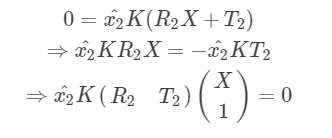目前主流的SfM(Structure from Motion,运动结构恢复)可以分为两大类型,一种是全局式的,一种是增量式的。全局式(Global)sfm能够一次性得出所有的相机姿态和场景点结构。它通常先求得所有相机的位姿,然后再通过三角化获得场景点。其中相机位姿求解也分为两步:第一步是求解全局旋转,第二步是根据全局旋转求解全局平移向量。因为第二步的计算依赖于第一步的输出,因此第一步输出结果的准确性直接决定了第二步的结果的优劣,也就是说,全局旋转的求解是相机姿态估计的核心关键问题。全局式sfm只需要在最后进行一次BA(Bundle Adjustment),因此效率较高,但是其鲁棒性差,很容易受到outlier的影响而导致重建失败。增量式(Incremental)sfm则是一边三角化(triangulation)和pnp(perspective-n-points),一边进行局部BA。这类方法在每次添加图像后都要进行一次BA,效率较低,而且由于误差累积,容易出现漂移问题;但是增量式sfm的鲁棒性较高。著名的开源库Colmap就是通过增量式sfm的pipeline实现的。而OpenMVG则同时实现了增量式和全局式两种pipeline。
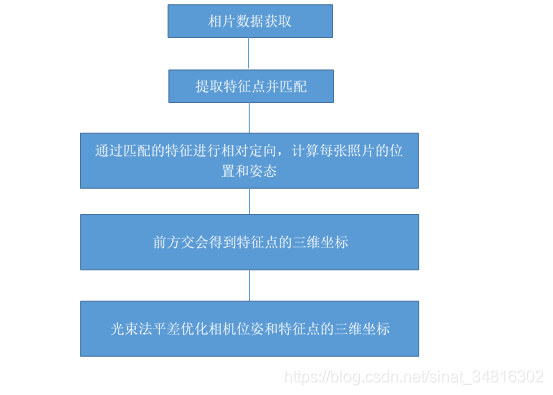
首先先上state-of-art开源库colmap的官方论文中的增量式sfm流程图:

感兴趣的小伙伴可以直接从这里下载原论文来看,免费。关于该论文的详细内容,可以参考我的这篇博客:Colmap论文——《Structure-from-Motion Revisited》论文阅读笔记。
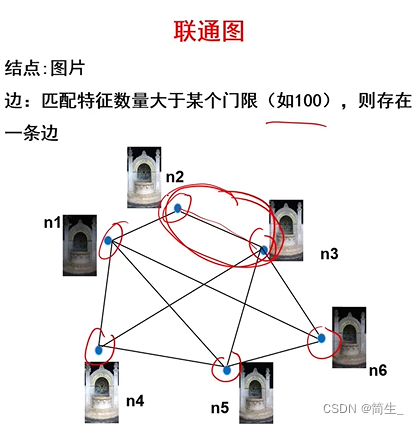
下图则是OpenMVG系统的详细流程。该流程与我下面介绍的自己复现增量式SfM的流程相似,只是它这里以图的方式对图像间的匹配关系进行了描述(感觉上更高大上了,但是这样描述也更容易劝退新人)。

下面介绍一下我在复现增量式sfm后对该框架的理解。在实现过程中主要调用了opencv、siftgpu和ceres库,部分实现代码参考了colmap。流程及使用的库(用[]标出)主要如下:
1. 图像数据读取 [opencv]
读取图像是为了可视化检查特征提取与匹配的正确性以及在三角化后获取三维点的颜色值,如果不需要这两步操作的话,可以直接跳过这一步,因为使用siftgpu库进行特征提取时只需要输入图像路径即可,不需要把图像数据读取到内存中。
2. 特征点提取和描述子计算 [siftgpu]
有别于SLAM,sfm并不要求实时性,所以通常使用更为可靠稳健的SIFT(Scale-Invariant Feature Transform)特征点,对应的描述子也称为sift描述子。有想了解sift特征点提取原理流程的,可以从这里下载sift文档来看,也可以参考博客1、博客2。siftgpu可以同时提取特征点并计算描述子,其描述子类型为128维的float。
3. 匹配图像对搜索 [siftgpu]
这里需要分为两个步骤,一个是可能存在匹配关系的图像对之间的匹配搜索,一个是图像对之间的特征点描述子之间的匹配。
首先是匹配图像对的搜索方式,包括:
- 穷举法:对所有图像进行两两匹配
- 空间匹配:基于GPS信息,有些图像的EXIF信息里就会带有这个信息,然后通过GPS计算空间距离,来缩小搜索范围。这一方式在机载影像的匹配图像对搜索中最为常用。
- 匹配关系传递:基于这么一个事实,若A与B匹配、B与C匹配,则A与C也很可能会存在匹配关系。
- 视觉词袋(Bag of Words):基于视觉词袋模型的图像分类系统主要由四个部分组成,分别为:图像底层特征提取、视觉词典生成、视觉词汇特征构建和分类器。要完成图像分类,首先需要生成一个规模适当的视觉词典,又称为视觉码本;然后,对于一幅待处理图像,提取出相应的底层特征后,依据视觉词典来构建该图像的视觉词汇特征;最后,将该视觉词汇特征输入已训练好的分类器中,得到该图像类别。(参考)
- 词汇树(Vocabulary Tree):在这种匹配模式下,每幅图像都会通过空间重新排序的词汇树与其视觉近邻进行匹配。这是大型图像集合(数千张)的推荐匹配模式(细节可参考)。与视觉词袋相比,词汇树利用层次kmeans得到尽可能多的特征。层次kmeans的意思是将空间中的点用普通kmeans得到k个聚类中心,每个点都属于一个聚类中心代表的类。对于一类中的所有点,再递归的进行kmeans,直到获得我们想要的聚类中心个数。这样的聚类方法相比普通kmeans聚类可以得到更多的聚类中心,同时花费的时间更加少。
- 序列匹配:和SLAM中一样,若拍摄图像如视频一般是有序的,那么直接根据顺序信息进行匹配即可,当然,可能不同时序的图像之间也会存在匹配关系,所以通常会结合词汇树方式一同使用。
上面的方式只是搜索出可能存在匹配关系的图像对,但是图像对内,哪些特征点之间是互相匹配的呢?这也需要进行计算(参考):
- 暴力匹配(Brute Force Matching):对两张图像上的所有描述子之间都进行一个相似度计算,认为相似度最大的是一个匹配点对。描述子距离的度量有L1范数(差值的绝对值之和)、L2范数(差值的平方和)、汉明距离(针对二进制描述子,对应位相同为0,相异为1)等。
- FLANN (Fast Library for Approximate Nearest Neighbors)快速最近邻匹配:FLANN训练了一种索引结构,用于遍历使用机器学习概念创建的潜在匹配候选对象。该库构建了非常有效的数据结构(KD树)来搜索匹配对,并避免了穷举法的穷举搜索。因此,速度更快,结果也非常好,但是仍然需要调试匹配参数。
由于我重建的主要是无人机影像,然后每张影像有gps测得的经纬度坐标,所以我在图像匹配的时候,借助了经纬度坐标进行邻域搜索,只对一定范围内的图像进行匹配。
4. RANSAC精化匹配点对 [opencv]
由于遮挡、重复纹理等因素,sift提取的特征点和描述子在匹配过程中会存在误匹配的情况,所以需要将错误的匹配点对剔除。这里的错误匹配点对剔除通常包含两个步骤,最初始的剔除通常使用比值测试(ratio test)和交叉验证( cross check)进行。其中基于最近距离和次近距离(这里的距离指描述子之间的相似性)比值的比值测试用于剔除不满足给定阈值的匹配对;其次,交叉验证用于选择两个方向能够互相为最近邻点的匹配。这两个步骤是最基本的剔除策略,之后还需要经过进一步的剔除。一个很简单粗暴的方法就是直接通过计算匹配点对的距离(这里的距离是指像素点坐标的距离),然后把距离大于一定阈值的匹配舍弃掉。但是这种方法只能剔除掉一部分错误匹配,比如距离小于阈值的错误匹配就无法剔除,且阈值的确定也是一个问题。由于该方法过于简陋且没有有力的理论依据,因此不应用于实际中。
通常采用的方法可以分为两种,显式和隐式。显式方法一般是利用E矩阵(Essential Matrix,本质矩阵)或者F矩阵(Fundamental Matrix,基础矩阵)等,通过RANSAC来去除错误匹配。具体操作是,随机选取图像对的8对及以上匹配点,使用归一化八点算法求解基础矩阵F(相机内参K未知),然后统计满足(当然由于误差存在不可能完全满足,一般是将Sampson误差在一定阈值范围内的点对视为内点)对极几何关系x’TFx=0的点对数量,其中x和x’为图像点。重复该过程若干次,选取满足条件的点对数量最多的匹配为精化匹配结果。
虽然RANSAC具有较强的抗外点能力,但是随着初始匹配外点率的提高(超过50%),RANSAC算法的性能出现显著下降。与基于RANSAC算法的显式参数估计不同,隐式参数估计方法具有更强的抗噪声能力,并在特征匹配粗差剔除中得到应用。其中霍夫变换(Hough transformation, HT)是常用方法,其基本思想是利用待估计的参数对投票空间进行划分、投票计数。
5. 增量式sfm初始化
初始化主要是指选取两张匹配的图像,设定其中一张图像的位姿为单位阵,然后通过它们之间的匹配点对估计出E矩阵,将E矩阵分解获得另一张图像的位姿。在估计出两张图像的位姿后,就可以通过三角化(triangulation)来生成三维点。初始图像对的选择是后续增量式重建的基础,如果这一步误差过大,通过误差的累积和传递效应,后续重建很可能会直接失败。因此,很多方法对该步骤进行了严格的要求。比如,OpenMVG在选取初始匹配图像对时,要求所有对应点三角化时射线夹角的中位数介于3°~60°之间。因为图像对的基线过长,容易出现遮挡的问题,导致对应关系不准确;而基线过短,则特征点点位的误差会被放大,导致重建精度降低。
6. 初始化后是一个循环,每次新加入一张图像
每次循环包括如下四步:
1. 获取下一最佳匹配图像(匹配点对数量最多),这里记为Inext
2. 对Inext进行pnp估计位姿(pose)
3. 对Inext进行三角化生成三维空间点
4. 对所有已生成的三维点和已估计出的位姿进行ba优化 [ceres]
这四步里面涉及到很多的trick,感觉是整个增量式sfm的核心所在。前三步的trick可以参考我的这篇博客:https://blog.csdn.net/weixin_44120025/article/details/111085028。ba部分我使用的是ceres库,在写ba的时候遇到了不少问题,有个小总结:https://blog.csdn.net/weixin_44120025/article/details/111052651。
对于第一步,colmap中提出的一个trick是,对特征点在图像上的分布进行打分,特征点数量越多,越均匀分布于图像上,得分越高。因为特征点的分布情况也会影响恢复的精度。
在这里,ba优化是通过最小化重投影误差实现的,待优化的变量包括三维空间点的坐标(x,y,z),相机内参(fx,fy,cx,cy),相机的畸变参数(k1,k2,k3,p1,p2),每张图像对应的相机位姿(R,t),在优化的时候,旋转矩阵R一般用四元数q(w,x,y,z)表示。需要注意的是,每轮ba过后都需要剔除误差过大的点(outliers)。
7. 对所有数据进行ba优化 [ceres]
全局优化,包括所有生成的三维点、相机位姿及内参数。在colmap中,有个trick是分组优化。它将图像分组,分成很多小的,较多重叠的组。每组内认为是同一个相机。因为在优化过程中,优化较多的是那些新加入的图像,其它的则仅仅是减小漂移。因此将图像分组优化会更高效。
8. 再三角化(可选)
再三角化的目的是因为刚开始的时候,由于加入的数据较少,优化的准确性较差,所以在使用ba进行重投影时,会剔除掉比较多的三维点(中间可能会有很多误剔除的)。随着加入图像数量的慢慢增多,优化的结果越来越准确,就可以重新对前面的图像进行三角化(把误剔除的点加回来),然后再进行ba优化。该trick由VisualSFM首次提出——当模型大小增加25%时,便re-triangulate这些失败的特征匹配。这一步不是必须的。
最后,贴上我复现增量式sfm的结果及部分复现过程中需要注意的问题:https://blog.csdn.net/weixin_44120025/article/details/111076614
以及,关于SfM的一些问题的答疑:https://blog.csdn.net/weixin_44120025/article/details/120530095
参考文献:
[1] Schonberger J L , Frahm J M . Structure-from-Motion Revisited[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016:4104-4113.
[2] Moulon P , Monasse P , Marlet R , et al. Global Fusion of Relative Motions for Robust, Accurate and Scalable Structure from Motion[C]// IEEE International Conference on Computer Vision. IEEE, 2013.