原文作者:月来客栈 https://www.zhihu.com/people/the_lastest
最快的方式:
第一,选择一篇有代码的论文,记住一定要有代码;
第二,大致弄清楚论文里所提出算法的思想原理;
第三,将自己新的想法加入到代码中,然后进行实验;
第四;调出一个至少和原论文差不多的结果,然后写成论文,对比算法就是原论文中对比的算法(到不用报告原论文提出的算法)。
这样做的好处就是,哪怕你新加入的东西并没有任何作用,但你只要能保证其最后的结果和原先的差不多,然后再编一个合理的动机来支持你的这一改进就行了。
1 前言
这两天笔者在知乎上被邀请回答这么一个问题“如何快速入门深度学习写论文?”。当时由于时间关系也就只是简单的回答了一下大概,因此在接下来的这篇文章中笔者将会重新系统的来回答一下这个问题。
通常,对于刚入门深度学习或者是机器学习的人来说,想要从零开始发表一篇论文还是相当有难度的,并且在这个阶段哪怕你费了九牛二虎之力换来的不一定就是想要的结果。那具体该怎么办呢?怎么才能快速的发出第一篇论文呢?
2 选择方向
对于初学者来说,首先要做的就是确定好自己的研究方向。这个研究方向可以是导师的课题,也可以是沿着师兄或者师姐的工作继续往下做。当然,如果这两者都没有的话,那首先可以通过阅读一些综述性的论文或者是根据自己的见闻和兴趣(例如CV、NLP等)来确定一个大致的方向;然后上网查找相关方向中有哪些细的分支,例如以NLP为例的话其细分领域就有文本分类、文本生成、命名体识别等。通常对于初学者来说,首先都应该挑选其中最简单的一个分支进行学习。
在确定相关研究方向后就需要开始阅读相关领域的论文了。那对于初学者来说应该如何进行这一过程呢?
3 论文阅读
通常来说,发表一篇论文都需要有一些自己新的创新点;而我们阅读论文的目的:一是为了了解相关基础知识;二就是为了通过多篇文章的阅读来获得改进的灵感。在阅读论文的时候,笔者认为最重要的两件事就是如何挑选论文与阅读论文。
3.1 挑选论文
对于人工智能这个领域来说,挑选论文的首选地址当然就是各大顶会的官网,例如NIPS[1]、ICML[2]、AAAI[3]、IJCAI[4]等等。我们首先可以打开各个顶会的官网,然后浏览一下最近三年左右(不要太远)被接收论文的标题,然后来初步选择自己可能会阅读的论文。以NIPS为例,在打开链接后我们就能看到一个历年接收论文的链接:

图 1. NIPS官网
接着我们点开2019年这个链接就能够看到如图2所示里被接收论文的题目:

图 2. NIPS 2019年接收论文
由于每年接收的论文有上千篇,如果一条一条来看的话可能会比较慢。因此你可以根据直接搜索关键字来进行定位,例如“text classification”、"sentence classification"等等。当然,有时间的话还是建议一条一条的扫一眼。
在初步根据确定一篇论文后,我们点击链接后就会看到如图3所示的页面:

图 3. 论文下载页面
从图3中可以看到,除了可以下载论文外,其它的评审意见和附件等都可以进行下载。由于是抱着快速发论文的目的,因此在打开论文后的第一件事情就是快速扫描全文,看看作者有没有提到代码的链接地址。
以上面这面论文为例。打开后笔者以code为关键字进行检索,很幸运的就看到了作者给出的地址:

图 4. 论文代码地址图
当然有的文章可能不会这么明显出现code这样的字眼,但你可以再试着以“implementation、github”等关键字在论文中进行搜索,如果搜索不到再快速扫描一下论文的内容可能就会找到了。
不过最难过的就是论文中丝毫没有提及代码这件事情,因此你也不知道他是否开源了代码。因此接下来你就要自己动手去网上查找相关代码。但通常来说,除非你下定决心要看这篇论文,或者说在这篇论文的基础上你有了改进的想法;不然的话直接换下一篇论文,因为可能作者根本就没有开放源码。如果你确实是前面的一种情况,那么有以下一些查找代码的方法进行参考。
3.2 查找代码
搜索代码的前提就是你一定要先列出一些关键词,然后再进行检索。很多人找不到论文代码的一个关键问题就是关键词太少。同时,如何有效筛选搜索到的结果也是一个关键,下面笔者将依次进行介绍。
对于检索的关键字一般的优先级可以是:①论文的标题;②论文中模型的全称名以及简称名,如XNAS;③各个作者的名字。检索地方一般的优先级可以是:①GitHub;②Google搜索;③CSDN搜索;④百度搜索。这里我们以在GitHub中搜索上面的论文代码为例进行介绍:
首先我们打开GitHub并以关键字“XNAS”进行搜索:
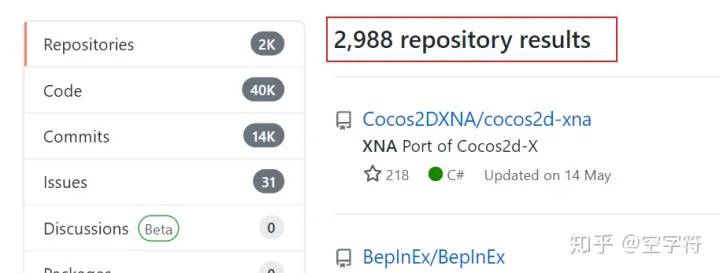
图 5. GitHub搜索结果图
从图5中可以看到,有2988个仓库都与关键字"XNAS"有关,但显然第一个就不是。接着往下看,会看到这么一个仓库:
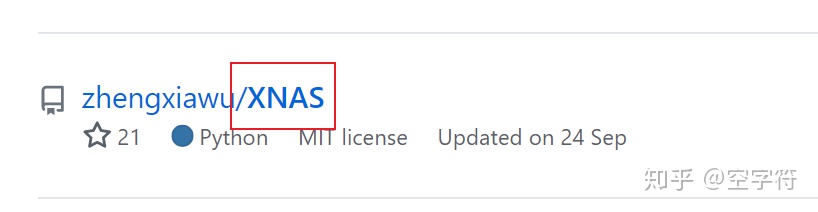
图 6. 类似XNAS
从这个仓库的名字来看,可能是论文中所提到的模型。但具体该怎么判断呢?首先可以点进去看看,如果主页上写了是基于这篇论文实现的,那么就可以肯定这个仓库就是XNAS的代码了。但此时不要高兴的过早,虽然它可能是对应论文的代码,但却不代表是论文作者自己开源的。有可能是其他人自己复现的代码。此时你就要甄别一下是否为原作者自己开源的,因为他人复现的代码可能存在错误。例如可以通过仓库对应的个人信息来判断他是不是论文作者的其中之一。
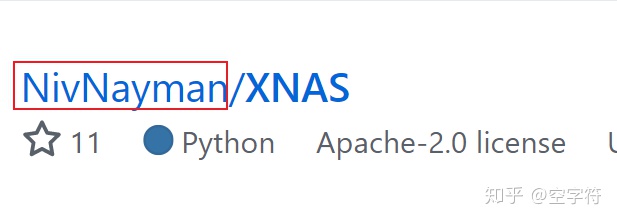
图 7. 作者开源XNAS
当然,对于XNAS这篇论文来说,当翻到第二页的时候就会发现作者本人开源的代码。但这并不是我们这里要介绍的重点。如图8所示,由于GitHub的默认搜索结果展示的都是与关键词相关的仓库,因此很多人在相关仓库中找不到代码就会关掉GitHub,然后说作者没有开源。
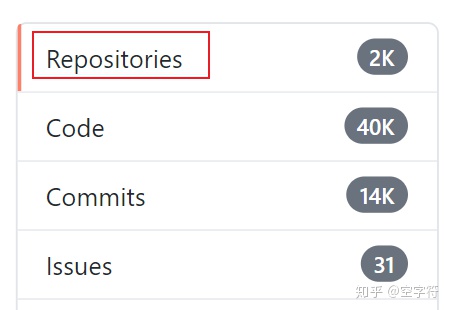
图 8. 默认搜索结果图
对于一些隐秘的代码,往往需要从后面这三栏中查找信息。如图9所示,如果你在以“Neural Architecture search with expert advice”为关键字进行检索,那么在默认的Repositories这一栏中并不会找到任何结果,而在Code这一栏中,你却可以一眼就看到作者开源的代码:
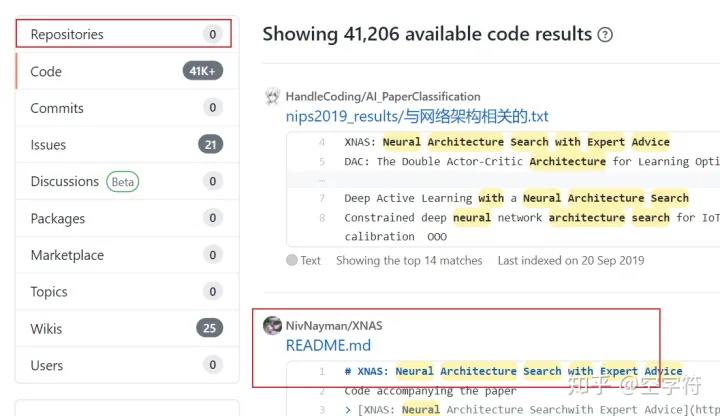
图 9. 从非Repositories中发现代码
因此,在通过GitHub查找代码时,一定不要忽略了这些信息。同时,根据图9可以发现,如果我们以论文第一个作者的名字“NivNayman”进行搜索,也是能够找到这份代码的。至于从其它几个网站的搜索其过程也大致如此,通过不同的关键字来进行搜索,然后筛选。
3.3 阅读论文
介绍完了如何查找论文与代码,那么接下来我们就来看看怎么阅读一篇论文。对于论文的阅读方法,真是100个人就有100种不同的观点。由于我们的目的就是要快速的出论文,所以对于拿到包含源码的论文一定要进行仔细的精读(实验部分可以暂时不看),尽可能的弄清楚论文中所提出模型的原理。如果你读完后就有了改动的想法,那么恭喜你可以直接进入到第4部分了。
如果你在看完第一篇后没有任何想法也不要慌,接着按上面的方法继续找下一篇论文继续精读,直到有了自己的改动想法为止。通常来说,只要你是仔细的完成了这个阅读过程,那么大约精读完3-4篇论文后你就会有了自己的想法。
这里也给大家推荐两篇掌柜对于Transformer和BERT模型原理到实现的详细解读:
月来客栈:This post is all you need(上卷)——层层剥开Transformer589 赞同 · 113 评论文章正在上传…重新上传取消
月来客栈:This post is all you need(下卷)——步步走进BERT43 赞同 · 9 评论文章正在上传…重新上传取消
4 实验
通常来说,我们在进行上述过程创新时都可以看作是A+B的创新模式,也就是将A模型中的(部分)技术融入到B模型中来(或者是替换掉B模型中的某个部分)。现在,假如我们要在B模型中加入A中的一些技术,那么就可以按照如下的步骤进行。
4.1 代码阅读与修改
对于B模型所对应的代码,首先我们需要弄懂代码的整个流程,每个模块(函数)的作用是什么,整个代码的运行流程是怎么样的;然后再定位到你需要改动的部分,将这个部分输入输出向量的类型、形状、含义弄清楚。但通常来说这一步会有一定的难度,因此更好的建议是把整个模型的代码一句一句的弄清楚(数据预处理的代码可以先不看),然后再进行后续的修改。
如果此时你对模型A中的要加入到模型B中的技术也熟悉的话,那么就直接可以进行后续的代码修改了。但如果你不知道如何实现新加入的这部分技术,那么你就要先去上网查查如何进行实现。例如PyTorch中怎么使用一个卷积层、怎么实现注意力机制、如何加入残差连接等。待到上述过程都准备完毕了,下一步就可以按照自己开始的想法对模型B进行改进了。
4.2 实验对比
在完成代码的阅读与修改后,下一步就可以开始跑实验了。在刚开始的过程中,实验出来的结果可能不是特别好,因此你就需要根据自己对整个模型的理解来调整模型里面相应的参数。不过要调到什么时候才算完呢?什么样的结果才足以发出一篇论文呢?
通常来说,你的结果只要不是最差的,基本都可以发论文了,但更保险的做法是至少你的结果要处于中等水平。例如你是在模型B的基础上进行的改进,且在该论文中除了模型B之外还有其它4个对比模型。那么只要你自己的模型跑出的结果能够处于第二或者第三的位置,那么基本上就可以开始准备写论文了。如果自己的结果实在不行怎么办呢?最后一招,那就是用对应的数据集名称在知网或者是谷歌学术中进行搜索,找到那些同样也使用了该数据集的论文,看看里面提及的模型结果是否比你的还差,如果是那就真的要恭喜你了。在最后进行实验对比时,你只需要将你自己的模型和比你差的模型放到一起对比分析即可。
同时,为了增加论文的篇幅或者是你改进后模型的说服力,你还可以在进行一组对比实验。例如在上面的创新过程中,如果你采用的是以A模型中的部分技术a,来替换掉B模型中的部分内容b的方式,那么你还可以将替换后(B-b+a)的实验结果与去掉B中该部分内容(B-b)的实验结果进行对比,以此来说明技术a的有效性。
5 撰写论文与投稿
在实验进行到后期的时候,你就可以开始着手撰写论文了。那对于论文的撰写该如何一步一步的进行呢?
5.1 确定框架与期刊
在撰写论文的时候,第一步要做的就是确定一个大致的论文框架。这里笔者建议的做法就是仿照你改进论文的框架大致列出一个结构;然后再参考一到两篇同类论文的框架结构进行修改。
在定完论文框架后就需要根据自己得到的实验结果,以及被修改论文的期刊等级来确定一个自己改进后论文的一个投稿等级。通常这一步可以去找自己的导师商量一下,然后再让导师给几个可以投稿的期刊。同时,可以先选一个等级稍微高一点的,如果被拒了再退而求其次。
这里特别需要注意的一点就是在筛选期刊的时候,一定要去网上搜索(例如小木虫上面就会有很多相应的信息)一下相关期刊的审稿流程和周期,因为有的期刊的审稿速度简直是慢到令人发指。一般来说可以根据自己可以接受的时间和对应期刊的等级来进行选择期刊,但如果是想要快速发表的话一般建议选择3个月内出一审结果的期刊。
5.2 写作与投稿
确定好论文框架与期刊后,就可以到对应期刊的官网去下载一份投稿模板,然后开始完成论文的撰写。对于第一次写论文的朋友来说可能真的是不知道如何下手。这里笔者建议的一个做法就同时打开两到三篇的同类型论文,然后看看他们是如何描写论文中的每一个部分的。你可以将不用论文中对同一事物在的表述进行糅合、或者是替换掉句式结构,总之同样的内容你变一个说法就是。最后一步一步的来完成整篇论文的撰写。
同时,如果你撰写的英文论文,但是你又不知道该替换成什么样的一个句式结构,或者说你想表达的东西参考论文里并没有出现。那么你这时候你就可以同时打开百度翻译或谷歌翻译(最好两者一起用),然后将你想要表达的中文翻译成对应的英文。需要注意的是只有在极少的情况下你可以将翻译后的结果直接拿来使用,通常情况下我们都需要对翻译后的句子再次进行加工处理。
在完成论文的撰写后,下一步就是拿去给自己的导师进行修改,让他给出相应的意见然后自己再对照着意见进行修稿。再这一步完成后,接下来就是投稿了。首先你需要去对应的官网注册一个账号;然后再按照官网里给出的投稿流程进行投稿即可。在投稿结束后,你就可以暂时的放松一下等待后续的结果了。
5.3 后续处理
如果你在前面选择的是会在3个月内出一审结果的期刊,那么你在对应的时间段里面就会收到编辑的邮件通知。如果对方明确说是创新不足什么什么的这就表示该期刊拒稿了。此时你也不用太灰心,赶快按上面步骤确定下一个期刊修改格式然后再进行投稿即可。如果对方邮件里没有明确的提到表示拒绝,只是说你这里应该这样调整,那里应该那样修改,以及可能有的审稿人可能会问为什么要那样做等等,这就表示你的论文百分之八十以上以没问题了。你只需要按照编辑或者审稿人的意见对你的论文进行大的调整,回答好审稿人的意见即可,然后在规定的日期里面回复到编辑那里去即可。
这里需要注意的是,不管审稿人提出什么样的意见,都要客气礼貌的进行回答,承认自己当时没讲清楚或者是没有考虑周到,然后将对应的内容补充上即可。如果是一些审稿人提出的问题比较尖锐,或者说完全和你自己的想法相左,那么也一定要重新再找一个角度来说服审稿人,不要表现出强势的观点,不然后面可能分分钟把你拒掉。
一般来说,在经历这样2-3次的修订后,你的论文就基本上就会被宣布接收了,你只要按流程付版面费即可。
6 总结
在这篇文章中,笔者首先介绍了选择自己的研究方向;然后笔者继续介绍了如何挑选合适的论文、查找论文对应的代码以及如何阅读一篇论文;接着介绍了怎么进行代码修改以及实验对比的技巧;最后介绍了如何挑选期刊、撰写论文以及对如何处理各类评审结果等。本次内容就到此结束,感谢您的阅读!青山不改,绿水长流,我们月来客栈见!
[1]NIPS: https://papers.nips.cc/
[2]ICML: https://icml.cc/
[3]AAAI: https://www.aaai.org/
[4]IJCAI: https://www.ijcai.org/past_conferences
[5]中国计算机学会(CCF)推荐中文科技期刊目录: https://www.ccf.org.cn/ccf/contentcore/resource/download?ID=101647
[6]中国计算机学会推荐国际学术会议和期刊目录2019 https://www.ccf.org.cn/ccf/contentc
# 整理一些论文资料,深度学习人工智能论文,来自深度之眼论文Paper 复盘资料,欢迎自取。
链接:https://pan.baidu.com/s/1PoVtY5kp7aQlR29U8C-zpw
提取码:ul0u