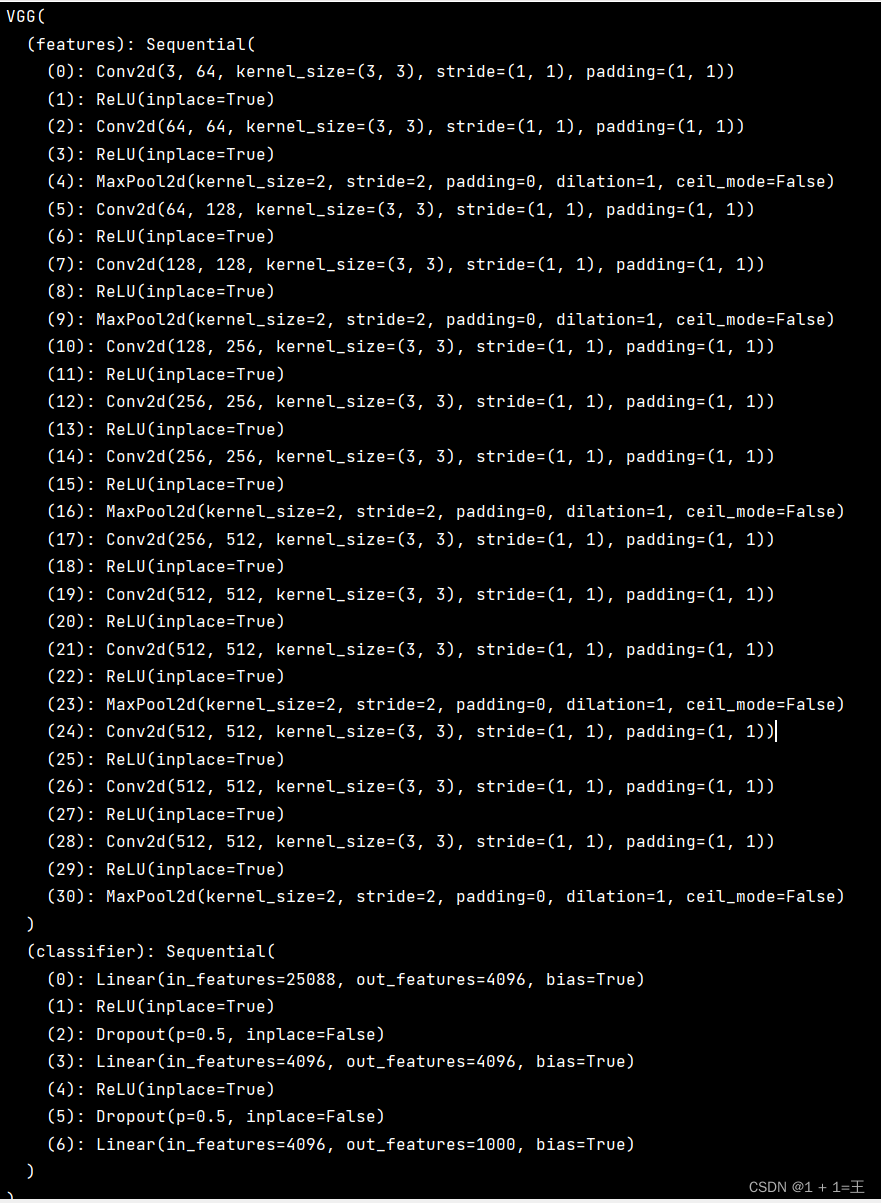
目录
Part I: CNN的基础构件
一张图片如何作为输入?
什么是卷积
什么是Padding
什么是池化(pooling)
什么是Flatten
什么是全连接层
什么是Dropout
什么是激活函数
VGG16的整体架构图
Part II: VGG 网络架构
典型VGG网络结构
VGG 网络参数数量计算:
Part III: 如何训练VGG
前馈
后馈
训练技巧
VGG 基于Tensorflow版本代码可参考前两篇博客:
1. VGG16系列I: 基于Tensorflow代码
2. VGG16系列II: 代码解析
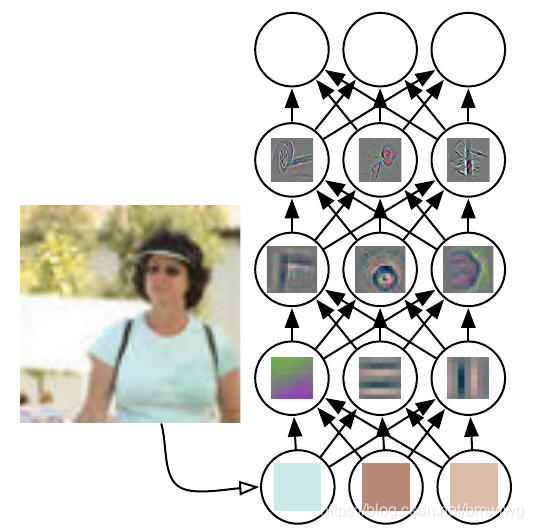
神经网络各层次的特征提取与传播类似于下图
Part I: CNN的基础构件
一张图片如何作为输入?
如下图,彩色图像有RGB三个色值通道,分别表示红、绿、蓝,每个通道内的像素可以用一个像下图右边的二维数组表示,数值代表0-255之间的像素值。假设一张900*600的彩色的图片,计算机里面可以用 (900*600*3)的数组表示。
对于其中一个色值通道的数据输入, 如下图
什么是卷积
卷积过程是基于一个小矩阵,也就是卷积核,在上面所说的每层像素矩阵上不断按步长扫过去的,扫到数与卷积核对应位置的数相乘,然后求总和,每扫一次,得到一个值,全部扫完则生成一个新的矩阵。如下图
卷积核如何设置可以参考卷积神经网络的卷积核大小、个数,卷积层数如何确定呢?一般取(3,3)的小矩阵,卷积核里面每个值就是我们需要寻找(训练)的神经元参数(权重),开始会随机有个初始值,当训练网络时,网络会通过后向传播不断更新这些参数值,直到寻找到最佳的参数值。如何知道是“最佳”?是通过损失函数去评估。
卷积核的步长是指卷积核每次移动几个格子,有横行和纵向两个方向。
卷积操作相当于特征提取,卷积核相当于一个过滤器,提取我们需要的特征。
如下图,左边小红色框是卷积核,从左上角扫到右下角,最终得到右边的特征图谱。
卷积:如何成为一个很厉害的神经网络
什么是Padding
卷积操作之后维度变少,得到的矩阵比原来矩阵小,这样不好计算,而我们只是希望作卷积,所以我们需要Padding,在每次卷积操作之前,在原矩阵外边补包一层0,可以只在横向补,或只在纵向补,或者四周都补0,从而使得卷积后输出的图像跟输入图像在尺寸上一致。
比如:我们需要做一个300*300的原始矩阵的卷积,用一个3*3卷积核来扫,扫出来结果的矩阵应该是:298*298的矩阵,变小了。
卷积前加 Padding 操作补一圈0,即300*300矩阵外面周围加一圈“0”,这样的300*300就变成了302*302的矩阵,再进行卷积出来就是300*300 ,尺寸和原图一样。
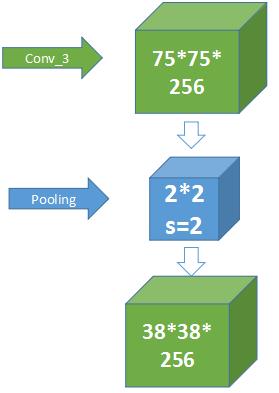
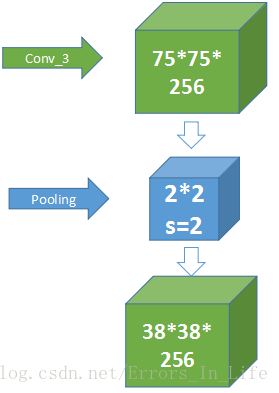
什么是池化(pooling)
卷积操作后我们提取了很多特征信息,相邻区域有相似特征信息,可以相互替代的,如果全部保留这些特征信息就会有信息冗余,增加了计算难度,这时候池化就相当于降维操作。池化是在一个小矩阵区域内,取该区域的最大值或平均值来代替该区域,该小矩阵的大小可以在搭建网络的时候自己设置。小矩阵也是从左上角扫到右下角。如下图
什么是Flatten
Flatten 是指将多维的矩阵拉开,变成一维向量来表示。
什么是全连接层
对n-1层和n层而言,n-1层的任意一个节点,都和第n层所有节点有连接。即第n层的每个节点在进行计算的时候,激活函数的输入是n-1层所有节点的加权。像下面的中间层就是全连接方式。
什么是Dropout
dropout是指在网络的训练过程中,按照一定的概率将网络中的神经元丢弃,这样有效防止过拟合。
什么是激活函数
CNNs are obtained by composing several different functions. In addition to the linear filters shown in the previous part, there are several non-linear operators as well.
The simplest non-linearity is obtained by following a linear filter by a non-linear activation function, applied identically to each component (i.e. point-wise) of a feature map. The simplest such function is the Rectified Linear Unit (ReLU)
VGG采用的激活函数是ReLu. ReLu是非常接近线性函数的非线性函数.
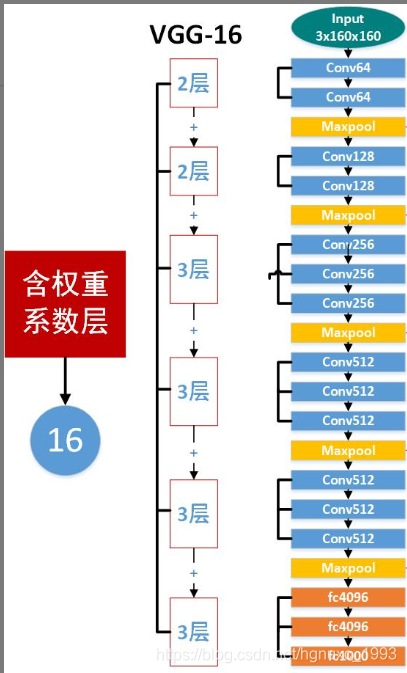
VGG16的整体架构图
从左至右,一张彩色图片输入到网络,白色框是卷积层,红色是池化,蓝色是全连接层,棕色框是预测层。预测层的作用是将全连接层输出的信息转化为相应的类别概率,而起到分类作用。
可以看到 VGG16 是13个(2+2+3+3+3)卷积层+3个全连接层叠加而成。
Part II: VGG 网络架构
典型VGG网络结构
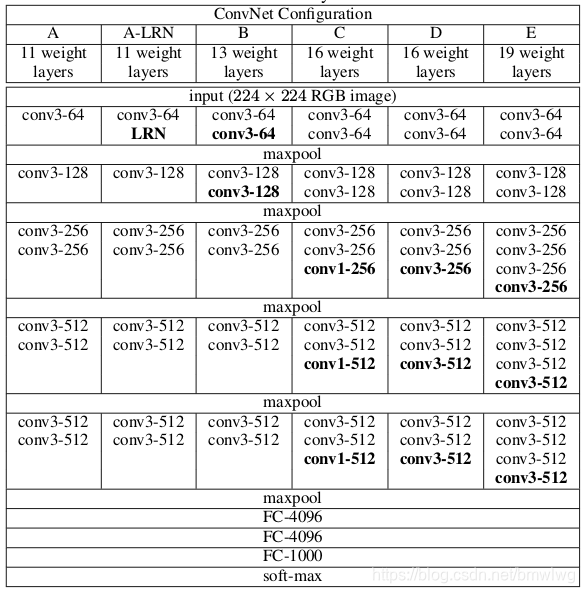
VGG 网络参数数量计算:
神经网络参数计算参考下一篇帖子

Part III: 如何训练VGG

类似于其他的神经网络, VGG也采用类似于反向传播的方式对网络的权重进行训练.
前馈
卷积神经网络一般采用的是梯度下降的方法来优化. 如果把整个神经网络当作函数 , 其中每一层表示为
, 每层的权重表示为
, 那么整个网络可以抽象成如下链式:
Training CNNs is normally done using a gradient-based optimization method. The CNN is the composition of
layers
each with parameters
, which in the simplest case of a chain looks like:
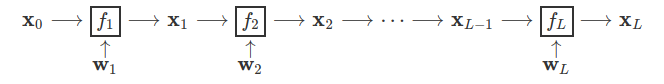
During learning, the last layer of the network is the loss function that should be minimized. Hence, the output of the network is a scalar quantity (a single number).
后馈
The gradient is easily computed using using the chain rule. If all network variables and parameters are scalar, this is given by:
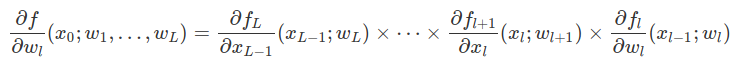
Back-propagation allows computing the output derivatives in a memory-efficient manner. To see how, the first step is to generalize the equation above to tensors using a matrix notation. This is done by converting tensors into vectors by using the vecvec (stacking) operator:
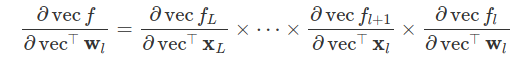
训练技巧
(参考Reference[2])
1. 求解器
• multinomial logistic regression
• mini-batch gradient descent with momentum
• dropout and weight decay regularisation
• fast convergence (74 training epochs)
2. 初始化
• large number of ReLU layers – prone to stalling
• most shallow net (11 layers) uses Gaussian initialisation
• top 4 conv. and FC layers initialised with 11 layer net
• other layers – random Gaussian
3. 图片增强
Multi-scale training
• randomly-cropped ConvNet input
• fixed-size 224x224
• different training image size • 256xN • 384xN • [256;512]xN – random image size (scale jittering)
Standard jittering
• random horizontal flips
• random RGB shift
References:
[1]. Very Deep Convolutional Networks for Large-Scale Image Recognition
[2]. VGG Convolutional Neural Networks Practical
[3]. 卷积神经网络VGG16这么简单,为什么没人能说清
[4]. Keras VGG



![[VGG16]——网络结构介绍及搭建(PyTorch)](https://img-blog.csdnimg.cn/6b465e7131a343c2b96bf46da7e39b82.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAU3RhcuaYn-Wxueeoi-W6j-iuvuiuoQ==,size_20,color_FFFFFF,t_70,g_se,x_16)