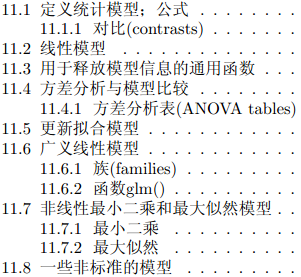
命令参考
https://surfer.nmr.mgh.harvard.edu/fswiki/recon-all
recon-all -i 输入文件路径.nii -s 创建用于保存文件夹名称 -sd 保存文件夹所在的目录 -命令 -autorecon2-cp
输入输出参考
https://surfer.nmr.mgh.harvard.edu/fswiki/ReconAllDevTable
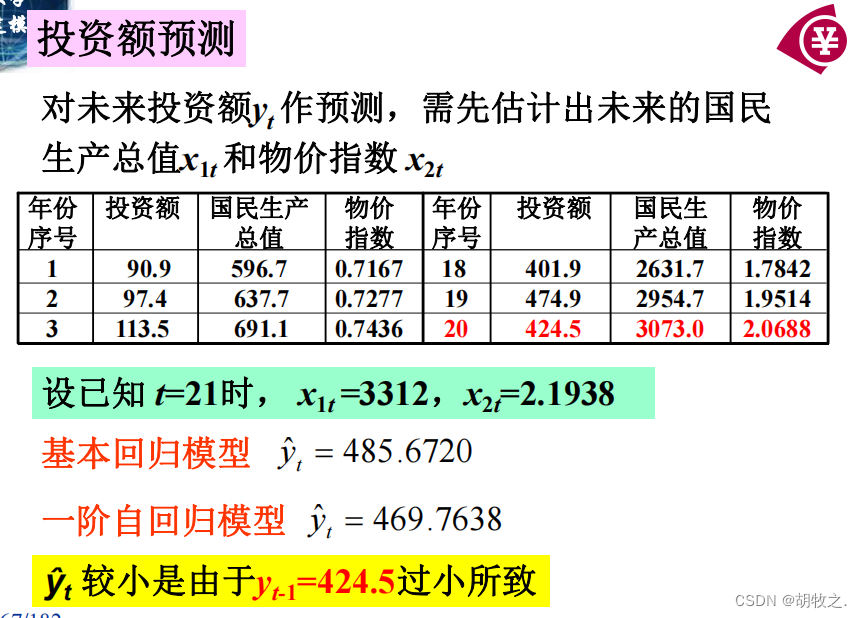
orig/001.mgz 将nii等文件转换成mgz
mri/rawavg.mgz 头动校正平均,没有多张的话直接将001.mgz复制到rawavg.mgz
mri/orig.mgz调整原始文件分辨率到256*256*128(1*1*1mm)
mri/transforms/talairach.xfm 转换矩阵
nu.mgz 对由于磁场不均匀引起的信号偏差进行偏差校正
T1.mgz 将白质区域信号标准化为110左右
brainmask.mgz头骨剥离后文件
transforms/talairach.lta 将偏差矫正后的图像nu.mgz配准到GCA模板
norm.mgz 去处颅骨后标准化
transforms/talairach.m3z 将偏差矫正后的图像norm.mgz配准到GCA模板
aseg.presurf.mgz根据 GCA 模型标记出皮下核团(以及胼胝体)的区域
brain.mgz 使用颅骨剥离和皮下核团标记后的结果将白质区域信息标准化 110 左右
brain.finalsurfs.mgz与brain.mgz类似
wm.mgz白质(脑室和皮下核团等区域)和灰质的边界,白质分割
filled.mgz去掉中脑(mid-brain)、分开左右脑;将左脑数值调整为 255,右脑数值调整为 127
lh.orig.nofix/rh.orig.nofix用小三角形覆盖灰白质的边界(即内皮层),生成原始的左右半球皮层
?h.smoothwm.nofix,?表示 l 或 r。生成的皮层是非常不平滑的,因为灰白质的边界在体素上是相互垂直的,因此对原始的皮层进行平滑
?h.inflated.nofix将皮层膨胀起来,使得折叠的沟能显示出来
?h.qsphere.nofix膨胀后的皮层进一步“变成”球形用于后面自动化修补皮层的缺陷
?h.orig修补原始皮层的拓扑学缺陷
?h.white.preaparc&&皮层曲率?h.curv通过微调原始皮层,使皮层沿着灰白质信号梯度的方向,从而细化白质皮层
?h.smoothwm 平滑
?h.inflated 和?h.sulc将皮层膨胀起来,使得折叠的沟能显示出来
?h.white.H/?h.white.K 以及?h.inflated.H/?h.inflated.K.H 表示平均曲率文件,.K 表示高斯曲率文件。计算平均曲率和高斯曲率
stats/?h.curv.stats曲率的统计指标
?h.sphere球形化
?h.sphere.reg 将个体球化的皮层配准到球形的模板(atlas),?h.sulc 进行粗配准,?h.curv 进行精配准。
?h.jacobian_white计算白质皮层在配准到球形模板中的变形程度
?h.avg_curv配准结果,将模板的曲率转换到个体水平
label/?h.aparc.annot将皮层根据 Desikan-Killiany Atlas 分区模板标记出不同区域
?h.pial灰质与脑膜边界的皮层(即外皮层)
?h.curv.pial/?h.area.pial相应的曲率、面积文件
?h.thickness通过外皮层和内皮层,得到皮层厚度文件
?h.ribbon.mgz/ribbon.mgz根据内外皮层,生成整个灰质区域的 mask 文件
stats/?h.aparc.stats根据分区结果,计算各个区域的结构指标,比如皮层厚度、平均曲率等
?h.aparc.a2009s.annot将皮层根据 Destrieux Atlas 分区模板标记出不同区域
stats/?h.aparc.a2009s.stats 根据分区标记结果,计算各个区域的结构指标,比如皮层厚度、平均曲率等
?h.aparc.DKTatlas40.annot将皮层根据 DKT Atlas 分区模板标记出不同区域
stats/?h.aparc.a2009s.stats根据分区结果,计算各个区域的结构指标,比如皮层厚度、平均曲率等。
surf/?h.w-g.pct.mgh 和 stats/?h.wg.pct.stats计算灰质和白质的比例:pct = 100*(W - G)/[0.5*(W + G)],
aseg.presurf.hypos.mgz
aparc+aseg.mgz、aparc.a2009s+aseg.mgz和 aparc.DKTatlas+aseg.mgz根据皮层标记的结果标记 volume,即将分区从皮层(surface)转换到体积(volume)上,是同一信息在不同数据形式上的表征,对应于不同分区模板
stats/aseg.stats计算皮下核团分区的结构指标统计值,包括体积均值、标准差等
wmparc.mgz 和 wmparc.stats对白质进行分区,并计算各分区的统计指标
label/?h.BA*_exvivo.label生成 Broadmann 分区的标签(label)文件标签文件和分区文件(annot)的区别在于一个标签文件只表示一个区域,一个分区文件包含了所有区域的分区信息
recon-all 的处理包括 volume 和 surface 两部分,volume 处理的结果
放在 mri 文件夹下,surface 处理的结果放在 surf 文件夹下,label 文件夹里放着分区和标签文件,stats
文件夹存放的各个分区的结构指标的统计值;
转自:http://learning-archive.org/?p=76