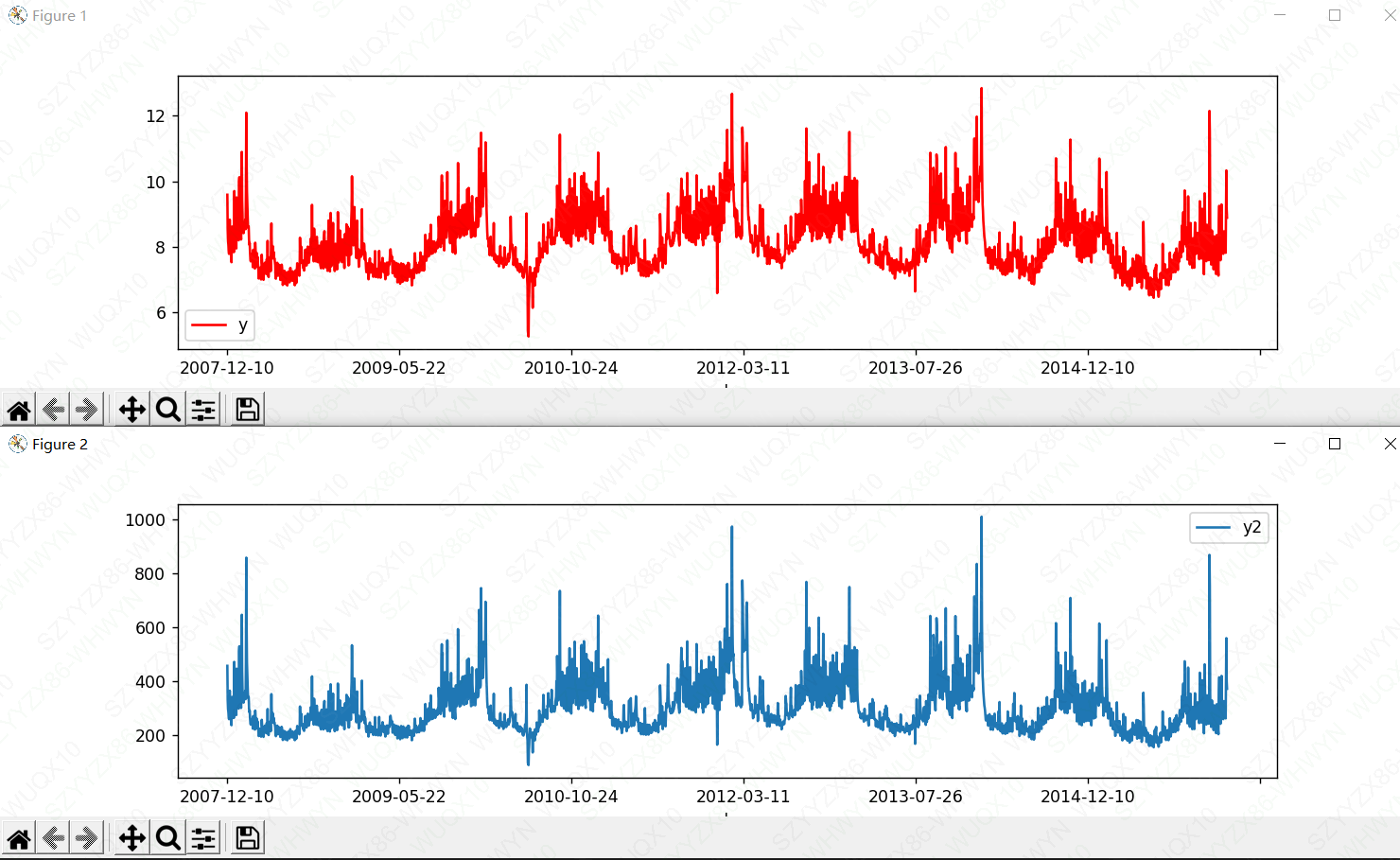
图1为取对数,图2未取对数,通过观察y轴的数值可以发现取对数可以缩小数值但不会改变数据的单调性。
预测指定天数时用prophet.make_future_dataframe来将未来的日期扩展指定的单位,periods = x 代表除历史数据的日期外再往后推 x 单位,注意x为历史数据的单位,如历史日期格式为yyyy-mm-dd,则x为天。
#构建模型对象
m = Prophet()
#训练模型对象
m.fit(df)
#指定预测天数
future = m.make_future_dataframe(periods=365)
#模型预测
forecast = m.predict(future)
print(forecast.head(5))
字段解释:
yhat:模型预测值
yhat_lower:预测下限
yhat_upper:预测上限
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']])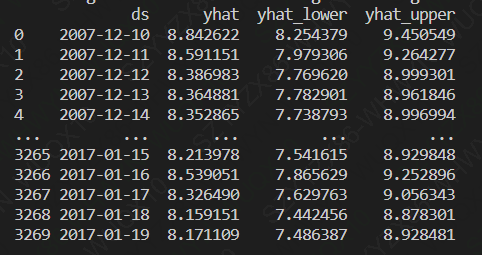
需要注意的是,模型预测出来的历史数据也是预测值,并不是真正的历史数据。
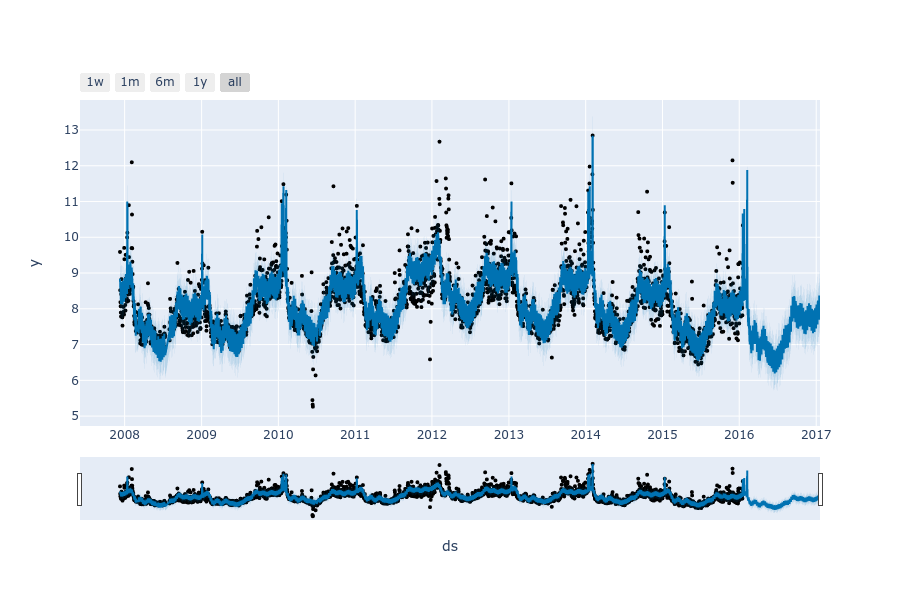
fig = m.plot(forecast)
plt.show()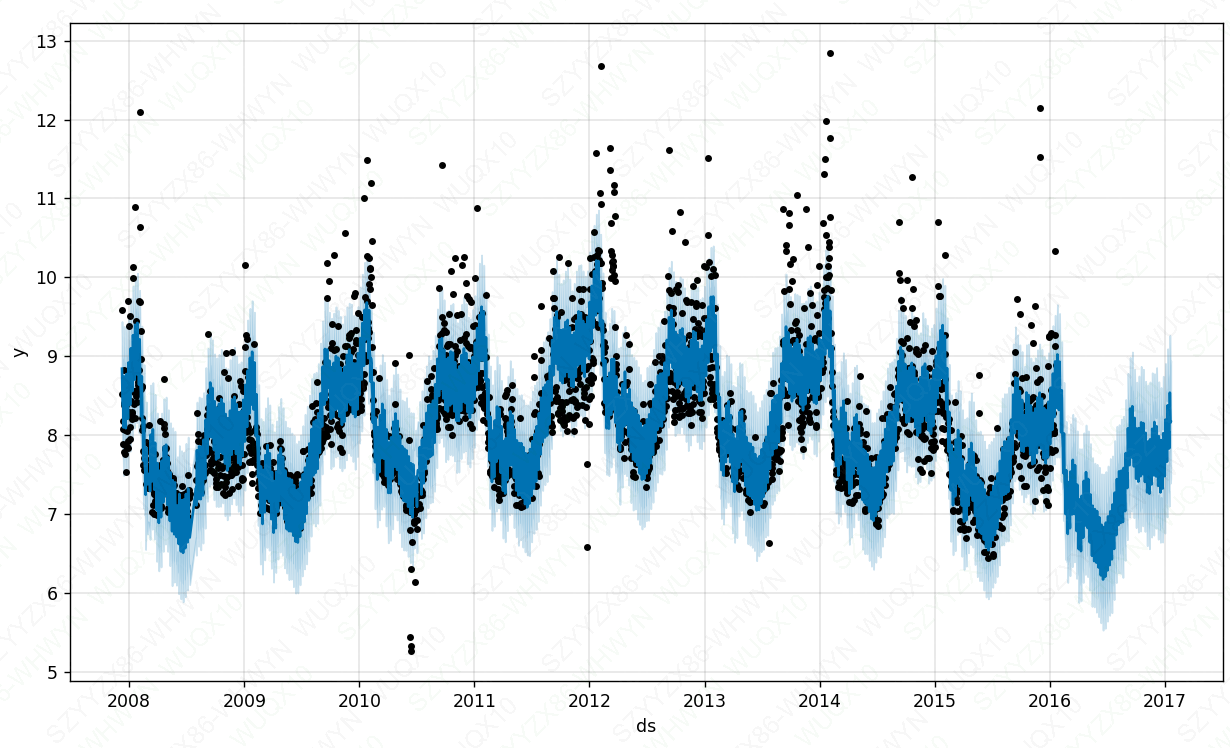
图中深蓝色的线为yhat(预测值)、浅蓝色分别为yhat_upper(预测值上限)和yhat_lower(预测值下限),黑点为真实值,不在浅蓝色线区域内的黑点即为异常点、没有黑点的区域为预测值。
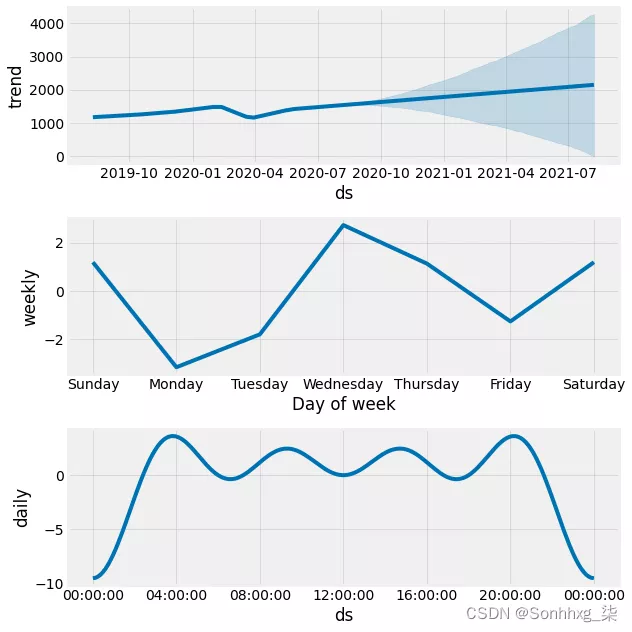
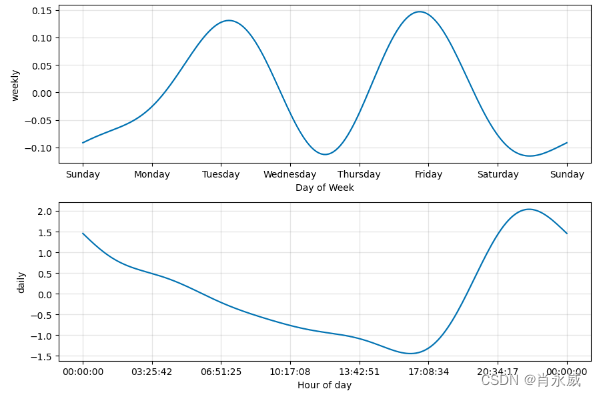
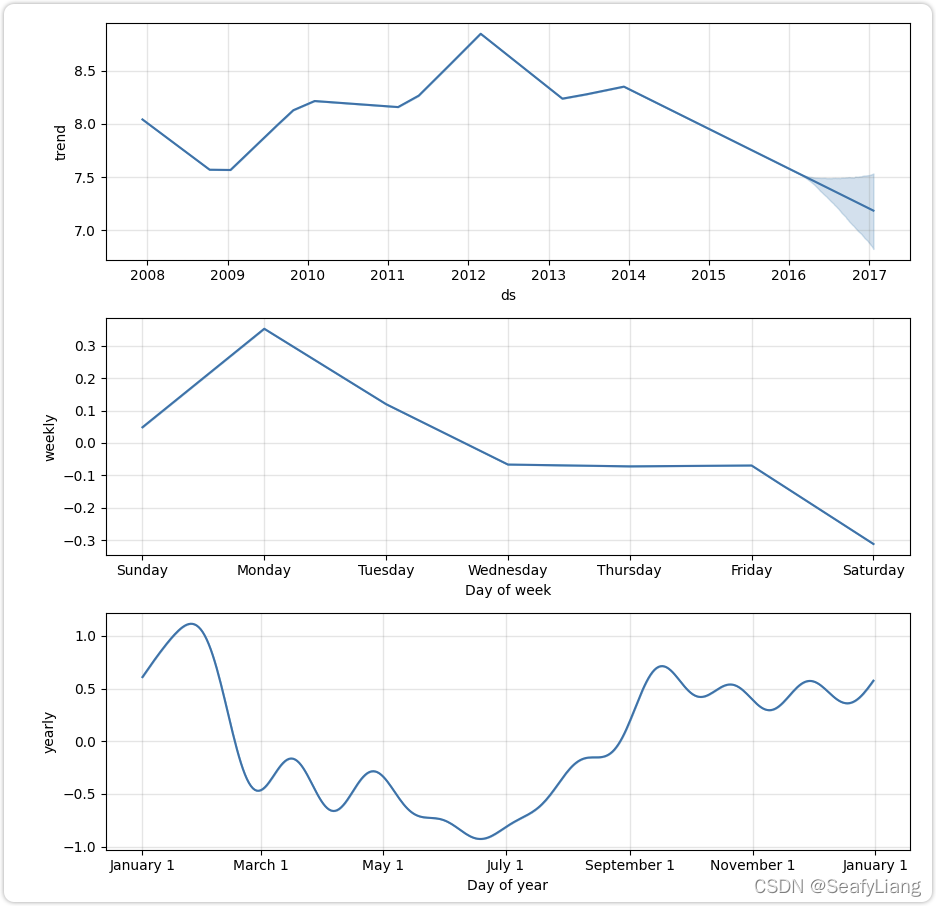
成分分析:使用Prophet.plot_components来分解模型成分。
fig = m.plot_components(forecast)成分分析能够很方便的发现时间序列在年、月、周的趋势
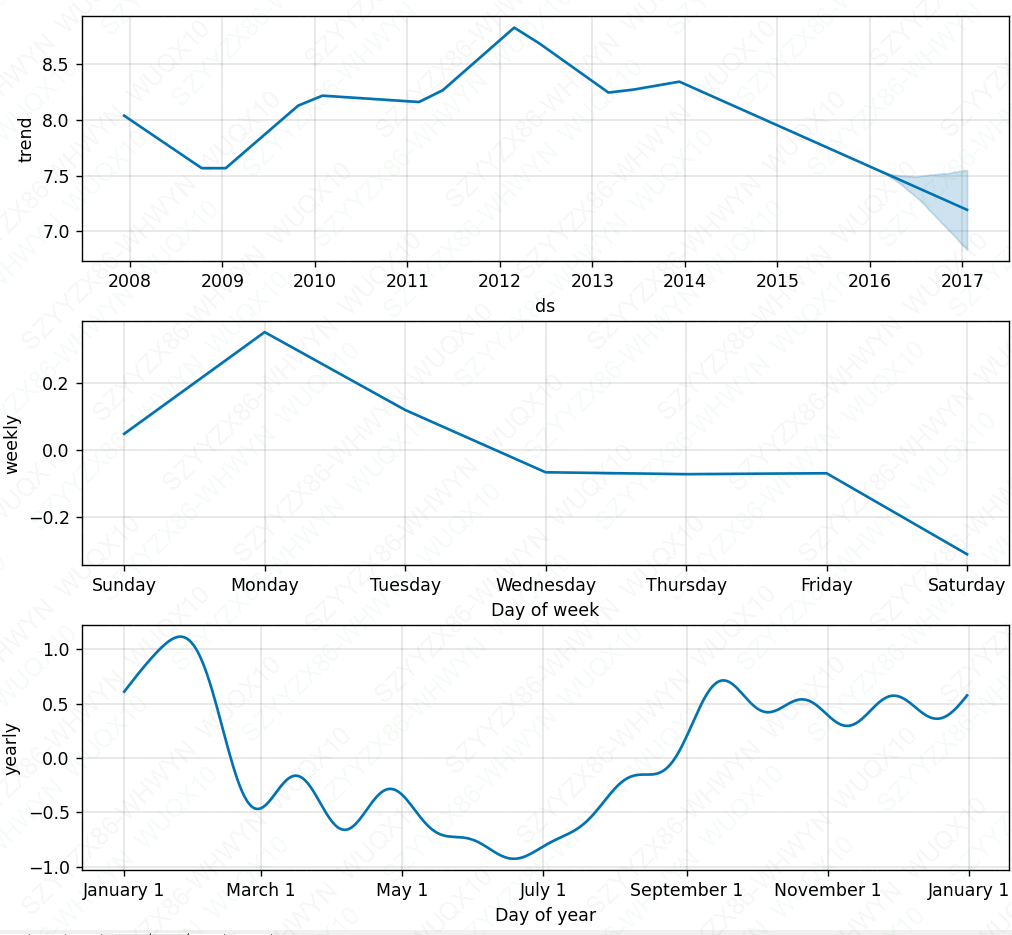
若训练结果并没有符合预期,可以尝试调参。
饱和预测
预测饱和增长
Prophet的growth参数在默认情况下使用线性模型进行预测。当预测增长情况时,通常会存在可到达的最大极限值,例如:总市场规模、总人口数等等。这被称作承载能力(carrying capacity),那么预测时就应当在接近该值时趋于饱和。
Prophet 可使用 logistic 增长趋势模型进行预测,同时指定承载能力。下面使用 R 语言的维基百科主页 访问量(取对数)的实例来进行说明。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from fbprophet import Prophet#导入数据
df_r = pd.read_csv(r'C:\Users\Desktop\example_wp_log_R.csv')
#可视化
df_r.plot(x='ds',y='y',figsize=(15,8))
plt.show()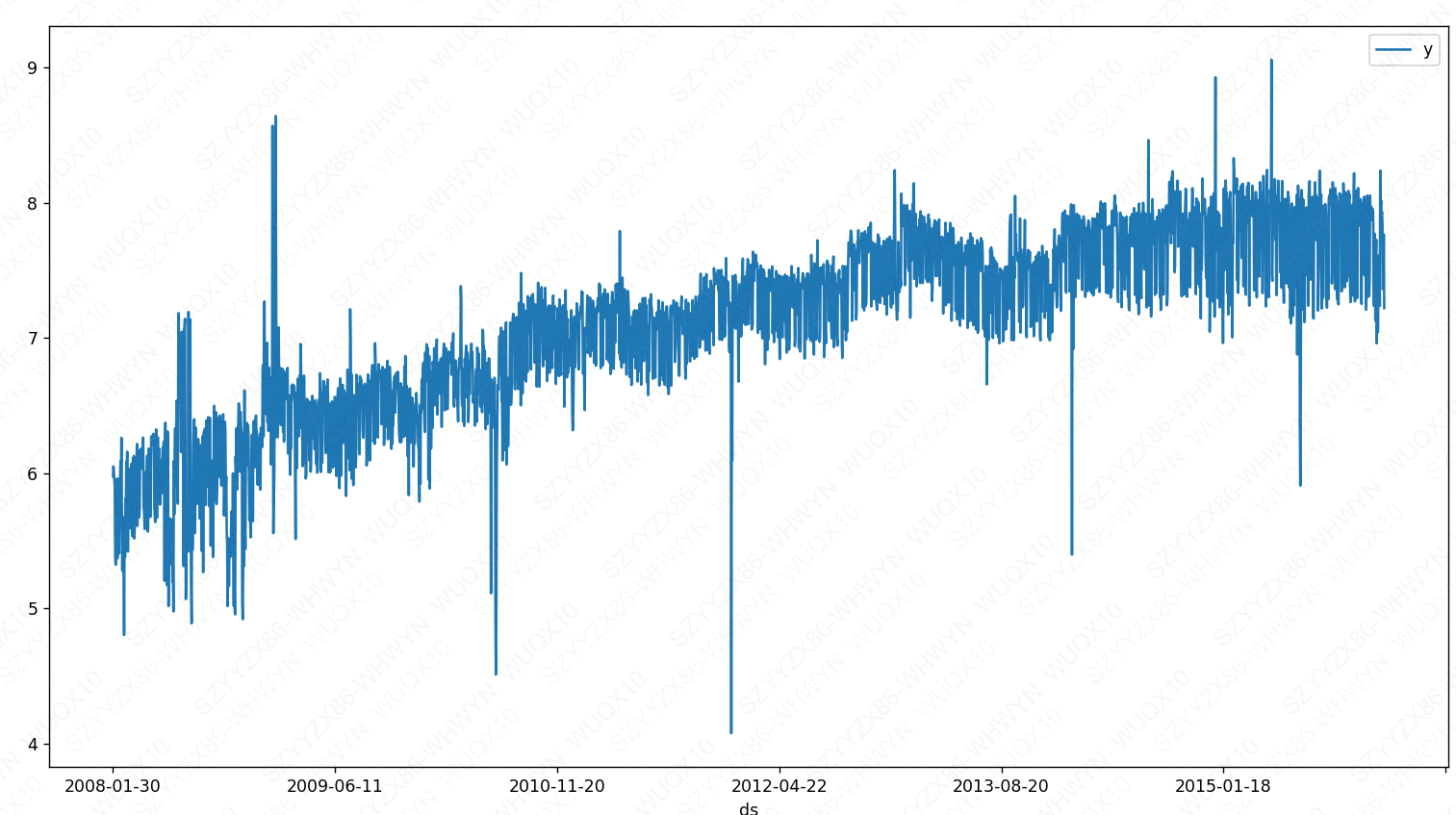
# 新建一列 cap 来指定承载能力的大小。本实例中假设取某个特定的值,通常情况下这个值应当通过市场规模的数据或专业知识来决定。
df_r['cap'] = 8.5
# growth='logistic'会对有趋势的模型拟合的更好
m_r = Prophet(growth='logistic')
#训练模型
m_r.fit(df_r)future_r = m_r.make_future_dataframe(periods=1800)
# 指定未来的承载能力,我们将未来的承载能力设定得和历史数据一样。
future_r['cap'] = 8.5fcst_r = m_r.predict(future_r)
fig = m_r.plot(fcst_r)
plt.show()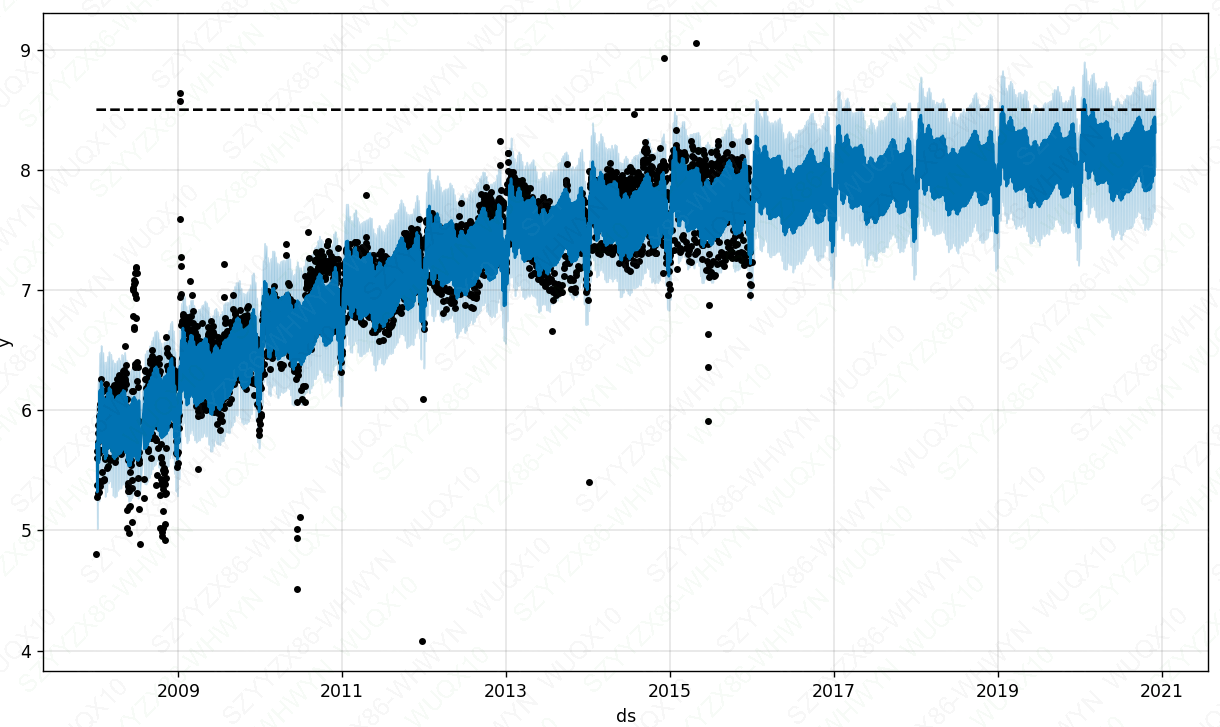
注意:如果不设置一个承载能力的话,预测趋势将比设置了承载能力的区间更大,承载能力要根据业务知识来确定。
# 新建一列 cap 来指定承载能力的大小。本实例中假设取某个特定的值,通常情况下这个值应当通过市场规模的数据或专业知识来决定。
# df_r['cap'] = 8.5
# growth='logistic'会对有趋势的模型拟合的更好
m_r = Prophet()
#训练模型
m_r.fit(df_r)future_r = m_r.make_future_dataframe(periods=1800)
# 指定未来的承载能力,我们将未来的承载能力设定得和历史数据一样。
# future_r['cap'] = 8.5fcst_r = m_r.predict(future_r)
fig = m_r.plot(fcst_r)
plt.show()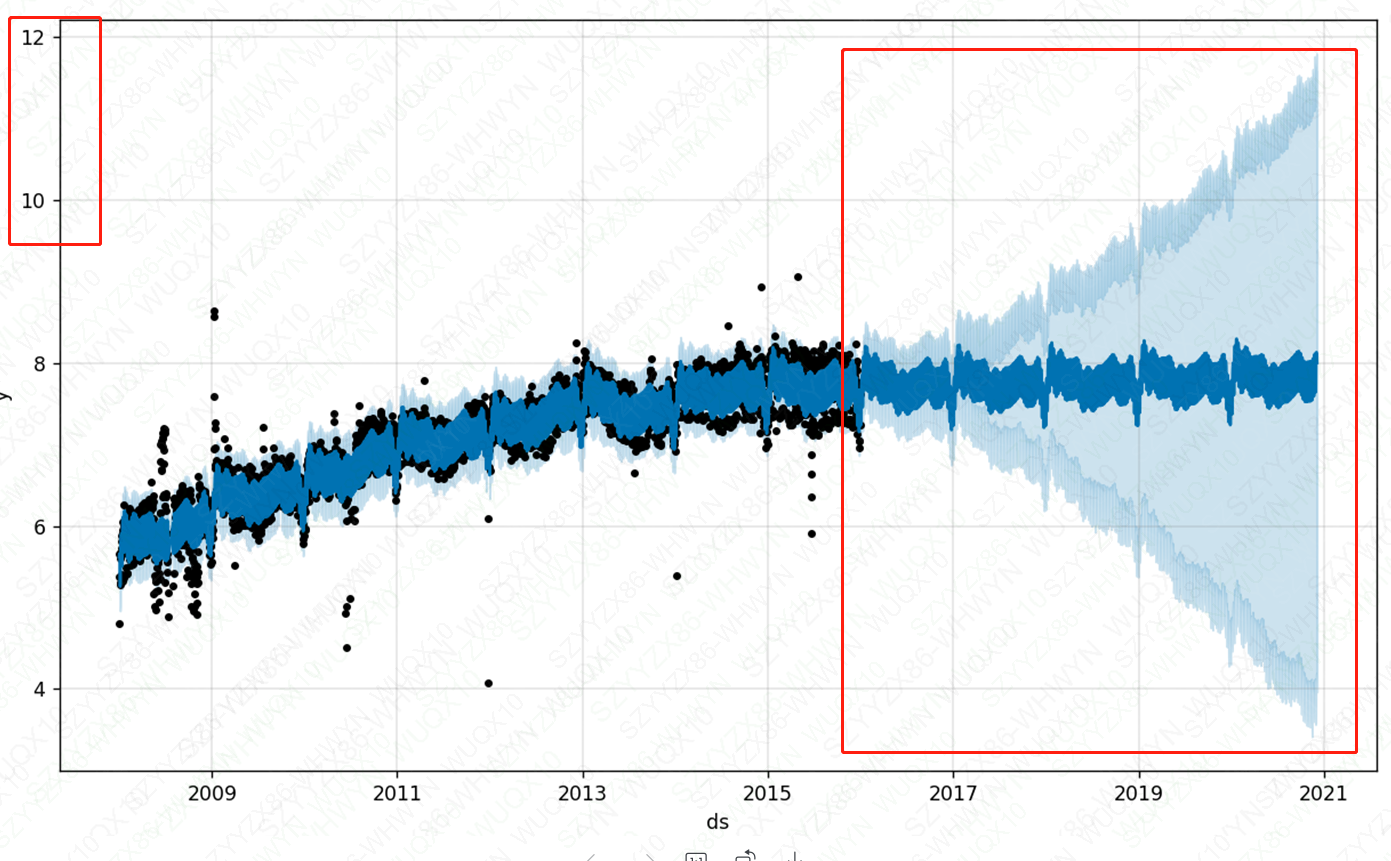
预测饱和减少
df_r['y'] = 10 - df_r['y']
df_rdown = df_r.copy()
# 相当于时间序列反过来了
df_rdown.plot(x='ds',y='y',figsize=(12,5))
plt.show()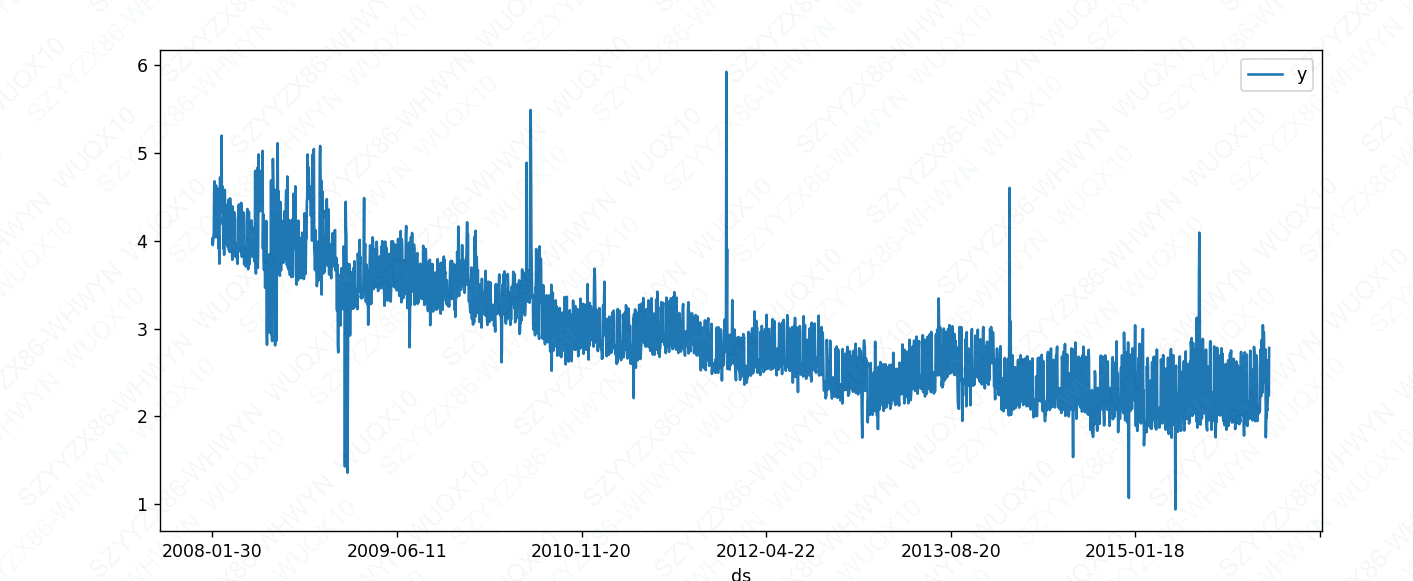
# 给最大值
df_rdown['cap'] = 6
# 最小值
df_rdown['floor'] = 1# 构建模型对象
m_rdown = Prophet(growth='logistic')# 模型训练
m_rdown.fit(df_rdown)# 指定预测天数
future_rdown = m_rdown.make_future_dataframe(periods=1800)# 设置未来数据
future_rdown['cap'] = 6
future_rdown['floor'] = 1#模型预测
fcst_rdown = m_rdown.predict(future_rdown)# 展示
fig_rdown = m_rdown.plot(fcst_rdown)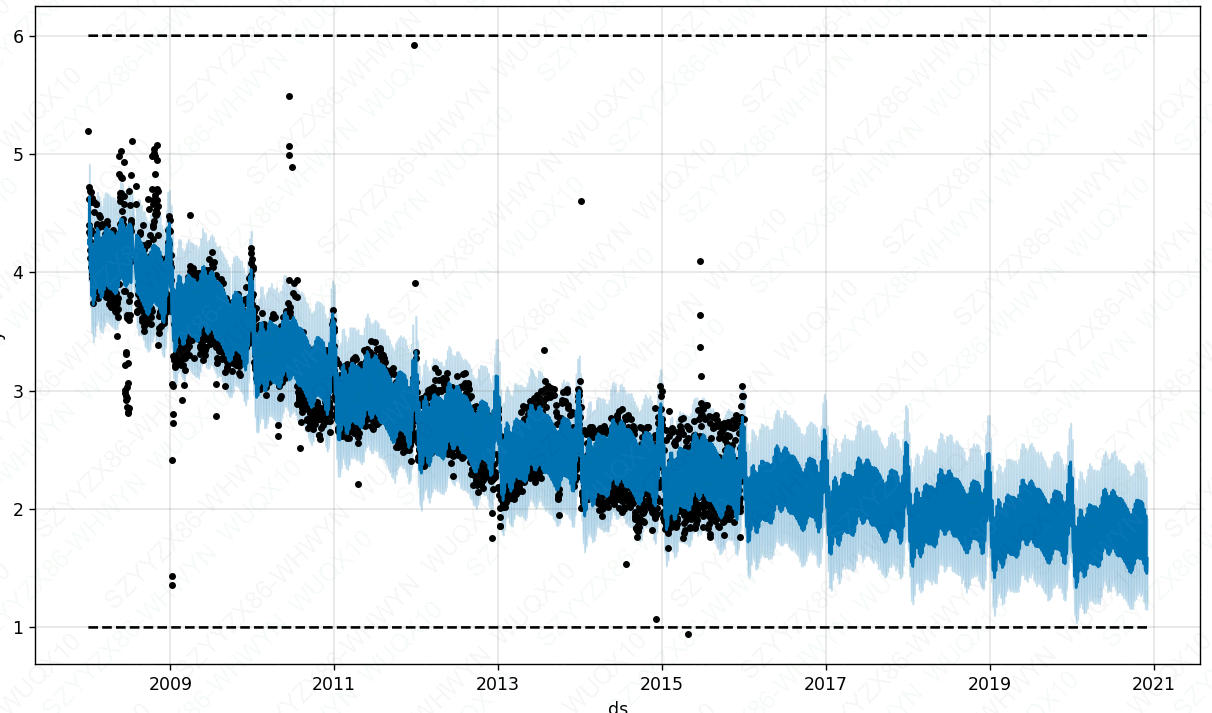
趋势突变点
在之前的部分,我们可以发现真实的时间序列数据往往在趋势中存在一些突变点。默认情况下, Prophet 将自动监测到这些点,并对趋势做适当地调整。不过,要是对趋势建模时发生了一些问题,例如:Prophet 不小心忽略了一个趋势速率的变化或者对历史数据趋势变化存在过拟合现象。如果我们希望对趋势的调整过程做更好地控制的话,那么下面将会介绍几种可以使用的方法。
#导入数据
df_tb = pd.read_csv(r'C:\Users\Desktop\example_wp_log_peyton_manning.csv')
#构建模型
m_tb = Prophet(changepoint_range=0.9)
#训练模型
m_tb.fit(df_tb)
future_tb = m_tb.make_future_dataframe(periods=365)
#预测
forecast_tb = m_tb.predict(future_tb)突变点检测
默认情况下,只有在时间序列的前80%才会推断出突变点,以便有足够的长度来预测未来的趋势,并避免在时间序列的末尾出现过度拟合的波动。这个默认值可以在很多情况下工作,但不是所有情况下都可以,可以使用changepoint_range参数进行更改。例如,Python中的m = Prophet(changepoint_range=0.9)。这意味着将在时间序列的前90%处寻找潜在的变化点。
from fbprophet.plot import add_changepoints_to_plotfig = m_tb.plot(forecast_tb)
a = add_changepoints_to_plot(fig.gca(), m_tb, forecast_tb)
plt.show()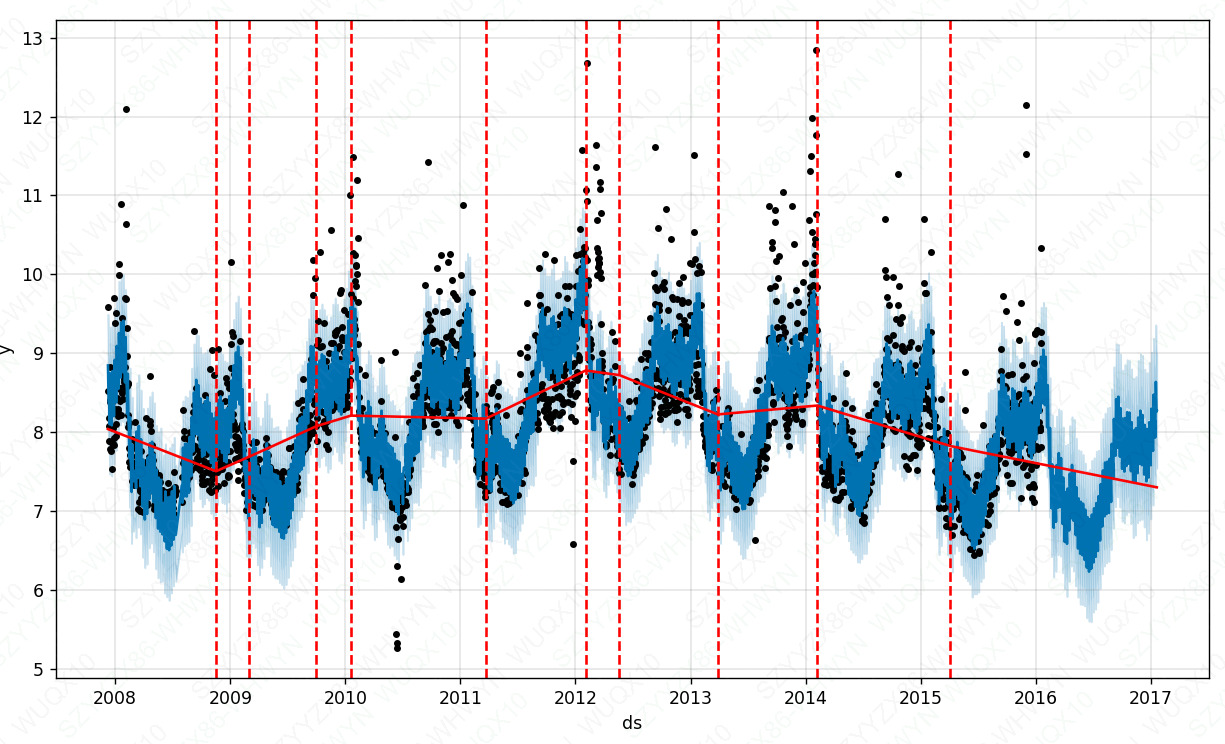
可以从上图看出,还是有一些突变点没有被检测到。
调整去趋势的灵活性
如果趋势的变化被过度拟合(即过于灵活)或者拟合不足(即灵活性不够),可以利用输入参数 changepoint_prior_scale 来调整稀疏先验的程度。默认下,这个参数被指定为 0.05 。
增加这个值,会导致趋势拟合得更加灵活(避免欠拟合,同时可能增加过拟合风险)。
#调整参数
m_tbdown = Prophet(changepoint_prior_scale=0.00001)
#训练模型
m_tbdown.fit(df_tb)
future_tbdown = m_tbdown.make_future_dataframe(periods=365)
#预测
forecast_tbdown = m_tbdown.predict(future_tbdown)
fig = m_tbdown.plot(forecast_tbdown)
plt.show()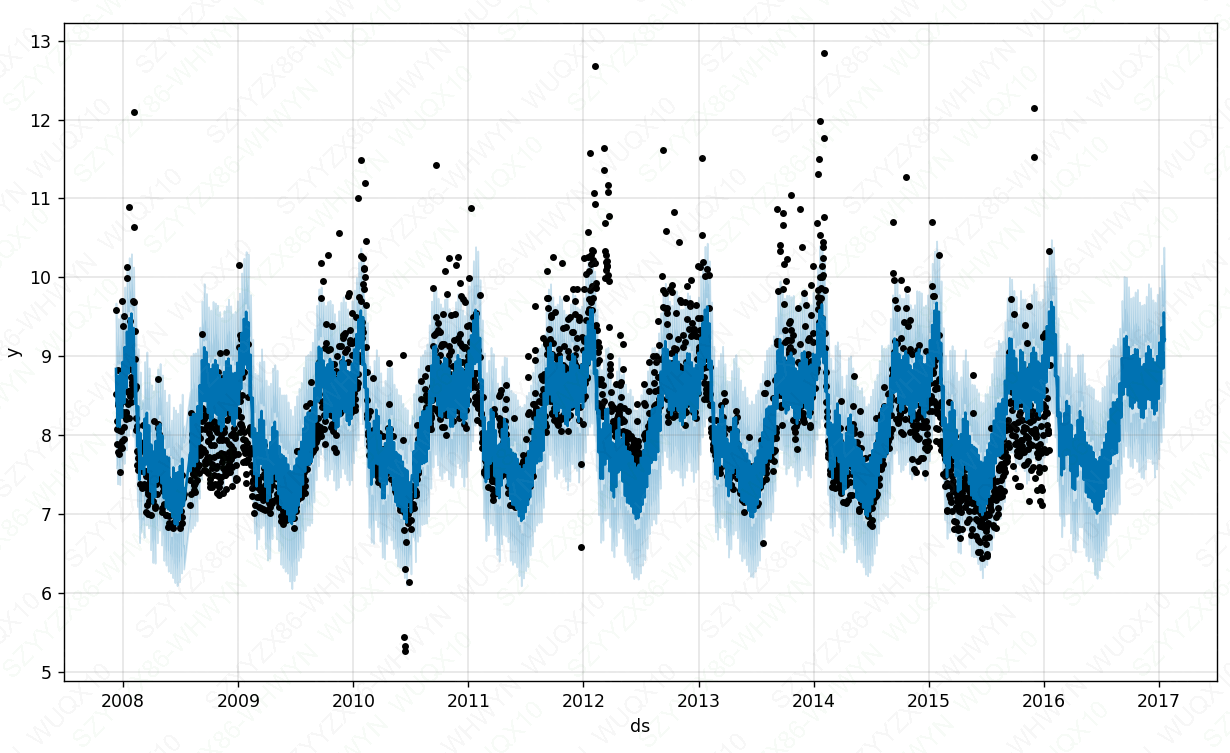
可以看到当changepoint_prior_scale较小时,预测区间变小了
m_tbup = Prophet(changepoint_prior_scale=1000)
m_tbup.fit(df_tb)
future_tbup = m_tbup.make_future_dataframe(periods=365)
forecast_tbup = m_tbup.predict(future_tbup)
fig = m_tbup.plot(forecast_tbup)
plt.show()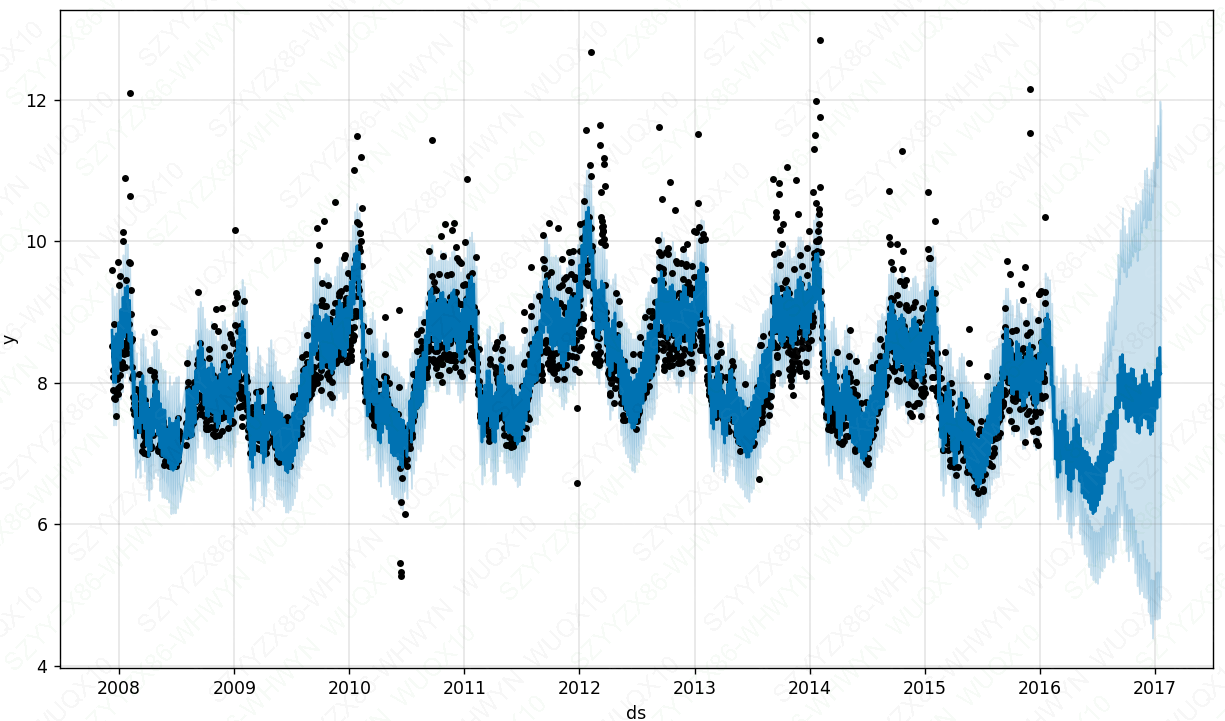
可以看到当changepoint_prior_scale较小时,预测区间变得很大
总结:
1、changepoint_prior_scale越高,时间序列预测幅度越大,但同时也可能过拟合。
2、changepoint_prior_scale越低,时间序列预测幅度越小,但同时也可能欠拟合。
控制突变点的位置
m_cp = Prophet(changepoints=['2014-01-01'])#可以多选日期
m_cp.fit(df_tb)
future_cp = m_cp.make_future_dataframe(periods=365)
forecast_cp = m_cp.predict(future_cp)
m_cp.plot(forecast_cp)
plt.show()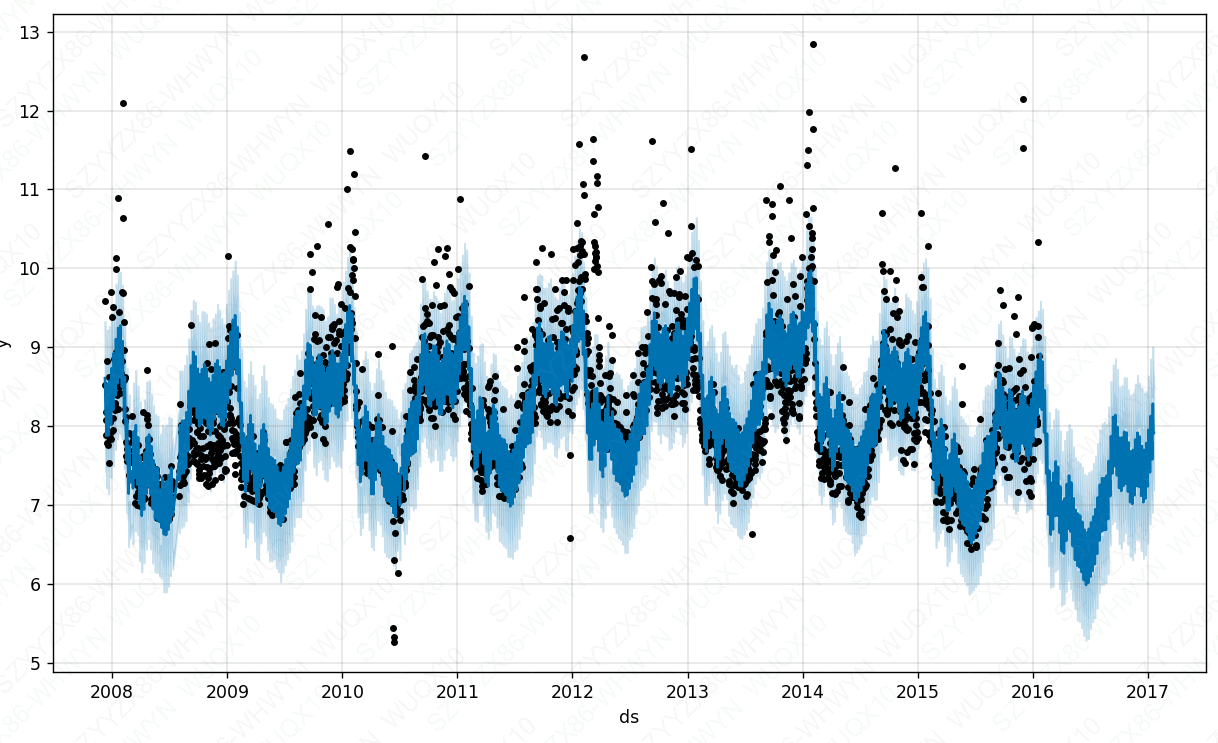
对假期和特征事件(突发活动事件)建模
如果需要专门对节假日或者其它的事件进行建模,你就必须得为此创建一个新的dataframe,其中包含两列(节假日 holiday 和日期戳 ds ),每行分别记录了每个出现的节假日。这个数据框必须包含所有出现的节假日,不仅是历史数据集中还是待预测的时期中的。如果这些节假日并没有在待预测的时期中被注明, Prophet 也会利用历史数据对它们建模,但预测未来时却不会使用这些模型来预测。
业务场景:过几天我们有个活动,能不能帮我预测下当日PCU (当天最高同时在线人数)
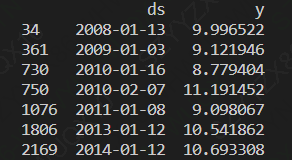
'lower_window','upper_window',前后的影响范围(该例中holiday的sd单位为天):lower_window为n即代表影响第一个日期(2008-01-13)往前n天也会被影响。
#传入节日数据
playoffs = pd.DataFrame({'holiday': 'playoff','ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16','2010-01-24', '2010-02-07', '2011-01-08','2013-01-12', '2014-01-12', '2014-01-19','2014-02-02', '2015-01-11', '2016-01-17','2016-01-24', '2016-02-07']),'lower_window': 0,'upper_window': 0,
})
superbowls = pd.DataFrame({'holiday': 'superbowl','ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),'lower_window': 0,'upper_window': 0
})
holidays = pd.concat((playoffs, superbowls))#合并两个节日数据df = pd.read_csv('example_wp_log_peyton_manning.csv')
#构建模型
m = Prophet(holidays=holidays)
#训练模型
m.fit(df)
#指定预测天数
future = m.make_future_dataframe(periods=365)
#预测
forecast = m.predict(future)#将df在节假日的ds和预测值拉出来
df_fc = forecast[forecast['ds'].isin(holidays['ds'])][['ds','yhat']]
df_fc['ds'] = df_fc['ds'].astype(str)# 成分分析
fig = m.plot_components(forecast)
plt.show()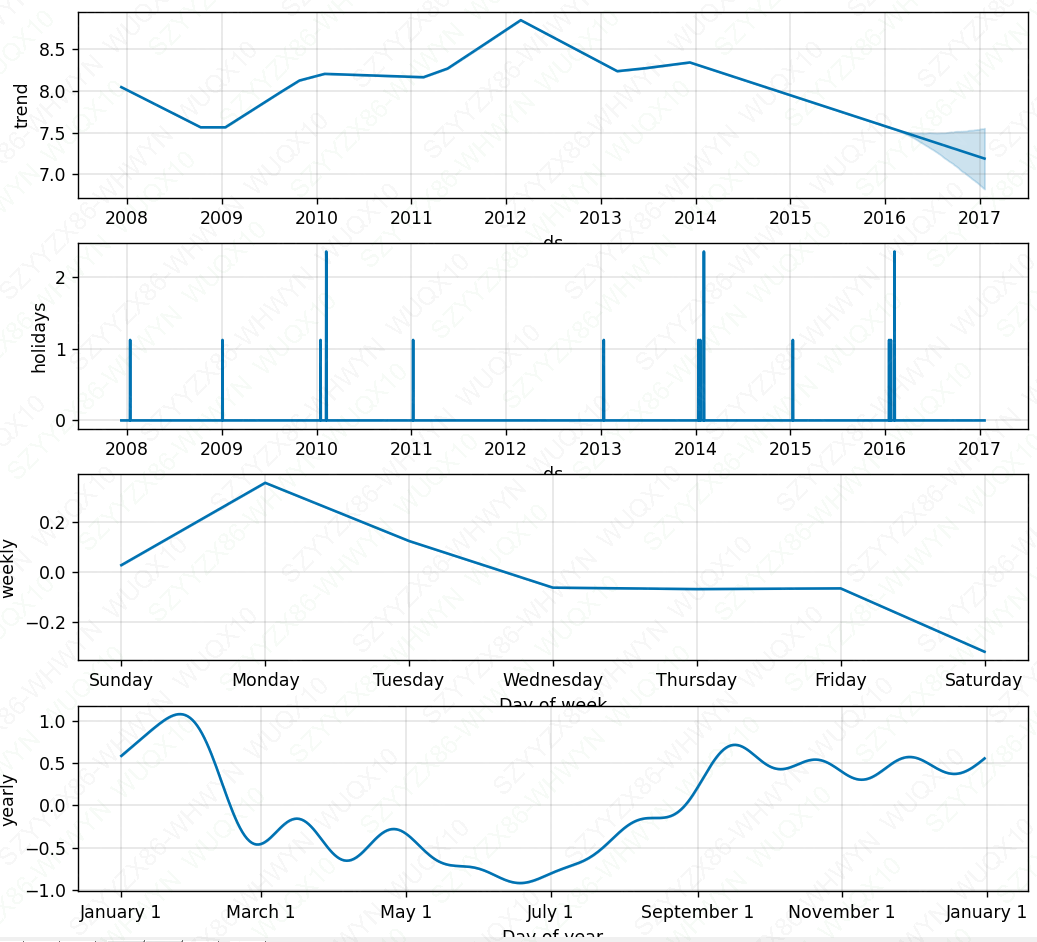
有没有holidays参数的区别还是很大的,可以对比一下:
df_ture = df[df['ds'].isin(holidays['ds'].astype(str))]
print(df_ture)
首先看数据的真实值:
# 在没有holidays参数时
df = pd.read_csv(r'C:\Users\wuqx10\Desktop\example_wp_log_peyton_manning.csv')m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)df_fc_noholidays = forecast[forecast['ds'].isin(holidays['ds'])][['ds','yhat']]
df_fc_noholidays['ds'] = df_fc_noholidays ['ds'].astype(str)df_fc_noholidays.columns = ['ds','yno']
df_c = pd.merge(pd.merge(df_fc,df_ture,how='left',on='ds'),df_fc_noholidays,how='left',on='ds')
df_c['dif_holiday'] = df_c['yhat'] - df_c['y']
df_c['dif_noholiday'] = df_c['yno'] - df_c['y']print(df_c['dif_holiday'].sum())
print(df_c['dif_noholiday'].sum())
乘法季节性
默认情况下,Prophet能够满足附加的季节性,这意味着季节性的影响是加到趋势中得到了最后的预报(yhat),而航空旅客数量的时间序列是一个附加的季节性不起作用的例子:
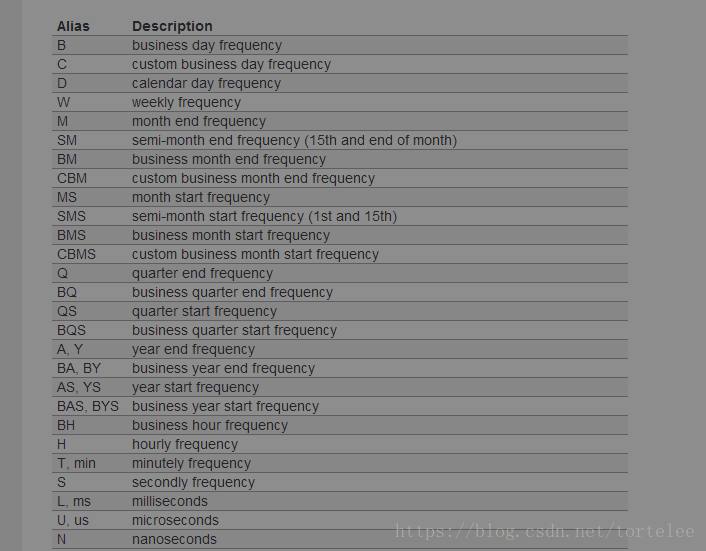
freq :
#读取文件
df_fly = pd.read_csv(r'C:\Users\Desktop\example_air_passengers.csv')
#构建模型
m_fly = Prophet()
#训练模型
m_fly.fit(df_fly)
#指定预测天数
future_fly = m_fly.make_future_dataframe(50, freq='M')
#预测
forecast_fly = m_fly.predict(future_fly)
fig = m_fly.plot(forecast_fly)
plt.show()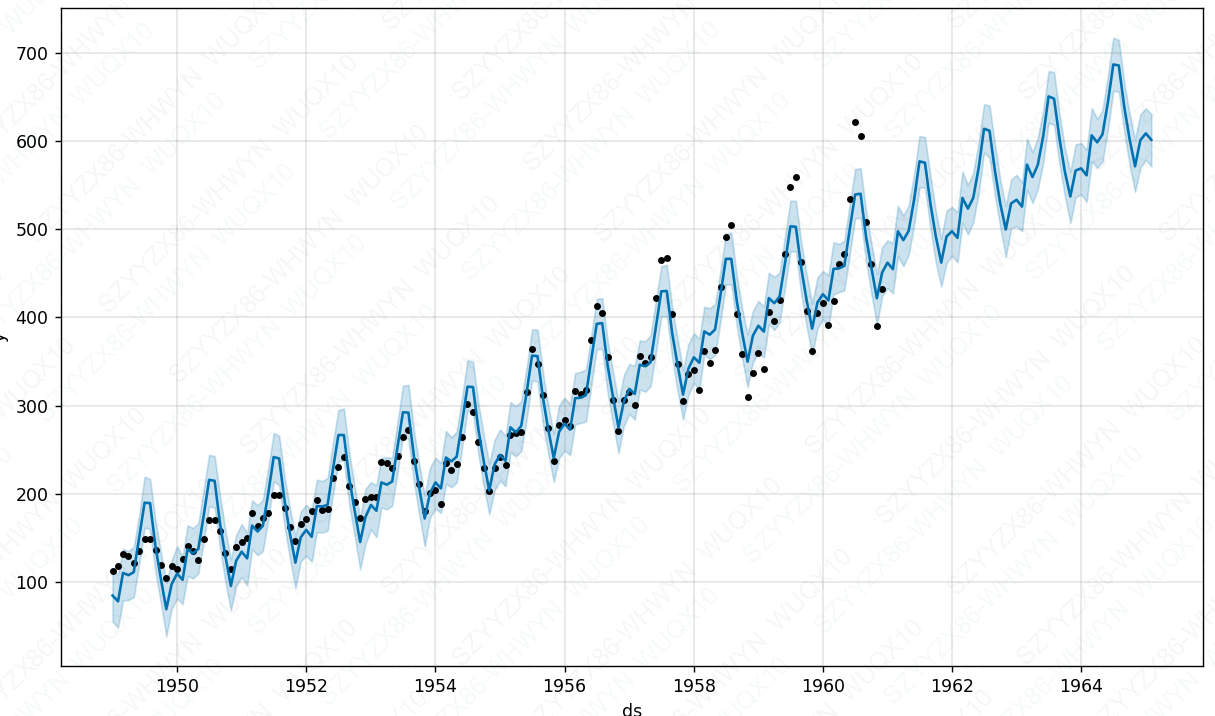
这个时间序列有一个明显的年度周期,但预测中的季节性在时间序列开始时太大,在结束时又太小。在这个时间序列中,季节性并不是Prophet所假定的是一个恒定的加性因子,而是随着趋势在增长。这就是乘法季节性(multiplicative seasonality)。
# Prophet可以通过设置seasonality_mode='multiplicative'来建模乘法季节性:
m_fly = Prophet(seasonality_mode='multiplicative')
m_fly.fit(df_fly)
forecast_fly = m_fly.predict(future_fly)
fig = m_fly.plot(forecast_fly)
plt.show()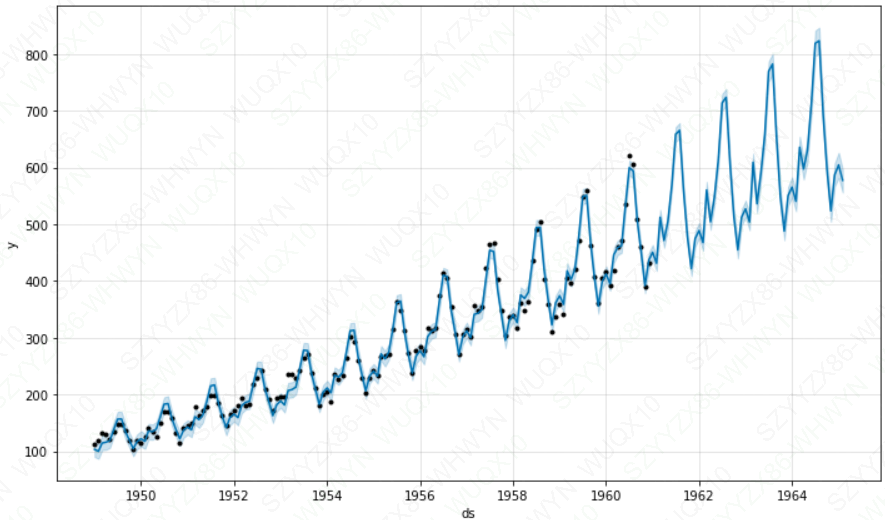
预测区间
df = pd.read_csv(r'C:\Users\Desktop\example_wp_log_peyton_manning.csv')m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
fig = m.plot(forecast)
plt.show()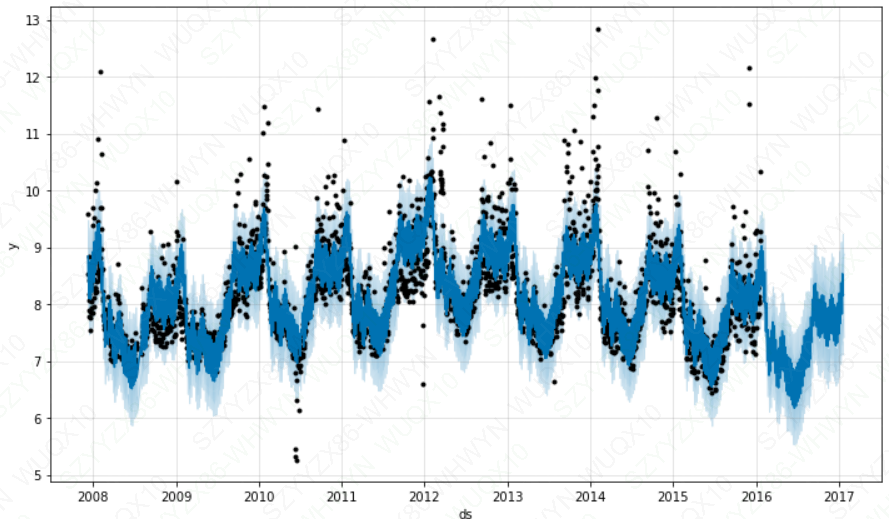
# 调整置信区间 interval_width
# 【0,1】m = Prophet(interval_width = 1)
m.fit(df)
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
fig = m.plot(forecast)
plt.show()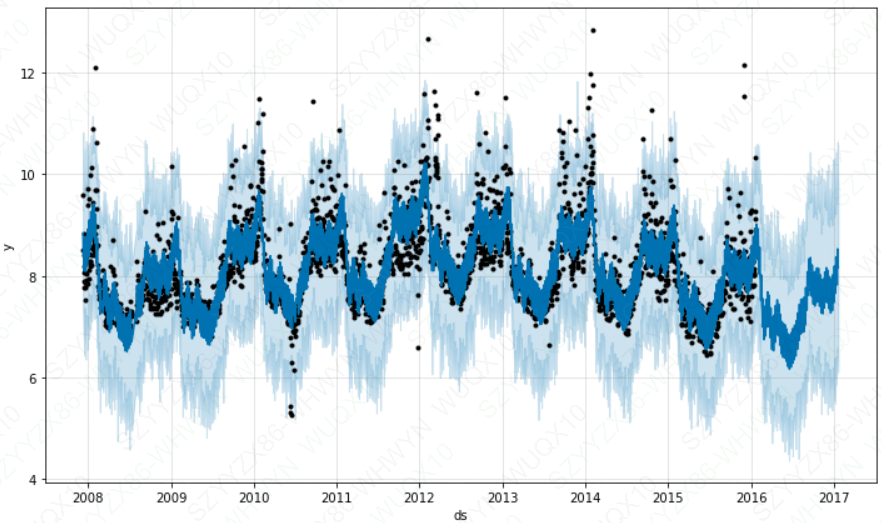
异常值处理
df_ro = pd.read_csv(r'C:\Users\Desktop\example_wp_log_R_outliers1.csv')
df_ro.plot(x='ds',y='y',figsize=(15,5))
plt.show()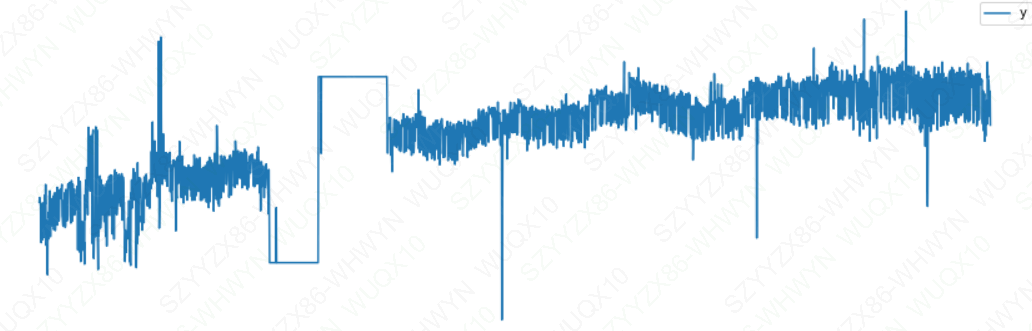
m_ro = Prophet()
m_ro.fit(df_ro)
future_ro = m_ro.make_future_dataframe(periods=1096)
forecast_ro = m_ro.predict(future_ro)
m_ro.plot(forecast_ro)
plt.show()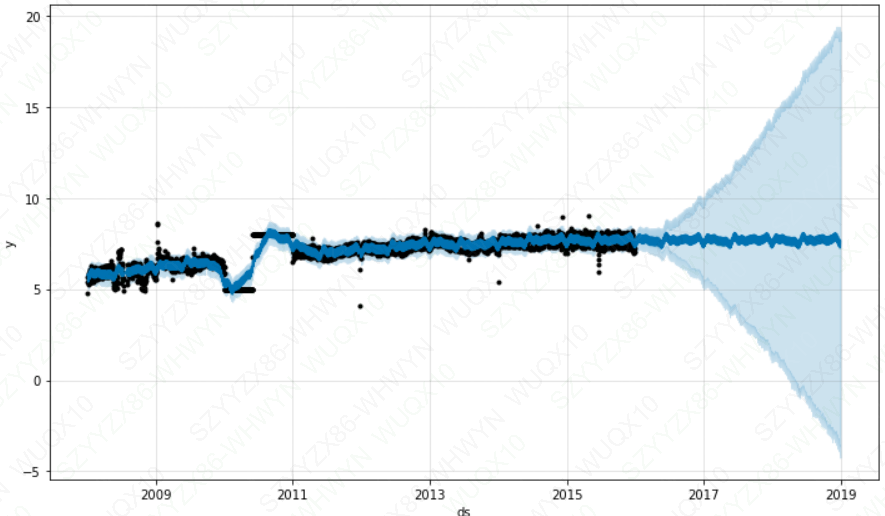
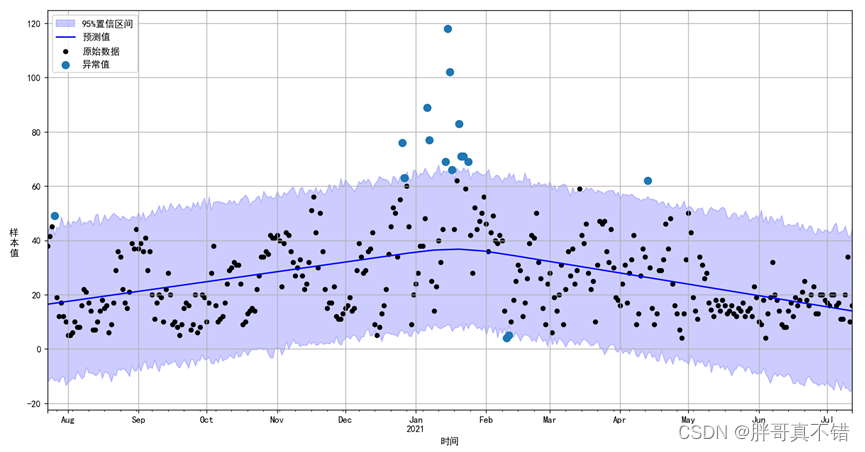
如上输出图所示,趋势预测看似合理,预测区间的估计却过于广泛。 Prophet 虽能够处理历史数据中的异常值,但仅仅是将它们与趋势的变化拟合在一起,认为未来也会有类似的趋势变化。
处理异常值最好的方法是移除它们,而 Prophet 是能够处理缺失数据的。如果在历史数据中某行的值为空( NA ),但是在待预测日期数据框 future 中仍保留这个日期,那么 Prophet 依旧可以给出该行的预测值。
df_ro.loc[(df_ro['ds'] > '2010-01-01') & (df_ro['ds'] < '2011-01-01'), 'y'] = None
m_ro = Prophet()
m_ro.fit(df_ro)
future_ro = m_ro.make_future_dataframe(periods=1096)
forecast_ro = m_ro.predict(future_ro)
m_ro.plot(forecast_ro)
plt.show()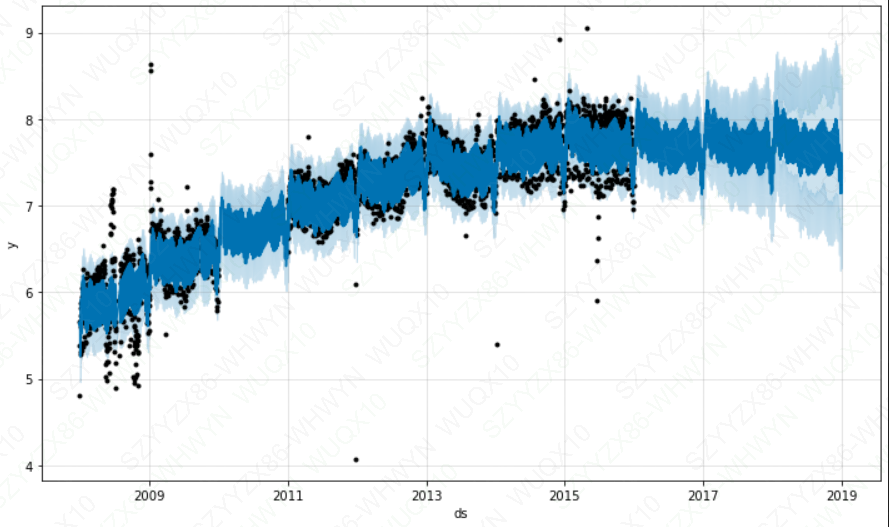
上述这个实例虽然影响了不确定性的估计,却没有影响到主要的预测值 yhat 。但是,现实往往并非如此,接下来,在上述数据集基础上加入新的异常值后再建模预测:
df_ro2 = pd.read_csv(r'C:\Users\Desktop\example_wp_log_R_outliers2.csv')
df_ro2.plot(x='ds',y='y',figsize = (15,5))
plt.show()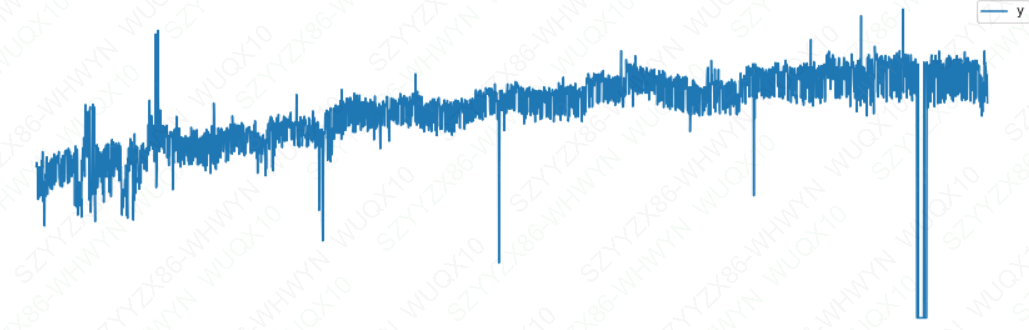
m_ro2 = Prophet()
m_ro2.fit(df_ro2)
future_ro2 = m_ro2.make_future_dataframe(periods=1096)
forecast_ro2 = m_ro2.predict(future_ro)
m_ro2.plot(forecast_ro2)
plt.show()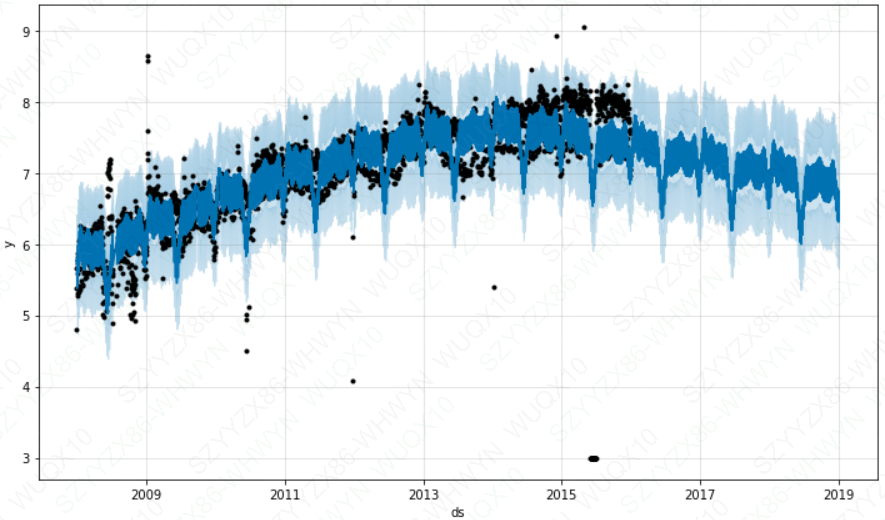
这里 2015年 6 月存在一些异常值破坏了季节效应的估计,因此未来的预测也会永久地受到这个影响。最好的解决方法就是移除这些异常值
df_ro2.loc[(df_ro2['ds'] > '2015-06-01') & (df_ro2['ds'] < '2015-06-30'), 'y'] = Nonem_ro2 = Prophet()
m_ro2.fit(df_ro2)
future_ro2 = m_ro2.make_future_dataframe(periods=1096)
forecast_ro2 = m_ro2.predict(future_ro)
m_ro2.plot(forecast_ro2)
plt.show()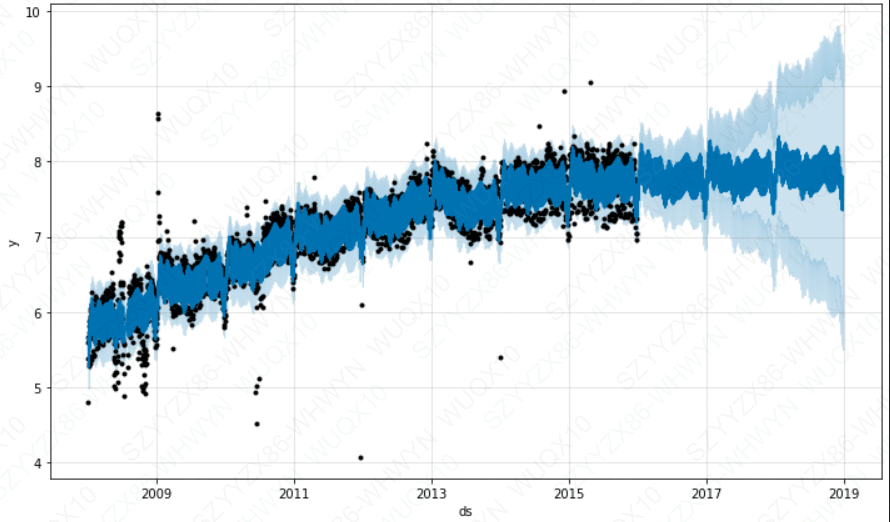
非日数据
子日数据
Prophet可以通过在ds列中传递一个带有时间的dataframe来对时间序列进行子日(Sub-daily)观测。时间的格式应该是YYYY-MM-DD - HH:MM:SS。当使用子日数据时,日季节性将自动匹配。在这里,我们用5分钟的分辨率数据集(约塞米蒂的每日温度)对Prophet进行数据匹配
freq预测的点的时间间隔:
df = pd.read_csv(r'C:\Users\Desktop\example_yosemite_temps.csv')
df['ds'] = pd.to_datetime(df['ds'])
df.plot(x='ds',y='y',figsize=(15,5))
plt.show()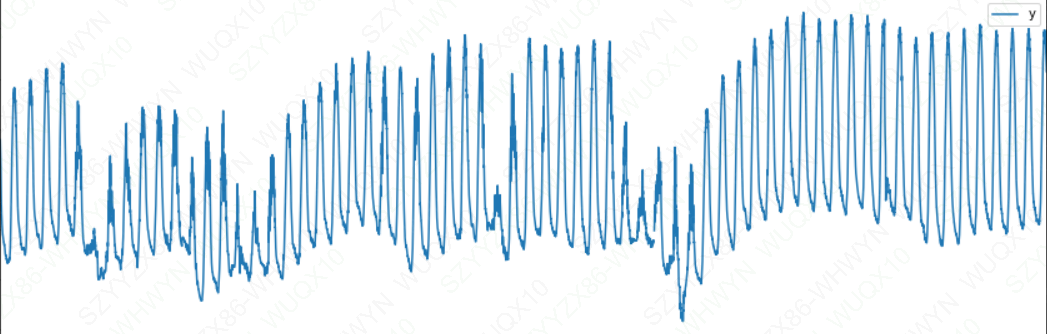
m = Prophet().fit(df)
future = m.make_future_dataframe(periods=30,freq='5min')
fcst = m.predict(future)
fig = m.plot(fcst)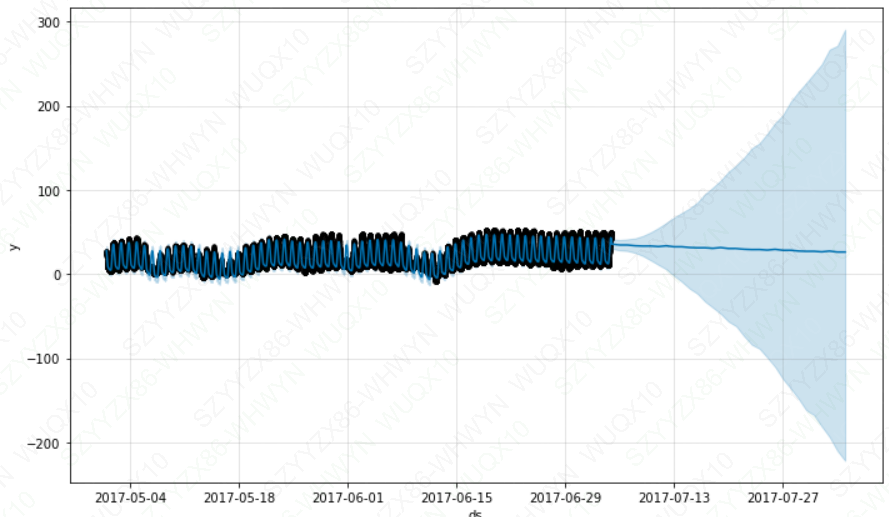
假设上面的数据集只有每天早上6点之前的观测值:
df2 = df.copy()
df2['ds'] = pd.to_datetime(df2['ds'])
# 只保留每天早上6点之前的数据
df2 = df2[df2['ds'].dt.hour < 6]
df2.plot(x='ds',y='y',figsize=(15,5))
plt.show()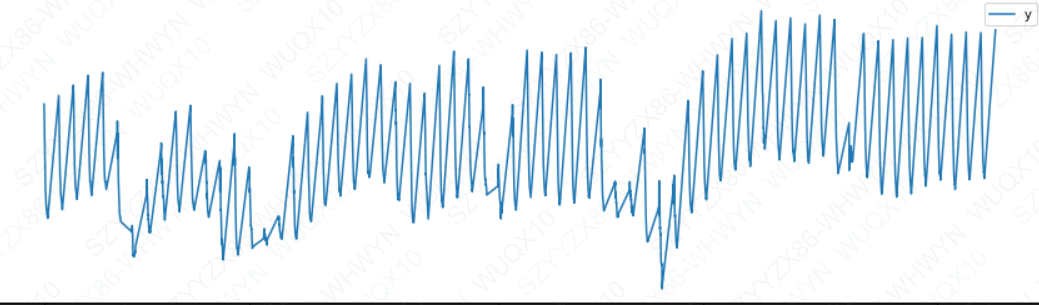
m = Prophet().fit(df2)
future = m.make_future_dataframe(periods=300, freq='H')
fcst = m.predict(future)
fig = m.plot(fcst)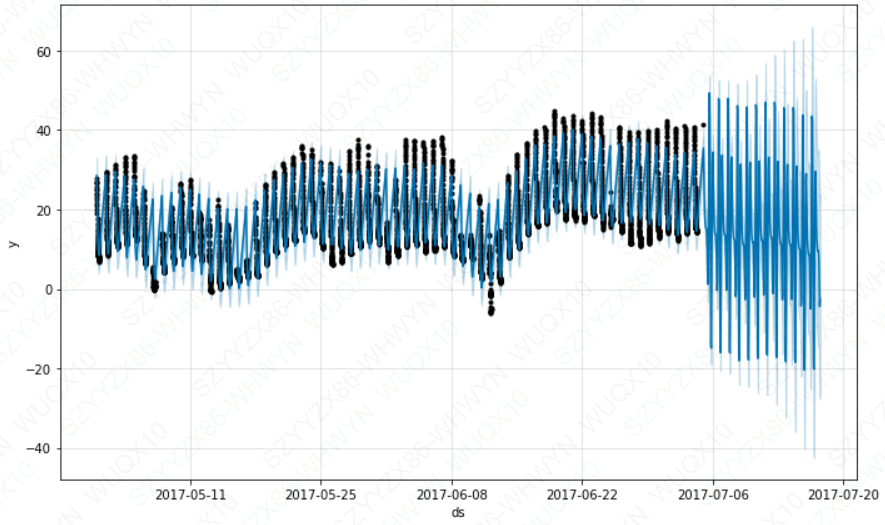
这个预测看起来很差,未来的波动比历史上看到的要大得多。这里的问题是,我们将每天的循环安排在一个时间序列中,这个时间序列中只有一天的一部分数据(24 - 06)。
因此,每天的季节性在一天剩下的时间里是不受约束的,估计也不准确。解决方案是只对有历史数据的时间窗进行预测。这里,这意味着限制未来dataframe的时间
m = Prophet().fit(df2)
future = m.make_future_dataframe(periods=300, freq='H')future2 = future.copy()
# 修改
future2 = future2[future2['ds'].dt.hour < 6]
fcst = m.predict(future2)
fig = m.plot(fcst)
plt.show()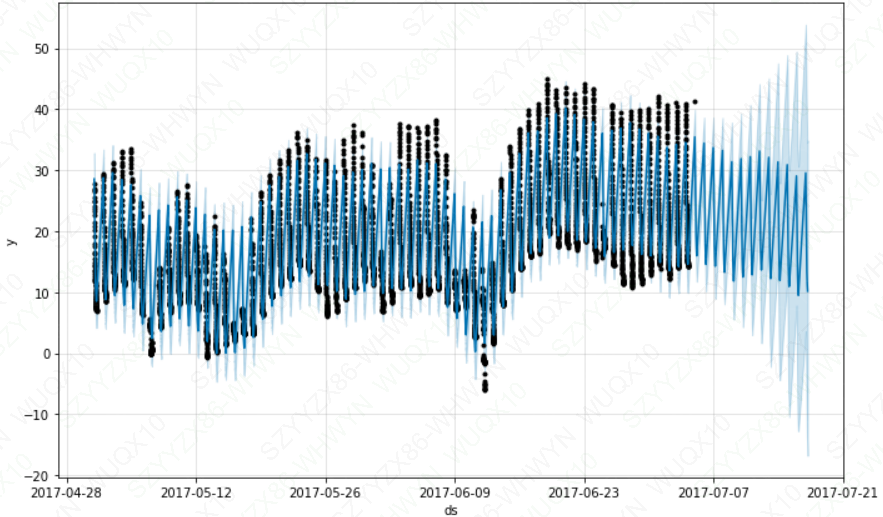
同样的原理也适用于数据中有规则间隔的其他数据集。例如,如果历史只包含工作日,那么应该只对工作日进行预测,因为不能很好地估计每周的季节性。
月数据
df = pd.read_csv(r'C:\Users\Desktop\example_retail_sales.csv')
m = Prophet().fit(df)
future = m.make_future_dataframe(periods=3652)
fcst = m.predict(future)
m.plot(fcst)
plt.show()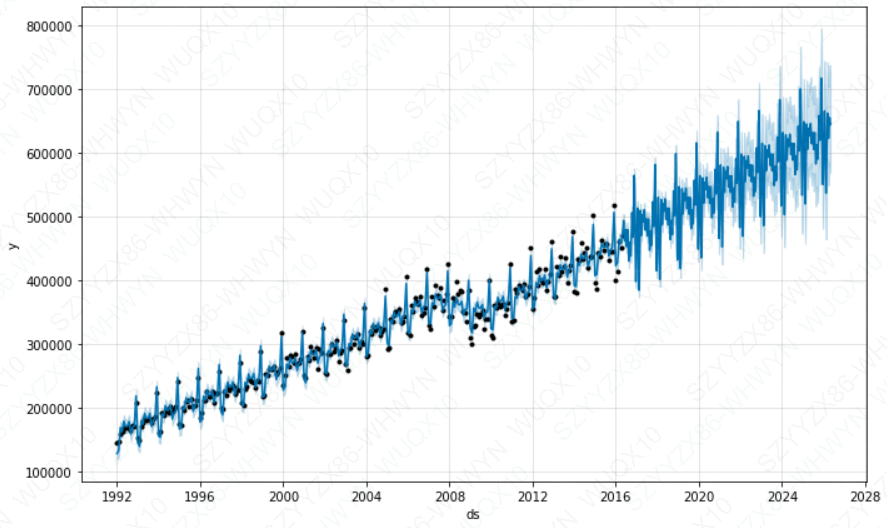
但Prophet预测的时间序列的间额却为日.
fcst[fcst['ds']>='2016-05-01']
future = m.make_future_dataframe(periods=120, freq='M')
fcst = m.predict(future)
m.plot(fcst)
plt.show()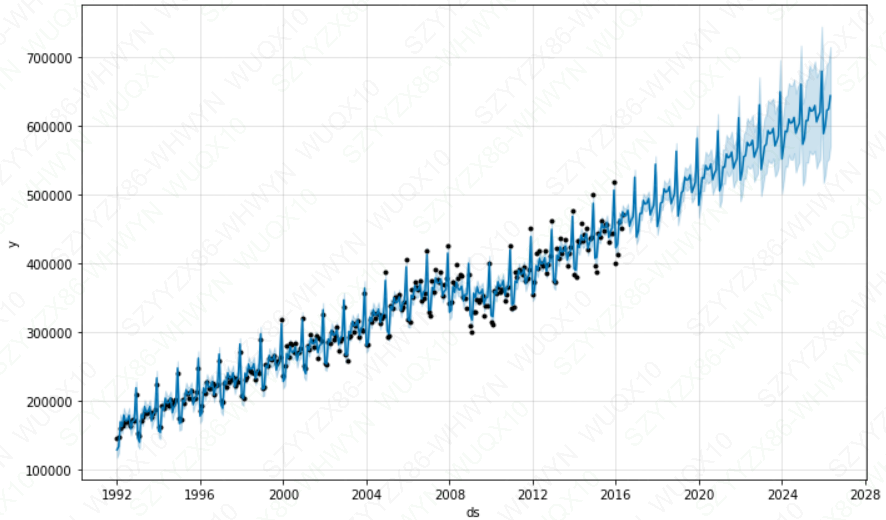
模型评估
df = pd.read_csv(r'C:\Users\Desktop\example_wp_log_peyton_manning.csv')
m = Prophet(changepoint_prior_scale=0.01).fit(df)
future = m.make_future_dataframe(periods=300, freq='H')
fcst = m.predict(future)
fig = m.plot(fcst)
plt.show()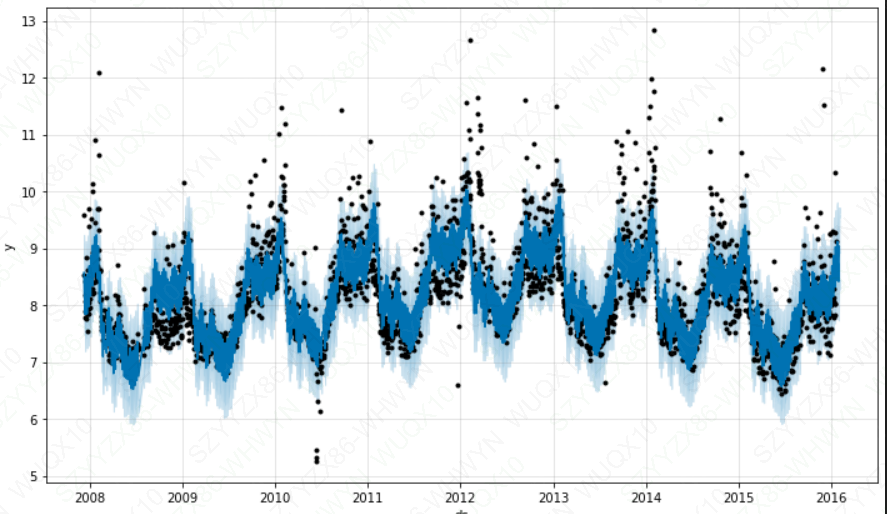
from sklearn.metrics import mean_squared_error
# 预测值
fcst['yhat']
# 保留历史数据
y_p = fcst[fcst['ds'].isin(df['ds'])]
#真实值
mean_squared_error(df['y'],y_p['yhat'])
#输出均方误差:0.2569427525764418