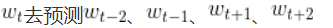利用word2vec训练词向量
这里的代码是在pycharm上运行的,文件列表如下:
一、数据预处理
我选用的数据集是新闻数据集一共有五千条新闻数据,一共有四个维度
数据集:https://pan.baidu.com/s/1ewzlU_tBnuwZQxVOKO8ZiA 提取码: mei3

首先我们要把我们需要的数据给提取出来,这里我们将数据集里的所有新闻提取出来,并对其进行分词,再删除停用词
(分词的原因是因为我们要训练词向量,那用于做训练的数据就应该是一个个词,而不是现成的文本)
import pandas as pd
import jieba#读取数据集
new_data = pd.read_table("./data/new_data.txt",names=['label', 'theme', 'URL', 'content'],encoding='UTF-8')
new_data = new_data.dropna() #删除数据集中的缺失值#提取我们需要的文本数据
content = new_data["content"].values.tolist()#对文本数据进行分词
content_S = []
for text in content:cut_content = jieba.lcut(text)if len(cut_content) > 1 and cut_content != '\r\n':content_S.append(cut_content)#删除停用词
stopwords = pd.read_csv("./data/stopwords.txt",sep='t', quoting = 3, names = ["stopwords"], encoding='UTF-8')
stopwords = stopwords.stopwords.values.tolist()#该方法用于删除停用词
def drop_stopwords(contents, stopwords):content_clearn = []for line in contents:line_clearn = []for word in line:if word in stopwords:continueline_clearn.append(word)content_clearn.append(line_clearn)return content_clearncontent_clearn = drop_stopwords(content_S, stopwords)上面我们已经把我们的文本数据处理完了,接下来我们把处理好的文本写入文件
一定要养成把处理过的数据集写入文件的习惯,不然每次重新运行太浪费时间了。
f = open("./data/text.txt","w",encoding="UTF-8")
for line in content_clearn:for word in line:f.write(word + ' ')
f.close()
二、模型训练
这里用到的模型是word2vec,使用之前建议去了解一下这个模型的底层原理,这里奉上用到的模型参数.
| 参数 | 作用 |
|---|---|
| sg=0 | 使用CBOW |
| size | 向量维度 |
| window | windowsize |
| min_count=5 | 最小出现次数 |
| workers | 线程数 |
| epoch | 训练次数 |
再次强烈建议使用模型之前一定要了解它的原理,不然你连参数都调不明白
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import logginglogging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)def tarin_function():new_data = open('./data/text.txt', "r",encoding='UTF-8') #r 只读model = Word2Vec(LineSentence(new_data),sg=0, size=192, window=5, min_count=5, workers=9)model.save('new_data.word2vec')#训练完词向量记得保存,不会吧 不会真的有人训练完不保存吧if __name__ == '__main__':tarin_function()
三、利用词向量计算词语之间的相似度
这里我们用我们刚才训练好的词向量分别计算了 销售 与 促销 和香蕉的相似度,之后又找出了10个跟"销售"相似度最大的词
#计算词与词之间的相似度
import gensim.models
from gensim.models import Word2Vecmodel = gensim.models.Word2Vec.load("new_data.word2vec")
print(model.similarity("销售","促销")) #0.80
print(model.similarity("销售","香蕉")) #0.46#与销售最相近的十个词
word = "销售"
if word in model.wv.index2word:print(model.most_similar(word))
这里要特别说明一下,最好选测试数据集中存在的词语,因为这个数据集太小了,训练出来的词向量效果很差,训练出好的词向量需要非常庞大的数据集,由于本人电脑实在拉跨(MX150了解一下),维基百科的数据集跑不下来,所以就选用了这个数据集,有条件的,最好用更庞大的数据集,这里奉上维基百科中文网页的数据集地址:
https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
用这个数据集训练之前记得处理一下数据集
啊对了 我这里有处理过的可以直接拿来训练模型的数据集,下载链接如下:
数据集:https://pan.baidu.com/s/1hTkj0i9iZCYljvfDWiMbug 提取码:9yvm
(要不是我电脑算力不够,我就直接把我训练好的词向量传上来。。。。。。)
希望算力雄厚的你能帮我跑一下
四、利用训练好的word2vec计算新闻之间的相似度
首先说一下wodrd2vec计算文章相似度的流程
- 提取关键词
- 关键词向量化
- 计算关键词之间的相似度
这里选用的数据是两条财经类的新闻,和一条汽车类的新闻。 首先分别提取这三条新闻的关键词
from jieba import analyse#提取句子的关键词
def keyword_extract(data, file_name):tfidf = analyse.extract_tagskeywords = tfidf(data)return keywords#将文档中的每句话进行关键词提取
def getKeywords(docpath, savepath):with open(docpath, 'r',encoding='UTF-8') as docf, open(savepath, 'w',encoding='UTF-8') as outf:for data in docf:data = data[:len(data)-1]keywords = keyword_extract(data, savepath)for word in keywords:outf.write(word + ' ')outf.write('\n')
方法写好了,接下来我们提取新闻中的关键词
if __name__ == '__main__':new1 = './data/new1.txt'new2 = './data/new2.txt'new3 = './data/new3.txt'new1_keywords = './data/new1_keywords.txt'new2_keywords = './data/new2_keywords.txt'new3_keywords = './data/new3_keywords.txt'getKeywords(new1, new1_keywords) # 返回new1的关键词getKeywords(new2, new2_keywords) # 返回new2的关键词getKeywords(new3, new3_keywords) # 返回new3的关键词
关键词提取完了,接下来就是求关键词对应的词向量了,这里我选的新闻本身就是训练集里的,所以它的词向量我们的都已经训练出来了,不必担心找不到。(竟然有人拿训练集里的数据测试模型,不会吧,不会吧,这不是测试了个寂寞么)还是建议有条件的把那个维基百科的数据集跑出来,然后用一些数据集里没有数据来测试。
import codecs
import numpy
import gensim
import numpy as np
from keyword_extract import *wordvec_size=192
def get_char_pos(string,char):chPos=[]try:chPos=list(((pos) for pos,val in enumerate(string) if(val == char)))except:passreturn chPos#从text文件中读取关键词,利用之前训练好的词向量获取关键词的词向量
def word2vec(file_name,model):with codecs.open(file_name, 'r',encoding='UTF-8') as f:word_vec_all = numpy.zeros(wordvec_size)for data in f:space_pos = get_char_pos(data, ' ')first_word=data[0:space_pos[0]]if model.__contains__(first_word):word_vec_all= word_vec_all+model[first_word]for i in range(len(space_pos) - 1):word = data[space_pos[i]:space_pos[i + 1]]if model.__contains__(word):word_vec_all = word_vec_all+model[word]return word_vec_all#通过余弦相似度计算两个向量之间的相似度
def simlarityCalu(vector1,vector2):vector1Mod=np.sqrt(vector1.dot(vector1))vector2Mod=np.sqrt(vector2.dot(vector2))if vector2Mod!=0 and vector1Mod!=0:simlarity=(vector1.dot(vector2))/(vector1Mod*vector2Mod)else:simlarity=0return simlarity接下来进行测试
if __name__ == '__main__':model = gensim.models.Word2Vec.load('new_data.word2vec')new1_keywords = './data/new1_keywords.txt'new2_keywords = './data/new2_keywords.txt'new3_keywords = './data/new3_keywords.txt'new1_vec=word2vec(new1_keywords,model)new2_vec=word2vec(new2_keywords,model)new3_vec=word2vec(new3_keywords,model)print(simlarityCalu(new1_vec,new2_vec)) #0.98print(simlarityCalu(new1_vec,new3_vec)) #0.56
这里计算出这两条财经新闻的相似度是0.98,而第一条财经新闻与汽车新闻的相似度只有0.56
参考:《Python自然语言处理实战核心技术与算法》作者 刘祥,刘树春 涂铭