1 简介
索引底层就是一种数据结构,空间换时间,能够帮助我们快速定位到对应的数据,就类似于字典里面的目录一样。
索引虽然能快速检索数据,但会影响数据修改的操作,而且索引存储在具体的文件,占用一定的空间(MySQL安装目录下的data文件存储),因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
2 索引类型
-
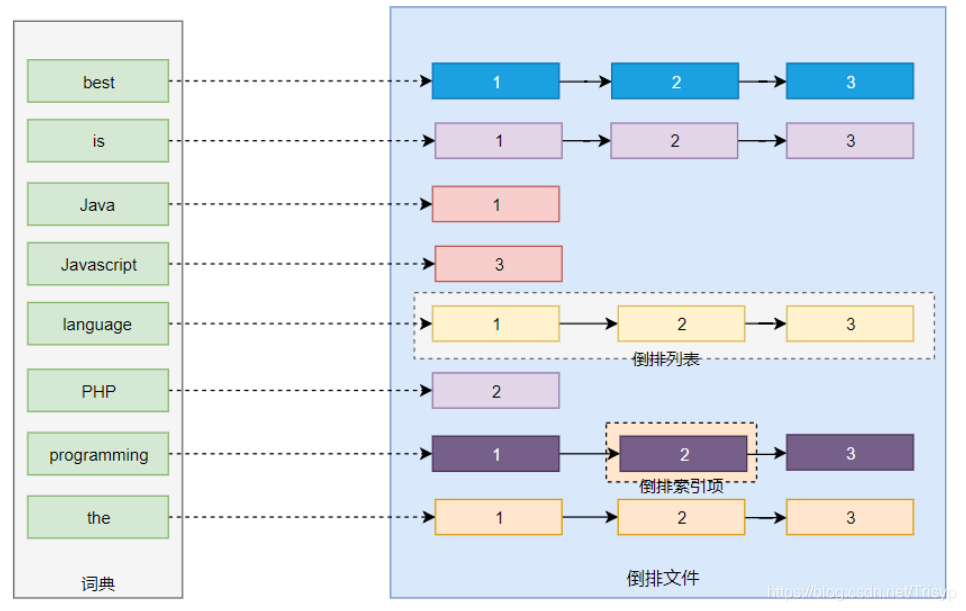
从索引存储结构划分:B Tree索引、Hash索引、FULLTEXT全文索引、R Tree索引
-
应用层次划分:普通索引、唯一索引、主键索引、组合索引
-
索引键值类型划分:主键索引、辅助索引(二级索引)
-
数据存储和索引键值逻辑关系划分:聚簇和非聚簇索引
3 数据结构
MySQL索引的数据结构是B+Tree,但是又对B+Tree做了一点改造(双向指针)。
这里推荐一个关于数据结构的网站:Data Structure Visualization
3.1 二叉树
左小又大,一个父元素下面只能存储两个子元素。
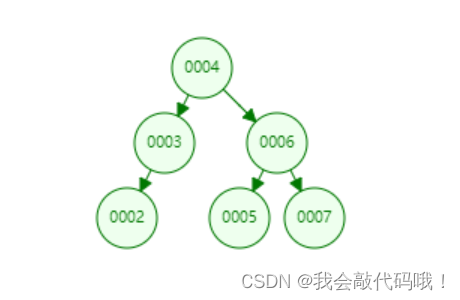
二叉树有什么弊端?
随着数据量的增加,数的高度也会跟着提高,最差的情况需要到最下层叶子节点才能获取到,而且还会出现链表的情况(二叉树的特性导致),如下:
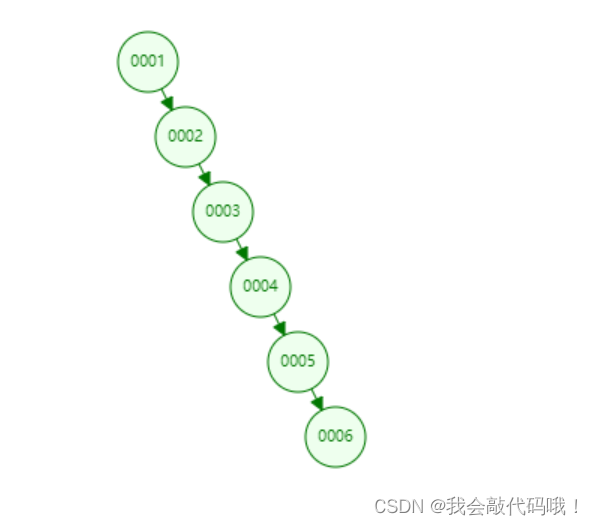
3.2 Hash
Hash索引是根据Hash表实现的,非常适合等值查询
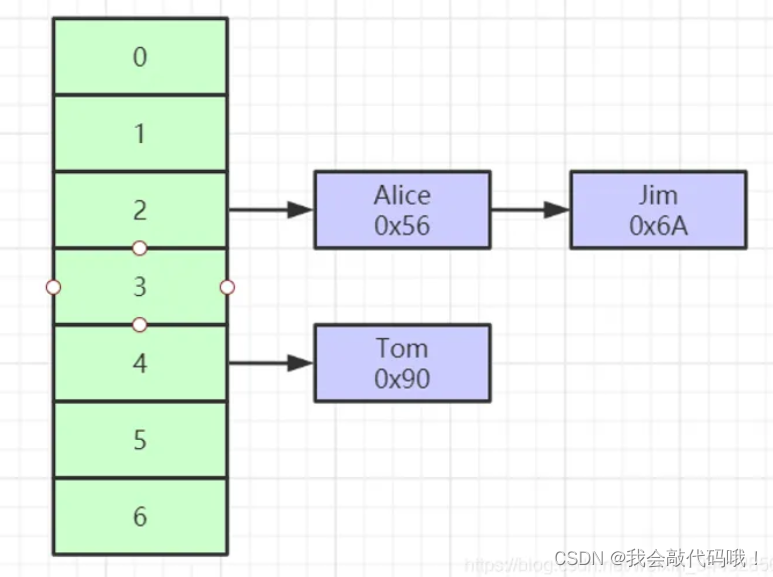
Hash有什么弊端呢?
不支持范围查询和模糊查询,每个桶采用拉链法解决Hash冲突,所以存在最坏的情况(长链表)
InnoDB存储引擎的自适应Hash索引:
当InnoDB注意到某些索引值访问非常频繁时,会在内存中基于B+Tree索引再创建一个哈希索引,使得内存中的 B+Tree 索引具备哈希索引的功能,即能够快速定值访问频繁访问的索引页。
3.3 B-Tree
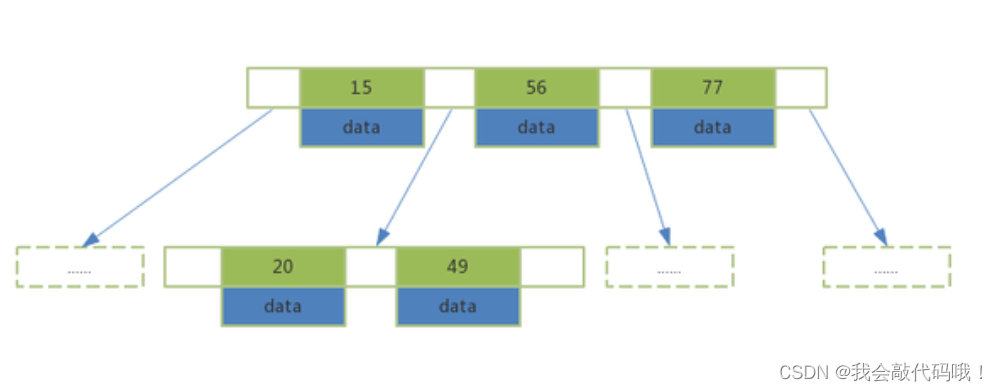
每个节点存放索引值及对应的data数据,弊端:数据量增大,树的高度也会提高
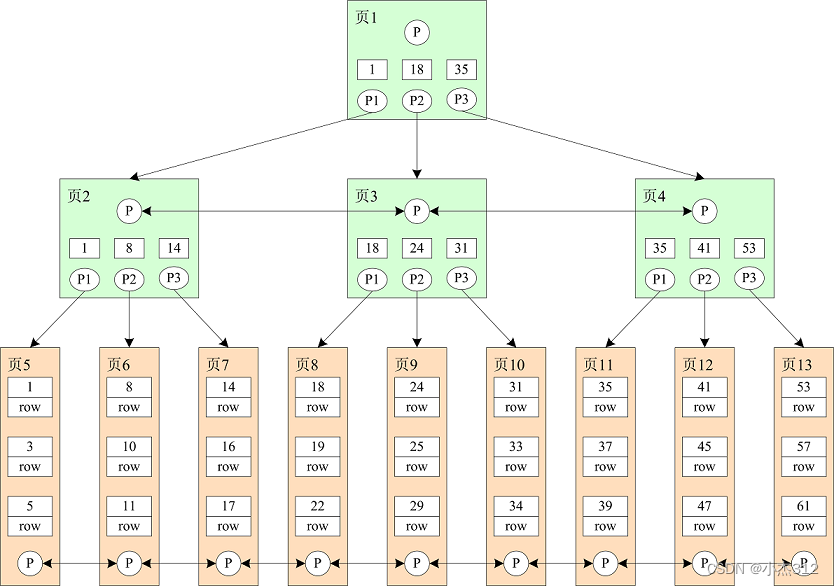
3.4 B+Tree
B+Tree是B Tree的变种。
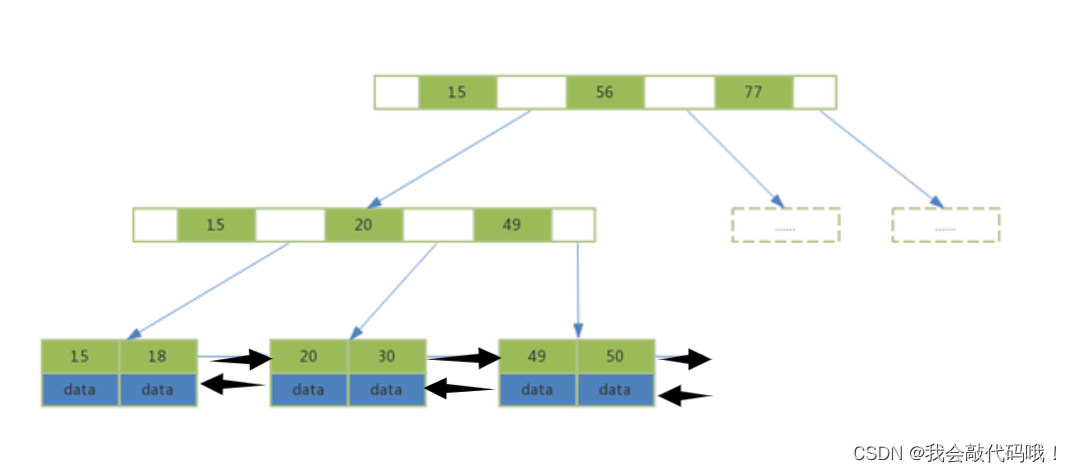
最下面的叶子节点存储具体的数据,并且不同数据页有双向指针相关联。
拿最简单的例子对比一下B树和B+树:
MySQL中一个数据页大小为16KB(show global status like 'Innodb_page_size'),int类型在存储时占4个字节,指针占6个字节,比如一个数据占1KB,B+树按三层高算:
第一层:16KB/4+6B = 1600个
第二层:1600个
第三层:一个数据页存储16个数据
所以一共1600 * 1600 * 16 = 40,960,000,而B树存储那么多数据就不可能低于3层。
而且B+树范围查询快。
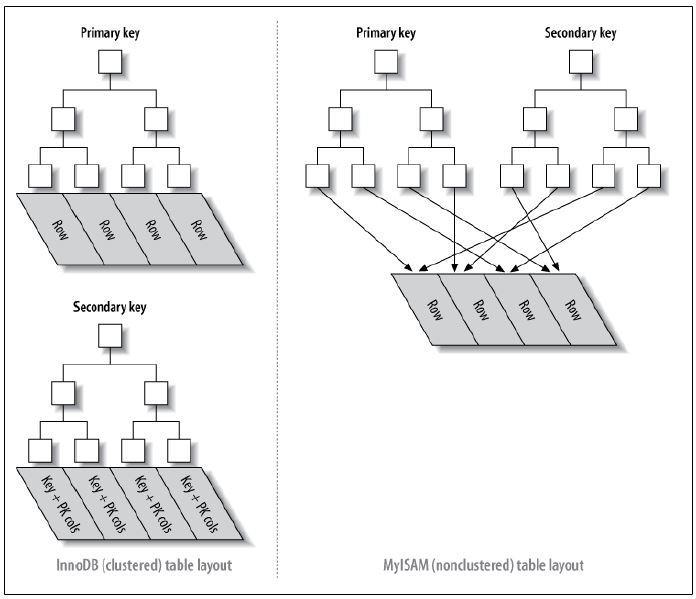
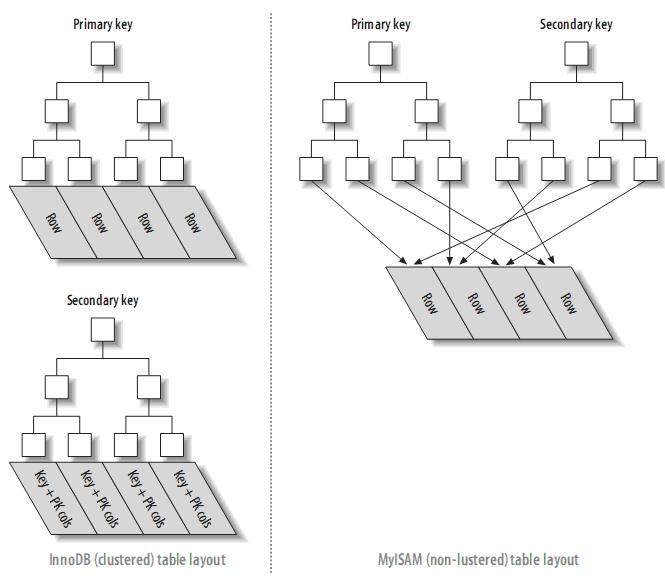
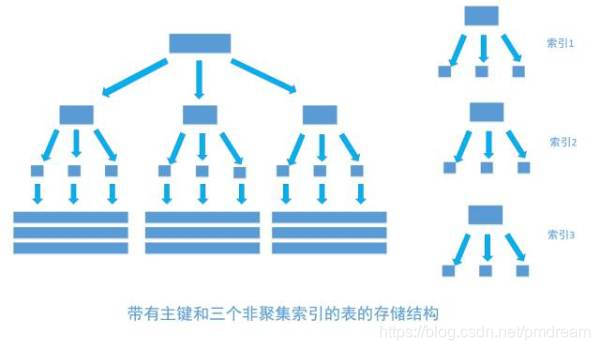
4 聚簇索引和非聚簇索引
聚簇索引:是一种存储方式,主键值和行记录保存在一起,意味着主键索引就是数据本身,主键索引就是聚簇索引。
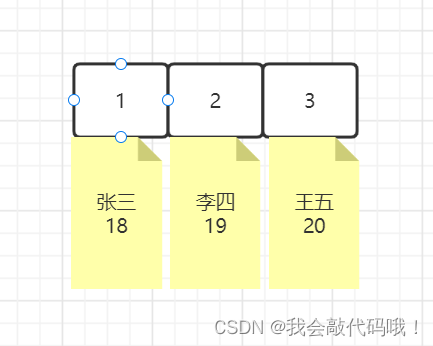
-
如果表定义了主键,则主键索引就是聚簇索引(主键就是索引)
-
没有定义主键,则第一个非空唯一列作为聚簇索引
-
都没有,创建一个隐藏的row-id作为聚簇索引
非聚簇索引:又叫二级索引(辅助索引),叶子节点只存储索引列和主键的信息,当查询的字段不是该索引列或者主键时,要进行回表查询出对应的数据。
5 最左前缀原则
MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,以最左边的为起点连续的索引都能匹配上。联合索引遇到范围查询(>、<、between、like)可能就会失效。

6 回表
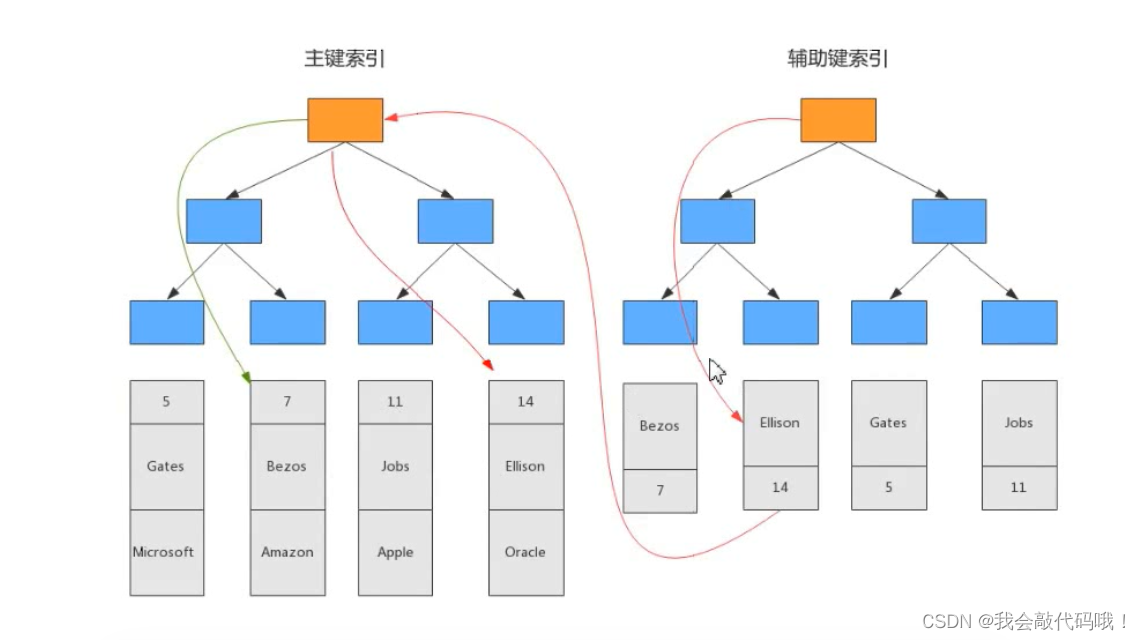
回表只发生在二级索引(非聚簇索引或者辅助索引)中,因为数据和索引不是保存在一块,二级索引树只保存索引值和主键值,当需要查询的数据不在辅助索引树上面时,需要先找到辅助索引,再找到主键索引,最后根据主键索引查询出对应的行数据,这叫回表。
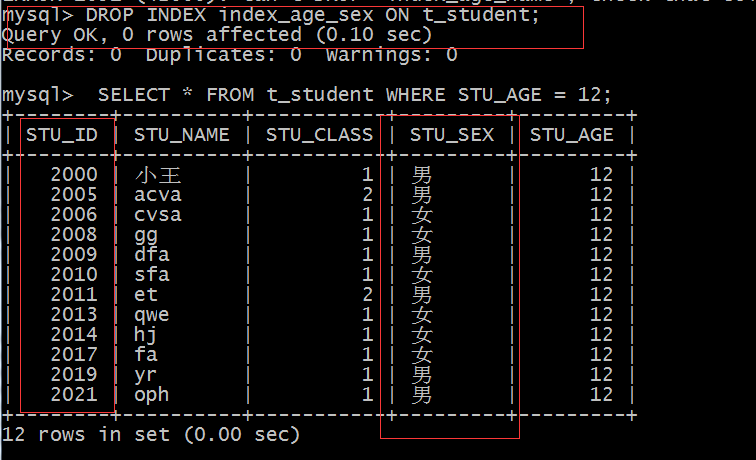
例如下图,使用辅助索引,查询Oracle数据时,就需要回表。
7 索引覆盖和索引下推
索引覆盖:只需在一颗索引树就能获取sql所需的所有列数据,不需要回表查询,速度很快。
索引下推:非主键每次查询都要回表,作用:回表之前先筛选掉一部分不符合的数据,再回表(减少回表的次数)
不使用索引条件下推优化时存储引擎通过索引检索到数据,然后返回给MySQL Server,MySQL Server进行过滤条件的判断。
当使用索引条件下推优化时,如果存在某些被索引的列的判断条件时,MySQL Server将这一部分判断条件下推给存储引擎,然后由存储引擎通过判断索引是否符合MySQL Server传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。
8 什么情况下适合创建索引
1.在where后面的过滤字段上建立索引
2.在具有唯一要求的字段上添加唯一索引
3.group by或者order by后面的字段添加索引
4.在多表连接join的时候在连接的字段上建立索引(小表驱动大表)
5.在频繁使用的列上建立索引
6.在区分度高的列上建立索引