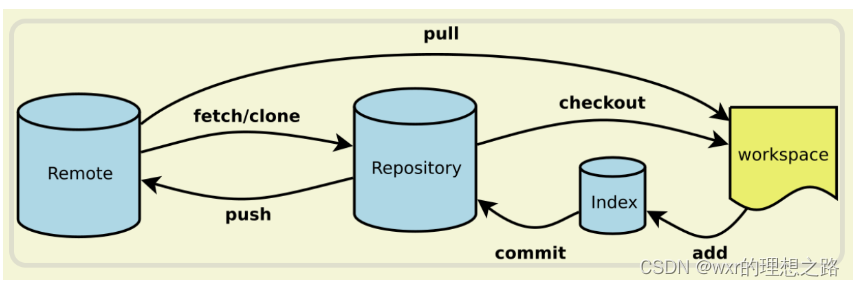
背景
数据库的演进
随着计算机的发展,越来越多的数据需要被处理,数据库是为处理数据而产生。从概念上来说,数据库是指以一定的方式存储到一起,能为多个用户共享,具有更可能小的冗余,与应用程序彼此独立的数据集合。从功能上来说,就是数据管理软件。
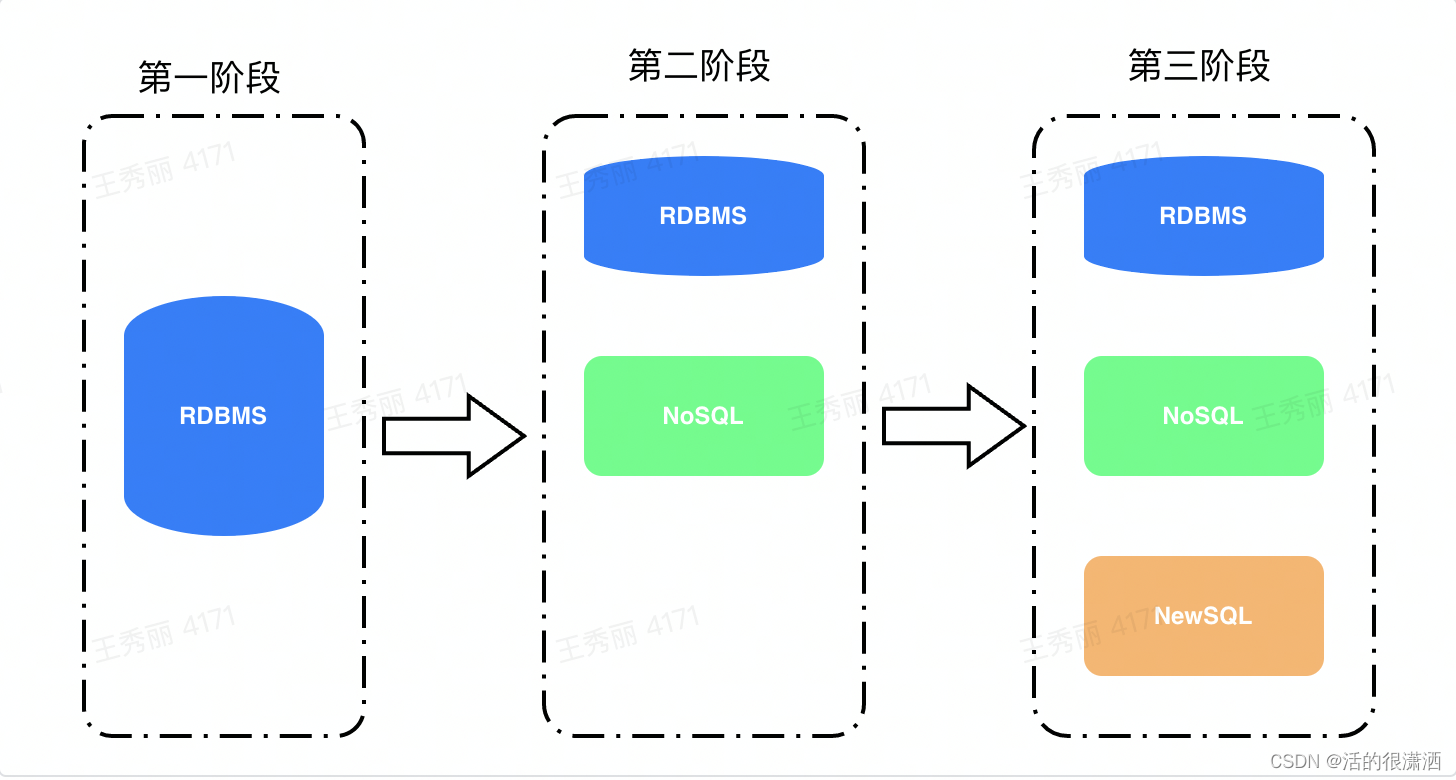
自1960s数据库的概念被提出,到1970s IBM的Edgar Codd第一次提出关系型数据库的概念,再到1980s,传统的关系型数据库已经能满足大部分的日常数据存储的需求,Oracle、IBM等商业化数据库也得到了蓬勃的发展。这个阶段可以认为是关系型数据库的天下,Oracle是公认的老大哥!
到了2000年随着互联网的发展,数据量呈现爆发式增长。海量数据的诞生,传统的关系型数据库在应对大规模,超大流量的时候就显得力不从心。借此,NoSQL数据库,NewSQLl数据库就此登场。
NoSQL 全称 "not only sql",所有非关系型的数据库都统称为NoSQL数据库,NoSQL数据库主要有四种类型,文档数据库(MongoDB为代表),键值数据库(Redis为代表),宽列存储(Hbase为代表)和图形数据库(Neo4J为代表)。NoSQL抛弃了传统数据库强事务保证和关系模型,重点放在高可用,可扩展性和高性能上。不支持SQL。
NewSQL数据库,提供了与NoSQL相同的扩展性,但仍属于关系型模型,还保留SQL作为查询语言,保证了ACID事务性。代表数据库有Spanner,CockroachDB。
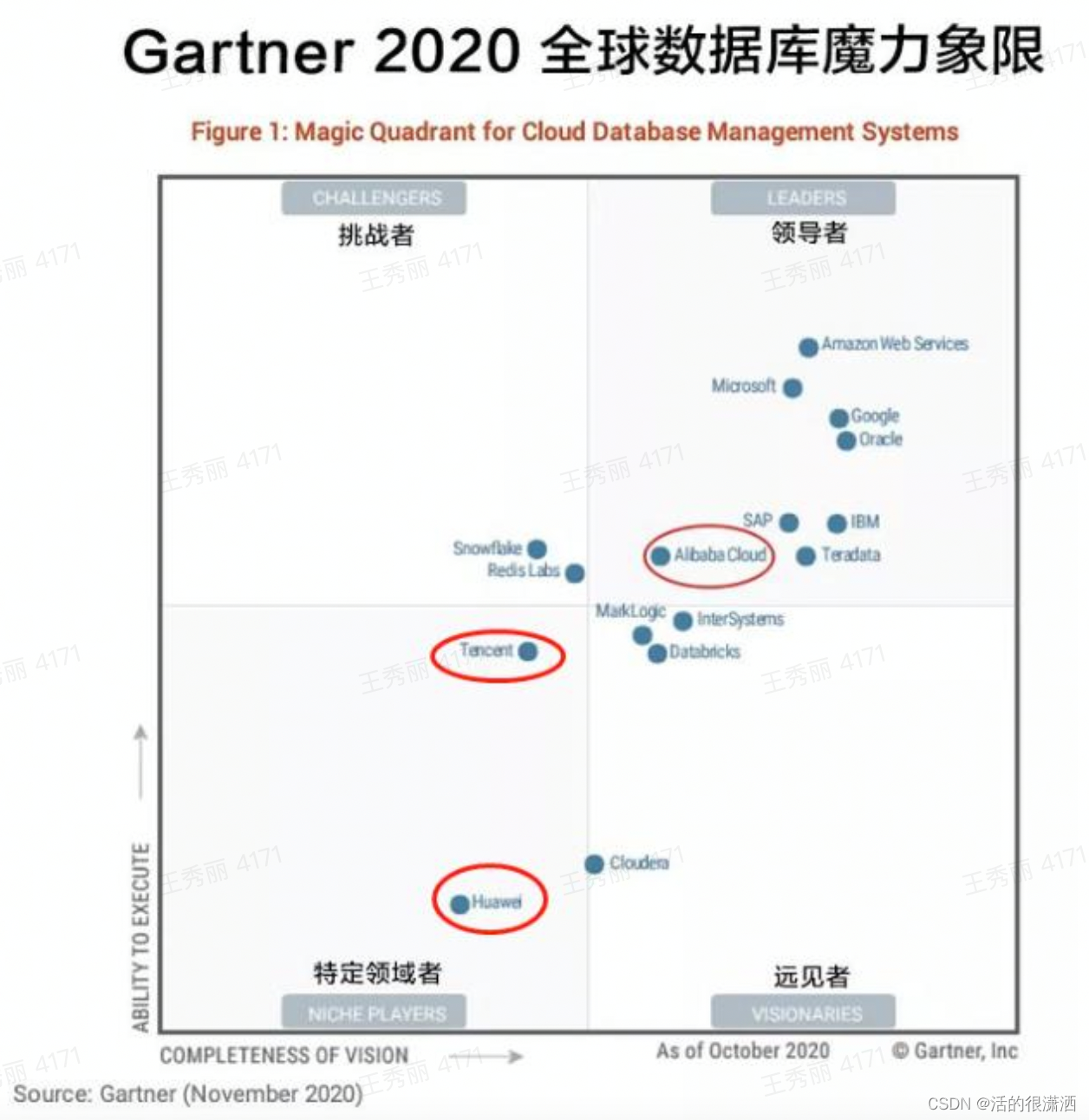
数据库发展到今天,可以说是百花齐放,随着2020年阿里云数据库进入全球魔力四象限的Leader象限,这也是中国数据库40年来首次进入全球顶级数据库行列,标志着国产数据库开始崛起。我也希望自己在中国数据库技术发展上贡献一份自己的力量。
在了解了数据库的发展后,我们再来看看对数据库来说哪些技术原理是不变的?这就要进入下文讲到的数据库索引技术了。
数据库索引技术
数据库是用来处理数据的,那高效的存储、检索数据,是数据库管理系统必备的技能。数据库中用于提高检索效率很重要的一项技术就是索引。讲到索引就不得不提下数据结构,我们来一起回顾下数据结构和算法的基础知识。

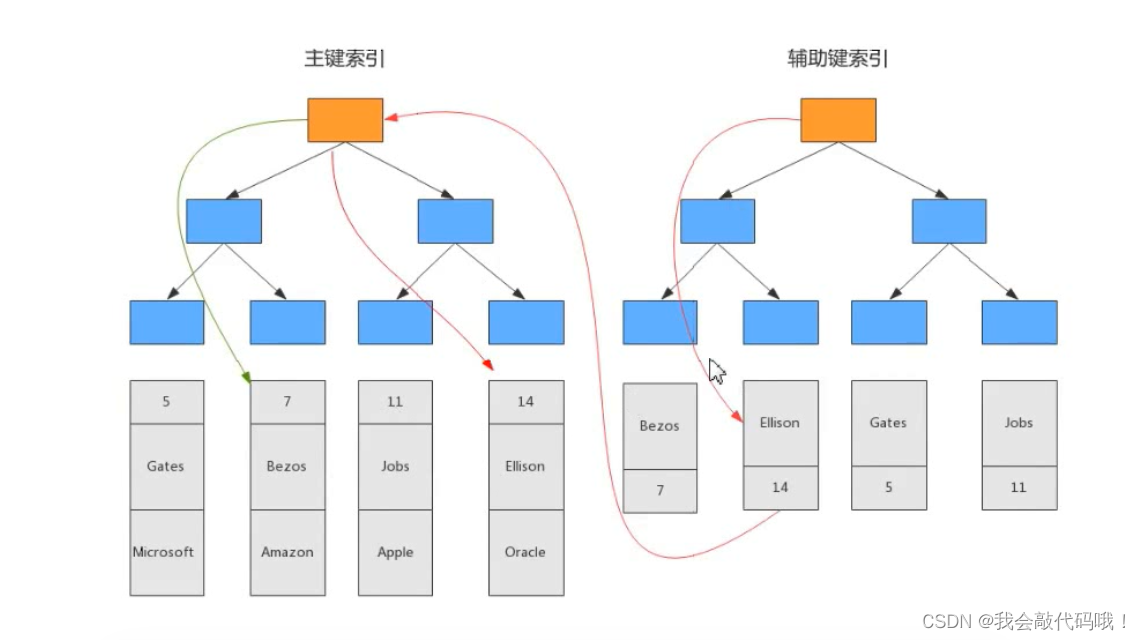
数据结构指的是“一组数据的存储结构”,算法指的是“操作数据的一组方法”。数据结构是为算法服务的,算法是要作用在特定的数据结构上的。数据库提高检索效率使用的是索引,数据库索引是一种树形数据结构,如MongoDB使用的是B-tree、MySQL使用的是B+tree。
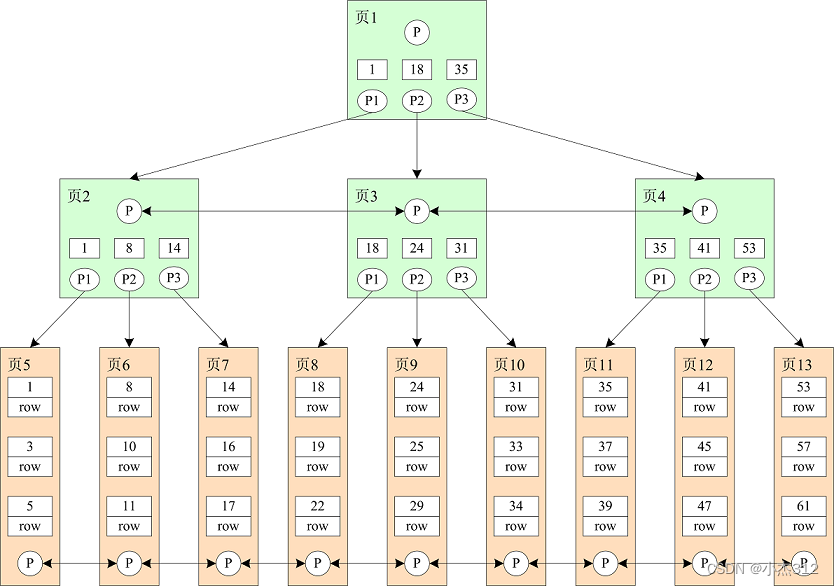
什么是B树(B-Tree)
我们来看下B树,如下图这是一颗3阶B树的例子:
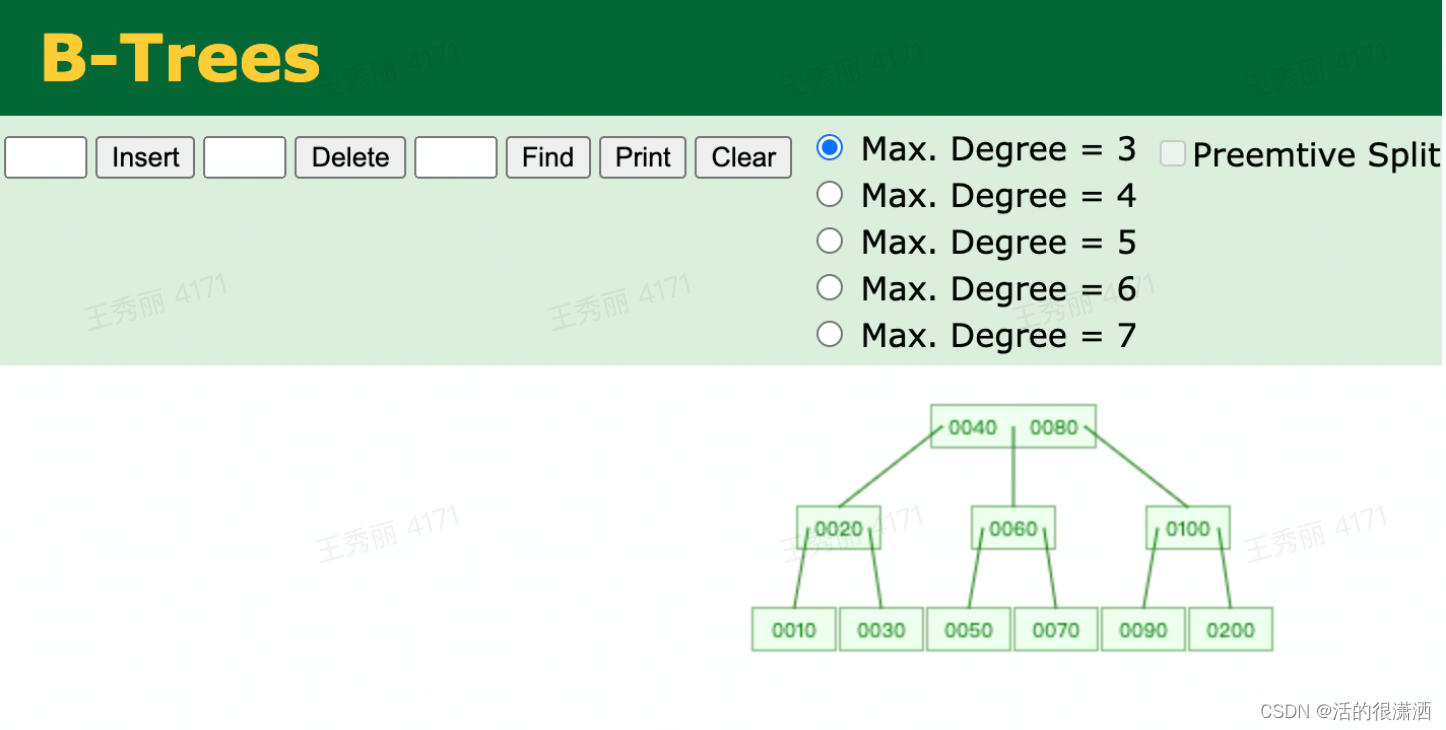
演示
通过学习B树,我们知道B树有以下特点
- B树在查询中的比较是在内存中完成的,相比磁盘IO的速度,内存中的比较耗时几乎可以忽略。所以只要树的高度足够低,IO次数足够少,就可以提升查找性能。
- B树为了插入一个元素,多个节点发生了连锁改变,会有一定的性能损耗,但也正因为如此,B树能够始终维持多路平衡。这也是B树的另外一大优势:自平衡。
- 查找的元素在不同的结点(根结点、中间结点、叶子结点),性能会有一定差别,因此查询性能不稳定。
- 范围查找性能不高。
我们知道二叉查找树查询的时间复杂度是O(logN),查找速度最快和比较次数最少,既然性能已经如此优秀,但为什么实现索引是使用B-Tree而不是二叉查找树,关键因素是磁盘IO的次数。
磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,大概9ms左右。这个成本是访问内存的十万倍左右。正是由于磁盘IO是非常昂贵的操作,所以数据库性能优化的核心思想是降低磁盘IO次数。
说明:
普通的机械盘HDD一次磁盘IO的时间大概是9ms
普通SSD一次磁盘IO耗时大概是0.2ms(IOPS:5000)
PCIe卡一次磁盘IO耗时大概是0.05ms(IOPS:20000) 从二叉树的查找过程了来看,最坏的情况下磁盘IO的次数由树的高度来决定。要减少磁盘IO的次数就必须要压缩树的高度,让瘦高的树尽量变成矮胖的树,所以B-Tree就在这样伟大的时代背景下诞生了。
在了解了数据库的发展及索引技术后,我们再进入今天的主题MongoDB,相信大家就有一定的体感了。
MongoDB介绍
本文重点介绍MongoDB,它虽然诞生于NoSQL,但4.0版本之后,已经不仅仅是NoSQL了,可以与上文中任何一位NewSQL的代表PK。MongoDB是一个开源、高性能、无模式的文档数据库,旨在简化开发和扩展。
MongoDB体系结构
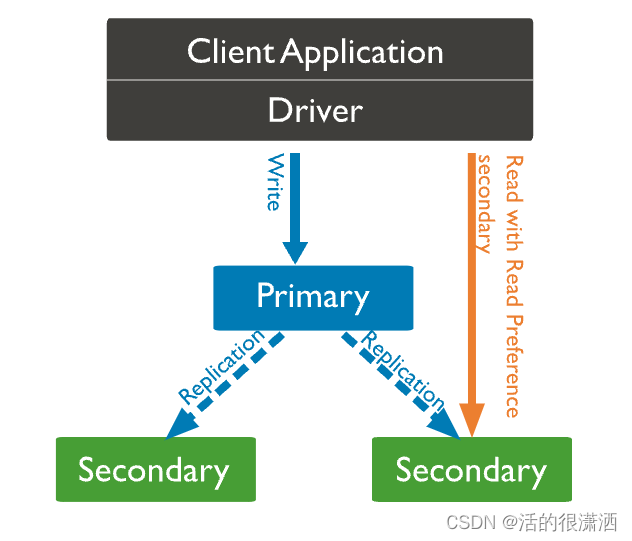
副本集架构
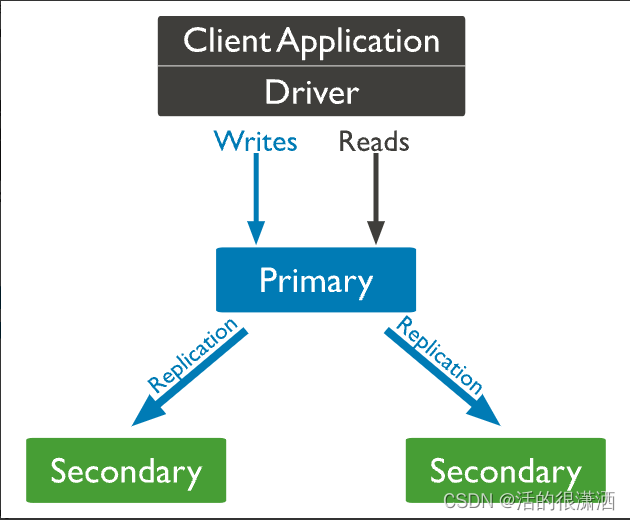
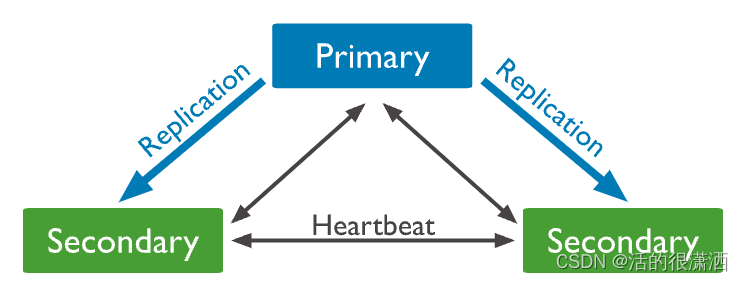
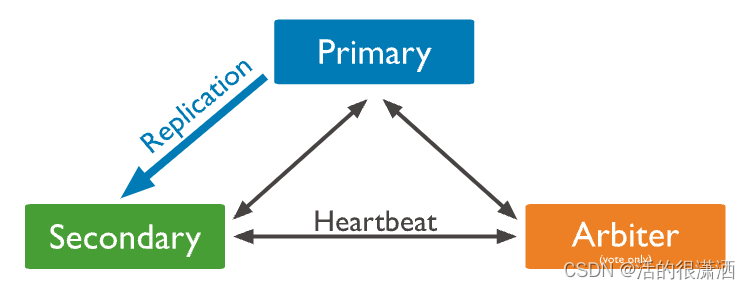
默认情况下,客户端从Primary读取数据,但可以配置读取首选项将读取操作发送到Secodary
备注
MongoDB复制是异步的,若配置了从Secondary读取数据,则需要业务接受数据延迟。
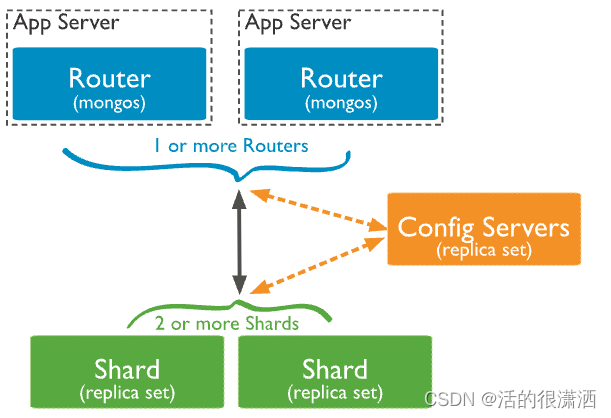
分片集群架构
一个 MongoDB分片集群由以下组件组成:
- shard:每个分片包含分片数据的一个子集。每个分片都可以部署为副本集。
- mongos:
mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。 - config servers:配置服务器存储集群的元数据和配置设置。从 MongoDB 3.4 开始,配置服务器必须部署为副本集 (CSRS)。
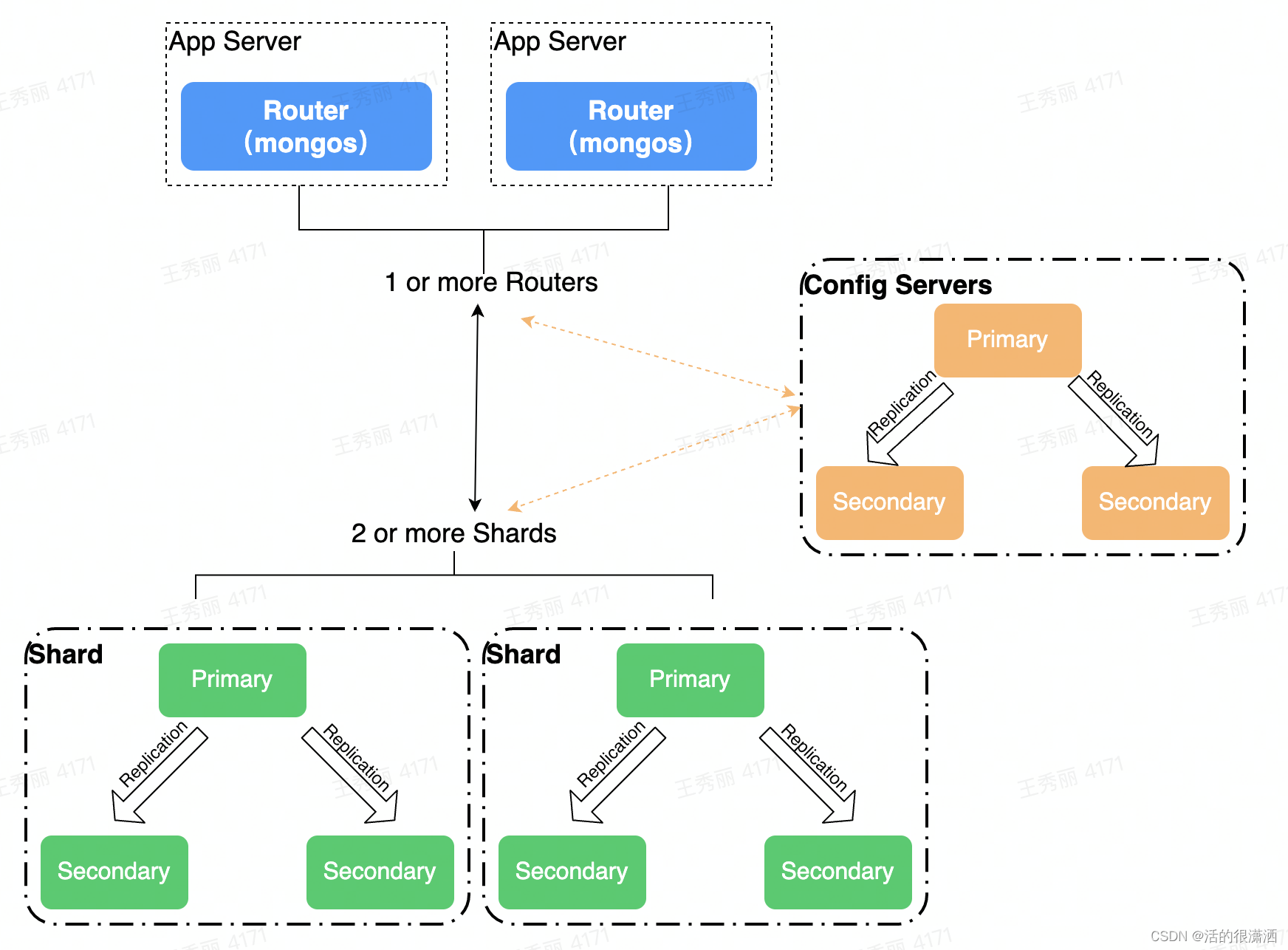
shard、config servers组建部署副本集保障高可用,mongos是单点架构,可以部署多个节点保障高可用。最终结构图如下:
 参照关系型数据库,我们来看看MongoDB中的对象。
参照关系型数据库,我们来看看MongoDB中的对象。
| RDBMS | MongoDB |
| database | database |
| table | collection |
| row | document |
| column | field |
MongoDB常用命令
选择切换数据库:use dbname
插入数据:db.collection.insert({bson数据})
查询所有数据:db.collection.find()
条件查询数据:db.collection.find({条件})
查询符合条件的第一条记录:db.collection.findOne({条件})
查询符合条件的前几条记录:db.collection.find({条件}).limit(条数)
查询符合条件的跳过的记录:db.collection.find({条件}).skip(条数)
修改数据:
db.collection.update({条件},{修改后的数据})
db.collection.update({条件},{$set:{要修改部分的字段:数据}})
修改数据并自增某字段值:db.collection.update({条件},{$inc:{自增字段:步进值}})
删除数据:db.collection.remove({条件})
统计查询:db.collection.count({条件})
模糊查询:db.collection.find({字段名:/正则表达式/})
条件比较运算:db.collection.find({字段名:{$gt:值}})
包含查询:
db.collection.find({字段名:{$in:[值1,值2]}})
db.collection.find({字段名:{$nin:[值1,值2]}})
条件连接查询:
db.collection.find({$and:[{条件1},{条件2}]})
db.collection.find({$or:[{条件1},{条件2}]})
MongoDB索引
索引是一种特殊的数据结构,常用于提高检索效率。MongoDB索引使用的是B-tree数据结构。
MongoDB索引分类
单字段索引
在单个字段上创建的索引,对于单字段索引和排序操作,索引键的排序顺序(即升序或降序)无关紧要,因为 MongoDB 可以在任一方向遍历索引

根据字段score进行选择的查询
#假如在字段score上创建了单列索引
db.records.find( { score: 2 } )
db.records.find( { score: { $gt: 10 } } )
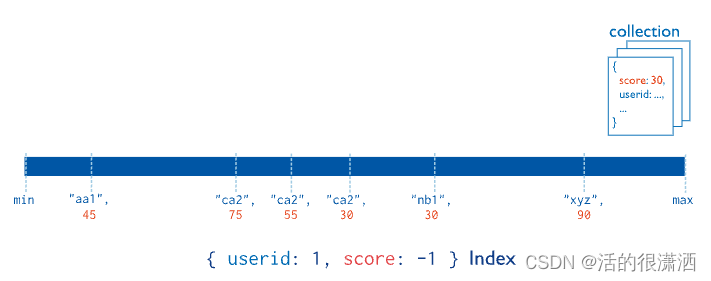
复合索引
多个字段的自定义索引,即复合索引。复合索引中列出的字段顺序很重要。例如,如果复合索引由{ userid: 1, score: -1 } 组成,则索引首先按userid排序,然后在每个userid值内按score排序。
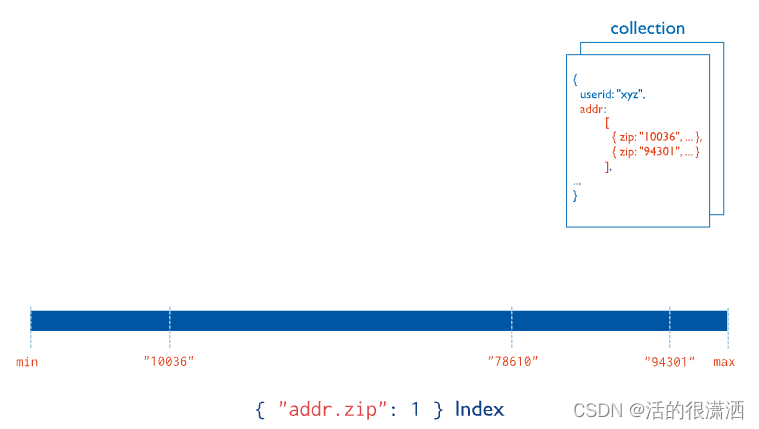
多键索引
MongoDB 使用多键索引来索引存储在数组中的内容。如果索引一个包含数组值的字段,MongoDB 会为数组的每个元素创建单独的索引条目。这些多键索引允许查询通过匹配数组的一个或多个元素来选择包含数组的文档。如果索引字段包含数组值,MongoDB会自动判断是否创建多键索引;你不需要明确指定多键类型。
其它索引
地理空间索引、文本索引、哈希索引、唯一索引
地理空间索引
为了支持地理空间坐标数据的高效查询,MongoDB 提供了两个特殊的索引:返回结果时使用平面几何的2d 索引和使用球面几何返回结果的2dsphere 索引。
文本索引
MongoDB 提供了一种text索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如“the”、“a”、“or”),而将集合中的词作为词干,只存储根词。
哈希索引
为了支持基于散列的分片,MongoDB 提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内具有更随机的分布值,但只支持相等匹配,不支持基于范围的查询。
唯一索引
索引的唯一属性导致 MongoDB 拒绝索引字段的重复值。除了唯一约束之外,唯一索引在功能上可以与其他 MongoDB 索引互换。
局部索引
3.2版本中的新功能。局部索引仅对集合中符合指定过滤器表达式的文档建立索引。通过对集合中文档的子集进行索引,局部索引具有较低的存储需求,并降低了索引创建和维护的性能成本。
局部索引提供了稀疏索引功能的超集,应该优先于稀疏索引。
稀疏索引
索引的稀疏属性确保索引仅包含具有索引字段的文档的条目。索引会跳过没有索引字段的文档。
你可以将稀疏索引选项与唯一索引选项结合使用,以防止插入索引字段具有重复值的文档并跳过缺少索引字段的索引文档。
TTL索引
TTL索引是 MongoDB 可用于在一定时间后自动从集合中删除文档的特殊索引。这对于某些类型的信息非常理想,例如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保留有限的时间。
索引注意事项
创建索引时,请考虑索引的以下行为:
- 每个索引至少需要 8 kB 的数据空间。
- 添加索引对写操作有一些负面的性能影响。对于具有高write-to-read比率的集合,索引很昂贵,因为每个插入还必须更新索引。
- 具有高read-to-write比率的集合通常受益于额外的索引。索引不影响未索引的读取操作。
- 当处于活跃状态时,每个索引都会消耗磁盘空间和内存。这种使用可能很重要,应该跟踪容量规划,尤其是对工作集大小的关注。
索引的使用
执行计划
分析查询性能,通常使用执行计划来查看查询的情况,如查询耗时,是否基于索引查询等。通常我们想知道,建立的索引是否有效,效果如何,都需要通过执行计划查看。
语法
db.collection.explain()
执行计划阅读
主要关注winningPlan部分
| 参数 | 含义 |
| plannerVersion | 查询计划版本 |
| namespace | 要查询的集合 |
| indexFilterSet | 是否应用了index filter |
| parsedQuery | 查询条件 |
| winningPlan | 最佳执行计划 |
| winningPlan.stage | 查询方式,常见的有
|
| winningPlan.filter | 过滤条件 |
| winningPlan.inputStage.keyPattern | 索引规则。这里是name正序 |
| winningPlan.inputStage.indexName | 索引名称 |
| winningPlan.inputStage.isMultiKey | 本次查询是否使用了多键、复合索引 |
| winningPlan.inputStage.isUnique | 本次查询是否使用了唯一键 |
| winningPlan.inputStage.direction | 查询顺序:正序是forward,倒序是backward |
| winningPlan.inputStage.indexBounds | 所扫描的索引范围 |
explain()参数
explain() 函数也可以接收不同参数,通过设置不同参数可以查看更详细的查询计划。参数包括:queryPlanner(默认)、executionStats、allPlansExecution
executionStats含义
| 参数 | 含义 |
| totalKeysExamined | 索引扫描次数 |
| totalDocsExamined | 在查询执行期间检查的文档数。 检查文档的常见查询执行阶段是 |
| nReturned | 返回的文档数 |
| executionTimeMillis | 执行耗时,单位:毫秒 |
| executionSuccess | 是否执行成功 |
|
| 以阶段树的形式详细说明获胜计划的完成执行情况;即一个阶段可以有一个 每个阶段都包含特定于该阶段的执行信息。 |
|
| 指定查询执行阶段执行的“工作单元”的数量。查询执行将其工作分成小单元。“工作单元”可能包括检查单个索引键、从集合中获取单个文档、将投影应用于单个文档或进行内部簿记。 |
|
| 存储层请求查询阶段暂停处理并产生其锁的次数。 |
|
| 查询阶段暂停处理并保存其当前执行状态的次数,例如准备释放其锁的次数。 |
|
| 查询阶段恢复保存的执行状态的次数,例如在恢复它之前产生的锁之后 |
|
| 指定在查询执行阶段扫描的文档数 为 |
MongoDB应用场景
MongoDB属于NoSQL数据库,支持单节点、副本集和分片集群三种部署架构,适用于处理JSON数据的场景,比如应用日志类分析查询。
灵活多变的业务场景
云数据库MongoDB采用No-Schema的方式,免去变更表结构的痛苦,非常适用于初创型的业务需求。用户可以将模式固定的结构化数据存储在RDS(Relational Database Service)中,模式灵活的业务存储在MongoDB中,高热数据存储在云数据库Redis中,实现对业务数据高效存取,降低存储数据的投入成本。
移动应用
云数据库MongoDB支持二维空间索引,可以很好地支撑基于位置查询的移动类App的业务需求。同时MongoDB动态模式存储方式也非常适合存储多重系统的异构数据,满足移动App应用的需求。
MongoDB最佳实践
有了上面的理论学习,那在实际使用中我们应该用什么姿势才能使MongoDB发挥出最佳性能呢?这里总结了一些实践经验。
选择合适的应用场景
非强关系型,Json文档类应用。
建立合适的索引
- 通过过滤性查看索引效果
- db.collection.distinct("field").length/db.collection.count() 值越接近1效果越好
- 通过执行计划查看索引是否有用
- 尽量使用覆盖索引
- 利用前缀索引
- 避免建重复索引,提高索引使用率
- 尽量利用索引排序,避免产生临时表
- 避免使用全模糊查询 like '%xxx%’
- 单集合索引建议不超过7个
什么情况下使用分片集群
当业务遇到如下问题时,可以使用分片集群解决:
- 存储容量受单机限制,即磁盘资源遭遇瓶颈。
- 读写能力受单机限制,可能是CPU、内存或者网卡等资源遭遇瓶颈,导致读写能力无法扩展。
选择合理的Shard Key
好的Shard Key拥有的特性
- key分布足够离散(sufficient cardinality)
- 写请求均匀分布(evenly distributed write)
- 尽量避免scatter-gather查询(targeted read)
示例:
场景:某物联网应用使用MongoDB分片集群存储海量设备的工作日志。如果设备数量在百万级别,设备每10秒向MongoDB汇报一次日志数据,日志包含设备ID(deviceId)和时间戳(timestamp)信息。应用最常见的查询请求是查询某个设备某个时间内的日志信息。
查询请求:查询某个设备某个时间内的日志信息。
- (推荐)方案一:组合设备ID和时间戳作为Shard Key,进行范围分片。
- 写入能均分到多个shard。
- 同一个设备ID的数据能根据时间戳进一步分散到多个chunk。
- 根据设备ID查询时间范围的数据,能直接利用(deviceId,时间戳)复合索引来完成。
- 方案二: 时间戳作为Shard Key,进行范围分片。
- 新的写入为连续的时间戳,都会请求到同一个分片,写分布不均。
- 根据设备ID的查询会分散到所有shard上查询,效率低。
- 方案三: 时间戳作为Shard Key,进行哈希分片。
- 写入能均分到多个shard上。
- 根据设备ID的查询会分散到所有shard上查询,效率低。
- 方案四:设备ID作为Shard Key,进行哈希分片。
说明 如果设备ID没有明显的规则,可以进行范围分片。
- 写入能均分到多个shard上。
- 同一个设备ID对应的数据无法进一步细分,只能分散到同一个chunk,会造成jumbo chunk,根据设备ID的查询只请求到单个shard,请求路由到单个shard后,根据时间戳的范围查询需要全表扫描并排序。
避免分片场景下的广播操作
mongos实例向集合的所有分片广播查询,除非mongos可以确定哪个分片或分片子集存储此数据。
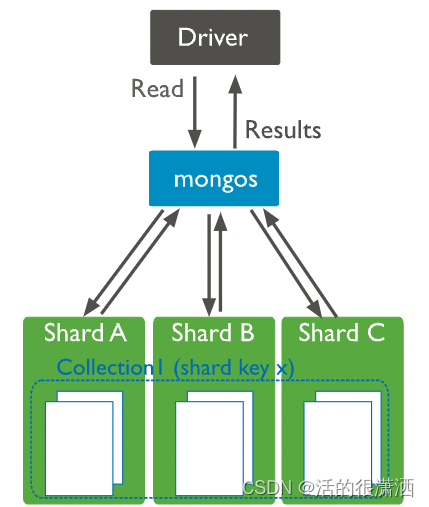
mongos接收到所有分片的响应后,它会合并数据并返回结果文档。广播操作的性能取决于集群的整体负载,以及网络延迟、单个分片负载和每个分片返回的文档数量等变量。在可能的情况下,优先选择导致目标操作的操作,而不是导致广播操作的操作。
比如:updateMany(),deleteMany()都是广播操作
关于负载均衡
MongoDB分片集群的自动负载均衡目前是由mongos的后台线程来做,并且每个集合同一时刻只能有一个迁移任务。负载均衡主要根据集合在各个shard上chunk的数量来决定的,相差超过一定阈值(和chunk总数量相关)就会触发chunk迁移。
负载均衡默认是开启的,为了避免chunk迁移影响到线上业务,可以通过设置迁移执行窗口,例如只允许凌晨02:00~06:00期间进行迁移。
use config
db.settings.update(
{ _id: "balancer" },
{ $set: { activeWindow : { start : "02:00", stop : "06:00" } } },
{ upsert: true }
)
No Data No BB
在聊了这么多以后,我们来点有力的数据说话。
测试环境
MongoDB4.2社区版,4核8G三节点副本集架构
测试说明
使用开源YCSB压测,每个document大小为1KB。
测试结果分析
为了和阿里云MongoDB在同一个维度对比,所有测试均为全表扫描,没有使用索引。MongoDB实际性能因不同应用场景会有所不同,业务使用上请以业务压测结果为准。
参数说明
- count:recordcount(已经存在的记录数)和operationcount(待执行的操作数)之和。
- threads:客户端测试所用线程数总和。
- throughput:客户端测试吞吐,即读写操作数。单位为ops/s。
- RAL:读操作平均延迟,单位为us。
- WAL:写操作平均延迟,单位为us。
在不谈响应时间的前提下谈并发都是耍流氓,以下所有测试结果均是在保障读写延迟在5ms内进行的最高并发压测。
纯insert 400w数据测试结果
| MongoDB4.2 on ECS | count | threads | Throughput | RAL | WAL |
| 4核8G | 4000000 | 16 | 16003 | 0 | 987 |
读写比50:50的测试结果
| MongoDB4.2 on ECS | count | threads | Throughput | RAL | WAL |
| 4核8G | 4000000 | 5 | 5964 | 798 | 863 |
读写比95:5的测试结果
| MongoDB4.2 on ECS | count | threads | Throughput | RAL | WAL |
| 4核8G | 4000000 | 16 | 16170 | 965 | 1171 |
常见问题
问题1:查线上问题,可以查备节点吗?
对于MongoDB来说,默认使用Primary节点对外提供读写服务,手工排查线上问题,可以访问Secondary节点查询数据。在DMS上找到自己的库,然后选择Secondary节点查询即可。
问题2:可以使用唯一索引吗?
对于数据库来说,最重要的作用是快速存储、检索数据。使用唯一索引的目的是避免重复数据写入,应用端就可以解决,在DB端实现的话会降低数据库的性能,所以不建议放到数据库上去实现。
问题3:我想看看在某列上键索引效率如何?
使用以下语句查看索引过滤性,值越接近1效果越好。
db.collection.distinct("field").length/db.collection.count() 问题4:如何实现读写分离?
要实现读写分离,需要在Connection String URI的options里添加readPreference=secondaryPreferred,设置读请求为Secondary节点优先。
mongodb://root:xxxxxxxx@dds-xxxxxxxxxxxx:3717,xxxxxxxxxxxx:3717/admin?replicaSet=mgset-xxxxxx&readPreference=secondaryPreferred 注意:副本集的复制是异步的,也就是说设置读取secondary优先,即意味着业务放弃了数据的实时性,接受数据延迟读取。
问题5:什么情况下使用分片集群?
当遇到如下问题时,可以使用分片集群解决:
- 存储容量受单机限制,即磁盘资源遭遇瓶颈。
- 读写能力受单机限制,可能是CPU、内存或者网卡等资源遭遇瓶颈,导致读写能力无法扩展。
问题6:如何确定shard、mongos数量?
可以根据以下方法确定shard和mongos的使用数量:
- 分片集群仅用于解决海量数据的存储问题,且访问量不多。例如一个shard能存储M, 需要的存储总量是N,那么业务需要的shard和mongos数量按照以下公式计算:
- numberOfShards = N/M/0.75 (假设容量水位线为75%)
- numberOfMongos = 2+(对访问要求不高,至少部署2个mongos做高可用)
- 分片集群用于解决高并发写入(或读取)数据的问题,但总的数据量很小。即shard和mongos需要满足读写性能需求,例如一个shard的最大QPS为M,一个mongos的最大QPS为Ms,业务需要的总QPS为Q,那么您的业务需要的shard和mongos数量按照以下公式计算:
- numberOfShards = Q/M/0.75 (假设负载水位线为75%)
- numberOfMongos = Q/Ms/0.75
说明:mongos、mongod的服务能力,需要用户根据访问特性来实测得出。
问题7:为什么MongoDB使用B树?
- MySQL 使用B+树是因为数据的遍历在关系型数据库中非常常见,它经常需要处理各个表之间的关系并通过范围查询一些数据;但是MongoDB作为面向文档的数据库,与数据之间的关系相比,它更看重以文档为中心的组织方式,所以选择了查询单个文档性能较好的 B 树,这个选择对遍历数据的查询也可以保证可以接受的时延;
- LSM 树是一种专门用来优化写入的数据结构,它将随机写变成了顺序写显著地提高了写入性能,但是却牺牲了读的效率,这与大多数场景需要的特点是不匹配的,所以MongoDB 最终还是选择读取性能更好的B树作为默认的数据结构。
问题8:相比MySQL InnoDB,MongoDB有哪些优势?
MongoDB是NoSQL类别里的文档数据库,在json方面具有明显优势。
扩展能力
MySQL分片能力需要借助第三方软件实现,增加运维成本;MongoDB原生支持分片,自带分片组件,不需要依赖第三方。
敏捷开发
MongoDB是no schema架构,不需要提前创建表结构,业务可以快速迭代。
性能
针对单key查询,时间复杂度最大是O(logN),性能强于MySQL。
问题9:对线上加索引会锁表吗?
4.2及以上版本在创建索引过程中,仅在索引构建的开始和结束时持有排他锁,构建过程中的其余部分产生交错读取和写入操作。建议在业务低峰期添加索引。
问题10:WiredTiger持久化如何实现的?
MongoDB使用可插拔的存储引擎来管理数据的持久化,通俗点讲就是存储引擎负责数据从内存到磁盘,及磁盘到内存的管理。
WT以page为单位读取数据,所有的的CURD操作在内存完成,WT负责内存到磁盘的持久化操作,默认情况下每60s会生成一个检查点,生成检查点的时刻可以保障内存和磁盘中的数据是一致的。两个检查点间的数据使用journal(redo log)日志记录,journal每100ms从日志缓冲区刷数据到journal文件。因此极端情况下会丢失100ms的数据。
问题11:oplog同步对性能的影响有多大?
有一定影响,但相对于单点不可用的风险,这点性能影响可以接受,具体影响多少,和业务使用场景相关,以实际业务压测为准。
问题12:string是如何转换成rage分片的?
[0-9][a-z]
问题13:对象嵌套,如何查询子文档性能较好?
使用全文索引可以加速效率,但MongoDB对倒排索引支持并不是特别好,建议纯文本搜索还是使用ES或者ADB之类的数据库产品。
问题14:如何查询引用文档?
参考
问题15:chunk的作用?
分片场景下的逻辑概念,可以认为是二次散列。chunksize大小决定了分片集群的性能。chunk数量由分片键基数、变化频率决定。config servier仅用于存放分片集群中的元数据,比如分片键、chunk、分片集群等信息,本身可以配置为副本集的方式,w:majority保证元数据不丢失。