一、VGG16的结构层次
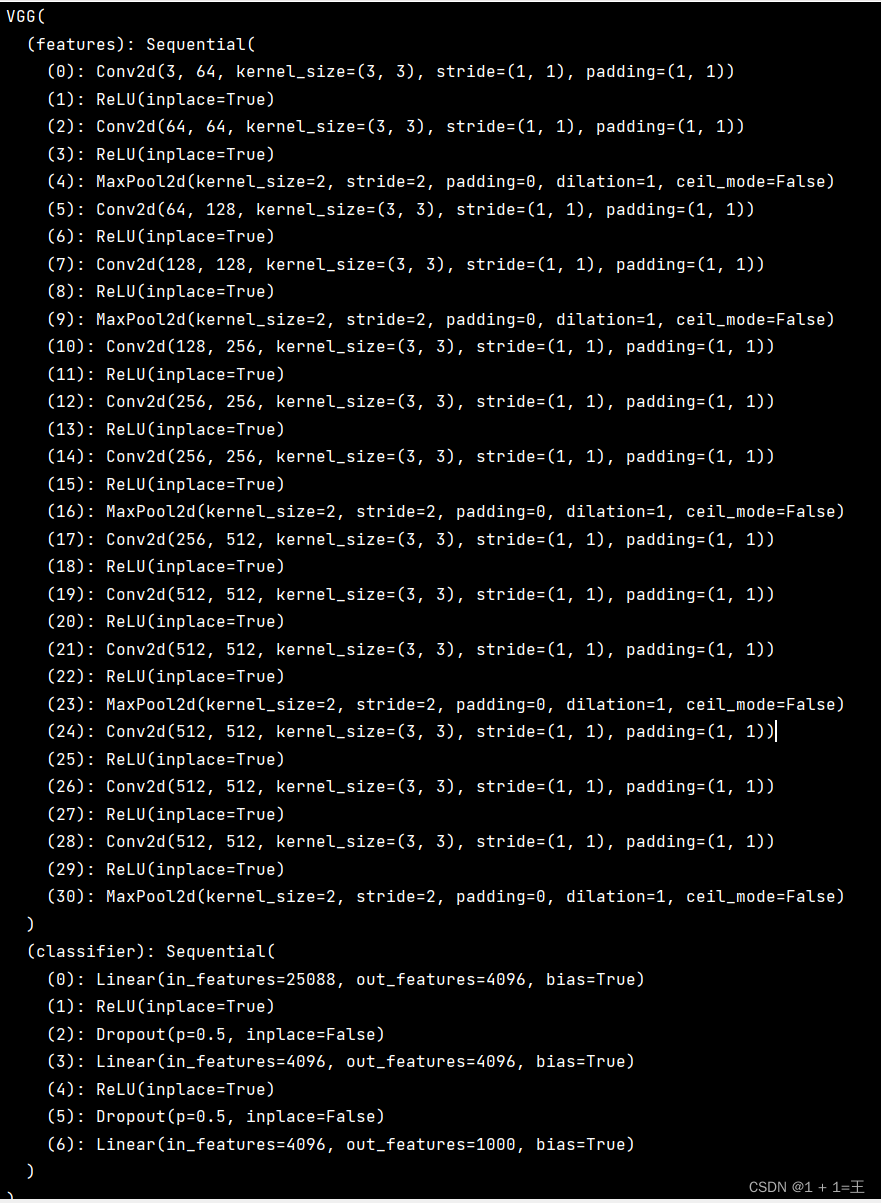
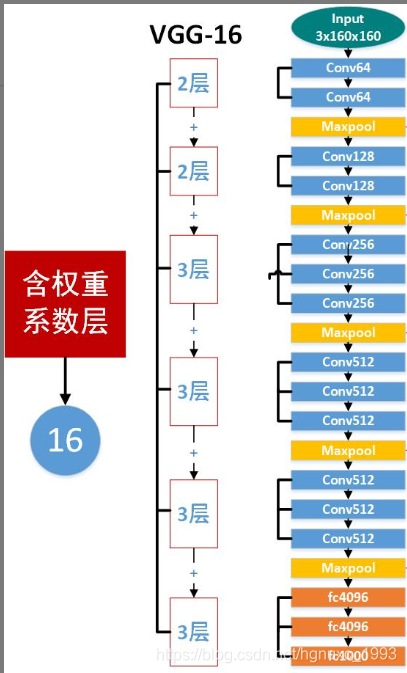
VGG16总共有16层,13个卷积层和3个全连接层,第一次经过64个卷积核的两次卷积后,采用一次pooling,第二次经过两次128个卷积核卷积后,采用pooling;再经过3次256个卷积核卷积后。采用pooling,再重复两次三个512个卷积核卷积后,再pooling,最后经过三次全连接。
1、附上官方的vgg16网络结构图:
- conv3-64的全称就是convolution kernel_size=3, the number of kernel=64,也就是说,这一层是卷积层,卷积核尺寸是3x3xn(n代表channels,是输入该层图像数据的通道数),该卷积层有64个卷积核实施卷积操作。
- FC4096全称是Fully Connected 4096,是输出层连接4096个神经元的全连接层。
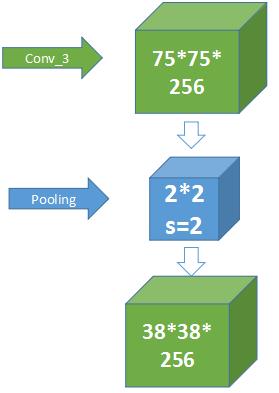
- maxpool就是最大池化操作。最大值池化的窗口尺寸是2×2,步长stride=2

2、 VGG模型所需的内存容量:

二、模型搭建
VGG16实现,基于CIFAR-10数据集
CIFAR-10:该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图,50000 training images and 10000 test images.- CIFAR-10:CIFAR-10 and CIFAR-100 datasets (toronto.edu)
1、数据加载

#加载数据
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
#训练集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True)
#测试集
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')2、VGG16网络实现
class Vgg16_net(nn.Module):def __init__(self):super(Vgg16_net, self).__init__()self.layer1=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), #(32-3+2)/1+1=32 32*32*64nn.BatchNorm2d(64),#inplace-选择是否进行覆盖运算#意思是是否将计算得到的值覆盖之前的值,比如nn.ReLU(inplace=True),#意思就是对从上层网络Conv2d中传递下来的tensor直接进行修改,#这样能够节省运算内存,不用多存储其他变量nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1), #(32-3+2)/1+1=32 32*32*64#Batch Normalization强行将数据拉回到均值为0,方差为1的正太分布上,# 一方面使得数据分布一致,另一方面避免梯度消失。nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2,stride=2) #(32-2)/2+1=16 16*16*64)self.layer2=nn.Sequential(nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1), #(16-3+2)/1+1=16 16*16*128nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128,out_channels=128,kernel_size=3,stride=1,padding=1), #(16-3+2)/1+1=16 16*16*128nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(2,2) #(16-2)/2+1=8 8*8*128)self.layer3=nn.Sequential(nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1), #(8-3+2)/1+1=8 8*8*256nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1), #(8-3+2)/1+1=8 8*8*256nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1), #(8-3+2)/1+1=8 8*8*256nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.MaxPool2d(2,2) #(8-2)/2+1=4 4*4*256)self.layer4=nn.Sequential(nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), #(4-3+2)/1+1=4 4*4*512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(4-3+2)/1+1=4 4*4*512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(4-3+2)/1+1=4 4*4*512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2,2) #(4-2)/2+1=2 2*2*512)self.layer5=nn.Sequential(nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(2-3+2)/1+1=2 2*2*512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(2-3+2)/1+1=2 2*2*512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(2-3+2)/1+1=2 2*2*512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2,2) #(2-2)/2+1=1 1*1*512)self.conv=nn.Sequential(self.layer1,self.layer2,self.layer3,self.layer4,self.layer5)self.fc=nn.Sequential(#y=xA^T+b x是输入,A是权值,b是偏执,y是输出#nn.Liner(in_features,out_features,bias)#in_features:输入x的列数 输入数据:[batchsize,in_features]#out_freatures:线性变换后输出的y的列数,输出数据的大小是:[batchsize,out_features]#bias: bool 默认为True#线性变换不改变输入矩阵x的行数,仅改变列数nn.Linear(512,512),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(512,256),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(256,10))def forward(self,x):x=self.conv(x)#这里-1表示一个不确定的数,就是你如果不确定你想要reshape成几行,但是你很肯定要reshape成512列# 那不确定的地方就可以写成-1#如果出现x.size(0)表示的是batchsize的值# x=x.view(x.size(0),-1)x = x.view(-1, 512)x=self.fc(x)return x3、模型训练
mini-batch设置为100,每加载50个mini-batch,统计一次数据(5000张图)
'''
模型训练
'''
def net_train():epoch = 10 # 训练次数learning_rate = 1e-4 # 学习率net = Vgg16_net()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=learning_rate)print('start Training.......')print("print msg : 50 mini-batches per time")for epoch in range(epoch): # 迭代running_loss = 0.0running_acc = 0.0print('*' * 25, 'epoch {}'.format(epoch + 1), '*' * 25, "——> ")for i, data in enumerate(trainloader, 0):inputs, labels = data#print("i: {}, inputs: {}, labels: {}".format(i, len(inputs), len(labels)))# 向前传播out = net(inputs)loss = criterion(out, labels)running_loss += loss.item() * labels.size(0)_, pred = torch.max(out, 1) # 预测最大值所在的位置标签num_correct = (pred == labels).sum()# 初始化梯度optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 打印loss 和 accrunning_acc += num_correct.item()running_loss += loss.item()if i % 50 == 49: # print every 5000 mini-batchesprint('[%d, %5d] loss: %.5f Acc:%.5f' %(epoch + 1, i + 1, running_loss / 5000, running_acc / 5000))running_loss = 0.0running_acc = 0.0print('Finished Training')return net4、模型测试
'''
模型测试
'''
def net_test(model):model.eval() # 模型评估criterion = nn.CrossEntropyLoss()eval_loss = 0eval_acc = 0for data in testloader: # 测试模型img, label = dataout = model(img)loss = criterion(out, label)eval_loss += loss.item() * label.size(0)_, pred = torch.max(out, 1)num_correct = (pred == label).sum()eval_acc += num_correct.item()print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(testset)), eval_acc / (len(testset))))