对人脸数据集“Labeled Faces in the Wild”:sklearn.datasets.fetch_lfw_people,下载地址aka LFW:http://vis-www.cs.umass.edu/lfw/lfw-funneled.tgz, 采用PCA,KPCA,MDS,LLE,ISOMAPE五种方式降维,比较基于SVM或决策树等分类器的识别效果。
一、课题设计背景
随着人工智能、大数据时代的到来,人们需要在众多场合验证身份信息。如今,身份认证技术已广泛应用于国家、社会的各领域,如政府、军队、银行、社会福利保障、电子商务、安全防护等。近年来,随着电子银行、线上商业等模式的推广,人们对于保障身份信息的安全性愈来愈重视。传统的身份认证方法(如密码、身份证等)因其容易盗取、假冒,已无法满足人们对个人信息安全的需求。生物特征识别技术因其稳定高效、单一快速等优势在身份认证领域迅速崛起,已成为人工智能时代学者们研究的热点。用于识别的人类生物特征一般有:人脸、虹膜、掌纹、指纹和步态等,而人脸图像识别(Face Recognition)因其方便获取,具有丰富的鉴别信息和非接触性的优势,已成为了生物特征识别技术研究的焦点之一。
人脸图像识别就是通过模式识别和图像处理技术,对现实空间的待识别人脸与人脸样本进行比较,根据相似度判断身份信息。在现实生活中存在大量人脸识别的例子,例如智能无人超市人脸识别、网上支付人脸识别、私人办公室人脸识别、安检人脸识别等。在国家以及社会的安全保障中,人脸识别也体现了其应用价值,对危险分子和境内外违法人员的及时监控和抓捕起到了极大作用,维护了国家和社会秩序的安全稳定。在信息安全防护中,人脸识别可以防止人们的身份信息泄露或者被窃取,遏制犯罪份子利用伪冒身份认证信息违法犯罪,有效保护人民群众的财产和隐私安全。
人脸图像采集质量的高低直接影响人脸识别的性能,因为人脸图像采集过程中易受到光照、姿态、角度以及采集设备等因素的影响,现实生活中获取的人脸图像数据往往具有复杂的高维非线性特性。因此,为了有效提高人脸识别性能,剔除人脸图像数据中的冗余信息,在不破坏人脸图像数据内在结构的同时降低人脸图像数据的维度,使得降维后的人脸数据可以被更加方便的存储和更加有效的识别是非常有必要的。
二、设计方案概述
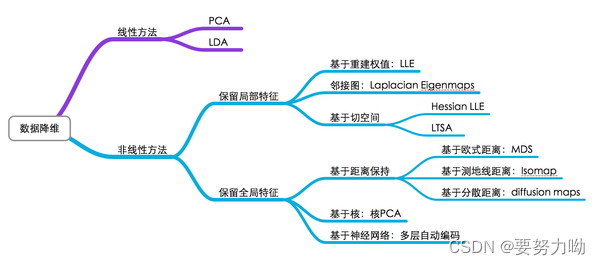
图1 降维方法系统分类
人脸图像降维方法,即利用线性或者非线性变换将高维空间中的原始人脸数据投影到一个合适的低维空间中,同时尽量保持人脸数据的几何结构不被改变,进而获取人脸数据的低维表达。通常,人脸图像降维技术按不同角度可分为有监督降维和无监督降维、线性降维和非线性降维等方法。
1)人脸图像数据的有监督降维是利用已有标签信息的人脸数据(训练)样本完成目标模型的训练,将输入的高维原始人脸数据映射到低维表达空间,再利用训练好的模型参数对新的人脸样本数据进行有效的降维处理。人脸图像数据的无监督降维相较于有监督降维方法,省去了样本信息标注的成本跟时间,但以牺牲部分降维性能为代价。
2)人脸图像的线性降维是通过假设人脸数据具有全局线性结构,然后利用线性映射函数将原始人脸数据映射到低维表达空间,完成线性降维模型的训练,再利用算法模型训练好的参数直接提取出新的人脸低维数据表达。人脸图像的非线性降维相较于线性方法,可以充分挖掘人脸样本数据的内在几何结构,更加准确地挖掘人脸图像的有效信息。
PCA 算法是常用的面向人脸图像的无监督线性降维算法,其核心思想是寻找一组包含较多信息的线性向量去描述原始人脸数据的分布结构。PCA 算法是一种优秀的统计特征提取方法,其通过选取少量有效人脸数据对人脸样本进行描述表达,在降维的同时尽量保留原始人脸识别的有用信息。
MDS 算法的降维思想同 PCA 算法相似,利用低维人脸特征来表达原始人脸信息,不同之处在于 MDS算法是通过计算人脸样本间的距离(一般选用欧式距离)来获取合适的低维表达数据,使得降维后的低维特征仍然保持原始人脸数据的潜在线性结构,从而达到人脸数据降维的目的。
为了克服线性降维算法在人脸图像降维中存在的缺陷,充分挖掘人脸数据潜在的非线性结构,非线性数据降维方法逐渐成为了人脸图像降维的研究热点,如核主成分分析(KPCA),但是核函数降维技术在人脸图像的降维过程中,也存在不少问题,比如核函数映射后的人脸样本特征分布无法明确、无选择核函数的统一标准、只能用于小样本的人脸数据训练,对于大样本人脸数据同样存在“维度灾难” 等问题。
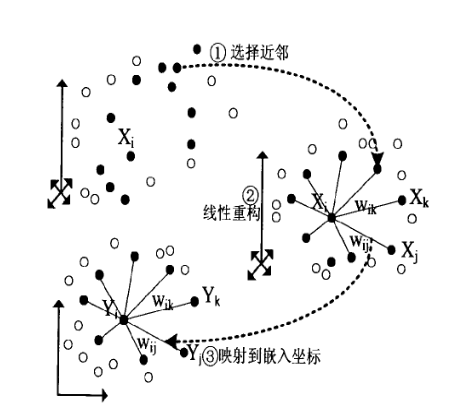
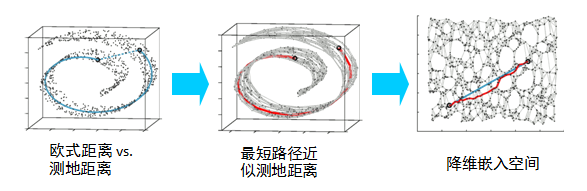
流形学习不同于核非线性降维,其核心思想是通过挖掘人脸数据的潜在规律,从人脸数据中获得数据的内在结构分布,将原始人脸数据映射到低维流形空间,同时保持低维样本数据在原始空间的几何关系。LLE 是一种是常用于处理人脸数据的经典的流形学习算法,其核心思想是假设数据的局部结构是线性的,通过找到局部近邻样本组合来线性表达样本。ISOMAP寻求一种低维表示,以保持点之间的“距离”。
经过上述对PCA、KPCA、LLE、MDS、ISOMAP的分析,为了验证上述降维方法的效果,因此设计对人脸数据集“Labeled Faces in the Wild”采用上述五种方式降维,比较基于SVM分类器的识别效果。
三、详细设计
3.1 LFW人脸数据集介绍
LFW (Labled Faces in the Wild)人脸数据集:是目前人脸识别的常用测试集,其中提供的人脸图片均来源于生活中的自然场景,因此识别难度会增大,尤其由于多姿态、光照、表情、年龄、遮挡等因素影响导致即使同一人的照片差别也很大。并且有些照片中可能不止一个人脸出现,对这些多人脸图像仅选择中心坐标的人脸作为目标,其他区域的视为背景干扰。LFW数据库是为了研究无约束的人脸识别问题而设计的。它包含超过13000张从网上收集的人脸图像。每张人脸图像都标有人的名字,在数据集中, 1680个人有两个或更多个不同的照片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。图2中显示的是LFW数据库中一个人的人脸样本。


图2 LFW数据样本
3.2 人脸识别流程
(1)图像预处理
人脸检测的关键性任务是从待检测的图像或一段视频中判定出人脸的存在与否,进而把图像分为两个区域,人脸和非人脸。人脸检测自身在图像检索等领域有着广泛的应用,但光照变化的强弱、姿态变化的样式、复杂背景的出现等都会对检测结果产生不同层次的影响。图像的预处理是能否成功将人脸检测出来的基础环节。
将读取图像从RGB值转化到Lab空间是预处理第一环节,将像素和灰度值去均值后,进行边缘检测,清除不必要的背景区域或者噪音等无关信息,最后将收纳的图像统一缩放为标准大小。
图像的预处理一般分为六个技术模块,其中二值法技术在进行处理过程中同样占有举足轻重的地位。它的工作主要是将已经处理过的灰度图像值生成黑白的二值图像,非黑即白,图像的二值化处理案例如下图3。图3是实验对象人脸五官的二值化处理。通过实现简单的二值化处理,设置一定的阙值范围(使提取轮廓的物体与背景区分割开、平滑边缘的轮廓)来实现图像从灰度到黑白的转化。
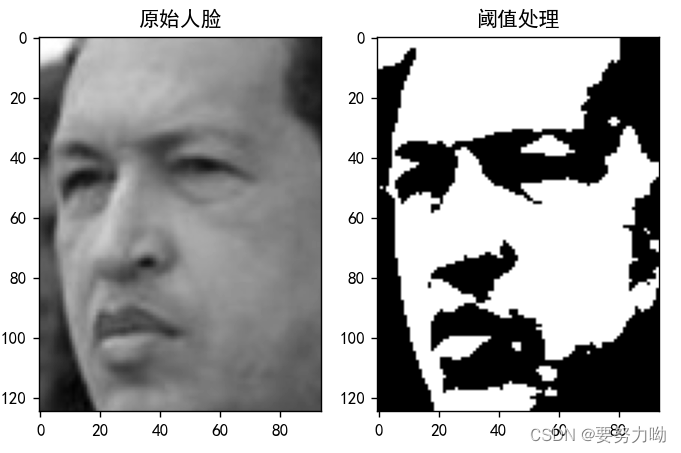
图3二值化处理
(2)人脸检测
人脸检测的任务是判别被检测者与所在的周围背景颜色等方面是否有计算机可察觉的明显区别。首先检测输入图像或视频序列中是否存在人脸图像或者人脸边缘。如果不存在,则检测框内不会出现任何变化;如果存在,检测框会定位到除去背景人脸所在位置和尺寸的大小。
经过对LFW人脸数据集分析后,大部分的图片都主要集中在人脸部位,被检测者与所在的周围背景颜色等方面无明显区别,因此在本设计中不在进行进行人脸检测。
(3)人脸鉴别
人脸鉴别,也称为人脸识别,鉴别过程就是把要识别的人脸与放在数据库中的人脸模板进行对比。它的核心点是如何选择正确的匹配规则和策略,依据恰当的表示方式和对比方式搜索到数据库中与它相匹配的待检测人脸。由此可见,它与人脸特征表示紧密相关。
在本设计中,利用降维算法,对数据进行降维后提取主要特征,再利用SVM进行识别,实现人脸的鉴别。
四、结果及分析
4.1参数对识别效果的影响
为了观察降低的维度对SVM分类器的影响程度,记录不同维度与准确率的关系,结果如下图4所示,根据下图分析可知,提高维度理论上可以保留更多的信息,并且会提高分类器的精度,但是PCA在提高到一定维度时,分类器的分类器的分类效果下降,因此对于PCA而言,在选择主成分个数时,应该选择合适的个数,这样才能达到理想的效果。
对于其他四种降维方法,在本次实验中,并未出现如PCA这种情况,整体呈提升维度,保留的信息增多,分类器的效果逐渐变好。
但在这个过程中,MDS出现增长缓慢的情况,MDS算法是通过计算人脸样本间的距离(一般选用欧式距离)来获取合适的低维表达数据,使得降维后的低维特征仍然保持原始人脸数据的潜在线性结构,从而达到人脸数据降维,但是最后的分类效果却不是很理想,可能与使用的分类器有关。
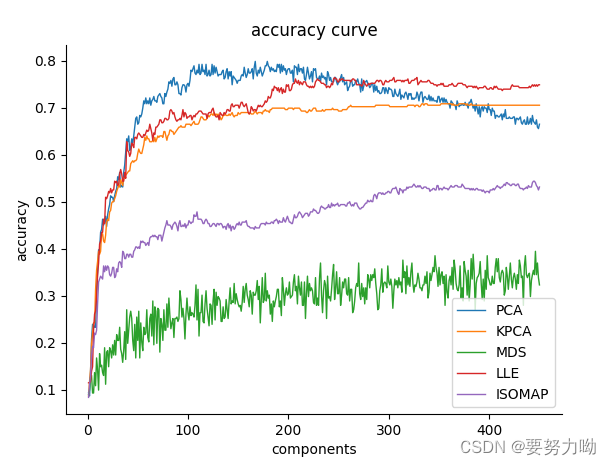
图4 维度与识别效果关系
4.2 识别结果显示
4.2.1 直接使用SVM识别结果
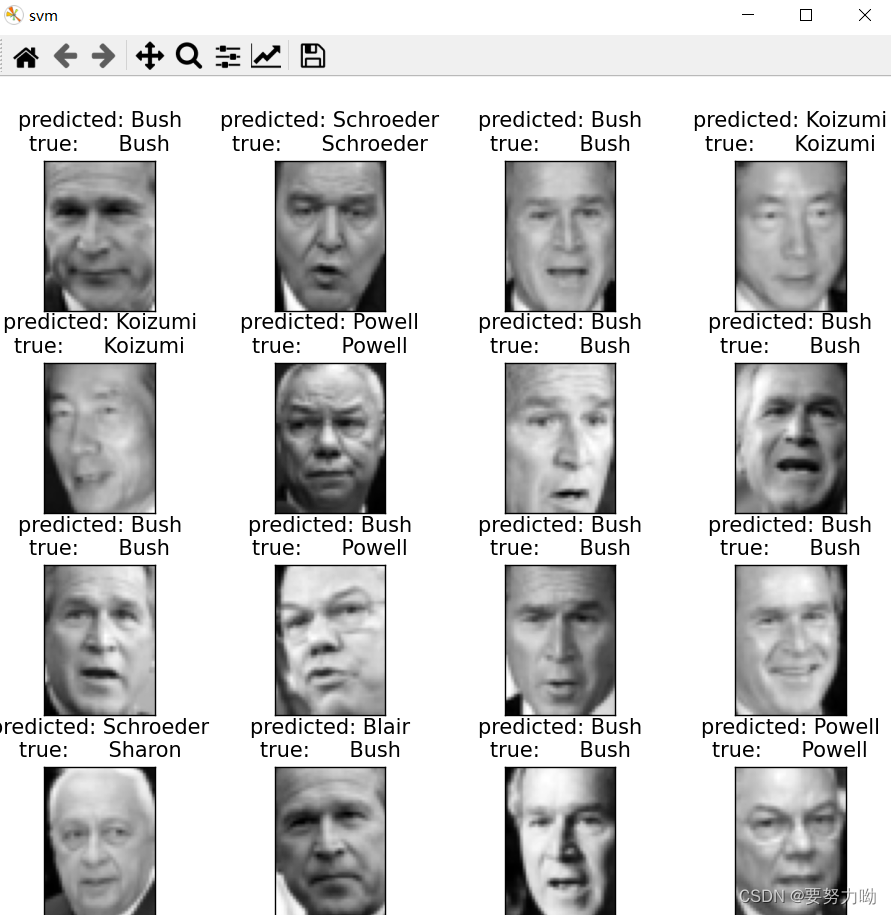
图5:SVM识别结果可视化
表1:SVM性能指标
| 人名 | precision | recall | f1-score | support |
| Ariel Sharon | 0.77 | 0.67 | 0.71 | 15 |
| Colin Powell | 0.75 | 0.85 | 0.80 | 68 |
| Donald Rumsfeld | 0.73 | 0.77 | 0.75 | 31 |
| George W Bush | 0.87 | 0.78 | 0.82 | 126 |
| Gerhard Schroeder | 0.50 | 0.70 | 0.58 | 23 |
| Hugo Chavez | 0.81 | 0.65 | 0.72 | 20 |
| Junichiro Koizumi | 0.92 | 1.00 | 0.96 | 12 |
| Tony Blair | 0.75 | 0.71 | 0.73 | 42 |
| 性能指标 | ||||
| accuracy | 0.77 | 337 | ||
| macro avg | 0.76 | 0.77 | 0.76 | 337 |
| weighted avg | 0.79 | 0.77 | 0.78 | 337 |
4.2.2通过PCA对人脸数据集降维后SVM识别结果
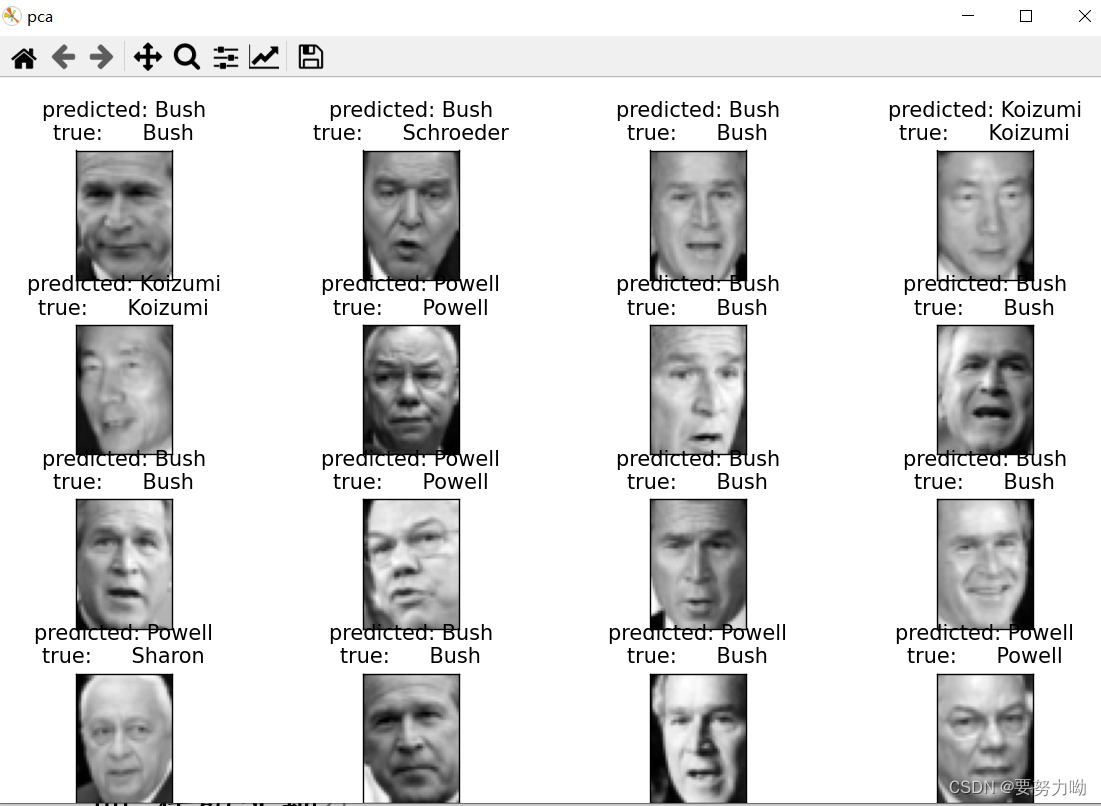
图6:PCA降维后SVM识别结果可视化
表2:PCA+SVM性能指标
| 人名 | precision | recall | f1-score | support |
| Ariel Sharon | 1.00 | 0.80 | 0.89 | 15 |
| Colin Powell | 0.64 | 0.96 | 0.76 | 68 |
| Donald Rumsfeld | 0.96 | 0.81 | 0.88 | 31 |
| George W Bush | 0.91 | 0.84 | 0.88 | 126 |
| Gerhard Schroeder | 0.89 | 0.70 | 0.78 | 23 |
| Hugo Chavez | 1.00 | 0.70 | 0.82 | 20 |
| Junichiro Koizumi | 1.00 | 0.75 | 0.86 | 12 |
| Tony Blair | 0.90 | 0.86 | 0.88 | 42 |
| 性能指标 | ||||
| accuracy | 0.84 | 337 | ||
| macroavg | 0.91 | 0.80 | 0.84 | 337 |
| weightedavg | 0.87 | 0.84 | 0.84 | 337 |
4.2.3 通过KPCA对人脸数据集降维后SVM识别结果
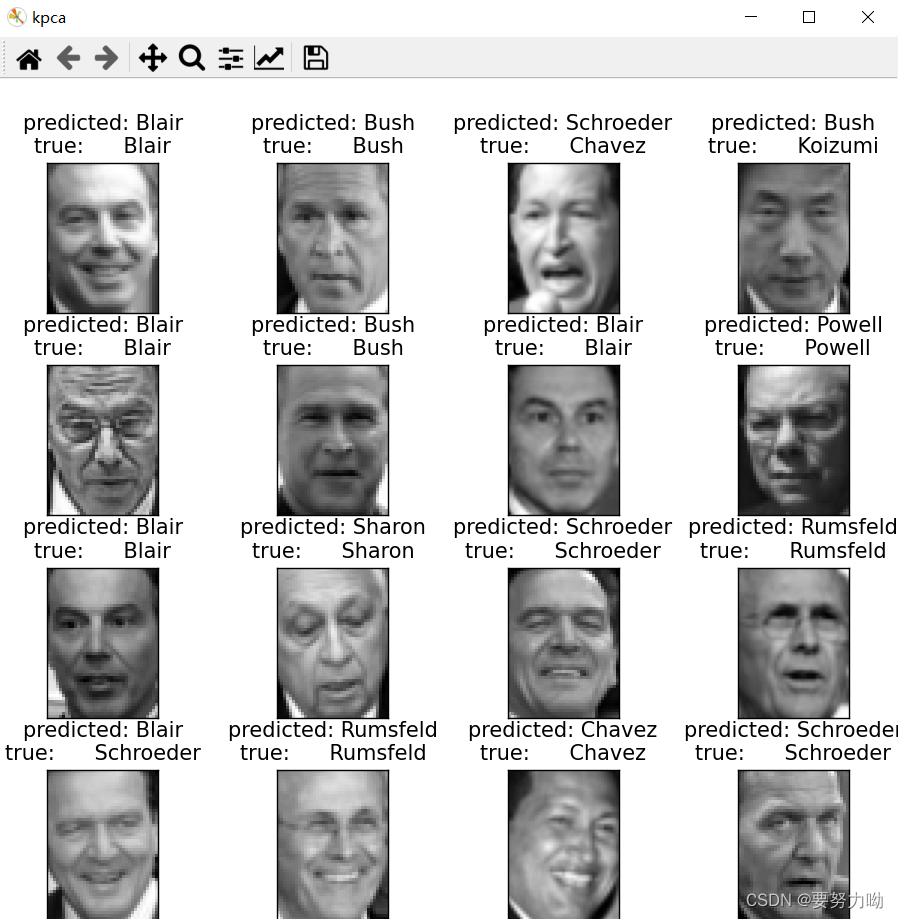
图7:KPCA降维后SVM识别结果可视化
表3:KPCA+SVM性能指标
| 人名 | precision | recall | f1-score | support |
| Ariel Sharon | 0.77 | 0.67 | 0.71 | 15 |
| Colin Powell | 0.81 | 0.85 | 0.83 | 68 |
| Donald Rumsfeld | 0.75 | 0.77 | 0.76 | 31 |
| George W Bush | 0.84 | 0.82 | 0.83 | 126 |
| Gerhard Schroeder | 0.50 | 0.61 | 0.55 | 23 |
| Hugo Chavez | 0.92 | 0.60 | 0.73 | 20 |
| Junichiro Koizumi | 0.92 | 0.92 | 0.92 | 12 |
| Tony Blair | 0.70 | 0.74 | 0.72 | 42 |
| 性能指标 | ||||
| accuracy | 0.78 | 337 | ||
| macro avg | 0.78 | 0.75 | 0.76 | 337 |
| weighted avg | 0.79 | 0.78 | 0.78 | 337 |
4.2.4 通过LLE对人脸数据集降维后SVM识别结果
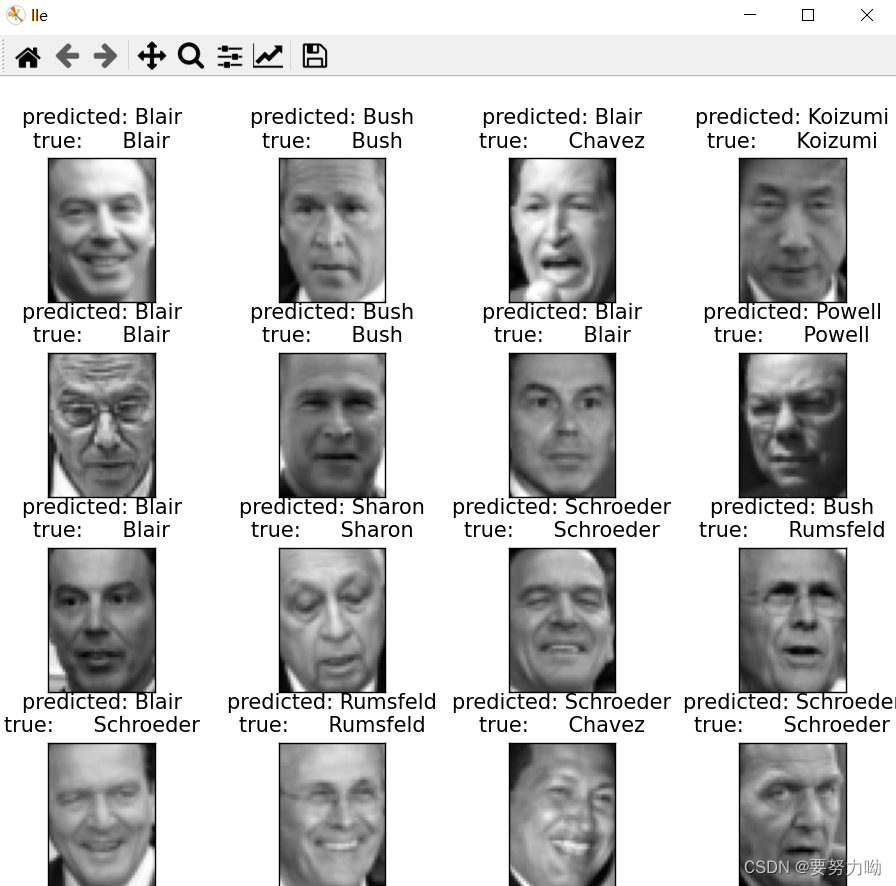
图8:LLE降维后SVM识别结果可视化
表4:LLE+SVM性能指标
| 人名 | precision | recall | f1-score | support |
| Ariel Sharon | 0.77 | 0.67 | 0.71 | 15 |
| Colin Powell | 0.92 | 0.84 | 0.88 | 68 |
| Donald Rumsfeld | 0.78 | 0.81 | 0.79 | 31 |
| George W Bush | 0.88 | 0.89 | 0.88 | 126 |
| Gerhard Schroeder | 0.62 | 0.65 | 0.64 | 23 |
| Hugo Chavez | 0.93 | 0.65 | 0.76 | 20 |
| Junichiro Koizumi | 0.92 | 1.00 | 0.96 | 12 |
| Tony Blair | 0.71 | 0.86 | 0.77 | 42 |
| 性能指标 | ||||
| accuracy | 0.83 | 337 | ||
| macro avg | 0.82 | 0.79 | 0.80 | 337 |
| weighted avg | 0.84 | 0.83 | 0.83 | 337 |
4.2.5 通过ISOMAP对人脸数据集降维后SVM识别结果
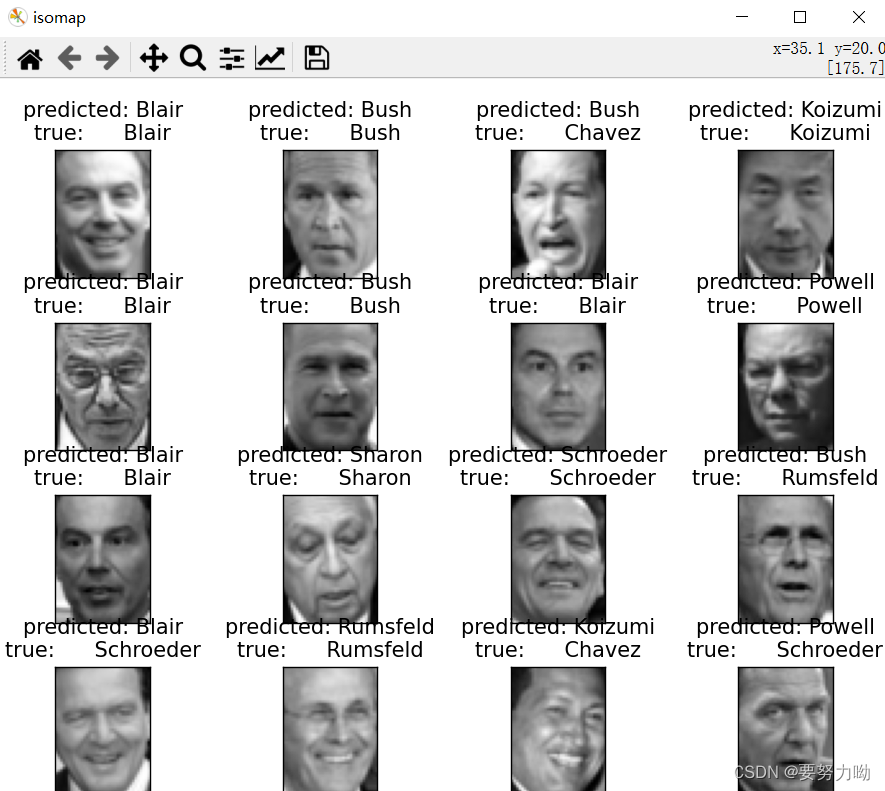
图9:ISOMAP降维后SVM识别结果可视化
表5:ISOMAP+SVM性能指标
|
| precision | recall | f1-score | support |
| Ariel Sharon | 0.70 | 0.47 | 0.56 | 15 |
| Colin Powell | 0.57 | 0.82 | 0.67 | 68 |
| Donald Rumsfeld | 0.73 | 0.61 | 0.67 | 31 |
| George W Bush | 0.73 | 0.66 | 0.69 | 126 |
| Gerhard Schroeder | 0.45 | 0.43 | 0.44 | 23 |
| Hugo Chavez | 0.50 | 0.20 | 0.29 | 20 |
| Junichiro Koizumi | 0.53 | 0.83 | 0.65 | 12 |
| Tony Blair | 0.55 | 0.52 | 0.54 | 42 |
| 性能指标 | ||||
| accuracy | 0.63 | 337 | ||
| macro avg | 0.60 | 0.57 | 0.56 | 337 |
| weighted avg | 0.63 | 0.63 | 0.62 | 337 |
4.2.6 通过MDS对人脸数据集降维后SVM识别结果
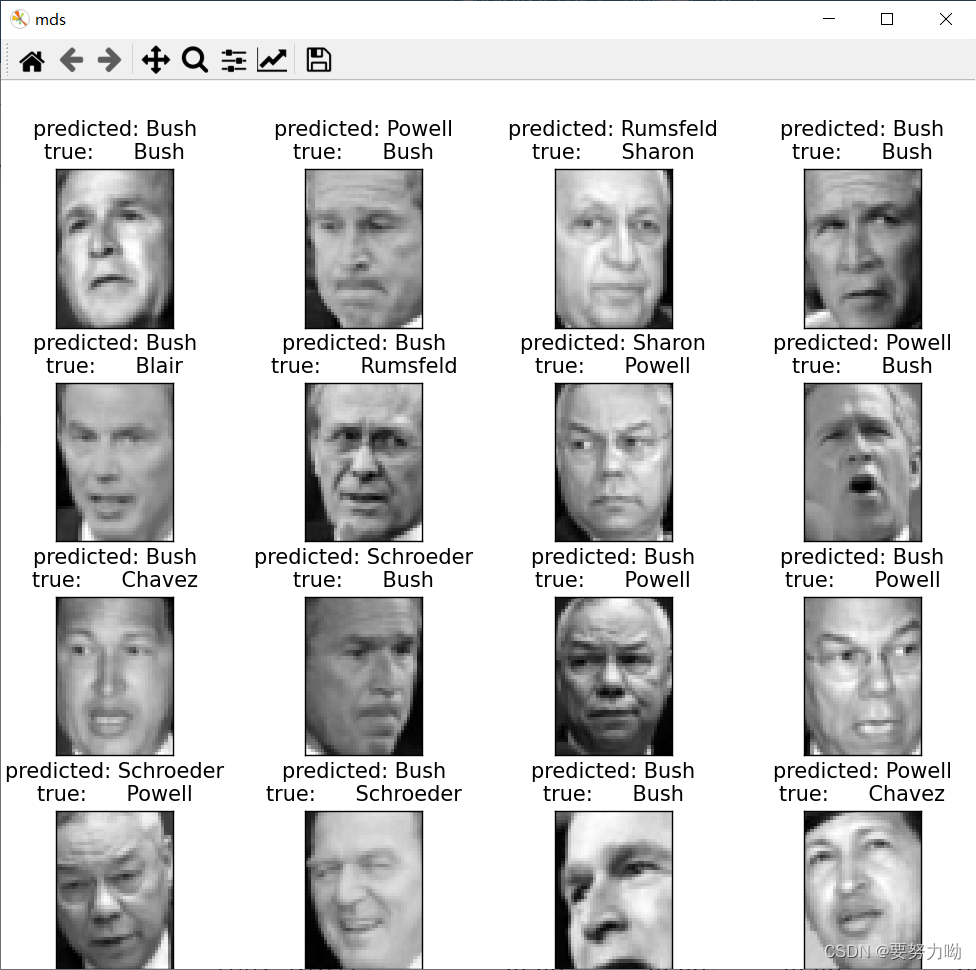
图10:MDS降维后SVM识别结果可视化
表6:MDS+SVM性能指标
| precision | recall | f1-score | support | |
| Ariel Sharon | 0.00 | 0.00 | 0.00 | 13 |
| Colin Powell | 0.19 | 0.20 | 0.20 | 60 |
| Donald Rumsfeld | 0.08 | 0.11 | 0.09 | 27 |
| George W Bush | 0.50 | 0.47 | 0.48 | 146 |
| Gerhard Schroeder | 0.12 | 0.24 | 0.16 | 25 |
| Hugo Chavez | 0.00 | 0.00 | 0.00 | 15 |
| Tony Blair | 0.05 | 0.03 | 0.03 | 36 |
| 性能指标 | ||||
| accuracy | 0.28 | 322 | ||
| macro avg | 0.13 | 0.15 | 0.14 | 322 |
| weighted avg | 0.29 | 0.28 | 0.28 | 322 |
4.3结果分析
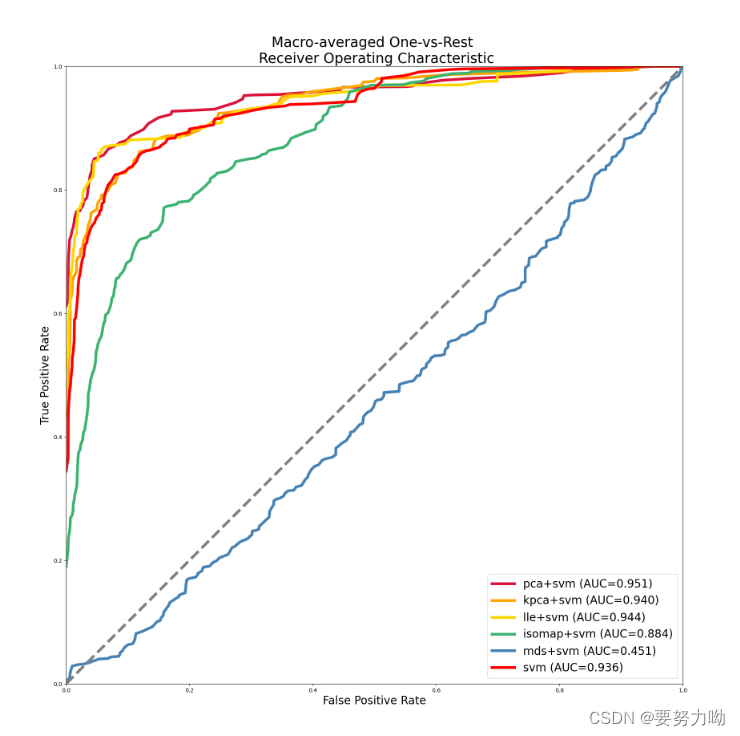
图11:宏平均ROC曲线
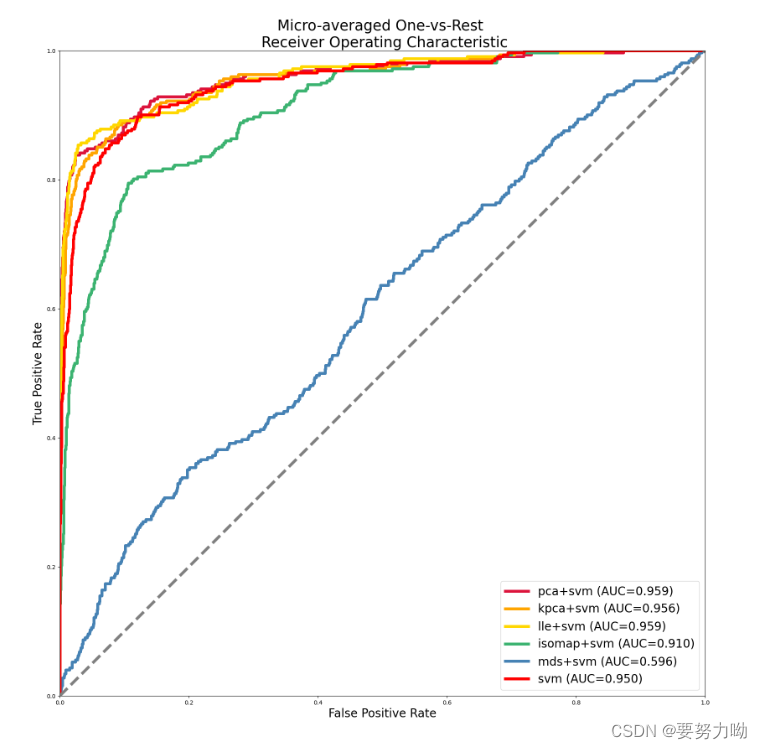
图12:微平均ROC曲线
为了比较在人脸数据集上,采用降维后,利用SVM分类识别的性能,我设计了五组实验分别为:PCA,KPCA,LLE,ISOMAP、MDS以及不使用降维,将五组降维方法与不使用降维的SVM进行对比,为了便于观察降维前后时间差距,总结如下表7所示,并且为了判断模型性能,绘制了不同降维算法的ROC曲线,结果如上图11,12所示。
表7:时间对比表
| 方法 | 降维时间 | 训练时间 | 准确率 | Macro-AUC | Micro-AUC | |
| SVM | 0.000s | 3.370s | 0.77 | 0.936 | 0.95 | |
| SVM+PCA | 0.270s | 0.364s | 0.84 | 0.951 | 0.959 | |
| SVM+KPCA | 0.275s | 0.311s | 0.78 | 0.94 | 0.956 | |
| SVM+LLE | 16.822s | 0.359s | 0.83 | 0.944 | 0.959 | |
| SVM+ISOMAP | 10.830s | 0.343s | 0.63 | 0.884 | 0.91 | |
| SVM+MDS | 13.237s | 0.305s | 0.28 | 0.451 | 0.596 |
注:以下描述中PCA代表SVM和PCA(即使用降维后的SVM),SVM代表没有进行降维。
由上表显示结果,可以看出降维时间对比:LLE>MDS>ISOMAP>PCA≈KPCA,训练时间:SVM>PCA>LLE>ISOMAP>KPCA,准确率:PCA>LLE>KPCA>SVM>ISOMAP>MDS。
根据上述结果显示,经过降维后的数据训练时间大幅度降低,并且合适的降维方法在保证了基本的信息得以保留的前提下,去除了冗余的信息,增加了对噪声的抵抗能力,最终识别效果也得到了提升,但是不合适的降维算法,会让最终的识别效果大幅度下降,出现适得其反的效果。
因此选择选择合适的降维方法,可以在去除冗余信息、缩短训练的时间的同时,提高识别效果,经过最后的对比,综合时间指标与准确率,降维后的训练速度比较,KPCA与PCA会更适合人脸识别。
五、总结
在大数据的时代,对大规模、呈指数级增长的复杂数据进行高效的组织、处理和分析,都离不开数据的降维处理。数据降维需要解决的问题是找到一个合适的投影,简洁、有效地表达出样本在原始高维空间的分布,使原始数据从高维空间变换到低维子空间。数据降维算法可以应用到人脸识别、场景分析、对象分类和生物统计等各种各样的场景中,因此许多降维算法已经被提出并应用。
本文以降维算法为背景,在仔细了解PCA,KPCA,LLE,ISOMAP,MDS几种降维算法的方法原理和涉及的知识基础后,利用这次模式识别课程设计,并结合资料与课本,动手实践了模式识别的经典降维算法和降维框架。降维算法部分包括各种经典算法的原理、公式推导和算法过程,以及它们在线性降维、流动学习、核方法(监督、无监督和半监督)中的优化算法。经过这次实验,结合课本,我总结以下关于降维的作用:
1.降低时间复杂度和空间复杂度
2.节省了提取不必要特征的开销
3.去掉数据集中夹杂的噪音
4.较简单的模型在小数据集上有更强的鲁棒性
5.当数据能有较少的特征进行解释,我们可以更好的解释数据,使得我们可以提取知识。
本次课程设计重点是:学习各种降维方法,并将上述方法运用到实际的人脸识别中,在这次实验中,因为对于脸部识别,其维度比较大,如果数据量非常大并且数据维度也非常高,程序运行效率就会很低。我利用了PCA,KPCA,LLE,ISOMAP,MDS降维方法,首先对人脸数据进行降维,其后再使用SVM进行识别。并与降维之前进行对比,效率提升了很多,各种方法对比见下表。
| 方法 | 降维时间 | 训练时间 | 准确率 | Macro-AUC | Micro-AUC | |
| SVM | 0.000s | 3.370s | 0.77 | 0.936 | 0.95 | |
| SVM+PCA | 0.270s | 0.364s | 0.84 | 0.951 | 0.959 | |
| SVM+KPCA | 0.275s | 0.311s | 0.78 | 0.94 | 0.956 | |
| SVM+LLE | 16.822s | 0.359s | 0.83 | 0.944 | 0.959 | |
| SVM+ISOMAP | 10.830s | 0.343s | 0.63 | 0.884 | 0.91 | |
| SVM+MDS | 13.237s | 0.305s | 0.28 | 0.451 | 0.596 |
在这个过程中,结合本案例我总结了以上五种降维方法的优缺点,结合实例,加强印象,锻炼能力,以PCA的优点与局限性为例:
优点:
- 易于实现,计算成本较低
- 不需要了解图像(如:面部特征)
限制:
- 训练集/测试集需要适当的中心脸
- 该算法对光照、阴影和图像中的人脸尺度都很敏感
- 该算法需要正面人脸视图才能正常工作
代码
代码太久了不知道对不对了
1.导入库
- import matplotlib.pyplot as plt
- import numpy as np
- from scipy import interp
- from sklearn.model_selection import train_test_split
- from sklearn.model_selection import GridSearchCV
- from sklearn.datasets import fetch_lfw_people
- from sklearn.metrics import classification_report
- from sklearn.metrics import *
- from sklearn.decomposition import PCA, KernelPCA
- from sklearn.manifold import LocallyLinearEmbedding, Isomap, MDS
- from sklearn.svm import SVC
- from sklearn.preprocessing import label_binarize
- from time import time
2.数据处理类
- # 构建自己的数据集
- class my_dataset():
- def __init__(self, min_faces_per_person=70, resize=0.4):
- self.dataset = fetch_lfw_people(min_faces_per_person=min_faces_per_person, resize=resize)
- self.n_samples, self.h, self.w = self.dataset.images.shape
- # 获取图像
- X = self.dataset.data
- # 每个人都有一个标签
- y = self.dataset.target
- # 获取标签对应的名字
- self.target_names = self.dataset.target_names
- self.n_features = X.shape[1]
- self.n_classes = self.target_names.shape[0]
- print("样本数: %d" % self.n_samples)
- print("选择的人物个数: %d" % self.n_classes)
- # 划分训练和测试数据集
- self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
- X, y, test_size=0.25, random_state=42)
- # print(self.X_train[0])
- # print(self.X_test.shape)
- # 获取训练测试数据
- def get_data(self):
- return self.X_train, self.X_test, self.y_train, self.y_test
- def get_traindata(self):
- return self.X_train, self.y_train,
- def get_test_data(self):
- return self.X_test, self.y_test
3.降维类
- # 降维类
- class my_decomposition():
- def __init__(self, dataset, choice, n_components):
- self.dataset = dataset # 数据集
- self.choice = choice # 选择的降维算法
- self.X_train, self.X_test, self.y_train, self.y_test = self.dataset.get_data() # 通过数据集获取数据
- self.decom(choice, n_components) # 构架降维类以后自动将数据降维
- def decom(self, choice, n_components):
- """
- 对数据集进行降维
- args:
- choice:string 选择的降维算法
- n_components: 维数
- """
- self.choice = choice
- self.n_components = n_components
- t0 = time()
- if self.choice == "pca+svm":
- self.re_model = PCA(n_components=self.n_components, svd_solver='randomized',
- whiten=True).fit(self.X_train)
- self.X_train_re = self.re_model.transform(self.X_train)
- self.X_test_re = self.re_model.transform(self.X_test)
- elif self.choice == "mds+svm":
- self.re_model = MDS(n_components=self.n_components,metric=True, n_init=5, max_iter=100, verbose=0,
- eps=1e-4, n_jobs=None, random_state=None, dissimilarity="euclidean")
- self.X_train_re = self.re_model.fit_transform(self.X_train)
- self.X_test_re = self.re_model.fit_transform(self.X_test)
- elif self.choice == "kpca+svm":
- self.re_model = KernelPCA(
- n_components=self.n_components, kernel='cosine').fit(self.X_train)
- self.X_train_re = self.re_model.transform(self.X_train)
- self.X_test_re = self.re_model.transform(self.X_test)
- elif self.choice == "lle+svm":
- self.re_model = LocallyLinearEmbedding(
- n_components=self.n_components,
- n_neighbors=200,
- neighbors_algorithm='auto').fit(self.X_train)
- self.X_train_re = self.re_model.transform(self.X_train)
- self.X_test_re = self.re_model.transform(self.X_test)
- elif self.choice == "isomap+svm":
- self.re_model = Isomap(
- n_components=self.n_components,
- n_neighbors=200,
- neighbors_algorithm='auto').fit(self.X_train)
- self.X_train_re = self.re_model.transform(self.X_train)
- self.X_test_re = self.re_model.transform(self.X_test)
- elif self.choice == "svm":
- self.X_train_re = self.X_train
- self.X_test_re = self.X_test
- self.re_time = time() - t0
- def model_report(self):
- """
- 打印模型耗费的时间等信息
- """
- print("%s降维时间:%0.3fs" % (self.choice,(self.re_time)))
- def get_X_train_re(self):
- """
- 获取降维后的数据
- """
- return self.X_train_re
- def get_X_test_re(self):
- return self.X_test_re
4.SVM类
- class svm():
- def __init__(self, dataset, decomposition, kernel='rbf', class_weight='balanced'):
- self.dataset = dataset
- self.decomposition = decomposition
- self.target_names = self.dataset.target_names
- self.choice = self.decomposition.choice
- self.n_samples, self.h, self.w = self.dataset.n_samples, self.dataset.h, self.dataset.w
- self.kernel = kernel
- self.class_weight = class_weight
- self.X_train, self.X_test, self.y_train, self.y_test = self.dataset.get_data()
- self.X_train_re = self.decomposition.get_X_train_re()
- self.X_test_re = self.decomposition.get_X_test_re()
- def my_fit(self):
- """
- 模型训练函数
- """
- # 可以选择网格调参
- # param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
- # 'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
- # clf = GridSearchCV(
- # SVC(kernel=self.kernel, class_weight=self.class_weight), param_grid
- # )
- clf = SVC(kernel=self.kernel, class_weight=self.class_weight)
- t0 = time()
- self.clf = clf.fit(self.X_train_re, self.y_train)
- self.train_time = time() - t0
- # print("训练时间:%0.3fs" % ((time() - t0)))
- return self.clf
- def my_predict(self):
- """
- 模型预测函数
- """
- self.y_pred = self.clf.predict(self.X_test_re)
- self.titles = [self.title(i) for i in range(self.y_pred.shape[0])]
- return self.y_pred
- def decision_function(self,X_test):
- return self.clf.decision_function(X_test)
- def model_report(self):
- """
- 打印模型耗费的时间等信息
- """
- print("训练时间:%0.3fs" % ((self.train_time)))
- print("模型性能:")
- print(classification_report(self.y_test,
- self.y_pred, target_names=self.target_names))
- def plot_gallery(self, plot_type="test", start=0, n_row=3, n_col=4):
- """
- 绘制肖像画廊的函数
- Args:
- plot_type:string 选择绘制预测图还是特征脸(废除,只能绘制肖像图)
- start: 选择绘制图片的起始位置
- n_row: 绘制图片的行数
- n_col: 绘制图片的列数
- """
- plt.figure(self.choice, figsize=(1.8 * n_col, 2.4 * n_row))
- plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
- if plot_type == "test":
- images = self.X_test
- titles = self.titles
- elif plot_type == "eigenface":
- images = self.eigenfaces
- titles = ["eigenface %d" % i for i in range(images.shape[0])]
- elif plot_type == "train":
- images = self.X_train
- # titles = self.titles
- for i in range(n_row * n_col):
- plt.subplot(n_row, n_col, i + 1)
- plt.imshow(
- images[i+start].reshape((self.h, self.w)), cmap=plt.cm.gray)
- # plt.title(titles[i+start], size=12)
- plt.xticks(())
- plt.yticks(())
- plt.show()
- def title(self, i):
- """
- 为plot_gallery函数提供帮助
- """
- pred_name = self.target_names[self.y_pred[i]].rsplit(' ', 1)[-1]
- true_name = self.target_names[self.y_test[i]].rsplit(' ', 1)[-1]
- return 'predicted: %s\ntrue: %s' % (pred_name, true_name)
5.绘制参数与模型性能函数
- def create_model(dataset, choice, components):
- decomposition = my_decomposition(dataset, choice, components)
- my_svc = svm(dataset, decomposition, kernel='rbf', class_weight='balanced')
- my_svc.my_fit()
- return my_svc
- def acc_components(dataset, choice):
- """
- 绘制特征数和精度的关系,选择最好的特征数
- """
- total_acc = []
- acc_dict = {}
- for j in range(1, 150+1):
- decomposition = my_decomposition(dataset, choice, j)
- my_svc = svm(dataset, decomposition, kernel='rbf',
- class_weight='balanced')
- my_svc.my_fit()
- y_pred = my_svc.my_predict()
- y_true = my_svc.y_test
- total_acc.append(accuracy_score(y_true, y_pred))
- print(choice, " ", j)
- return total_acc
- def plot_acc_components(my_dataset):
- """
- 基于多个降维算法,绘制特征数和精度的关系,选择最好的特征数
- """
- acc_pca = acc_components(my_dataset, "pca")
- acc_kpca = acc_components(my_dataset, "kpca")
- acc_mds = acc_components(my_dataset, "mds")
- acc_lle = acc_components(my_dataset, "lle")
- acc_isomap = acc_components(my_dataset, "isomap")
- x = range(1, (len(acc_pca)+1))
- plt.figure()
- # 去除顶部和右边框框
- ax = plt.axes()
- ax.spines['top'].set_visible(False)
- ax.spines['right'].set_visible(False)
- plt.xlabel('components') # x轴标签
- plt.ylabel('accuracy') # y轴标签
- # 以x_train_loss为横坐标,y_train_loss为纵坐标,曲线宽度为1,实线,增加标签,训练损失,
- # 默认颜色,如果想更改颜色,可以增加参数color='red',这是红色。
- plt.plot(x, acc_pca, linewidth=1, linestyle="solid", label="PCA")
- plt.plot(x, acc_kpca, linewidth=1, linestyle="solid", label="KPCA")
- plt.plot(x, acc_mds, linewidth=1, linestyle="solid", label="MDS")
- plt.plot(x, acc_lle, linewidth=1, linestyle="solid", label="LLE")
- plt.plot(x, acc_isomap, linewidth=1, linestyle="solid", label="ISOMAP")
- plt.legend()
- plt.title('accuracy curve')
- plt.savefig("./模式识别课设/filename.png")
- # plt.show()
6.绘制ROC曲线
- def plot_Macro_roc(dataset,choices,colors,components=150,save=True, dpin=100):
- """
- 将使用多个降维算法的模型的roc图输出到一张图上
- Args:
- choice: list, 多个模型的名称
- sampling_methods: list, 多个模型的实例化对象
- save: 选择是否将结果保存(默认为png格式)
- Returns:
- 返回图片对象plt
- """
- n_classes = dataset.n_classes
- plt.figure(figsize=(20, 20), dpi=dpin)
- # 计算每个类别的ROC曲线和AUC面积
- fpr = dict()
- tpr = dict()
- roc_auc = dict()
- for (choice, colorname) in zip(choices, colors):
- print(choice)
- model = create_model(dataset, choice, components)
- y_test = model.y_test
- y_test = label_binarize(y_test,classes=range(n_classes))
- X_test = model.X_test_re
- y_scores = model.decision_function(X_test)
- # print(y_test.shape)
- # print(y_scores.shape)
- # print(X_test)
- for i in range(n_classes):
- fpr[i], tpr[i], _ = roc_curve(y_test[:,i], y_scores[:, i])
- roc_auc[i] = auc(fpr[i], tpr[i])
- # 首先收集所有的假正率
- all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
- # 然后在此点内插所有ROC曲线
- mean_tpr = np.zeros_like(all_fpr)
- for i in range(n_classes):
- mean_tpr += interp(all_fpr, fpr[i], tpr[i])
- # 最终计算平均和ROC
- mean_tpr /= n_classes
- fpr["macro"] = all_fpr
- tpr["macro"] = mean_tpr
- roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
- plt.plot(fpr["macro"], tpr["macro"], lw=5, label='{} (AUC={:.3f})'.format(choice, roc_auc["macro"]),color = colorname)
- # 绘制对角线
- plt.plot([0, 1], [0, 1], '--', lw=5, color = 'grey')
- plt.axis('square')
- plt.xlim([0, 1])
- plt.ylim([0, 1])
- plt.xlabel('False Positive Rate',fontsize=20)
- plt.ylabel('True Positive Rate',fontsize=20)
- plt.title('Macro-averaged One-vs-Rest \n Receiver Operating Characteristic',fontsize=25)
- plt.legend(loc='lower right',fontsize=20)
- if save:
- plt.savefig('Macro Curve.png')
- return plt
- def plot_Micro_roc(dataset,choices,colors,components=150,save=True, dpin=100):
- """
- 将使用多个降维算法的模型的roc图输出到一张图上
- Args:
- choice: list, 多个模型的名称
- sampling_methods: list, 多个模型的实例化对象
- save: 选择是否将结果保存(默认为png格式)
- Returns:
- 返回图片对象plt
- """
- n_classes = dataset.n_classes
- plt.figure(figsize=(20, 20), dpi=dpin)
- # 计算每个类别的ROC曲线和AUC面积
- fpr = dict()
- tpr = dict()
- roc_auc = dict()
- for (choice, colorname) in zip(choices, colors):
- print(choice)
- model = create_model(dataset, choice, components)
- y_test = model.y_test
- y_test = label_binarize(y_test,classes=range(n_classes))
- X_test = model.X_test_re
- y_scores = model.decision_function(X_test)
- # 计算ROC曲线和AUC面积的微观平均(micro-averaging)
- fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_scores.ravel())
- roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
- plt.plot(fpr["micro"], tpr["micro"], lw=5, label='{} (AUC={:.3f})'.format(choice, roc_auc["micro"]),color = colorname)
- # 绘制对角线
- plt.plot([0, 1], [0, 1], '--', lw=5, color = 'grey')
- plt.axis('square')
- plt.xlim([0, 1])
- plt.ylim([0, 1])
- plt.xlabel('False Positive Rate',fontsize=20)
- plt.ylabel('True Positive Rate',fontsize=20)
- plt.title('Micro-averaged One-vs-Rest \n Receiver Operating Characteristic',fontsize=25)
- plt.legend(loc='lower right',fontsize=20)
- if save:
- plt.savefig('Micro Curve.png')
- return plt
7.主函数设计
- choices = ["pca+svm",
- "kpca+svm",
- "lle+svm",
- "isomap+svm",
- "mds+svm",
- 'svm'
- ]
- colors = ['crimson',
- 'orange',
- 'gold',
- 'mediumseagreen',
- 'steelblue',
- 'red'
- ]
- choice, n_components = "pca+svm", 150
- # min_faces_per_person每个人至少选取x张图像
- my_dataset = my_dataset(min_faces_per_person=70, resize=0.4)
- ## 绘制指标图
- plot_Macro_roc(my_dataset,choices,colors)
- plot_Micro_roc(my_dataset,choices,colors)
- ## 绘制维数参数与准确率关系
- plot_acc_components(my_dataset)
- # 绘制样本图
- my_decomposition = my_decomposition(my_dataset,choice,n_components)
- my_svc = svm(my_dataset,my_decomposition,kernel='rbf', class_weight='balanced')
- my_svc.my_fit()
- my_svc.plot_gallery(plot_type="train",start=0,n_row=4, n_col=4)
- # my_decomposition = my_decomposition(my_dataset,choice,n_components)
- # my_svc = svm(my_dataset,my_decomposition,kernel='rbf', class_weight='balanced')
- t0 = time()
- # PCA降维
- my_svc.my_fit()
- # print("经过PCA降维训练时间 %0.3fs" % (time() - t0))
- y_pred = my_svc.my_predict()
- my_svc.model_report()
- my_decomposition.model_report()
- # 画测试结果
- my_svc.plot_gallery(plot_type="test",start=0,n_row=4, n_col=4)
- plt.show()
- t0 = time()
- # KPCA降维
- my_svc.my_fit(n_components=150,choice="kpca")
- y_pred = my_svc.my_predict()
- # print("经过KPCA降维训练时间 %0.3fs" % (time() - t0))
- # 画测试结果
- my_svc.plot_gallery(plot_type="test",start=50,n_row=4, n_col=4)
- plt.show()
- t0 = time()
- # lle降维
- my_svc.my_fit(n_components=150,choice="lle")
- # print("经过LLE降维训练时间 %0.3fs" % (time() - t0))
- y_pred = my_svc.my_predict()
- # 画测试结果
- my_svc.plot_gallery(plot_type="test",start=50,n_row=4, n_col=4)
- plt.show()
- t0 = time()
- # isomap降维
- my_svc.my_fit(n_components=150,choice="isomap")
- # print("经过ISOMAP降维训练时间 %0.3fs" % (time() - t0))
- y_pred = my_svc.my_predict()
- # 画测试结果
- my_svc.plot_gallery(plot_type="test",start=50,n_row=4, n_col=4)
- plt.show()
- t0 = time()
- # mds降维
- my_svc.my_fit(n_components=150,choice="mds")
- # print("经过ISOMAP降维训练时间 %0.3fs" % (time() - t0))
- y_pred = my_svc.my_predict()
- # 画测试结果
- my_svc.plot_gallery(plot_type="test",start=50,n_row=4, n_col=4)
- plt.show()