[1]https://www.cnblogs.com/pinard/p/6266408.html
[2]Graph Embedding Techniques, Applications, and Performance: A Survey
主要参考和图片来源[1]
-
- LLE推导
- 算法流程
局部线性嵌入(Locally Linear Embedding,LLE),一种重要降维方法,与PCA、LDA相比,更注重保持样本局部线性特征,常用语图像识别、高维数据可视化等。
数学意义上的流形:一个不闭合曲面,曲面上数据分布均匀,特征比较稠密,流形降维就是把流形从高维到低维的降维过程,并在降维中保留流形高维的特征。

我的理解:数据分布于高维的一个曲面,流行学习就是将这个曲面降维展开表达出来

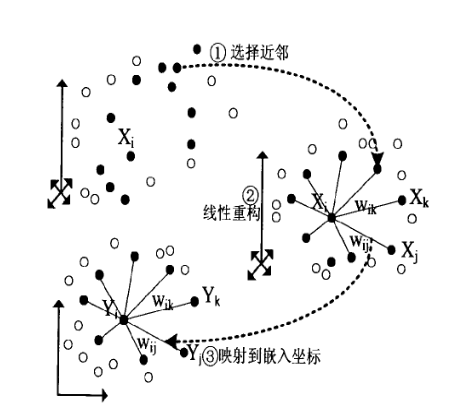
LLE
LLE假设数据在较小的局部是线性的,即样本 x1 x 1 可以由K个近邻样本 x2,x3,x4 x 2 , x 3 , x 4 线性表示
则希望降维之后依然保持这种线性关系
由于只考虑了局部线性关系,所以复杂度低很多
LLE推导
首先设定邻域大小k,然后寻找某个样本与近邻样本的线性关系,即权重系数。
假设有m个n维样本 {x1,x2,...,xm} { x 1 , x 2 , . . . , x m } ,则有损失函数
对权重系数有归一化限制
对损失函数矩阵化
其中 Wi=(wi1,wi2,...,wik)T W i = ( w i 1 , w i 2 , . . . , w i k ) T
表示局部协方差 Zi=(xi−xj)T(xi−xj) Z i = ( x i − x j ) T ( x i − x j )
则简化为
对约束有
其中1k为k维全1向量
则拉格朗日乘子法:
对W求导取0得
则
利用约束做归一化有
注:把 1Tk挪到左边就对上了。。。 1 k T 挪 到 左 边 就 对 上 了 。 。 。
至此,获得高维的权重系数,希望权重系数保持。设定n维样本集 {x1,x2,...,xm} { x 1 , x 2 , . . . , x m } 在低维的d维度投影为 {y1,y2,...,ym} { y 1 , y 2 , . . . , y m } ,希望保持线性关系且均方差损失函数最小,则最小化损失函数
J(y)=∑i=1m‖yi−∑j=1kwijyj‖22 J ( y ) = ∑ i = 1 m ‖ y i − ∑ j = 1 k w i j y j ‖ 2 2
区别在于高维的时候是求权重系数W,低维时是求低位数据Y
为了得到标准化低维数据,加入约束条件
∑i=1myi=0;1m∑i=1myiyTi=I ∑ i = 1 m y i = 0 ; 1 m ∑ i = 1 m y i y i T = I
将目标损失函数矩阵化
令 M=(I−W)T(I−W) M = ( I − W ) T ( I − W ) ,则最小化 J(Y)=tr(YTMY) J ( Y ) = t r ( Y T M Y ) ,约束函数矩阵化为 YTY=mI Y T Y = m I
通过拉格朗日函数得到
求导取0得到
则求出矩阵M的最小的d个特征值所对应的d个特征向量组成矩阵 Y=(y1,y2,...,yd) Y = ( y 1 , y 2 , . . . , y d )
注,一般最小的特征值为0不能反映数据特征,因此取[1,d+1]小的特征值的特征向量。(这里因为最小化目标,所以取小的特征值)
算法流程
总结一波流程:K近邻=>算权重系数=>算降维后的矩阵


LLE算法的主要优点有:
1)可以学习任意维的局部线性的低维流形
2)算法归结为稀疏矩阵特征分解,计算复杂度相对较小,实现容易。
LLE算法的主要缺点有:
1)算法所学习的流形只能是不闭合的,且样本集是稠密均匀的。
2)算法对最近邻样本数的选择敏感,不同的最近邻数对最后的降维结果有很大影响。