说在前头:本篇文章主要是记录这次项目的过程,不全是贴代码,具体的程序移步这里,不喜欢的同学请轻喷。
事件起因:大三狗一枚,专业是软件应用。这学期的中级软件设计实作题目是实现一个小型的数据库,具体的题目要求如下:
建立一个类似Oracle\SQL Server的小型数据库系统:
- 可建立表,表有字段、类型
- 表中可通过SQL语句填入数据(只能是特定类型)和查询数据;
- 对主键字段,应自动建立索引;
- 当进行查询时,在主键上应是基于索引的高效查询,而不能是字符串匹配这样的原始查询。
觉得题目似曾相识的同学,应该猜到我是哪所大学的了吧。一番Google、百度下来,最终确定了实现成一个Android的应用,毕竟这学期刚学的Android,这知识还滚烫着呢,而且Android的各种框架已经很成熟了,不用重复造轮子了。
前期准备:既然需求已经如此明确,接下来就是进行界面设计。然而自己并没有高大上的审美,也没有美术的基础,所以并不敢有太高的要求,但是业务逻辑要通顺,其他只能说长得不丑就行了。我用的是Mac系统下的一个Sketch的软件绘制的原型图,在这里就不贴出来了,具体的应用界面下面有。
接下来就是技术准备了,实现一个小型数据库,我总结了以下几点主要的技术难点:
- 首先是主流数据库系统的实现原理;我主要参看了以下链接的内容:数据库的最简单实现、数据库索引的实现原理、为什么要用B+树结构——MySQL索引结构的实现等等技术博客,感谢各位无私奉献的大牛们~
- 其次也是最难的部分是B+树,当前的很多数据库系统都是用B+树。关于B+树的总结,可以参看我的另一篇博客。
- 最后就是Android的相关知识。这个需要长期的积累,遇到不会的我都会Google,或者查看技术博客,stackoverflow,github等等也有很多轮子可以直接用。
实际编码:终于来到真正的打大怪阶段了。这一部分内容我直接按界面(Activity)进行划分。
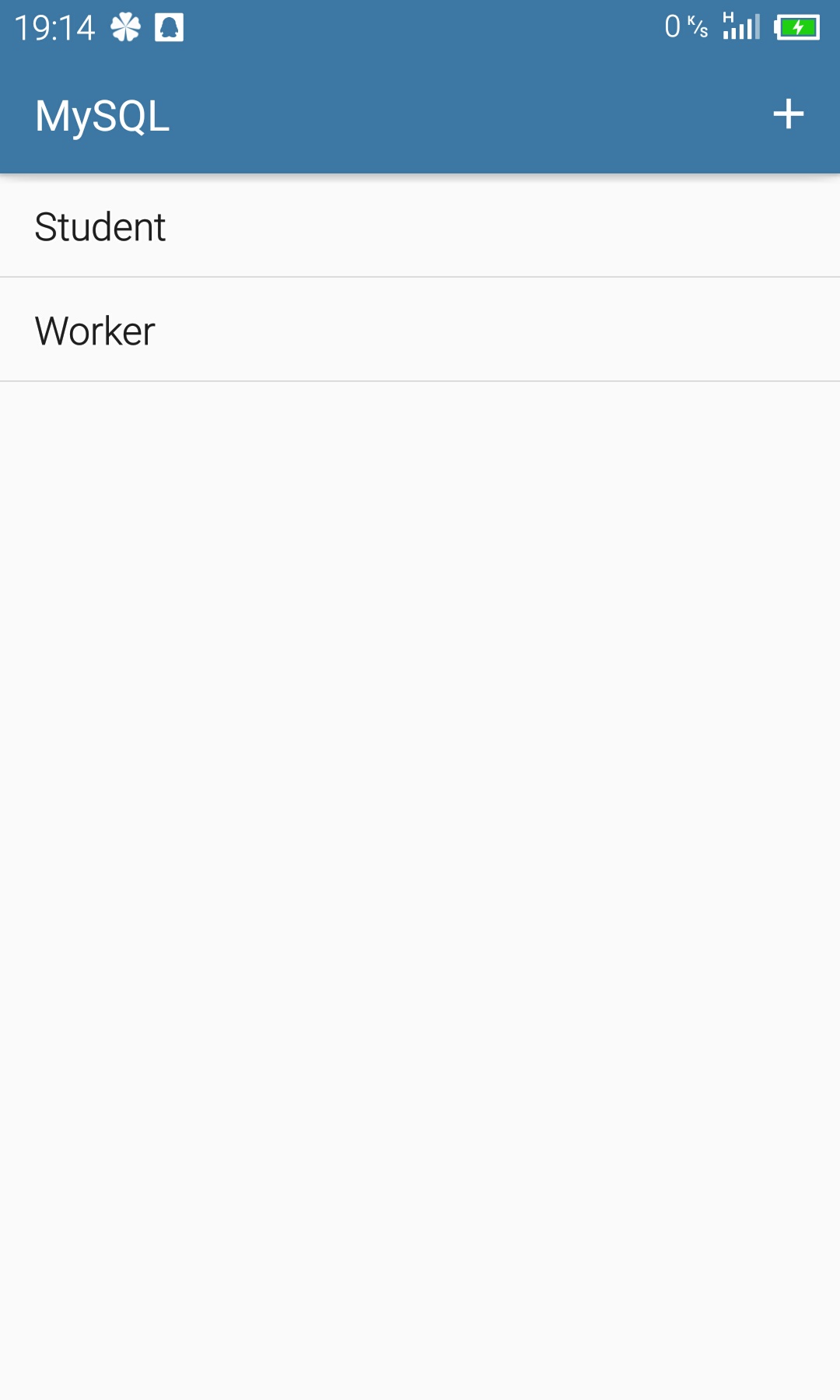
- 主界面(Main Activity):首先是界面展示
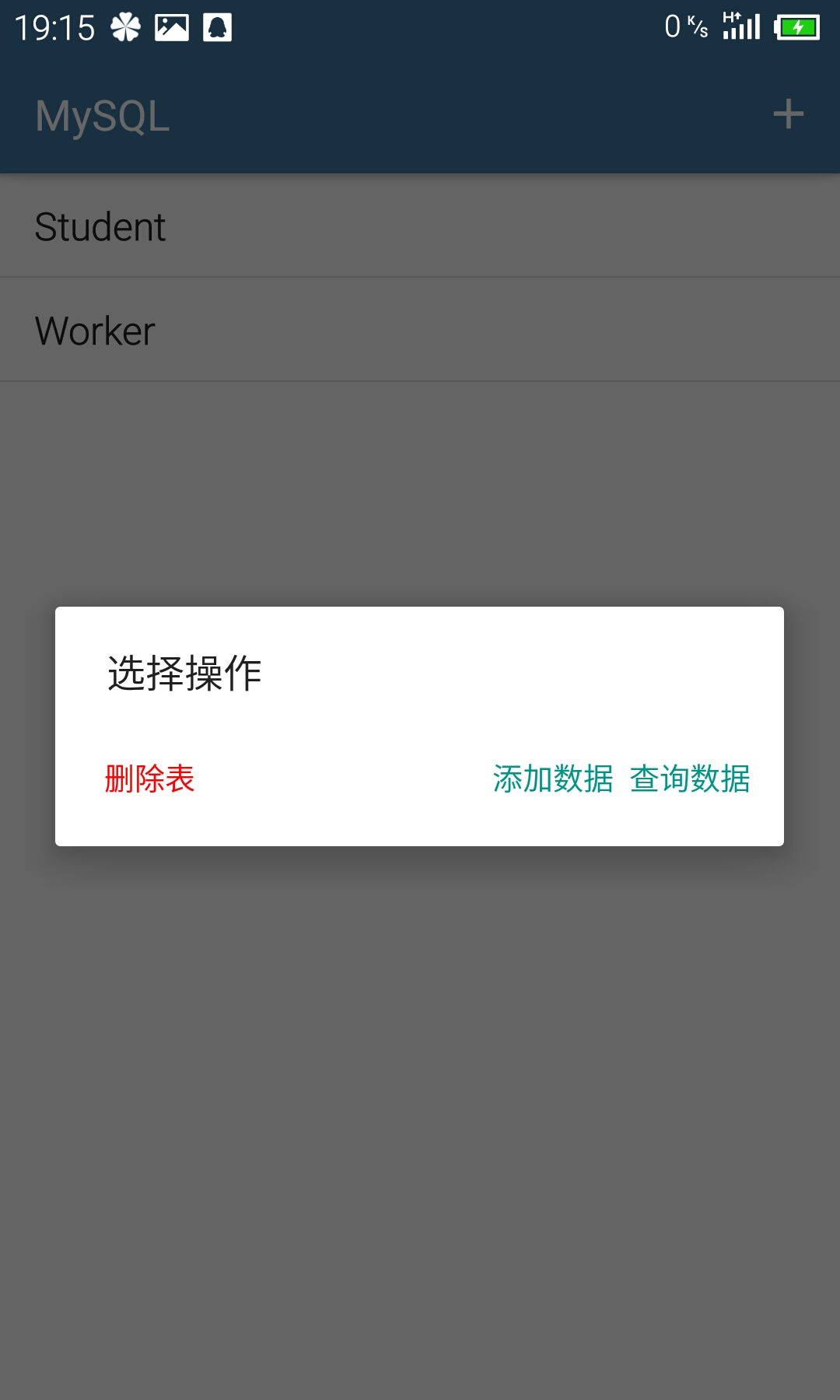
主界面上就是所有已经建好的表的列表,点击列表项则弹出对话框进行删除表、添加数据、查询数据操作,这三个操作具体实现在后面会详细说;其次右上角是新建表的按钮,点击跳转到对应的界面。主界面逻辑都很简单,值得一提的是刷新列表的操作我是放在onResume函数中,所以每次进入主界面就会刷新列表。代码片段如下:
@Override
protected void onResume()
{super.onResume();refreshSharedPreferencesList(); // 刷新列表
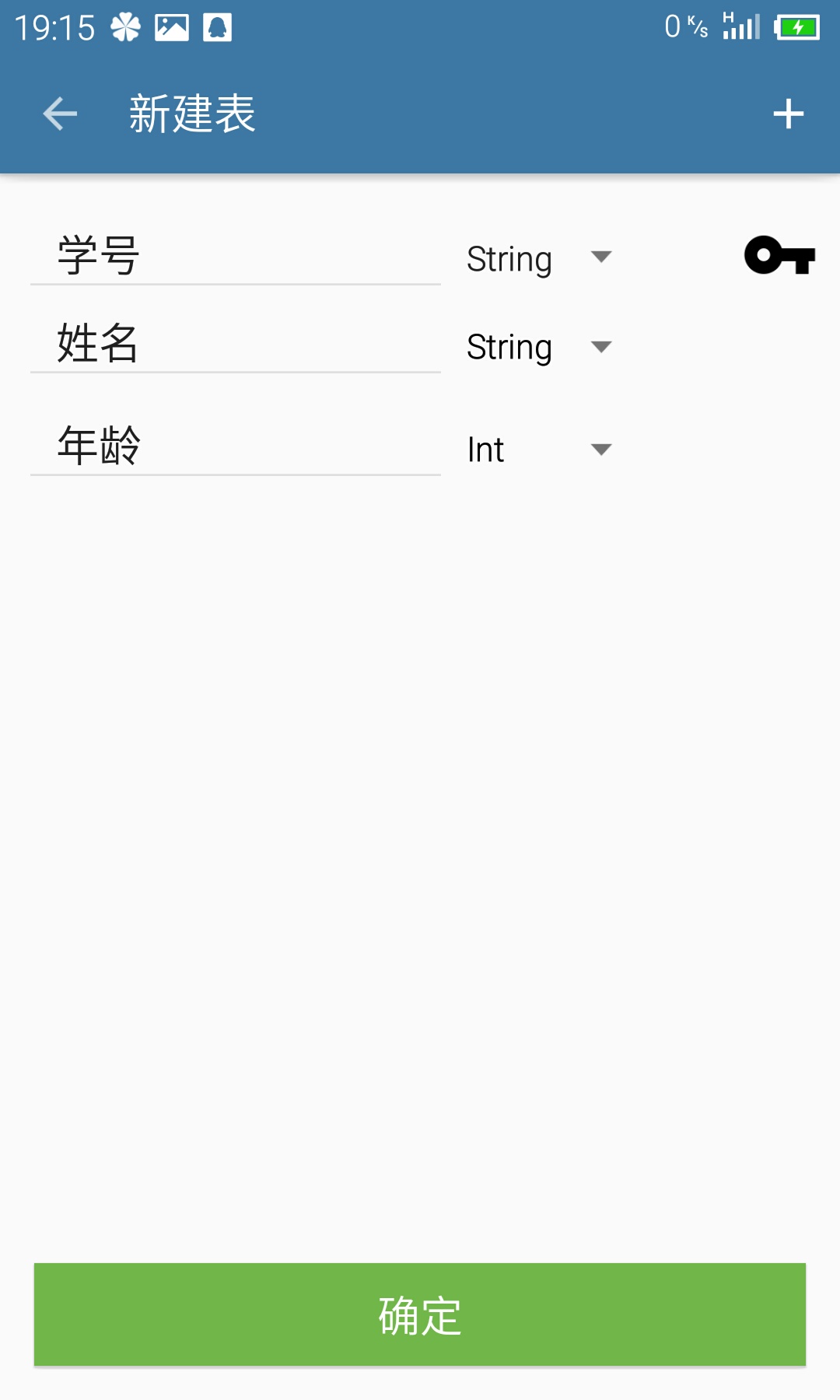
}- 新建表界面(AddTable Activity):界面展示如下:
界面上一个是编辑框输入字段名,一个是对应数据类型的下拉列表,填好一个字段信息后按右上角的”+”按钮再生成一对新的字段名框和类型列表,所有的编辑框和下拉列表保存在ArrayList中,且默认第一个是主键,最后按下面的确定按钮新建表。
考虑到数据量小,而且是键值对应的形式,我将表的信息保存SharedPreference中,以用户输入的表名命名该文件。相关代码如下:
private List<EditText> editTextList = new ArrayList<>();
private List<Spinner> spinnerList = new ArrayList<>();// 将字段名和对应的类型存储到SharedPreferences中
private void saveInSharedPreferences(String tableName)
{SharedPreferences.Editor editor = getSharedPreferences(tableName, MODE_PRIVATE).edit();int index = -1;for (EditText editText : editTextList) {index++;String fieldName = editText.getText().toString();Spinner spinner = spinnerList.get(index);String type = spinner.getSelectedItem().toString();editor.putString(String.valueOf(index), fieldName+"&"+type);}editor.commit();
}因为SharedPreference内部是用HashMap存储的,所以字段是无序的,为了取出的时候保持有序我只能将所以的键依次设为递增的整数,值通过’&’符号复合字段名和对应的类型,等取出的时候在解析出来。另外,刚刚主界面有删除表的操作,现在可以补上具体操作:找出SharedPreference存储的位置(haredPreferences 文件都是存放在/data/data/packagename/shared_prefs/目录下的),根据文件名删除对应的文件即可,代码如下:
// 删除表
private void deleteTableAction(String tableName)
{File prefsdir = new File(getApplicationInfo().dataDir,"shared_prefs");if(prefsdir.exists() && prefsdir.isDirectory()){String[] list = prefsdir.list();for (String fileNameWithEx : list) {String fileName = getFileNameNoEx(fileNameWithEx);if (fileName.equals(tableName)) {File deleteFile = new File(prefsdir, fileName+".xml");deleteFile.delete();refreshSharedPreferencesList(); //刷新列表}}}
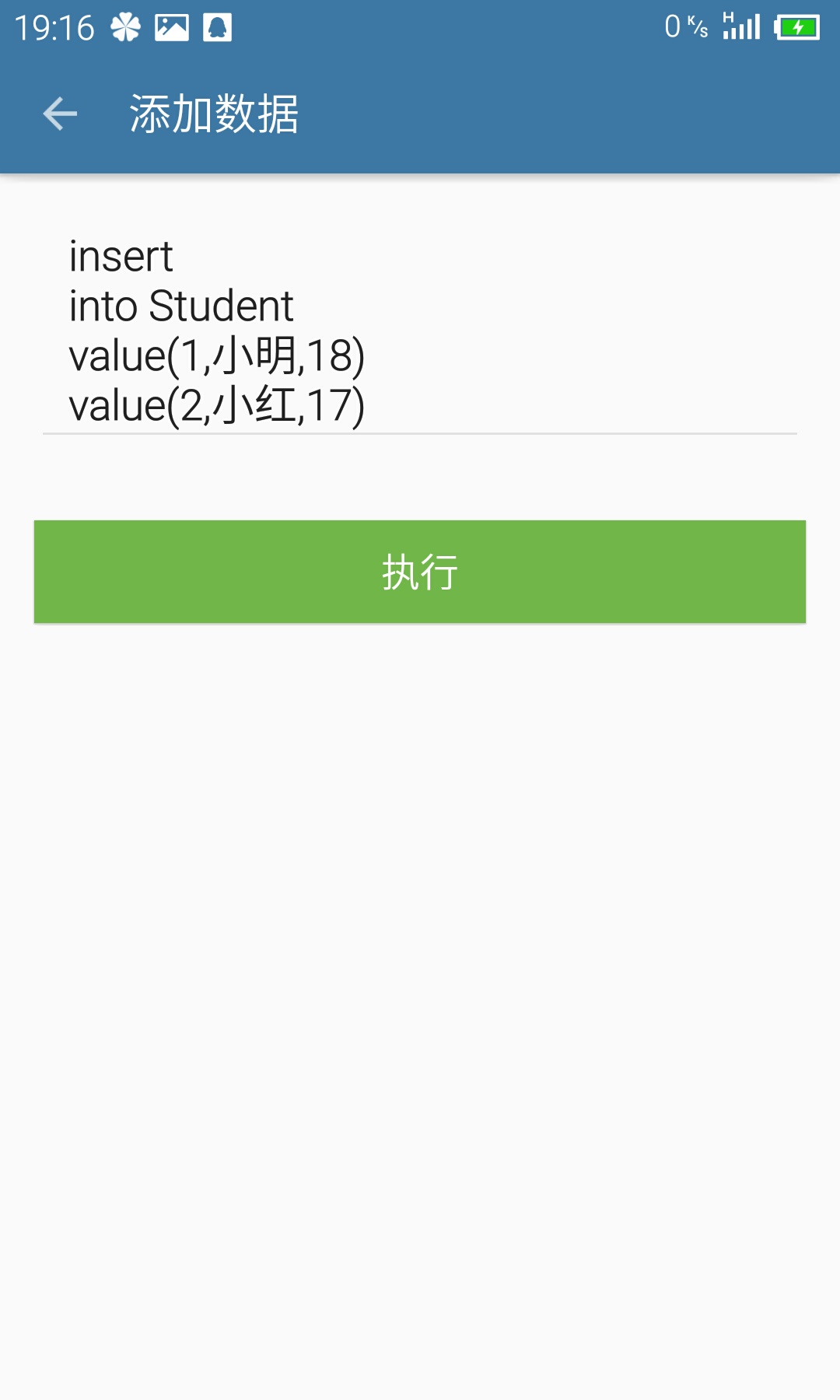
}- 插入界面(ExecSQL Activity):国际惯例展示界面先:
考虑到插入界面和搜索界面都是输入SQL语句然后执行操作,所以共用了同一个界面(ExecSQL Activity),下面不再说明。因为输入插入语句然后按”执行”按钮然后在当前界面并不能立刻进行查询操作,同时需要永久存储插入的数据,所以考虑将所有的插入语句存储到文件中,然后在需要执行查询的时候在取出插入语句插入到B+树上,然后进行查询。相关代码如下:
// 将插入语句写进文件中
private void writeInsertSqlToFile(String fileName)
{FileOutputStream out = null;BufferedWriter writer = null;try {out = openFileOutput(fileName, Context.MODE_APPEND); // 追加模式writer = new BufferedWriter(new OutputStreamWriter(out));String insertSQLStatement = sqlEdit.getText().toString();String[] lines = insertSQLStatement.split(System.getProperty("line.separator")); // 按行截取int length = lines.length;// 将所有的插入语句写入文件中for (int i = 2; i < length; i++) {String oneLine = lines[i];//Todo: 此处应该检查每一行数据的正确性writer.write(oneLine);writer.newLine(); // 换行Log.d("write oneLine", oneLine);}sqlEdit.setText(null);} catch (IOException e) {e.printStackTrace();} finally {try {if (writer != null) {writer.close();}} catch (IOException e) {e.printStackTrace();}}
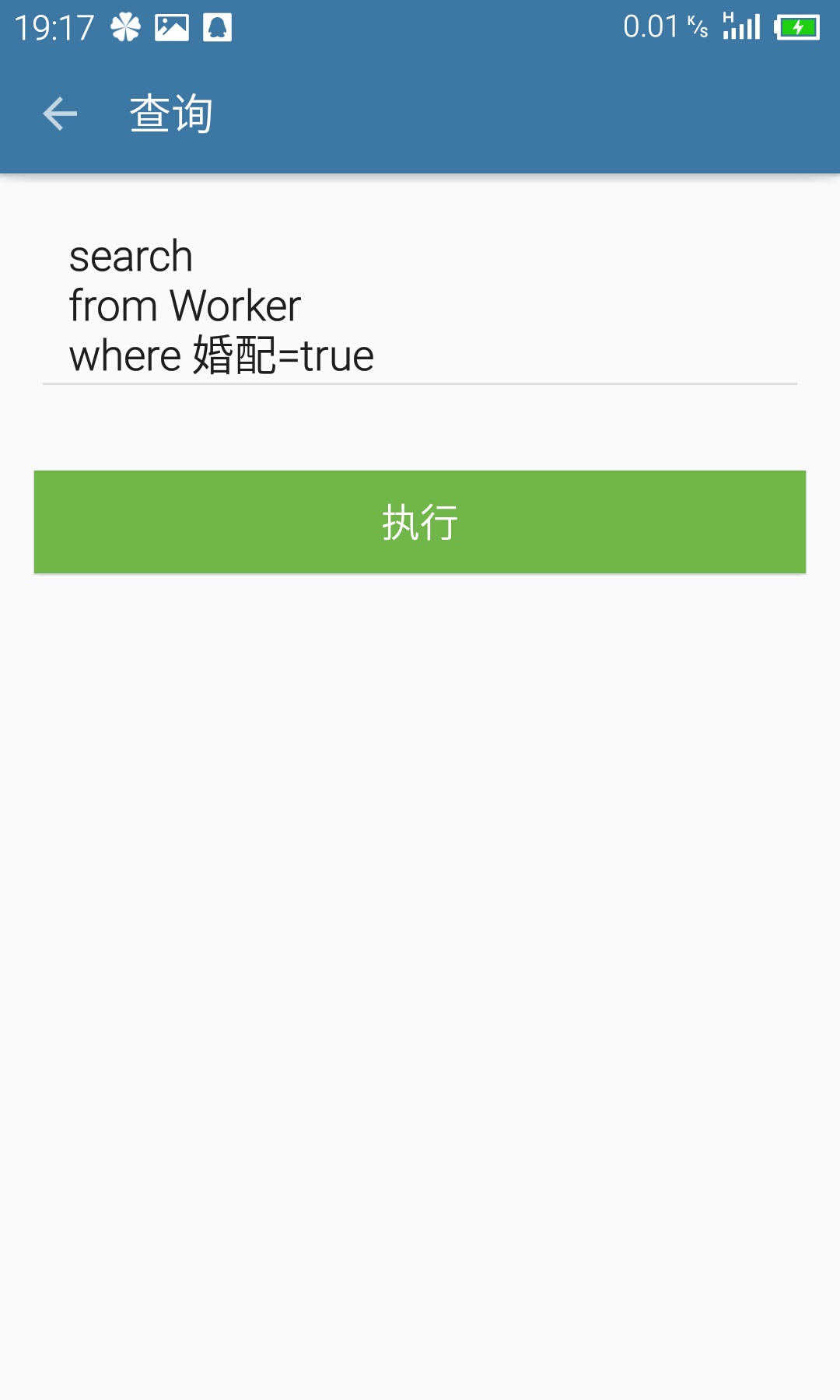
}- 查询界面(ExecSQL Activity):界面展示如下:
查询的时候先取出where语句,然后解析出查询的时候具体的限定条件,具体代码如下:
// 从表中查询数据
private void queryFromTable()
{BPlusTree tree = new BPlusTree(tableName, BPLUSTREE_DEGREE);String insertSql = readInsertSqlFromFile(tableName);// 将数据逐条插到B+树上if (insertDataInTree(tree, insertSql)) {String querySql = sqlEdit.getText().toString();String[] twoStr = analyseQuerySqlStatement(querySql);ArrayList<String> resultList = new ArrayList<String>();if (twoStr[0].equals(fieldNameArray.get(0))) {// 查询主键Object result = tree.search(twoStr[1]);if (result != null) {String resultString = formatResultMapToString((Map) result, twoStr[1]);resultList.add(resultString);}} else {// 查询其他属性Node head = tree.getHead();resultList = traverseTreeToSearch(head, twoStr);}}
}取出查询结果存放到ArrayList中,跳转到查询结果界面并putExtra把查询结果传过去。
- 查询结果界面(QueryResult Activity):最后就是展示查询的结果了:
这里只需展示查询结果到列表中即可。

后记:当做完整个项目之后回头看看,似乎做了什么了不得的事,又似乎什么都没有做的样子。通过这次浮沉历程,我深刻体会到做好前期准备是多么的重要,一遍遍改数据结构、数据类型是很痛苦的……还有一点体会就是应该把model层(MVC框架)写的健壮,具有鲁棒性,得益于我花了4、5天的B+树,我后期的时候只管组织好界面等其他部分即可,不用担心我的B+树会闹别扭。看来设计模式果然灰常重要的,《大话设计模式》、《设计模式之禅》……你们等着我,我交完这次作业就过来找你们!!!
PS: 我将这次的完整程序放在了这里,这是初期版本,可能会有更新,下了初期版本想要更新版本的可以私信我。也欢迎各位大牛拍砖,你们的意见是我前进最好的指导,谢谢。