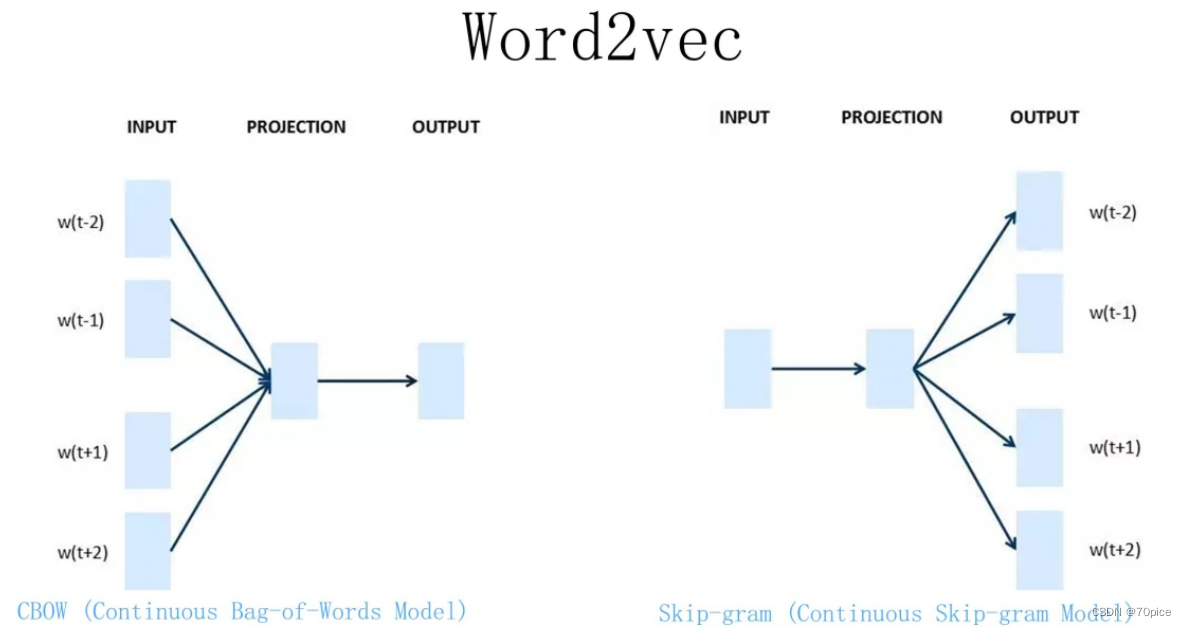
2017年1月12日在中国汽车协会举办的信息发布会上,中汽协秘书长助理代表协会对2017年中国汽车市场作出预测:“2017年我国的汽车产销量预计为2940万辆,增速预计保持在5%左右。”在当天发布的产销数据中,2016年汽车销量达2803万辆。
中国汽车销售市场连年火爆,自主品牌实力不断增强,对汽车整车及零部件的质量检测与管控都提出了极高的要求。只有不断提高产品质量,才能保证在竞争激烈的市场中占有一席之地。而在汽车行业检测中,纹理金属的表面缺陷检测具有极其重要的地位,因为大到整车车身,小到轴承、螺纹孔位等,都遍布着纹理金属的影子。
粗糙金属表面检测的挑战

图1:汽车行业现场示意图
检测汽车行业中的粗糙金属零部件的质量,主要面临着以下挑战:
-
由于粗糙的表面和明显的纹理,在生产早期阶段产生的撞击、刮伤和污渍很难被检测出来。
-
材料表面正常的形变和不显著的异常应该处于容许范围内,不应当被当成残次品而报错。
-
污渍和伤痕在不同照明条件下所呈现的差异不同 。
VIDI是第一款致力于工业图像分析、可以深度学习并可以做用前准备的软件。VIDI套件是一款基于科学的机器学习算法、可实地测验的可靠软件解决方案,被喻为机器视觉行业的阿尔法狗。它可以解决程序检查及分类等不太可能完成的挑战。这为机器视觉应用领域中的诸多挑战提供了一个强大、灵活、明确的解决方案。VIDI套件主要包含VIDI blue、VIDI red和VIDI green三种不同的工具,各自的详细功能及特性简介如下:

功能定位 & 自动识别
VIDI蓝色工具,能在一张图片中寻找和定位一个或多个特征。它具有强大的改变自身特性的能力,能适应大多数嘈杂环境(OCR)或复杂的对象。这款蓝色工具能通过学习带有特征注释的图片,来定位和识别复杂的特征和目标。
训练使用VIDI蓝色工具,您只需要提供标记了目标特性的图片。

分割 & 缺陷检测
VIDI红色工具,用来检测异常现象以及一些审美上的缺陷。例如装饰物表面的划痕,不完整的衣片,甚至是在纺织物的织造问题上,这款红色工具都能通过学习对象正常情况下的外观,包括重要的、可允许的变化,来识别这些问题,甚至其他更多问题。 VIDI红色工具也可以用来分割一些特定区域,例如有缺陷的部分或感兴趣区域。 无论是医疗用织物还是饰带的裁剪区上的特定异物,这款红色工具都能通过学习目标区域的不同外表,轻易识别。

目标 & 事件分类
VIDI绿色工具,用来分类一个对象或者一个完整的场景。无论是通过检测包装来完成对产品的识别、对焊接接缝的分类,还是对可接受的和不可接受的缺陷的分离,这款绿色工具都可以通过对标签图像的采集,来学习如何将不同类型的图像分离开来。
训练使用这款绿色工具,您只需要提供按照不同种类进行分配、贴标的图片。
2016年年底,阿尔法狗升级版Master横扫60多位围棋大师,创造了人工智能的新神话,成为街头巷尾热议的话题。
同年源自瑞士的人工智能深度学习软件VIDI,也针对机器视觉行业做了产品升级,发布了VIDI 2.0的版本。VIDI和阿尔法狗一样使用神经网络算法,模块化地解决机器视觉的各种问题,真正让人工智能走入机器视觉领域。VIDI让每一台自动化设备有了大脑,有了像人一样的学习能力,可以在不断工作中积累经验,越干经验越丰富,结果越来越精准,实现真正意义上的机器替代人,必将掀起新一轮的产业变革。
利用VIDI红色模块工具的管理模式和VIDI绿色模块的自动化检测与分类,将会使汽车行业的金属零部件检测变得非常简单。
首先需要收集大量的零部件检测图片做为学习样本库,其中包括正常品和残次品,每种残次品的检测图片至少包含一组以上。样本库中的样本越多,学习效果越好,后续的检测也会越准确。
接下来VIDI Suite通过图片样本库进行训练学习,并产生检测的参照模型,这个学习过程只需要不到30分钟,具体学习取决于电脑的硬件配置。
最后即可将VIDI用于实际的检测中。
缺陷案例

图2:缺陷检测案例
如图2所示,软件算法通过一组有代表性的注释图像,以及已知的好样本进行自我训练后,学习系统自动集成上下文信息,形成一个可靠的形状和纹理的模型,用于校对检测。结果显示,之前难以被识别的缺陷,都可以被准确地检测到:撞击和刮伤被视为异常,因为它们有一个纹理区域偏离了预期的设定值,即撞击和刮伤面积超出了容忍偏差。
粗糙金属板
表面缺陷检查的关键挑战之一, 即它们是动态的,这与零部件的加工工艺流程或成形过程有直接关系。当零部件经历了全部的生产步骤,其中部分表面被喷涂油漆,导致抛光表面成为镜面反射光。如图3所示,此时撞击、污渍和划痕这些缺陷才变得可见,并且令人不安。汽车生产厂商完全不能接受这种缺陷产品。
然而,这种只能在工艺末端才能检测到的缺陷,成本非常高昂。利用VIDI红色模块,粗糙材料上典型的缺陷,可以通过任何标准照明和矩阵相机获得的图像检测和分类。训练阶段完成后,在一个标准GPU上计算其能在几毫秒内可靠地识别缺陷,从而实现在线实时检测。

图3:粗糙金属板表面的撞击、污渍和划痕检测实例
结果 & 性能
-
强大的检测:VIDI可以在生产过程的早期阶段,可靠地对复杂纹理的表面、镜面反射和可容忍范围内的异常图像缺陷进行检测和分类。
-
自学习:检测过程无需大量仔细调整和优化的检测算法,而是依赖于一个类似人类的方法——学习和应用,并且具有改进的测试一致性和可重复性。
-
快速&简单:整个学习具有代表性的图片样本库的过程非常高效,其学习时间小于30分钟。
-
2017年1月12日在中国汽车协会举办的信息发布会上,中汽协秘书长助理代表协会对2017年中国汽车市场作出预测:“2017年我国的汽车产销量预计为2940万辆,增速预计保持在5%左右。”在当天发布的产销数据中,2016年汽车销量达2803万辆。
中国汽车销售市场连年火爆,自主品牌实力不断增强,对汽车整车及零部件的质量检测与管控都提出了极高的要求。只有不断提高产品质量,才能保证在竞争激烈的市场中占有一席之地。而在汽车行业检测中,纹理金属的表面缺陷检测具有极其重要的地位,因为大到整车车身,小到轴承、螺纹孔位等,都遍布着纹理金属的影子。
粗糙金属表面检测的挑战
图1:汽车行业现场示意图
检测汽车行业中的粗糙金属零部件的质量,主要面临着以下挑战:
-
由于粗糙的表面和明显的纹理,在生产早期阶段产生的撞击、刮伤和污渍很难被检测出来。
-
材料表面正常的形变和不显著的异常应该处于容许范围内,不应当被当成残次品而报错。
-
污渍和伤痕在不同照明条件下所呈现的差异不同 。
VIDI是第一款致力于工业图像分析、可以深度学习并可以做用前准备的软件。VIDI套件是一款基于科学的机器学习算法、可实地测验的可靠软件解决方案,被喻为机器视觉行业的阿尔法狗。它可以解决程序检查及分类等不太可能完成的挑战。这为机器视觉应用领域中的诸多挑战提供了一个强大、灵活、明确的解决方案。VIDI套件主要包含VIDI blue、VIDI red和VIDI green三种不同的工具,各自的详细功能及特性简介如下:
功能定位 & 自动识别
VIDI蓝色工具,能在一张图片中寻找和定位一个或多个特征。它具有强大的改变自身特性的能力,能适应大多数嘈杂环境(OCR)或复杂的对象。这款蓝色工具能通过学习带有特征注释的图片,来定位和识别复杂的特征和目标。
训练使用VIDI蓝色工具,您只需要提供标记了目标特性的图片。
分割 & 缺陷检测
VIDI红色工具,用来检测异常现象以及一些审美上的缺陷。例如装饰物表面的划痕,不完整的衣片,甚至是在纺织物的织造问题上,这款红色工具都能通过学习对象正常情况下的外观,包括重要的、可允许的变化,来识别这些问题,甚至其他更多问题。 VIDI红色工具也可以用来分割一些特定区域,例如有缺陷的部分或感兴趣区域。 无论是医疗用织物还是饰带的裁剪区上的特定异物,这款红色工具都能通过学习目标区域的不同外表,轻易识别。
目标 & 事件分类
VIDI绿色工具,用来分类一个对象或者一个完整的场景。无论是通过检测包装来完成对产品的识别、对焊接接缝的分类,还是对可接受的和不可接受的缺陷的分离,这款绿色工具都可以通过对标签图像的采集,来学习如何将不同类型的图像分离开来。
训练使用这款绿色工具,您只需要提供按照不同种类进行分配、贴标的图片。
2016年年底,阿尔法狗升级版Master横扫60多位围棋大师,创造了人工智能的新神话,成为街头巷尾热议的话题。
同年源自瑞士的人工智能深度学习软件VIDI,也针对机器视觉行业做了产品升级,发布了VIDI 2.0的版本。VIDI和阿尔法狗一样使用神经网络算法,模块化地解决机器视觉的各种问题,真正让人工智能走入机器视觉领域。VIDI让每一台自动化设备有了大脑,有了像人一样的学习能力,可以在不断工作中积累经验,越干经验越丰富,结果越来越精准,实现真正意义上的机器替代人,必将掀起新一轮的产业变革。
利用VIDI红色模块工具的管理模式和VIDI绿色模块的自动化检测与分类,将会使汽车行业的金属零部件检测变得非常简单。
首先需要收集大量的零部件检测图片做为学习样本库,其中包括正常品和残次品,每种残次品的检测图片至少包含一组以上。样本库中的样本越多,学习效果越好,后续的检测也会越准确。
接下来VIDI Suite通过图片样本库进行训练学习,并产生检测的参照模型,这个学习过程只需要不到30分钟,具体学习取决于电脑的硬件配置。
最后即可将VIDI用于实际的检测中。
缺陷案例
图2:缺陷检测案例
如图2所示,软件算法通过一组有代表性的注释图像,以及已知的好样本进行自我训练后,学习系统自动集成上下文信息,形成一个可靠的形状和纹理的模型,用于校对检测。结果显示,之前难以被识别的缺陷,都可以被准确地检测到:撞击和刮伤被视为异常,因为它们有一个纹理区域偏离了预期的设定值,即撞击和刮伤面积超出了容忍偏差。
粗糙金属板
表面缺陷检查的关键挑战之一, 即它们是动态的,这与零部件的加工工艺流程或成形过程有直接关系。当零部件经历了全部的生产步骤,其中部分表面被喷涂油漆,导致抛光表面成为镜面反射光。如图3所示,此时撞击、污渍和划痕这些缺陷才变得可见,并且令人不安。汽车生产厂商完全不能接受这种缺陷产品。
然而,这种只能在工艺末端才能检测到的缺陷,成本非常高昂。利用VIDI红色模块,粗糙材料上典型的缺陷,可以通过任何标准照明和矩阵相机获得的图像检测和分类。训练阶段完成后,在一个标准GPU上计算其能在几毫秒内可靠地识别缺陷,从而实现在线实时检测。
图3:粗糙金属板表面的撞击、污渍和划痕检测实例
结果 & 性能
-
强大的检测:VIDI可以在生产过程的早期阶段,可靠地对复杂纹理的表面、镜面反射和可容忍范围内的异常图像缺陷进行检测和分类。
-
自学习:检测过程无需大量仔细调整和优化的检测算法,而是依赖于一个类似人类的方法——学习和应用,并且具有改进的测试一致性和可重复性。
-
快速&简单:整个学习具有代表性的图片样本库的过程非常高效,其学习时间小于30分钟。
-