都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm
库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的
requests:获取网页源代码
lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml
新建一个项目:

光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧

依赖库导入
我们不是说要使用requests吗,来吧
由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图:
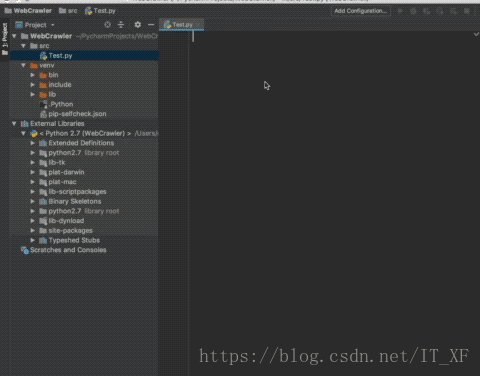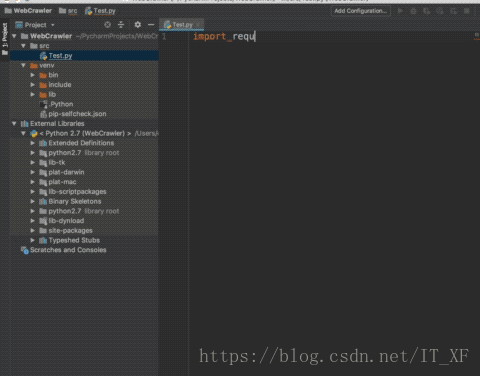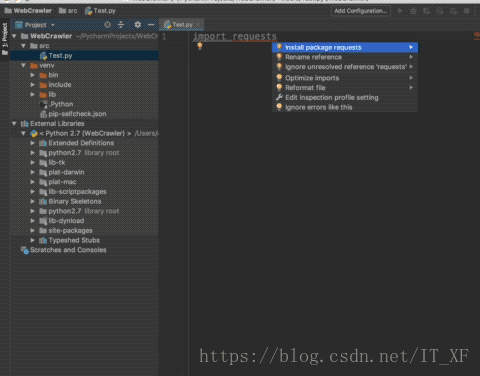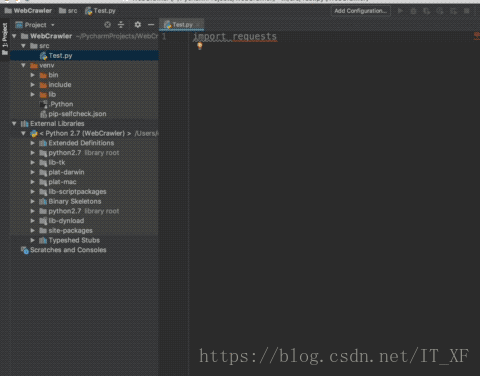
在Test.py中输入:
import requests这个时候,requests会报红线,这时候,我们将光标对准requests,按快捷键:alt + enter,pycharm会给出解决之道,这时候,选择install package requests,pycharm就会自动为我们安装了,我们只需要稍等片刻,这个库就安装好了。lxml的安装方式同理.
将这两个库安装完毕后,编译器就不会报红线了

接下来进入快乐的爬虫时间
获取网页源代码
之前我就说过,requests可以很方便的让我们得到网页的源代码
网页就拿我的博客地址举例好了:https://blog.csdn.net/it_xf?viewmode=contents
获取源码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# 打印源码
print html.text代码就是这么简单,这个html.text便是这个URL的源码
获取指定数据
现在我们已经得到网页源码了,这时就需要用到lxml来来筛选出我们所需要的信息
这里我就以得到我博客列表为例
首先我们需要分析一下源码,我这里使用的是chrome浏览器,所以右键检查,便是这样一份画面:
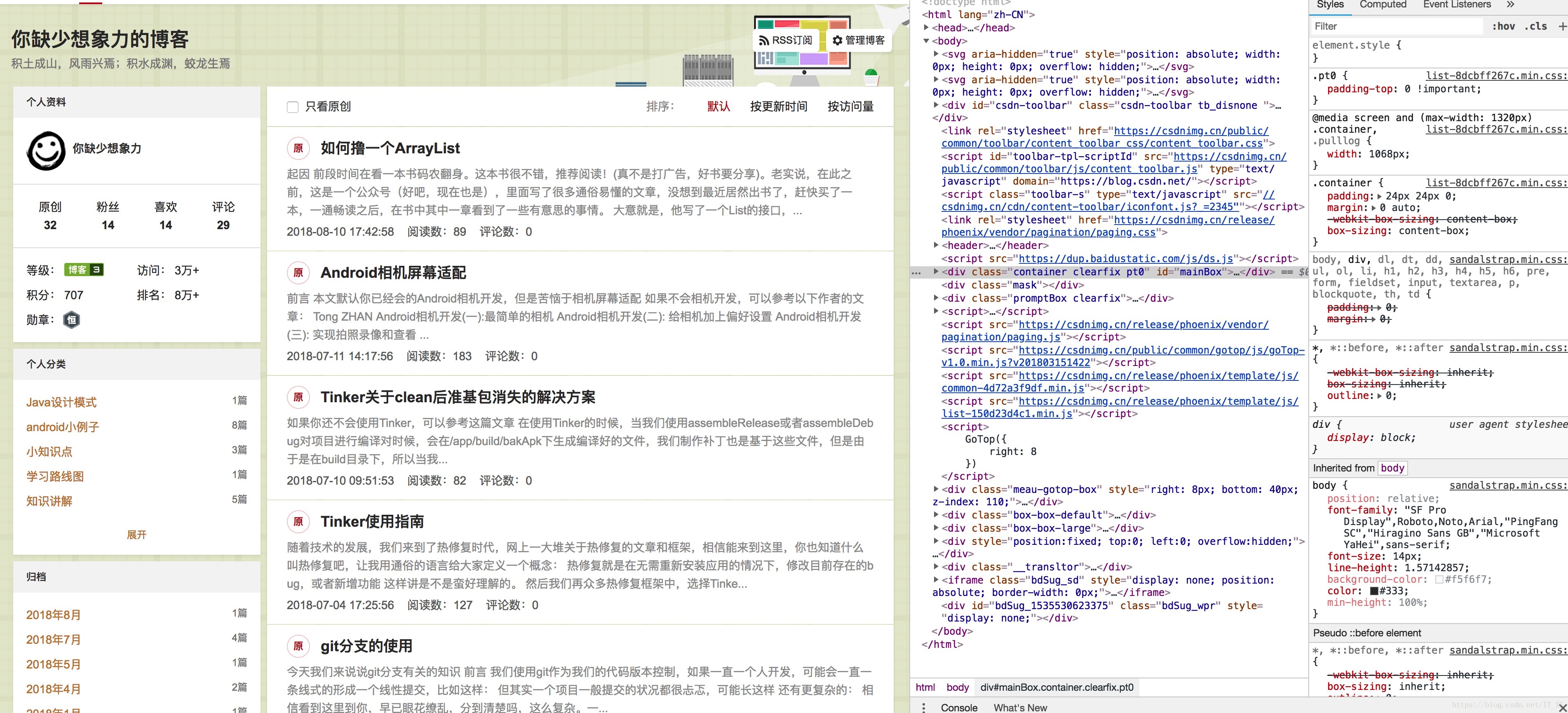
然后在源代码中,定位找到第一篇
像这样?
操作太快看不清是不是?
我这里解释一下,首先点击源码页右上角的箭头,然后在网页内容中选中文章标题,这个时候,源码会定位到标题这里,
这时候选中源码的标题元素,右键复制如图:

得到xpath,嘿嘿,知道这是什么吗,这个东西相当于地址。比如网页某长图片在源码中的位置,我们不是复制了吗,粘贴出来看看长啥样
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a这里给你解释解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
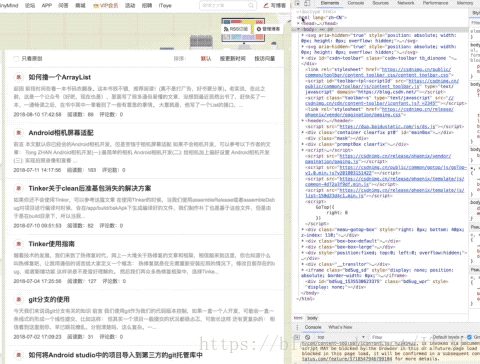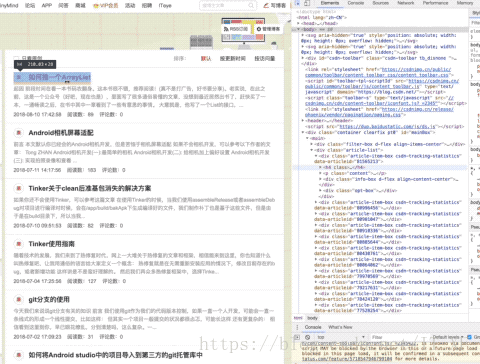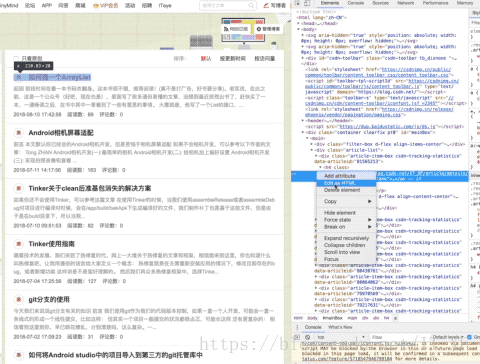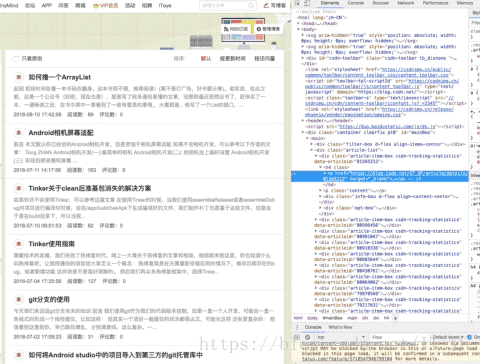
提取属性内容:/@xxxx后面两个我们还没有在这个表达式见过,待会说,先摆张图放出来

表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
我们来琢磨琢磨,首先,//表示根节点,也就是说啊,这//后面的东西为根,则说明只有一个啊
也就是说,我们需要的东西,在这里面
然后/表示往下层寻找,根据图片,也显而易见,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a这里,我想,你们应该也就看得懂了,然后我们在后面加个/text,表示要把元素的内容提取出来,所以我们最终的表达式长这样:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()这个表达式只针对这个网页的这个元素,不难理解吧?
那么这个东西怎么用呢?
所有代码:
import requests
from lxml import etreehtml = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.textetree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:print(each)这时候,each里面的数据就是我们想要得到的数据了
打印结果:
如何撸一个ArrayList 打印结果却是这个结果,我们把换行和空格去掉
import requests
from lxml import etreehtml = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.textetree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')for each in content:replace = each.replace('\n', '').replace(' ', '')if replace == '\n' or replace == '':continueelse:print(replace)
打印结果:
如何撸一个ArrayList 相当nice,那么,如果我们要得到所有的博客列表呢
看图看表达式分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们能够很容易发现,main->div[2]其实包含所有文章,只是我们取了main->div[2]->div[1],也就是说我们只是取了第一个而已。所以,其实表达式写出这样,就可以得到所有的文章了
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()再来一次:
import requests
from lxml import etreehtml = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.textetree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')for each in content:replace = each.replace('\n', '').replace(' ', '')if replace == '\n' or replace == '':continueelse:print(replace)打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南相当nice,我们得到了所有的文章列表。
总结
我们用到了requests获取网页列表,用lxml筛选数据,可以看出python用来在网页上爬取数据确实方便不少,chrome也支持直接在源码中得到表达式xpath,这两个库的内容肯定不止这一点点,还有很多功能等着你们去挖掘。对了,其中在写这篇博客的同时,我发现了一个很重要的问题:我的文章写的太少啦!【逃】