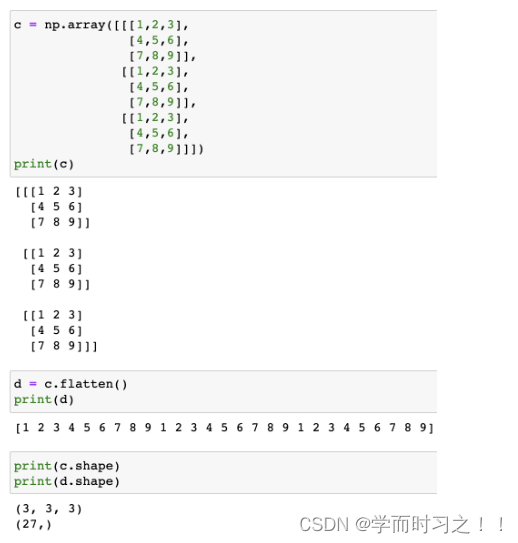
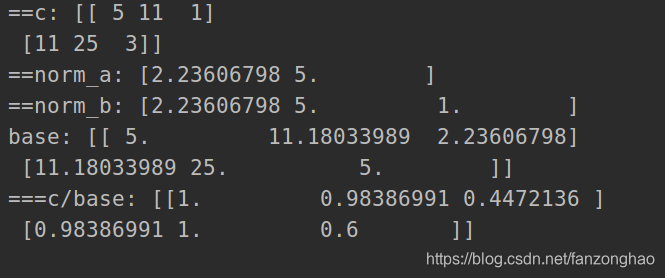
“从稀疏到密集”的范式使SSOD的流程复杂化,同时忽略了强大的直接、密集的教师监督 - 最新半监督检测框架
论文地址:https://arxiv.org/pdf/2207.05536.pdf
Mean-Teacher (MT) 方案在半监督目标检测 (SSOD) 中被广泛采用。在MT中,由教师的最终预测(例如,在非极大抑制 (NMS) 后处理之后)提供的稀疏伪标签通过手工制作的标签分配对学生进行密集监督。然而,“从稀疏到密集”的范式使SSOD的流程复杂化,同时忽略了强大的直接、密集的教师监督。
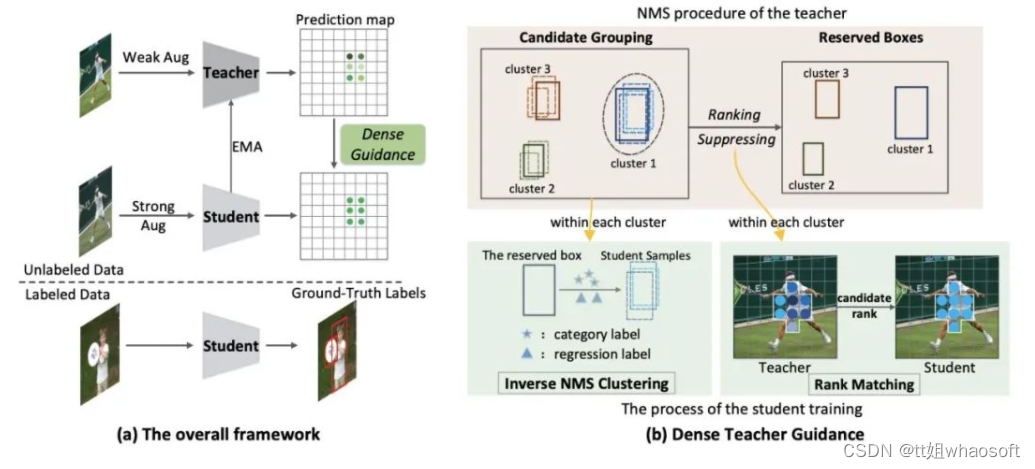
在今天分享中,研究者尝试直接利用教师的密集指导来监督学生的训练,即“密集到密集”范式。具体来说,研究者提出了逆NMS聚类(INC)和秩匹配(RM)来实例化密集监督,而无需广泛使用的传统稀疏伪标签。INC引导学生在NMS中像老师一样将候选框分组到集群中,这是通过学习在老师的NMS程序中显示的分组信息来实现的。在通过INC获得与教师相同的分组方案后,学生通过Rank Matching进一步模仿教师在聚类候选人中的排名分布。
通过提出的INC和RM,将Dense Teacher Guidance集成到半监督目标检测(称为“DTG-SSOD”)中,成功地放弃了稀疏伪标签,并在未标记数据上实现了更多信息学习。在COCO基准测试中,新方法的DTG-SSOD在各种标记比率下实现了最先进的性能。例如,在10%的标注率下,DTG-SSOD将监督基线从26.9提高到35.9mAP,比之前的最佳方法Soft Teacher高19个百分点。
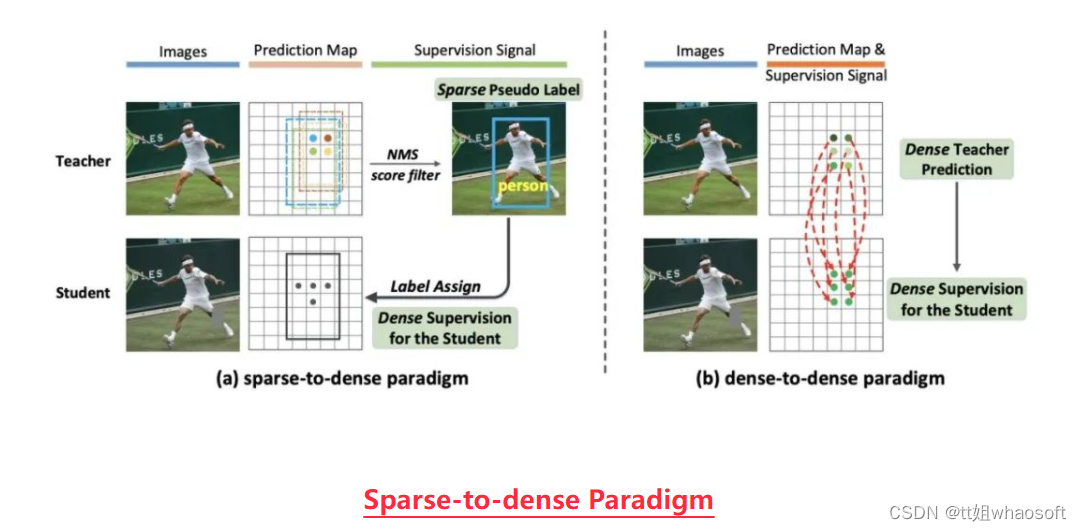
教师监督信号的比较:下图(a)之前的方法对教师进行NMS和分数过滤以获得稀疏的伪标签,通过标签分配进一步转换为对学生的密集监督;下图(b)提出的DTG-SSOD直接采用教师的密集预测作为学生的密集指导。
Task Formulation
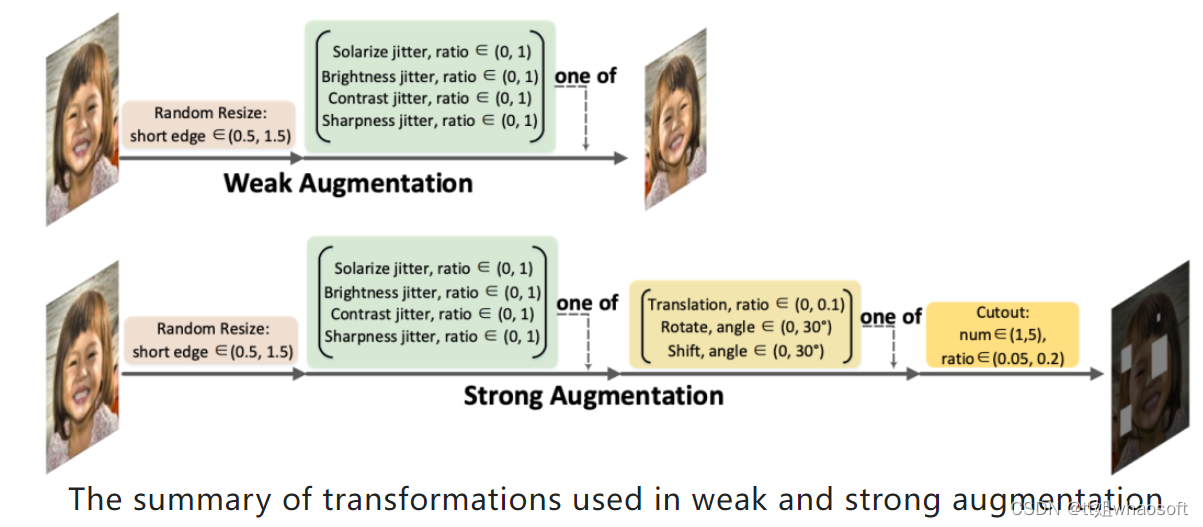
SSOD的框架如下图(a)所示。Mean-Teacher方案是以前技术的常见做法,实现了端到端的训练,每次训练迭代后通过EMA从学生构建教师。教师将弱增强(例如翻转和调整大小)图像作为输入以生成伪标签,而学生则应用强增强(例如剪切、几何变换)进行训练。强大且适当的数据增强起着重要作用,它不仅增加了学生任务的难度并缓解了过度自信的问题,而且还使学生能够对各种输入扰动保持不变,从而实现鲁棒的表征学习。
Sparse-to-dense Baseline
所有以前的SSOD方法都是基于稀疏到密集的机制,其中生成带有类别标签的稀疏伪框,以充当学生训练的基本事实。它带有基于置信度的阈值,其中仅保留具有高置信度(例如,大于0.9)的伪标签。这使得对未标记数据的前景监督比对标记数据的监督要稀疏得多,因此,类不平衡问题在SSOD中被放大,严重阻碍了检测器的训练。
为了缓解这个问题,研究者借鉴了之前工作的一些优势:Soft Teacher将混合比r设置为1/4,以便在每个训练批次中采样更多未标记数据,这使得未标记数据上的前景样本数接近标记数据;Unbiased Teacher用Focal loss代替了交叉熵损失,从而减少了简单示例的梯度贡献。
这两个改进,即适当的混合比r(1/4)和Focal loss,都被用于稀疏到稠密的基线和研究者的稠密到稠密的DTG 方法。因为老师只提供稀疏伪标签,进一步转化为对学生训练的密集监督,这些方法被称为“稀疏到密集”范式。理论上,新提出的SSOD方法独立于检测框架,可以适用于单级和两级检测器。为了与以前的作品进行公平比较,使用Faster RCNN作为默认检测框架。
作为表显示,在完全标记数据设置下,新提出的DTG-SSOD大大超过了以前的方法,超越至少1.2mAP。按照之前的的做法,研究者还对标记数据应用了弱增强,并获得了40.9mAP的强监督基线。即使基于如此强的基线,DTG-SSOD仍然获得了+4.8mAP的最大改进,达到了45.7mAP,这验证了新方法在标记数据量较大时的有效性。
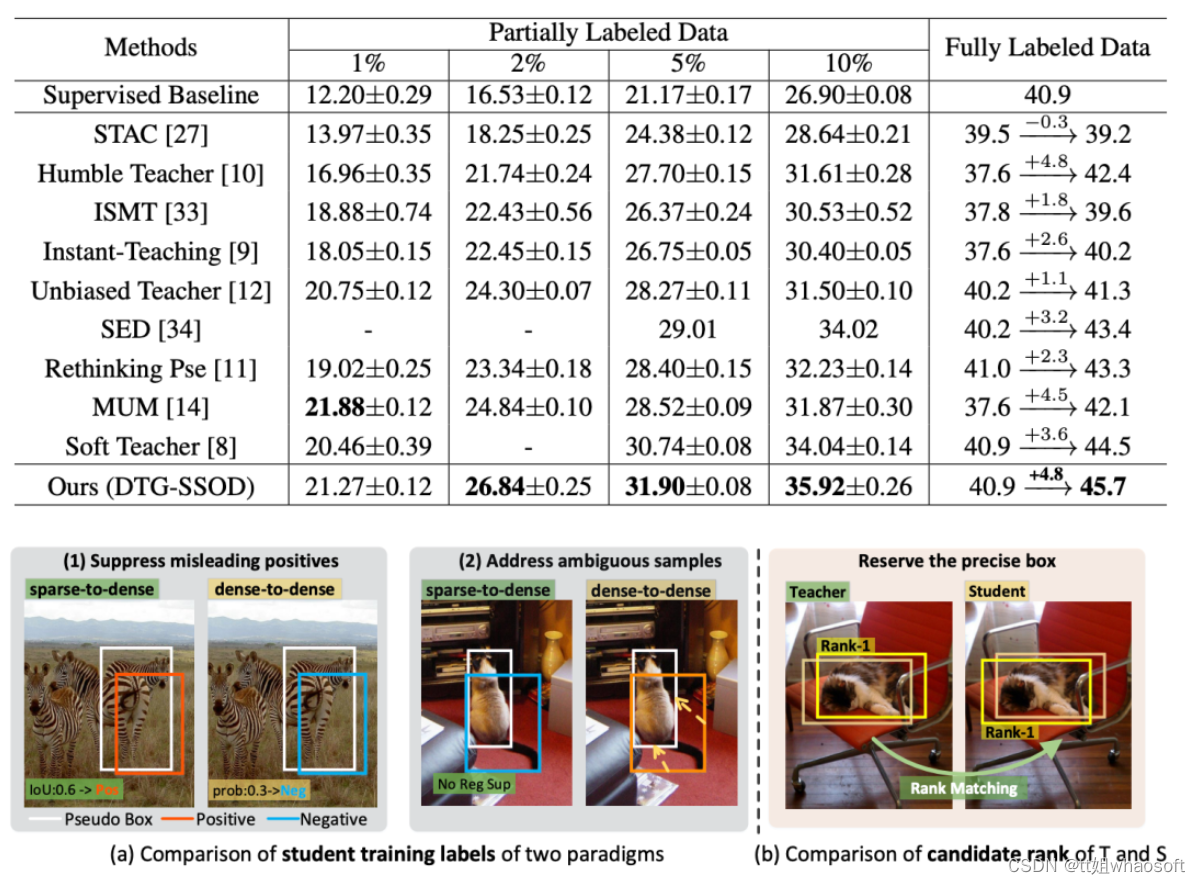 研究者在30k迭代处采用一个检查点进行分析。稀疏伪标签提供的学生训练标签和研究者密集的教师指导进行了精心比较。(a)sparse-to dense范式和研究者的dense-to-dense范式为学生样本带来了不同的训练标签。(b)老师给高质量的候选者分配更高的分数,从而保留精确的框。
研究者在30k迭代处采用一个检查点进行分析。稀疏伪标签提供的学生训练标签和研究者密集的教师指导进行了精心比较。(a)sparse-to dense范式和研究者的dense-to-dense范式为学生样本带来了不同的训练标签。(b)老师给高质量的候选者分配更高的分数,从而保留精确的框。
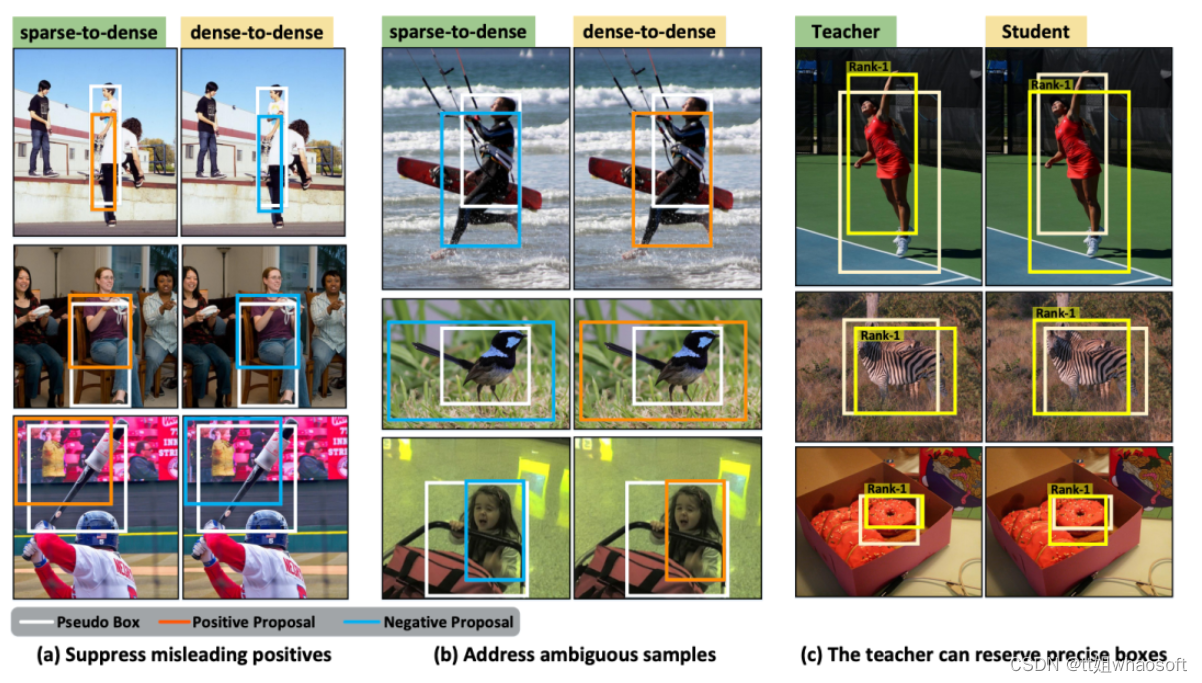
一些可视化的例子来展示新提出的方法相对于传统的稀疏到密集范式的优势。(a-b)对于相同的学生提案,新的密集到密集范式和传统的稀疏到密集范式将分配不同的标签。很明显,新的密集到密集范式可以分配更精确和合理的训练标签。(c)教师比学生更擅长对集群候选者的关系建模。
好啦 完事 whaosoft aiot http://143ai.com