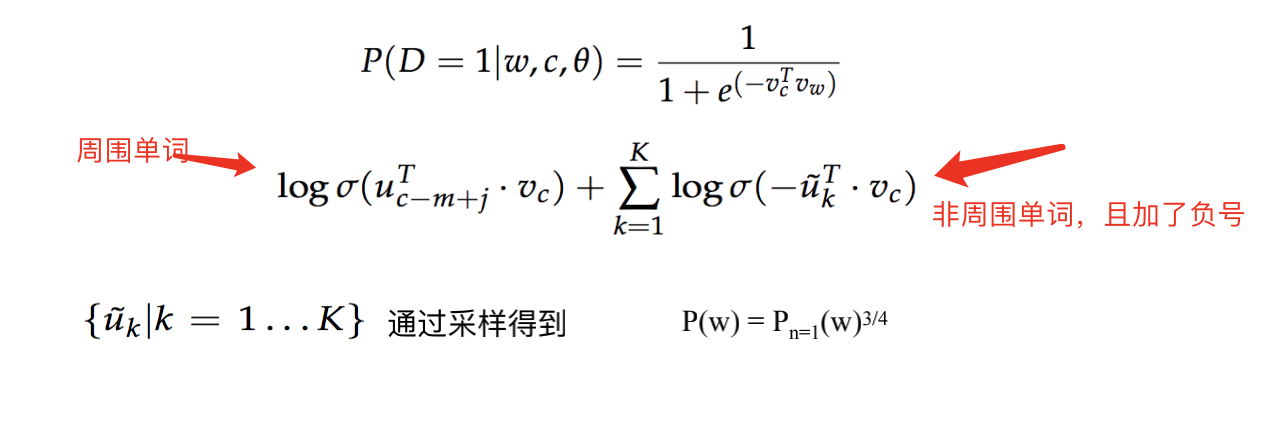词向量训练
一、 实验目的
- 掌握课堂所讲词向量的基本概念和训练方法。
- 加强对pytorch、tensorflow等深度学习框架的使用能力。
二、 实验要求
任选课上讲的一种词向量模型进行实现即可,如是其他模型则请写明模型结构,作业压缩文件中也提供给大家相关的一些论文来进行参考。
三、实验内容
1.数据读取及预处理
中文语料已经分好词了,还需要去掉停用词。

def load_stopwords():with open('data/stopwords.txt','r',encoding="utf-8") as f:return f.read().split("\n")def cut_stopwords(mode):if mode =="zh":stop_words=load_stopwords()with open('data/zh.txt','r',encoding="utf-8") as f:alldata=f.read().split(" ")result=[]for words in alldata:if words not in stop_words:result.append(words)return resultelse:with open('data/en.txt','r',encoding="utf-8") as f:alldata=f.read().split(" ")result=[]for words in alldata:result.append(words)return result
2.训练词向量选择的模型结构cbow及word2vec代码
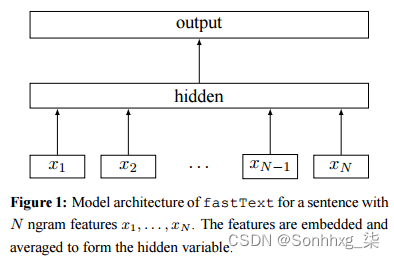
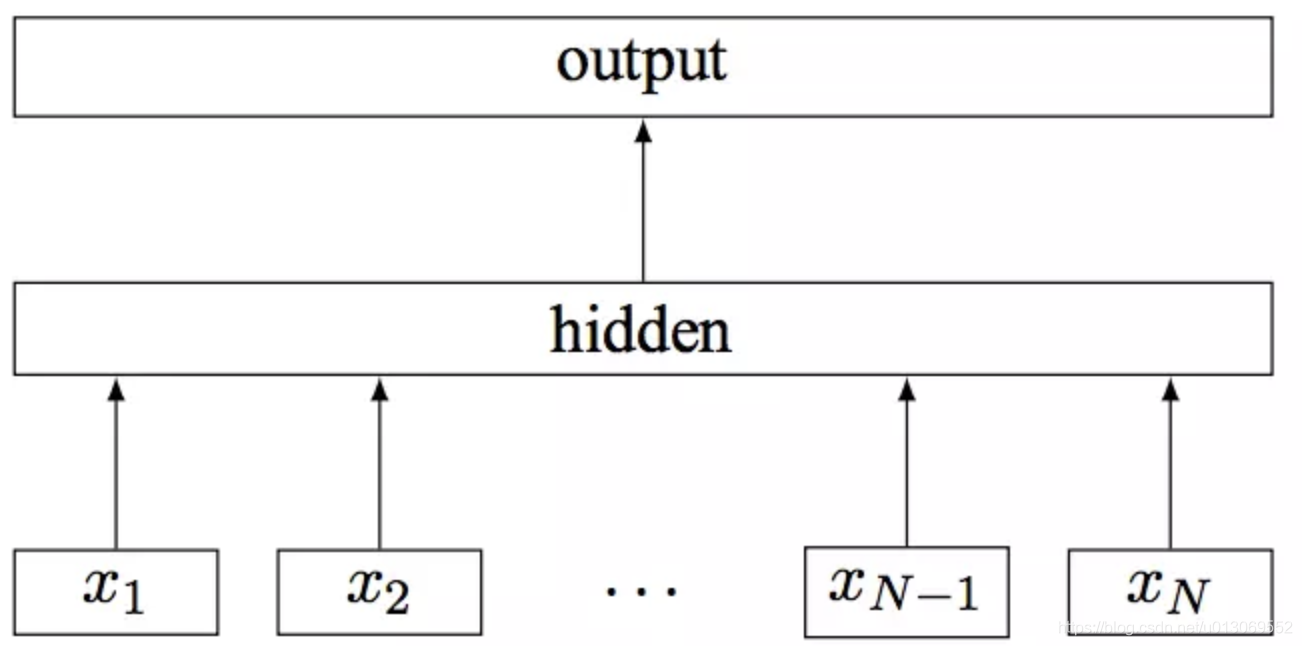
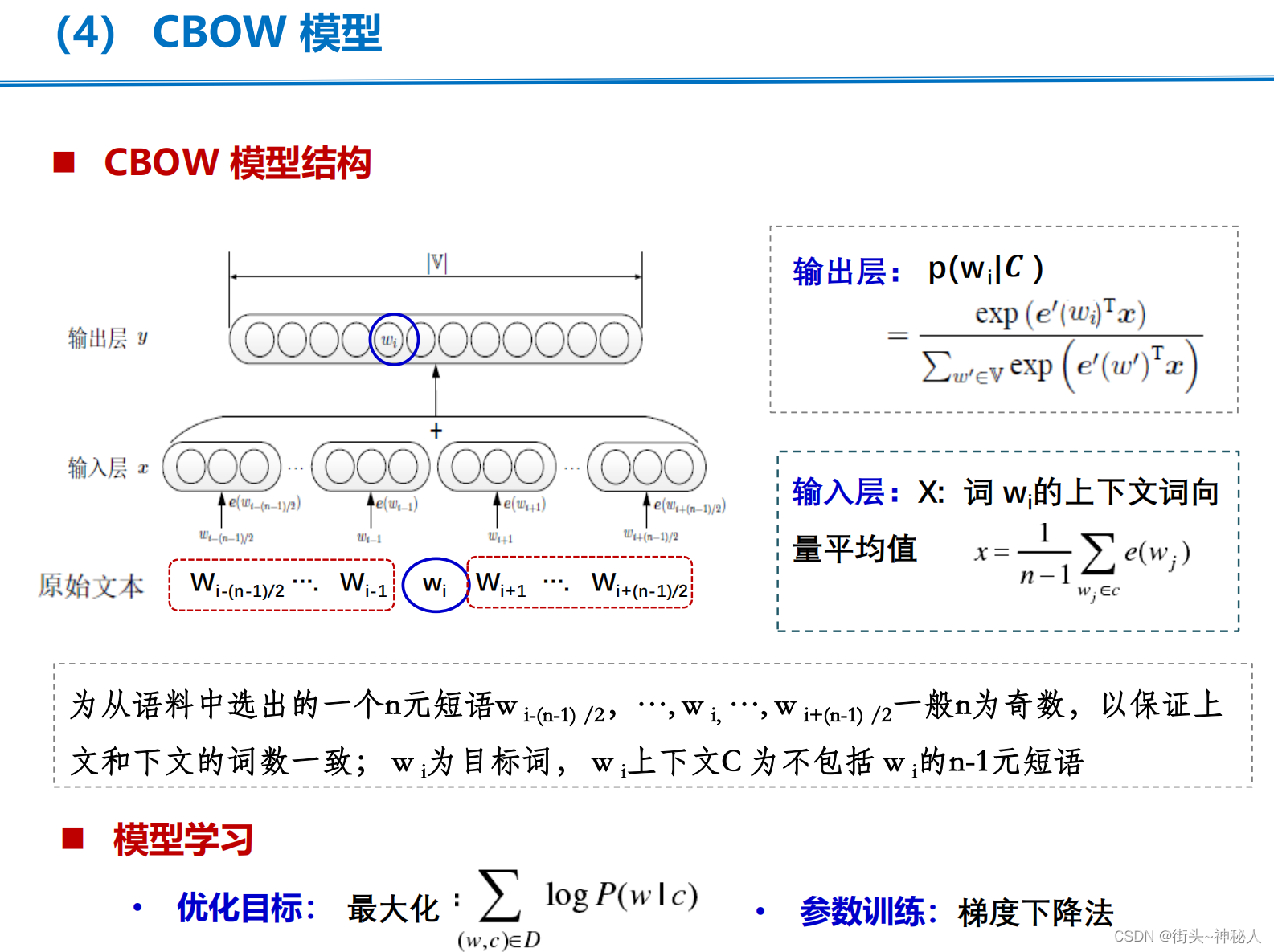
①CBOW结构图
(1)CBOW是通过周围词去预测中心词的模型(skip-gram是用中心词预测周围词)
(2)word-embedding:将高维的词转换为低维的词表示,embedding之后向量中是一些浮点数
②结构代码
import torch.nn as nn
import torch.nn.functional as Fclass CBOW(nn.Module):def __init__(self, duplist_size, embedding_dim):super(CBOW, self).__init__()self.embeddings = nn.Embedding(duplist_size, embedding_dim)self.proj = nn.Linear(embedding_dim, 128)self.output = nn.Linear(128, duplist_size)def forward(self, inputs):embeds = sum(self.embeddings(inputs)).view(1, -1)out = F.relu(self.proj(embeds))out = self.output(out)nllp = F.log_softmax(out, dim=-1)return nllp
第一层embeddings嵌入,然后两层全连接,最后经一个softmax输出。
(1)embeddings输入是词表大小,输出是dim,词向量维度。
(2)第一层全连接输入是词向量维度个结点,输出128个个结点。
(3)第二层全接连输入128个结点,输出词表大小个结点。
(4)最后展平经softmax输出。
③构造词表
需要构造([‘加强’, ‘雨情’, ‘分析’, ‘研究’], ‘水情’,)的标签词表, 类似于滑动窗口中心词前后设为两个词,也就是4。
def pre(mode):data=[]raw_text=cut_stopwords(mode)print(len(raw_text))#词去重dup_list=set(raw_text)dup_list_size=len(dup_list)#转成字典,词对索引和索引对词的word2idx={word: i for i,word in enumerate(dup_list)}idx2word={i: word for i,word in enumerate(dup_list)}#([w1,w2,w4,w5],"label")for i in range(2, len(raw_text) - 2):context = [raw_text[i - 2], raw_text[i - 1],raw_text[i + 1], raw_text[i + 2]]target = raw_text[i]data.append((context, target))return dup_list_size,word2idx,idx2word,data
④训练和测试代码
def train(mode):for epoch in trange(epochs):total_loss = 0for context, target in tqdm(data):# 把训练集的上下文和标签都放到GPU中context_vector = make_context_vector(context, word2idx).to(device)target = torch.tensor([word2idx[target]]).cuda()# print("context_vector=", context_vector)# 梯度清零model.zero_grad()# 开始前向传播train_predict = model(context_vector).cuda() #cudaloss = loss_function(train_predict, target)# 反向传播loss.backward()# 更新参数optimizer.step()total_loss += loss.item()tl=total_loss/len(data)/100losses.append(tl)print("\nlosses=", tl)Weight = model.embeddings.weight.cpu().detach().numpy()print("\n开始测试")test(mode)return Weight
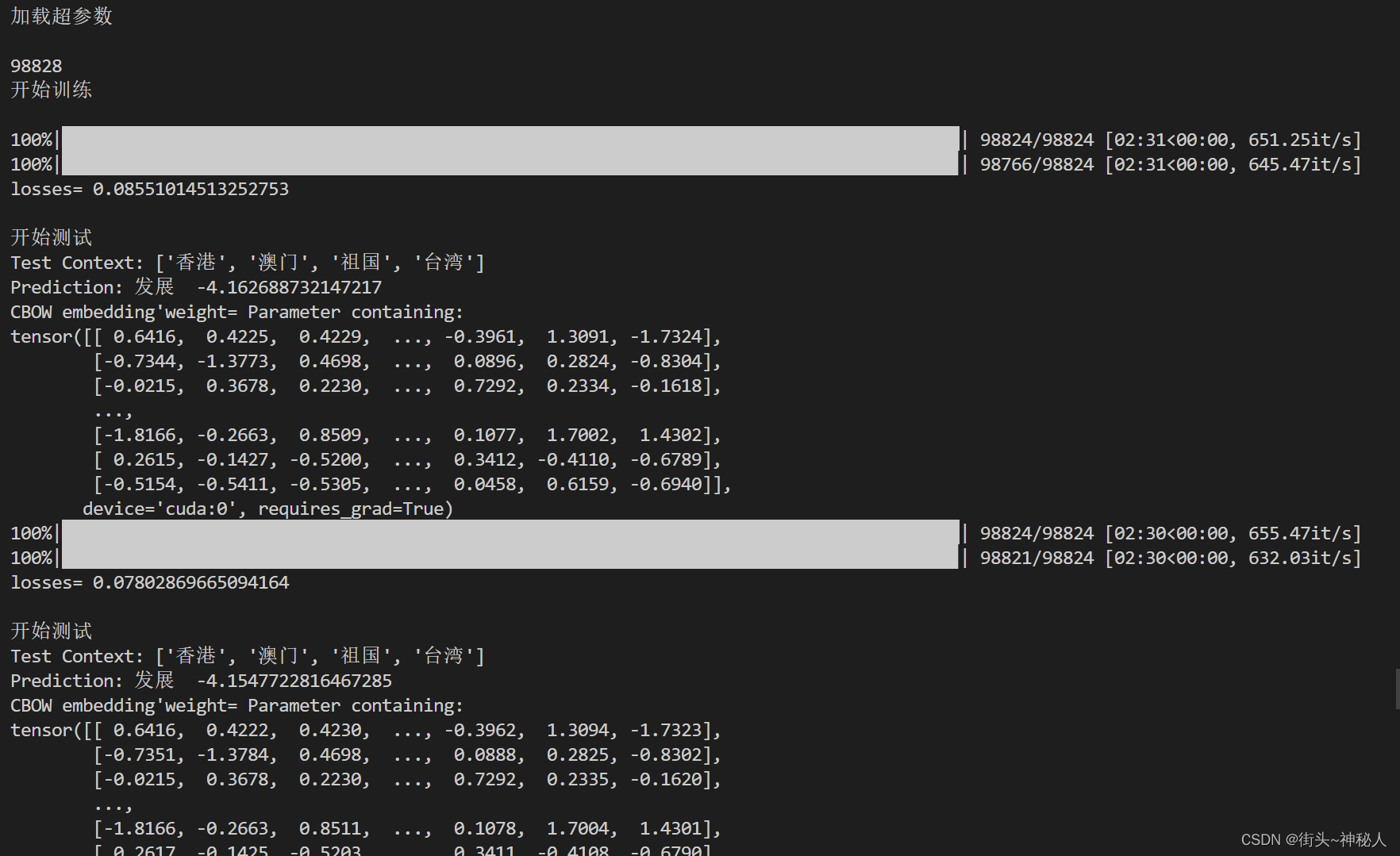
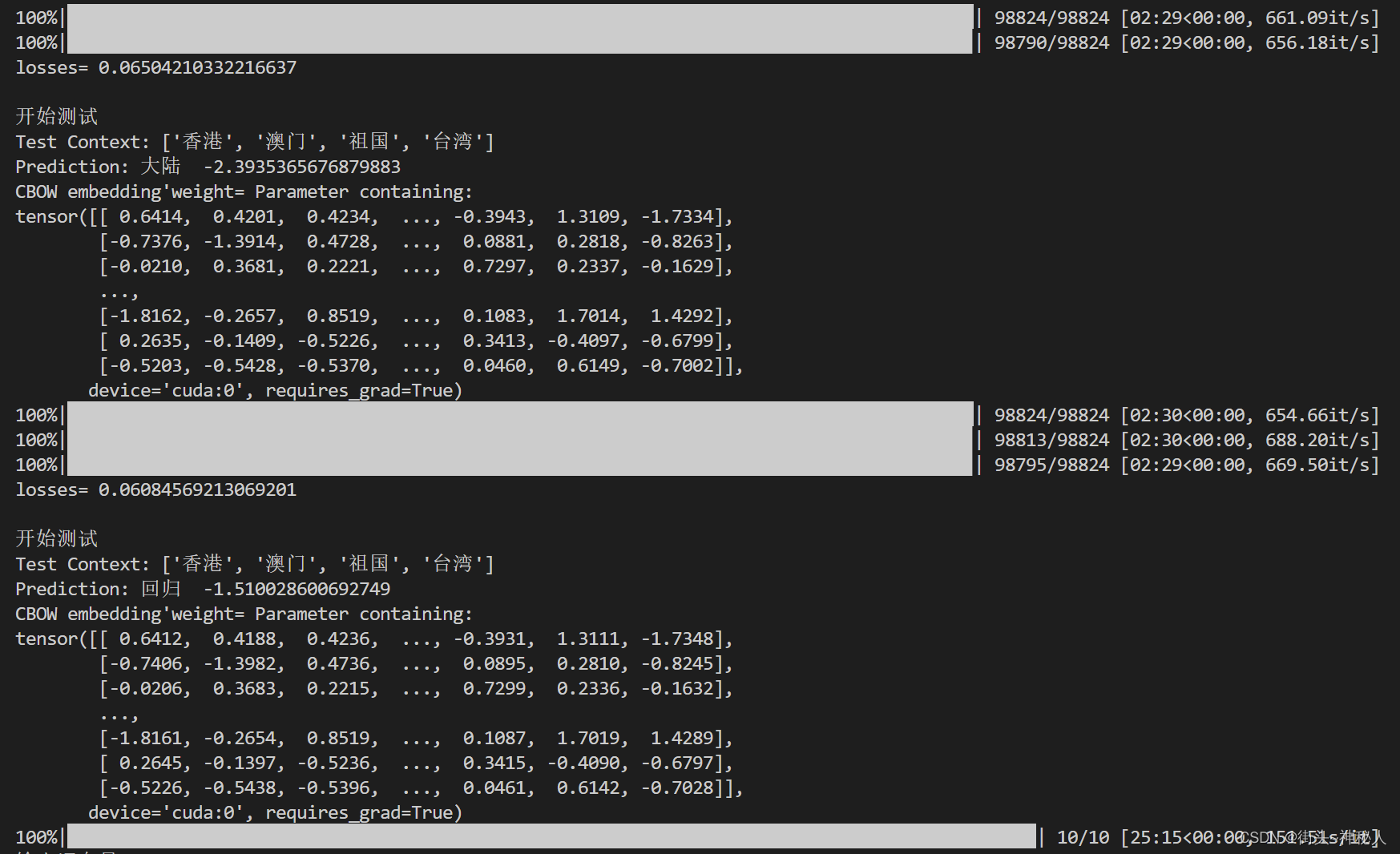
def test(mode):if mode =="zh":context = ['香港', '澳门', '祖国', '台湾']else: context = ['helping', 'western', 'restore', 'its']context_vector = make_context_vector(context, word2idx).to(device)predict = model(context_vector).cpu().detach().numpy() # 预测的值print('Test Context: {}'.format(context))max_idx = np.argmax(predict) # 返回最大值索引print('Prediction: {} {}'.format(idx2word[max_idx],np.max(predict))) # 输出预测的值print("CBOW embedding'weight=", model.embeddings.weight) #获取词向量Embedding
训练10个epoch,每个epoch都进行测试,测试用例为[‘香港’, ‘澳门’, ‘祖国’, ‘台湾’],原文中间词为回归,在第10个epoch时训练的权重预测到中心词为回归。
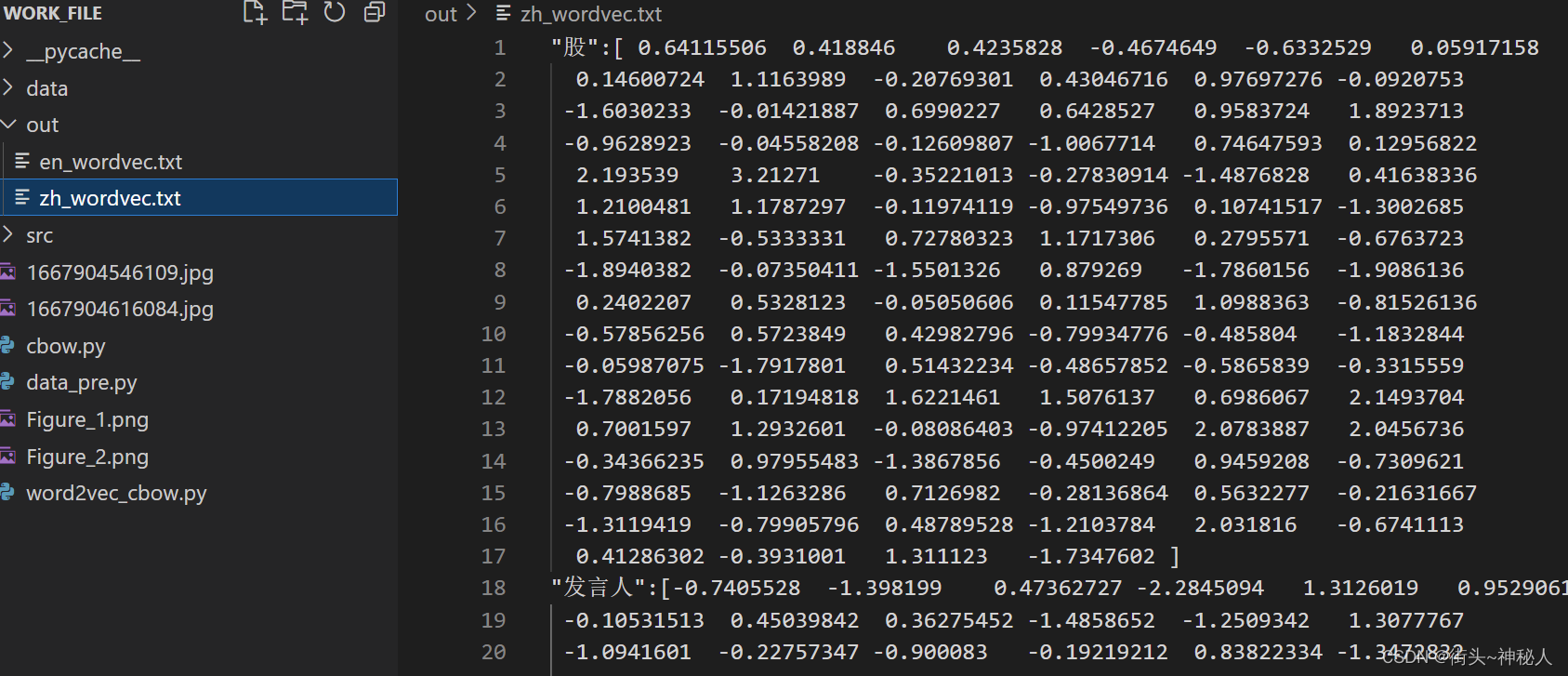
⑤输出词向量
每个词向量用100维的float数表示
def out(Weight,mode):#{单词1:词向量1,单词2:词向量2...}word2vec = {} for word in word2idx.keys():word2vec[word] = Weight[word2idx[word], :] #词向量矩阵中某个词的索引所对应的那一列即为所该词的词向量# 将生成的字典写入到文件中if mode == "zh":with open("out/zh_wordvec.txt", 'w', encoding='utf-8') as f: #中文字符集要设置为utf-8,不然会乱码for key in word2idx.keys():f.writelines('"' + str(key) + '":' + str(word2vec[key]))f.write('\n')f.write('\n')else:with open("out/en_wordvec.txt", 'w') as f:for key in word2idx.keys():f.writelines('"' + str(key) + '":' + str(word2vec[key]))f.write('\n')f.write('\n')print("out over")
⑥词向量可视化,PCA降维
def show(W,mode): # 将词向量降成二维绘图pca = PCA(n_components=2) # 数据降维principalComponents = pca.fit_transform(W)word2ReduceDimensionVec = {} #{单词1:(维度一,维度二),单词2:(维度一,维度二)...}for word in word2idx.keys():word2ReduceDimensionVec[word] = principalComponents[word2idx[word], :]plt.figure(figsize=(20, 20)) # 将词向量可视化count = 0if mode=="zh":for word, wordvec in word2ReduceDimensionVec.items():if count < 100:plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号,否则负号会显示成方块plt.scatter(wordvec[0], wordvec[1])plt.annotate(word, (wordvec[0], wordvec[1]))count += 1else:for word, wordvec in word2ReduceDimensionVec.items():if count < 100: # 只画出100个plt.scatter(wordvec[0], wordvec[1])plt.annotate(word, (wordvec[0], wordvec[1]))count += 1plt.show()
3.程序模块
四、问题和思考
1.词向量?

2.word2vec?
word2vec是一种将word转为向量的方法,其包含两种算法,分别是skip-gram和CBOW,它们的最大区别是skip-gram是通过中心词去预测中心词周围的词,而CBOW是通过周围的词去预测中心词。