在需要过去一些网页上的信息的时候,使用 Python 写爬虫来爬取十分方便。
1. 使用 urllib.request 获取网页
urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 HTML 解析库, 可以编写出用于采集网络数据的大型爬虫;
注: 示例代码使用Python3编写; urllib 是 Python2 中 urllib 和 urllib2 两个库合并而来, Python2 中的 urllib2 对应 Python3中的 urllib.request
简单的示例:
import urllib.request # 引入urllib.requestresponse = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝, 这时就需要将爬虫伪装成人类用户的浏览器, 这通常通过伪造请求头信息实现, 如:
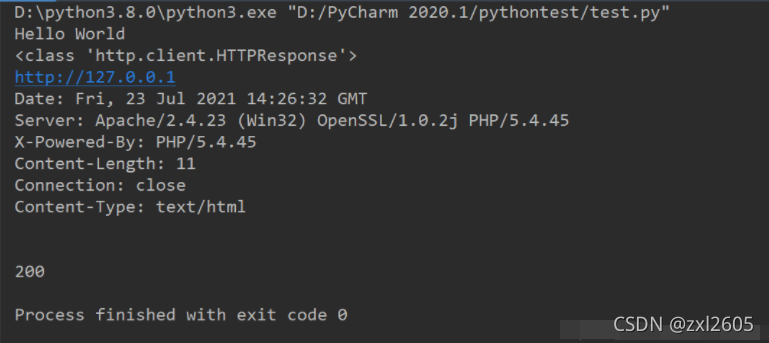
import urllib.request#定义保存函数def saveFile(data):path = "E:\\projects\\Spider\\02_douban.out"f = open(path,'wb')f.write(data)f.close()#网址url = "https://www.douban.com/"headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/51.0.2704.63 Safari/537.36'}req = urllib.request.Request(url=url,headers=headers)res = urllib.request.urlopen(req)data = res.read()#也可以把爬取的内容保存到文件中saveFile(data)data = data.decode('utf-8')#打印抓取的内容print(data)#打印爬取网页的各类信息print(type(res))print(res.geturl())print(res.info())print(res.getcode())
结果:
 伪造请求头可以用谷歌的插件Chrome UA Spoofer
伪造请求头可以用谷歌的插件Chrome UA Spoofer

右键点击选项便有许多人类用户的浏览器可以伪造,直接复制就行
3. 伪造请求主体
在爬取某一些网站时, 需要向服务器 POST 数据, 这时就需要伪造请求主体;
为了实现有道词典在线翻译脚本, 在 Chrome 中打开开发工具, 在 Network 下找到方法为 POST 的请求, 观察数据可以发现请求主体中的 ‘ i ‘ 为经过 URL 编码的需要翻译的内容, 因此可以伪造请求主体, 如:
import urllib.request
import urllib.parse
import jsonwhile True:content = input('请输入要翻译的内容:')if content == 'exit!':breakurl='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'# 请求主体data = {}data['type'] = "AUTO"data['i'] = contentdata['doctype'] = "json"data['xmlVersion'] = "1.8"data['keyfrom'] = "fanyi.web"data['ue'] = "UTF-8"data['action'] = "FY_BY_CLICKBUTTON"data['typoResult'] = "true"data = urllib.parse.urlencode(data).encode('utf-8')head = {}head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体response = urllib.request.urlopen(req)html = response.read().decode('utf-8')target = json.loads(html)print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
也可以使用 add_header() 方法伪造请求头, 如:
import urllib.request
import urllib.parse
import jsonwhile True:content = input('请输入要翻译的内容(exit!):')if content == 'exit!':breakurl = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'# 请求主体data = {}data['type'] = "AUTO"data['i'] = contentdata['doctype'] = "json"data['xmlVersion'] = "1.8"data['keyfrom'] = "fanyi.web"data['ue'] = "UTF-8"data['action'] = "FY_BY_CLICKBUTTON"data['typoResult'] = "true"data = urllib.parse.urlencode(data).encode('utf-8')req = urllib.request.Request(url,data)req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')response = urllib.request.urlopen(req)html=response.read().decode('utf-8')target = json.loads(html)print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫采集过于频繁导致的IP被封的问题, 可以使用代理IP, 如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})# 定制一个opener
opener = urllib.request.build_opener(proxy_support)# 安装opener
urllib.request.install_opener(opener)#调用opener
opener.open(url)
注: 使用爬虫过于频繁的访问目标站点会占用服务器大量资源, 大规模分布式爬虫集中爬取某一站点甚至相当于对该站点发起DDOS攻击; 因此, 使用爬虫爬取数据时应该合理安排爬取频率和时间; 如: 在服务器相对空闲的时间 ( 如: 凌晨 ) 进行爬取, 完成一次爬取任务后暂停一段时间等;
5. 检测网页的编码方式
尽管大多数网页都是用 UTF-8 编码, 但有时候会遇到使用其他编码方式的网页, 因此必须知道网页的编码方式才能正确的对爬取的页面进行解码;
chardet 是 python 的一个第三方模块, 使用 chardet 可以自动检测网页的编码方式;
安装 chardet : pip install charest
使用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获得跳转链接
有时网页一个页面需要在原始 URL 的基础上进行一次甚至多次跳转才能最终到达目的页面, 因此需要正确的处理跳转;
通过 requests 模块的 head() 函数获得跳转链接的 URL , 如
url='https://unsplash.com/photos/B1amIgaNkwA/download/'
res = requests.head(url)
re=res.headers['Location']