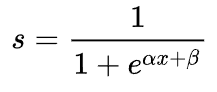文章目录
- 1. 排名分类
- 1.1 区别RANK,DENSE_RANK和ROW_NUMBER
- 1.2 分组排名
- 2. 准备数据
- 3. 不分组排名
- 3.1 连续排名
- 3.2 并列跳跃排名
- 3.3 并列连续排名
- 4. 分组排名
- 4.1 分组连续排名
- 4.2 分组并列跳跃排名
- 4.3 分组并列连续排名
在MYSQL的最新版本MYSQL8已经支持了排名函数
RANK,DENSE_RANK和ROW_NUMBER。但是在就得版本中还不支持这些函数,只能自己实现。实现方法主要用到了条件判断语句(CASE WHEN或IF)和添加临时变量。
个人联系方式:微信
1. 排名分类
1.1 区别RANK,DENSE_RANK和ROW_NUMBER
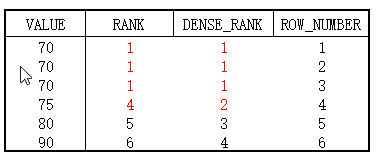
- RANK并列跳跃排名,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,跳跃到总共的排名。
- DENSE_RANK并列连续排序,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,依然按照连续数字排名。
- ROW_NUMBER连续排名,即使相同的值,依旧按照连续数字进行排名。
区别如图:
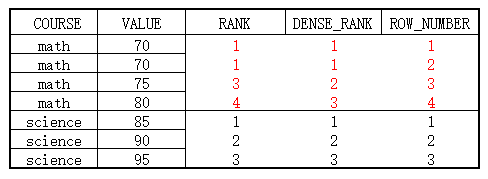
1.2 分组排名
将数据分组后排名,区别如图:
2. 准备数据
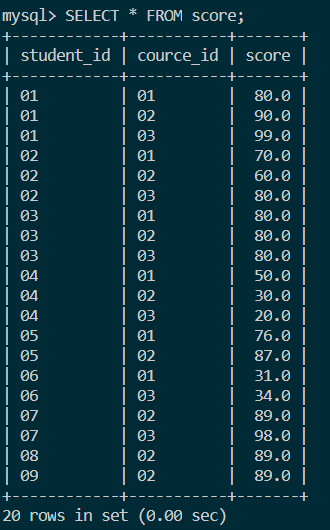
创建一张分数表,里面有字段:分数score,课程号course_id和学生号student_id。
执行如下SQL语句,进行导入数据。
create table score(student_id varchar(10),course_id varchar(10),score decimal(18,1)
);insert into score values('01' , '01' , 80);
insert into score values('01' , '02' , 90);
insert into score values('01' , '03' , 99);
insert into score values('02' , '01' , 70);
insert into score values('02' , '02' , 60);
insert into score values('02' , '03' , 80);
insert into score values('03' , '01' , 80);
insert into score values('03' , '02' , 80);
insert into score values('03' , '03' , 80);
insert into score values('04' , '01' , 50);
insert into score values('04' , '02' , 30);
insert into score values('04' , '03' , 20);
insert into score values('05' , '01' , 76);
insert into score values('05' , '02' , 87);
insert into score values('06' , '01' , 31);
insert into score values('06' , '03' , 34);
insert into score values('07' , '02' , 89);
insert into score values('07' , '03' , 98);
insert into score values('08' , '02' , 89);
insert into score values('09' , '02' , 89);
查看数据:
3. 不分组排名
3.1 连续排名
- 使用
ROW_NUMBER实现:
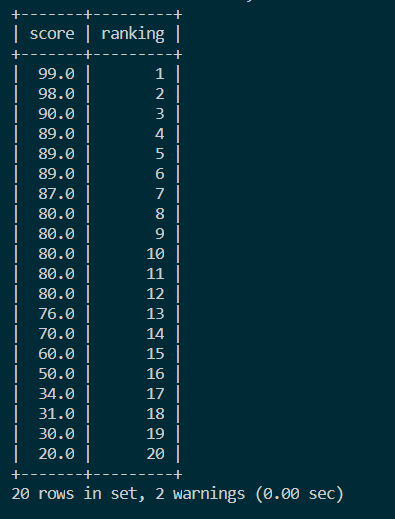
SELECT score,
ROW_NUMBER() OVER (ORDER BY score DESC) ranking
FROM score;
- 使用
变量实现:
SELECT s.score, (@cur_rank := @cur_rank + 1) ranking
FROM score s, (SELECT @cur_rank := 0) r
ORDER BY score DESC;
结果如图:
3.2 并列跳跃排名
- 使用
RANK实现:
SELECT course_id, score,
RANK() OVER(ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:
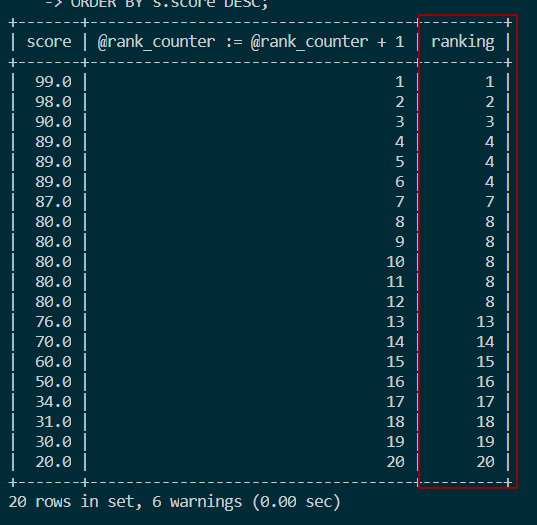
SELECT s.score,
@rank_counter := @rank_counter + 1,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC;
- 使用
变量和CASE语句实现:
SELECT s.score,
@rank_counter := @rank_counter + 1,
(CASEWHEN @pre_score = s.score THEN @cur_rankWHEN @pre_score := s.score THEN @cur_rank := @rank_counterEND
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC;
结果如图:
3.3 并列连续排名
- 使用
DENSE_RANK实现:
SELECT course_id, score,
DENSE_RANK() OVER(ORDER BY score DESC) FROM score;
- 使用
变量和IF语句实现:
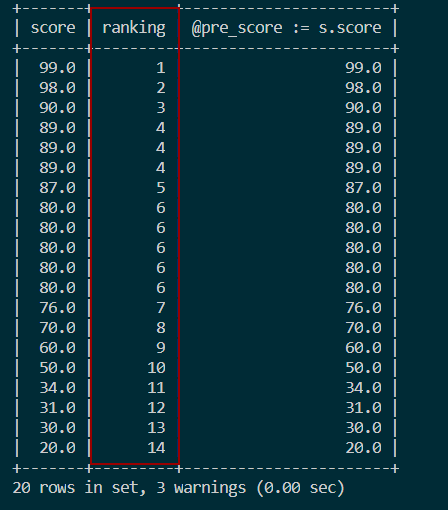
SELECT s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;
- 使用
变量和CASE语句实现:
SELECT s.score,
(CASEWHEN @pre_score = s.score THEN @cur_rankWHEN @pre_score := s.score THEN @cur_rank := @cur_rank + 1END
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;
结果如图:
4. 分组排名
4.1 分组连续排名
- 使用
ROW_NUMBER实现:
SELECT course_id, score,
ROW_NUMBER() OVER (PARTITION BY course_id ORDER BY score DESC) ranking FROM score;
- 使用
变量和IF语句实现:
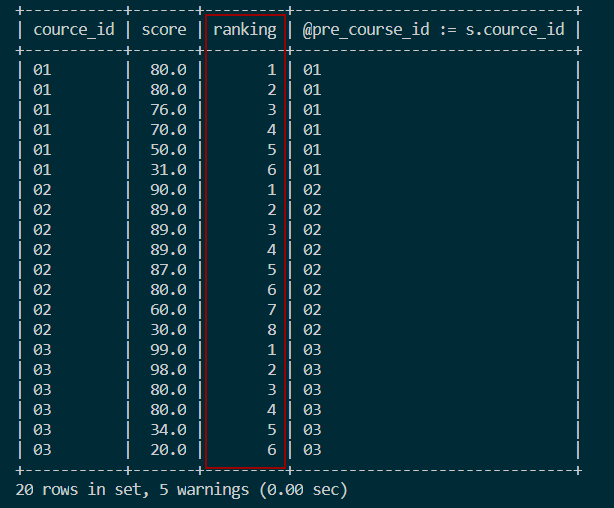
SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id, @cur_rank := @cur_rank + 1, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;
结果如图:
4.2 分组并列跳跃排名
- 使用
RANK实现:
SELECT course_id, score,
RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:
SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,@rank_counter := @rank_counter + 1,@rank_counter := 1) temp1,
IF(@pre_course_id = s.course_id,IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter),@cur_rank := 1) ranking,
@pre_score := s.score temp2,
@pre_course_id := s.course_id temp3
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL, @pre_score := NULL, @rank_counter := 1)r
ORDER BY s.course_id, s.score DESC;
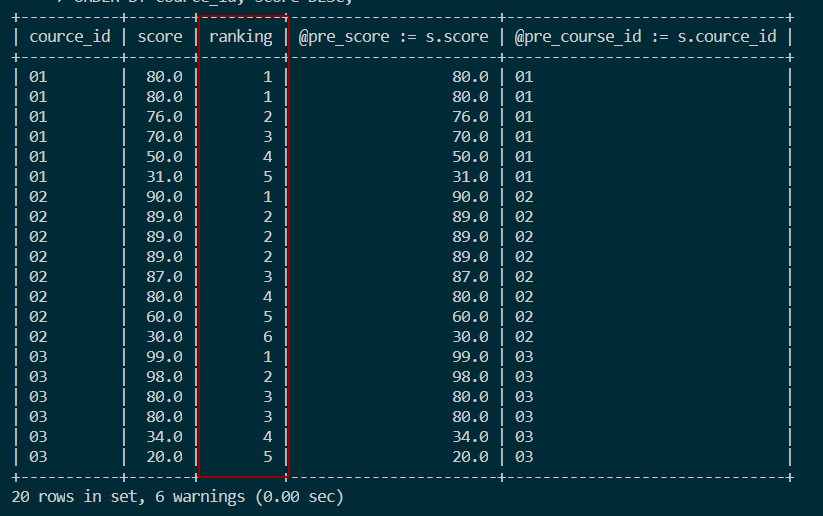
结果如图:
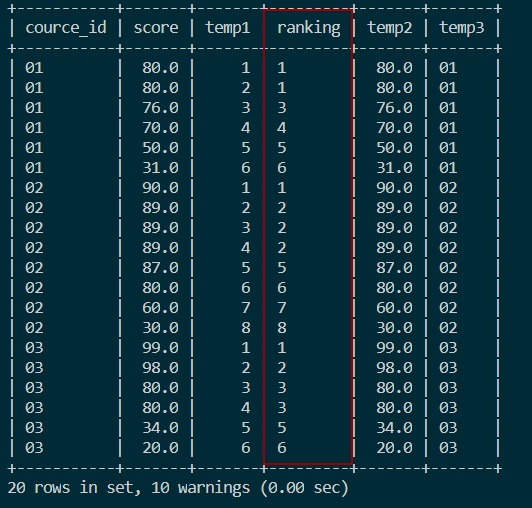
4.3 分组并列连续排名
- 使用
DENSE_RANK实现:
SELECT course_id, score,
DENSE_RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:
SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1),@cur_rank := 1) ranking,
@pre_score := s.score,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;
可以将上述的IF条件提取出来:
SELECT s.course_id, s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) temp1,
@pre_score := s.score temp2,
IF(@pre_course_id = s.course_id, @cur_rank, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;
结果如图: