本文代码及数据集来自《Python大数据分析与机器学习商业案例实战》
决策树模型的建树依据主要用到的是基尼系数的概念。基尼系数(gini)用于计算一个系统中的失序现象,即系统的混乱程度。基尼系数越高,系统的混乱程度就越高,建立决策树模型的目的就是降低系统的混乱程度,根据基尼系数判断如何划分节点,从而得到合适的数据分类效果。采用基尼系数进行运算的决策树也称为CART决策树。
回归决策树模型的概念和分类决策树模型基本一致,最大的不同就是其划分标准不是基尼系数或信息熵,而是均方误差MSE。
案例实战:员工离职预测模型搭建
# 1.数据读取与预处理
import pandas as pd
df = pd.read_excel('员工离职预测模型.xlsx')
print(df.head())
运行结果:

原始数据中的“工资”数据被分为“高”“中”“低”3个等级,而Python数学建模中无法识别这种文本内容,所以“工资”列的内容需要进行数值化处理。这里用pandas库中的replace()函数将文本“高”“中”“低”分别替换为数字2、1、0。
df = df.replace({'工资': {'低': 0, '中': 1, '高': 2}})# 2.提取特征变量和目标变量
X = df.drop(columns='离职')
y = df['离职']# 3.划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
为了保证程序每次运行时都能采用相同的节点划分方式,以获得相同的决策树,就需要设置random_state参数。这里设置的数字123没有特殊含义,它只是一个随机数种子,也可以设置成其他数字。
# 4.模型训练及搭建
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=3, random_state=123)
model.fit(X_train, y_train)
至此,一个决策树模型便搭建完成了。这里把测试集中的数据导入模型中进行预测,通过打印y_pred[0:100]查看预测结果的前100项。
# **1.直接预测是否离职**
y_pred = model.predict(X_test)
print(y_pred[0:100])
运行结果:

接着将模型的预测值y_pred和测试集的实际值y_test进行汇总。其中y_pred是一个numpy.ndarray类型的一维数组结构,y_test为Series类型的一维序列结构,用list()函数将它们都转换为列表,并将它们集成到一个DataFrame中,代码如下。
a = pd.DataFrame()
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
运行结果:

#查看模型评分
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)model.score(X_test, y_test)
将score打印输出,结果为0.9573,也就是说,模型对整个测试集的预测准确度为0.9573,即在3000组测试集数据中有约2872组数据的预测结果和实际结果相符。
# **2.预测不离职&离职概率**
y_pred_proba = model.predict_proba(X_test)
print(y_pred_proba[0:5])
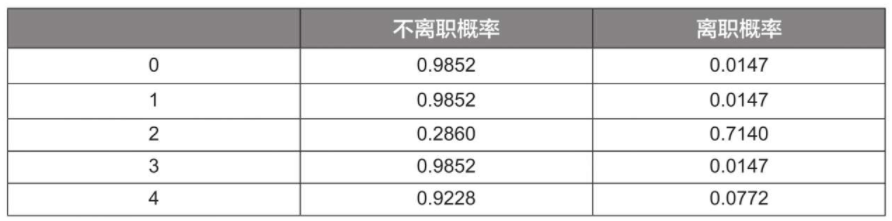
#获得的y_pred_proba是一个二维数组,数组左列为分类为0的概率,右列为分类为1的概率;也可以通过如下代码将其转换为DataFrame格式以方便查看。
b = pd.DataFrame(y_pred_proba, columns=['不离职概率', '离职概率'])
print(b.head())
#提取离职概率
print(y_pred_proba[:,1])
运行结果:
# **3.模型预测效果评估**
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test, y_pred_proba[:,1])a = pd.DataFrame()
a['阈值'] = list(thres)
a['假警报率'] = list(fpr)
a['命中率'] = list(tpr)
a.head()
运行结果:

#绘制ROC曲线
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)
plt.show()#求出模型的AUC值
from sklearn.metrics import roc_auc_score
score = roc_auc_score(y_test, y_pred_proba[:,1])
print(score)
运行结果:

AUC=0.9736722483245008。
模型搭建完成后,有时还需要知道各个特征变量的重要程度,即哪些特征变量在模型中发挥的作用更大,这个重要程度称为特征重要性。在决策树模型中,一个特征变量对模型整体的基尼系数下降的贡献越大,它的特征重要性就越大。
# **4.特征重要性评估**
print(model.feature_importances_)features = X.columns
importances = model.feature_importances_importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False) #设置ascending参数为False表示进行降序排序
运行结果:
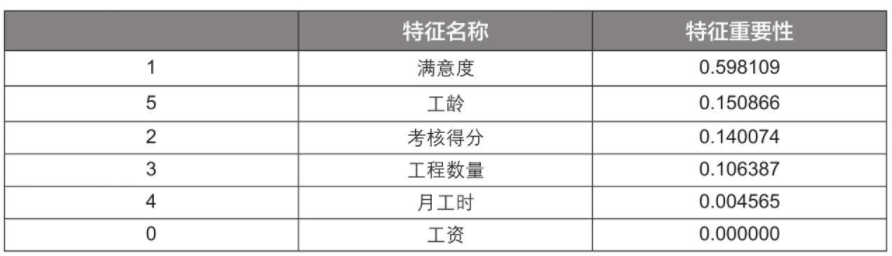
可以看到,特征重要性最高的是“满意度”,这一点的确符合常理,因为员工对工作的满意度高,其离职的概率就相对较低,反之则较高。其次重要的是“考核得分”和“工龄”。
“工资”在该模型中的特征重要性为0,也就是说它没有发挥作用,这并不符合常理。之所以会有这个结果,在某种程度上是因为我们限制了决策树的最大深度为3层(max_depth=3),所以“工资”没有发挥作用的机会,如果增大决策树的最大深度,那么它可能会发挥作用。
另一个更重要的原因是本案例中的“工资”不是具体的数值,而是“高”“中”“低”3个档次,这种划分方式过于宽泛,使得该特征变量在决策树模型中发挥的作用较小,如果“工资”是具体的数值,如10000元,那么该特征变量应该会发挥更大的作用。
决策树可视化插件Graphviz的安装
首先下载Graphviz插件,下载地址为https://graphviz.gitlab.io/download/。以Windows版本为例,在如下图所示的网页中单击相应的链接,进入Windows版本的下载页面。

下载完成后运行exe文件。

记住文件的安装位置,本文直接装在D盘,路径为:D:\Graphviz。安装完成后在anaconda安装graphviz库。

安装完成后就可以使用了,注意代码中的路径修改,本文的环境为D:\Graphviz\bin。
# **决策树模型可视化呈现及决策树要点理解**
# 1.如果不用显示中文,那么通过如下代码即可:
# !pip3 install pygraphvizfrom sklearn.tree import export_graphviz
import graphviz
import os
#将Graphviz插件安装路径下的bin文件夹部署到环境变量中
os.environ['PATH'] = os.pathsep + r'D:\Graphviz\bin'#用export_graphviz()函数将之前搭建的决策树模型model转换为字符串格式并赋给变量dot_data
#其中需要设定out_file参数为None,转换后获得的内容才为字符串格式
dot_data = export_graphviz(model, out_file=None, class_names=['0', '1'])#将dot_data转换成可视化的格式
graph = graphviz.Source(dot_data)#导出成PDF文件
graph.render("result")
print('可视化文件result.pdf已经保存在代码所在文件夹!')
运行结果:
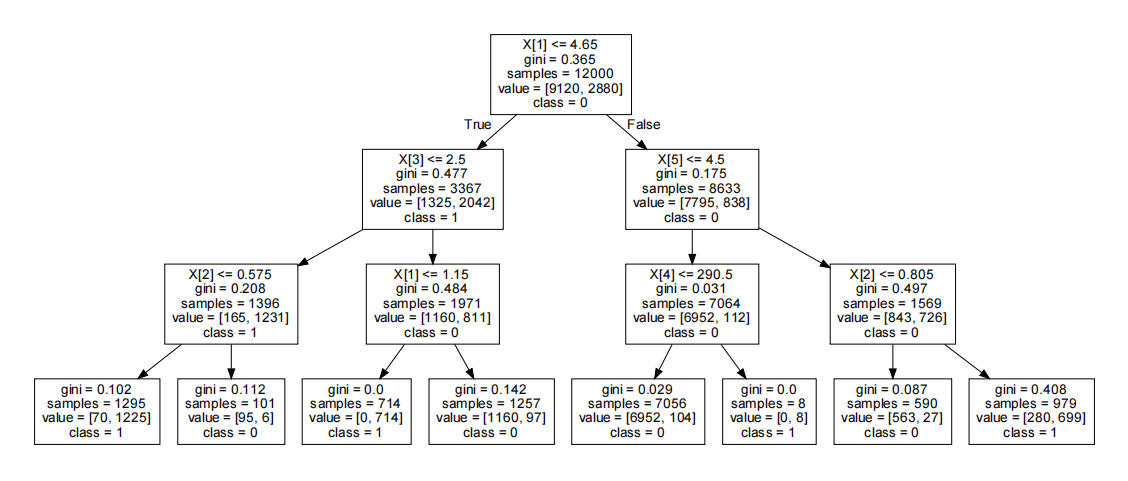
其中X[1]表示第2个特征变量“满意度”,X[2]表示第3个特征变量“考核得分”,X[3]表示第4个特征变量“工程数量”,X[4]表示第5个特征变量“月工时”,X[5]表示第6个特征变量“工龄”;gini表示该节点的基尼系数;samples表示该节点中的样本数,例如,根节点中的12000即训练集中的样本数;value表示样本中各类别的数量,例如,根节点的value后面的中括号中,左边的9120表示不离职员工的数量,右边的2880表示离职员工的数量;class表示分类类别,例如,class=0表示判定该节点为“不离职”节点。
dot_data = export_graphviz(model, out_file=None, feature_names=['income', 'satisfication', 'score', 'project_num', 'hours', 'year'], class_names=['0', '1'], filled=True)
graph = graphviz.Source(dot_data)
graph.render("result")
print('可视化文件result.pdf已经保存在代码所在文件夹!')
也可修改以上代码,把变量名添进图中,并添加颜色。运行结果:

因为Graphviz插件不直接支持中文,所以需要进行特殊处理,可以采用如下代码:
#2.如果想显示中文,需要使用如下代码
from sklearn.tree import export_graphviz
import os
# 以下这行是手动进行环境变量配置,防止在本机环境的变量部署失败
os.environ['PATH'] = os.pathsep + r'D:\Graphviz\bin'dot_data = export_graphviz(model, out_file=None, feature_names=X_train.columns, class_names=['不离职', '离职'], rounded=True, filled=True)
# rounded与字体有关,filled设置颜色填充
f = open('dot_data.txt', 'w')
f.write(dot_data)
f.close()#修改字体设置,避免中文乱码
import re
f_old = open('dot_data.txt', 'r')
f_new = open('dot_data_new.txt', 'w', encoding='utf-8')
for line in f_old:if 'fontname' in line:font_re = 'fontname=(.*?)]'old_font = re.findall(font_re, line)[0]line = line.replace(old_font, 'SimHei')f_new.write(line)
f_old.close()
f_new.close()os.system('dot -Tpng dot_data_new.txt -o 决策树模型.png')
print('决策树模型.png已经保存在代码所在文件夹!')os.system('dot -Tpdf dot_data_new.txt -o 决策树模型.pdf')
print('决策树模型.pdf已经保存在代码所在文件夹!')
运行结果:




![[Ansys Workbench] Mechanical 界面显示模型树窗口和详细信息窗口](https://img-blog.csdnimg.cn/a14d47d299994130825df7a7beb0c7c7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5buJ5Lu35Za1,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)