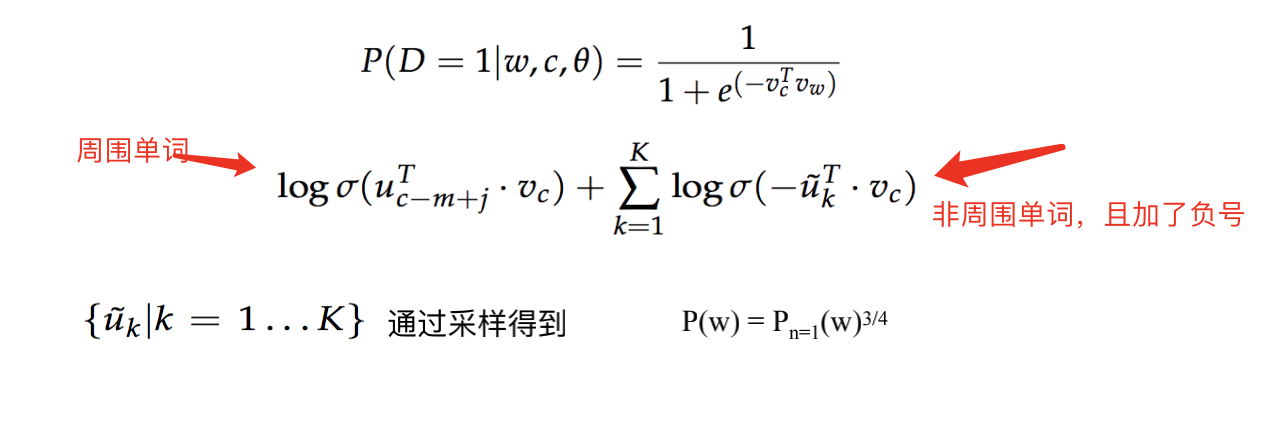关键字:
文档 句子 词语
单词 上下文单词 上下文窗口
向量 相似性 类比性 欧几距离 余弦距离 余弦相似度 相似度阀值
归于此类 创建新的类别
词向量 --- word2vec、glove
相似度 --- 欧几距离、余弦距离
聚类 --- kmeans
+、词向量
是指将词转化成为稠密向量,并且对于相似的词,其对应的词向量也相近
1、离散表示(one-hot representation)
传统的基于规则或基于统计的自然语义处理方法将单词看作一个原子符号
被称作one-hot representation。one-hot representation把每个词表示为一个长向量。这个向量的维度是词表大小,向量中只有一个维度的值为1,其余维度为0,这个维度就代表了当前的词。
例如:
苹果 [0,0,0,1,0,0,0,0,0,……]
one-hot representation相当于给每个词分配一个id,这就导致这种表示方式不能展示词与词之间的关系。另外,one-hot representation将会导致特征空间非常大,但也带来一个好处,就是在高维空间中,很多应用任务线性可分。
2、分布式表示(distribution representation)
word embedding指的是将词转化成一种分布式表示,又称词向量。分布式表示将词表示成一个 定长的 连续的 稠密向量。
分布式表示优点:
(1) 词之间存在相似关系:
是词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。
(2) 包含更多信息:
词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
+、词向量生成算法
1、基于统计 - 共现矩阵
通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数作为当前word的vector。

矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
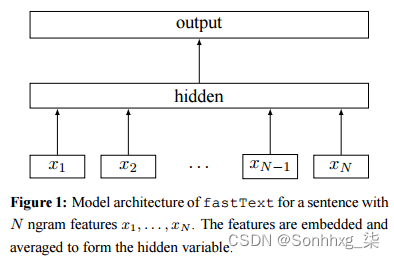
2、语言模型 - NNLM -> Word2Vec -> Glove -> Seq2Seq -> Seq2Seq With Attention -> ELMo -> GPT -> Bert
语言模型生成词向量是通过训练神经网络语言模型NNLM(neural network language model),词向量作为语言模型的附带产出。NNLM背后的基本思想是对出现在上下文环境里的词进行预测,这种对上下文环境的预测本质上也是一种对共现统计特征的学习。
2.1、Word2Vec
基本出发点是上下文相似的两个词,它们的词向量也应该相似,比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似。
只关心模型训练完后的副产物:词向量矩阵
word2vec模型中比较重要的概念是词的上下文,说白了就是一个词周围的词,比如wt的范围(即窗口)为1的上下文就是wt−1和wt+1。
word2vec模式下的两个模型:CBOW 和 SkipGram
CBOW(Continuous Bag-of-Word):以上下文词汇预测当前词,即用 ![]()
SkipGram:以当前词预测其上下文词汇,即用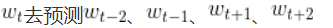
如何通俗理解word2vec_结构之法 算法之道-CSDN博客_word2vec
2.2、GloVe - Global Vectors for word Respresentation
一个基于全局词频统计的词表征,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。
斯坦福设计的一个新的词向量算法,结合了词频和词嵌入词向量计算的优点。
GloVe 教程之实战入门+python gensim 词向量_sscssz的博客-CSDN博客_glove python
2.3、BERT
BERT是一个预训练的模型,用于创建NLP从业人员可以免费下载和使用的模型。
使用BERT从文本数据中提取特征,即单词和句子的嵌入向量。
BERT生成的单词表示是由单词周围的单词动态通知的。
BERT中的词向量指南,非常的全面,非常的干货_AI公园-CSDN博客