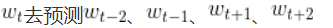本篇博客是对于
https://www.cnblogs.com/nickchen121/p/15105048.html#%E7%AC%AC%E4%B8%80%E7%AF%87-transformergptbert%E9%A2%84%E8%AE%AD%E7%BB%83%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E7%9A%84%E5%89%8D%E4%B8%96%E4%BB%8A%E7%94%9F%E7%90%86%E8%AE%BA
的归纳
先来了解一下什么是预训练
预训练的概念开始存在于图片领域

如果有一个比较大的模型,训练了各式各样的图片,他的约浅层拥有一个越通用的特征。而深层拥有比较特殊的特征。浅层的特征可以通用,深层的特征不能通用。
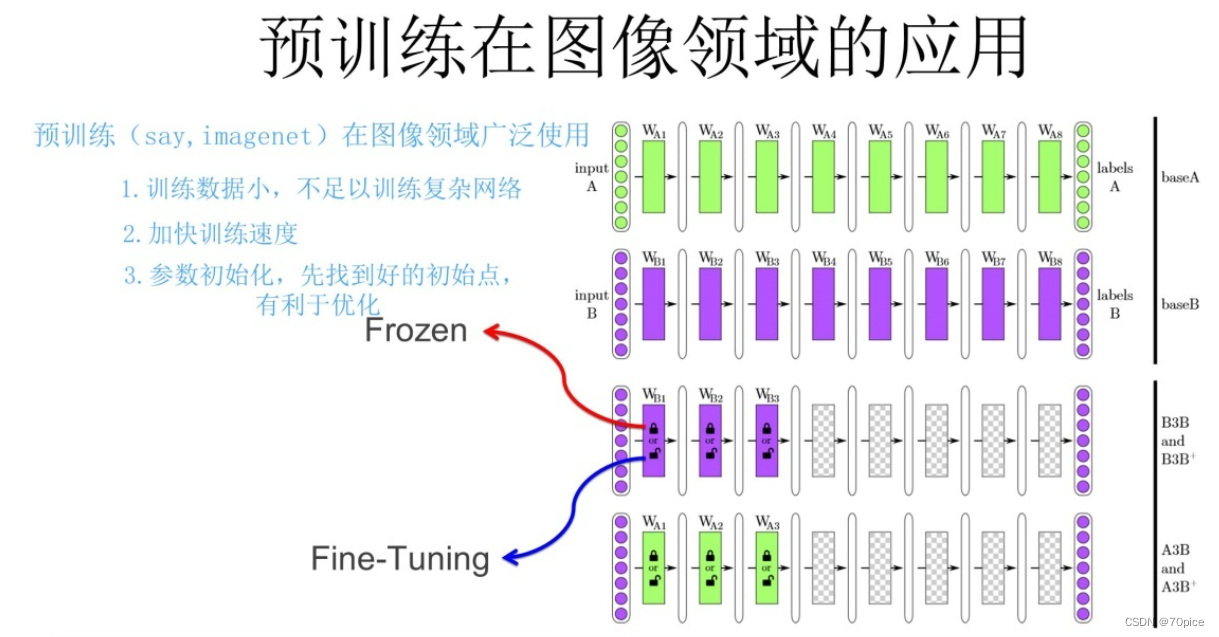
因此诞生了两种使用这种浅层参数的方法,分别是
- 冻结(少用):深层参数随机初始化,浅层参数不变
- 微调(主用):深层参数随机初始化,浅层参数参与训练,会发生改变
语言模型
其实bert gpt,本质上是一个语言模型。只不过他们是基于深度学习的语言模型。那么要了解bert、gpt基于深度学习的语言模型,那么你就要先了解什么是语言模型。
语言模型是一个计算成句概率的模型。他主要由两个作用
- 预测下一个词
- 判断成句概率
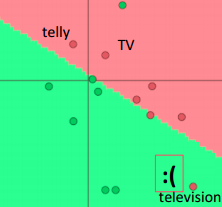
例子:判断一个词的词性
分词后变成 判断 一个 词 的 词性
预测下一个词
首先要明白什么是概率论中的链式法则
P(w1w2) = P(w1) * P(w1|w2)
P(w1w2w3…wn) = P(w1)*P(w1|w2)*P(w3|w1w2)
这就是语言模型
所以 判断 一个 词 的 词性
概率大于 判断 一个 词 的 火星
因为P(abcde)比较大
如果是判断成句概率同理
P(w1w2w3…wn)也比较大
但是最如果用全元模型,计算计算量太大了。因此考虑用n元模型
语言模型,统计语言模型了解之后,再来了解一下什么是
神经网络语言模型
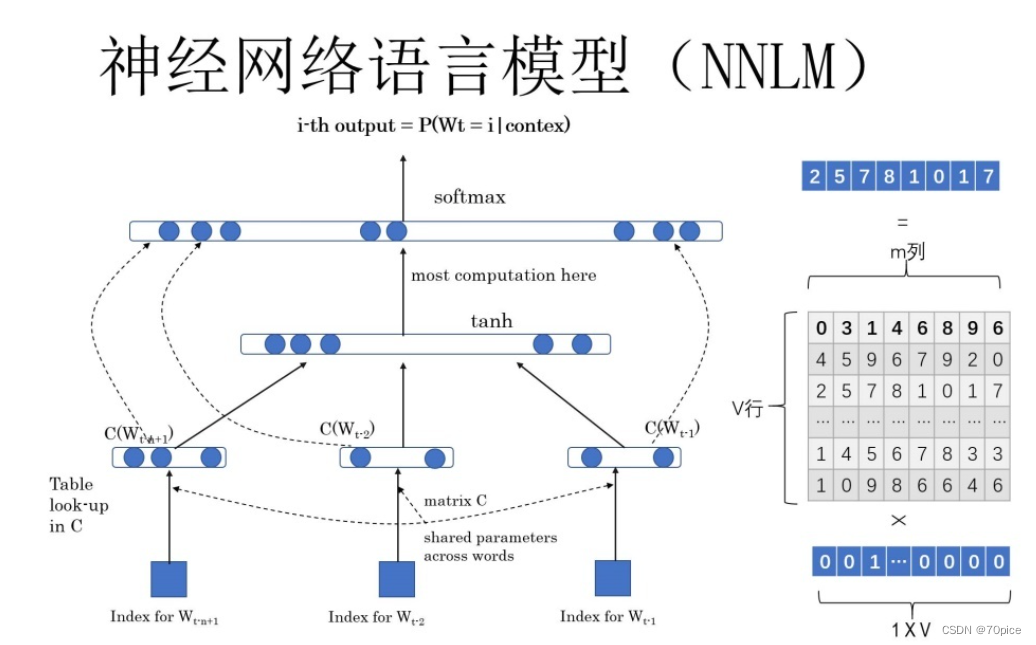
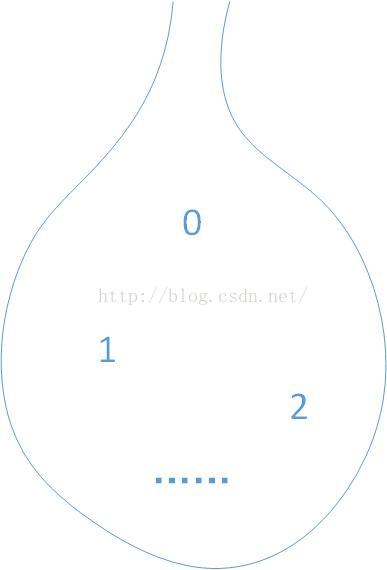
输入的第一层是一个one-hot编码,我们假设它是1 * 7 (有七个字)
里面的输入矩阵为 7 * 7,那么隐藏层,1 * 7,汇集了这些信息之后,最后输出的矩阵为1 * 7的矩阵。表示为这七个字中,谁有可能出现在下一个词
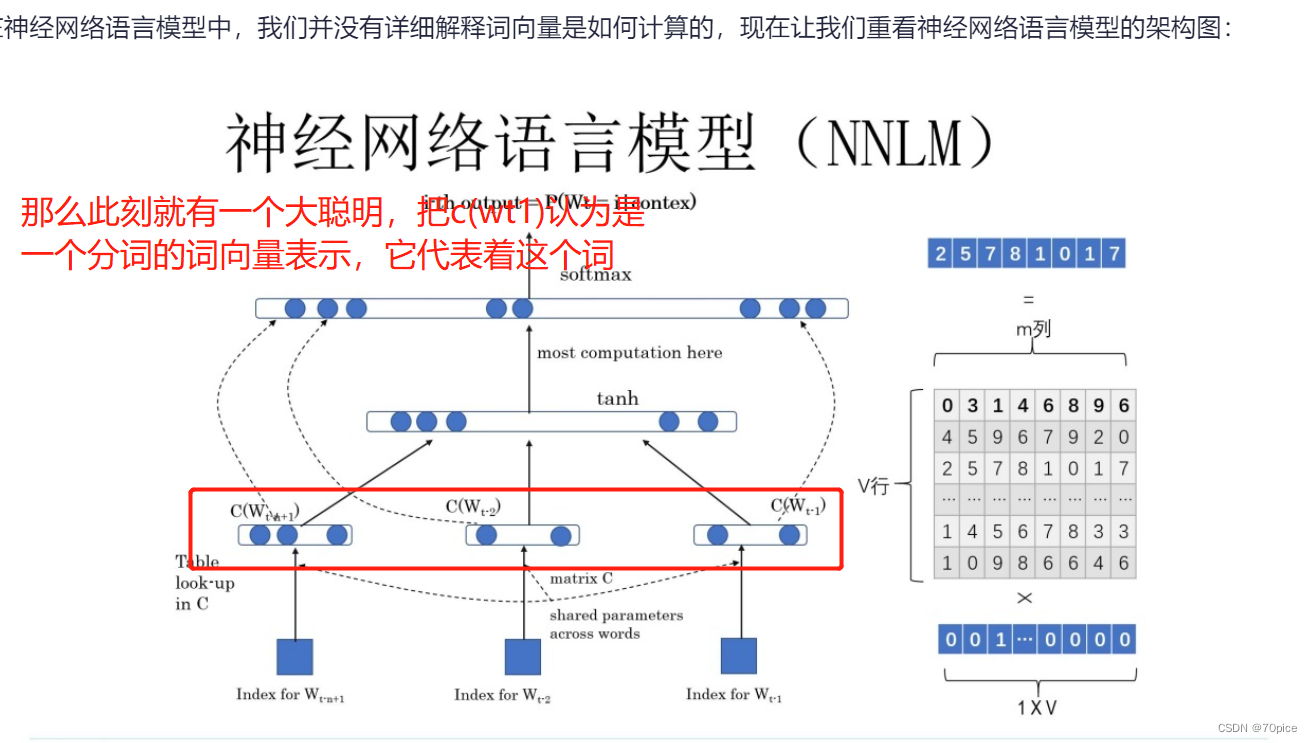
这个词向量表示,岂不是可以把一个一个词表示的更加精确?
由此但是了Word2Vec这个研究
Word2Vec分为
CBOW
Skip-gram
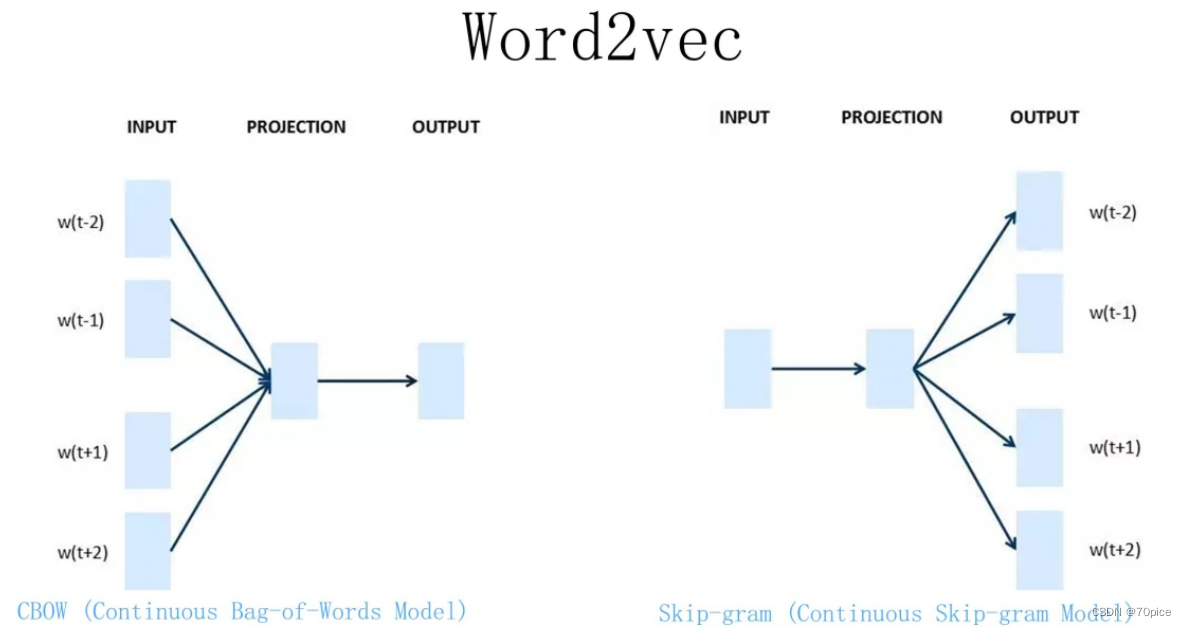
注意他们的核心思想是得到这个Q矩阵,
假设one-hot是c
c * Q = W(词向量矩阵)
他的核心不是想去处理得到一个任务。他的核心是想更加精确的表示一个词。
CBOW是通过一上下文去预测一个词(和Bert的思想就很接近了)
Skip是同一过一个词去预测上下文
那么这种Word Embedding算的上是一种预训练模型吗?
怎么不算,在每一个下游任务之前,是不是要先把词语转化成词向量,用词向量表示一个词。那么,那么是不是可以通过这个Q矩阵去做这个事情