之前分享过一篇博客,👉不会这20个Spark热门技术点,你敢出去面试大数据吗?,那一篇确实是非常精华,提炼出了非常重要同样非常高频的Spark技术点,也算是收到了一些朋友们的好评。本篇博客,博主打算再出个番外篇,也就是再为大家分享一些Spark面试题,敢问各位准备好了么~

文章目录
- 1、Spark Application在没有获得足够的资源,job就开始执行了,可能会导致什么问题发生?
- 2、driver的功能是什么?
- 3、Spark中Work的主要工作是什么?
- 4、Spark为什么比mapreduce快?
- 5、Mapreduce和Spark的都是并行计算,那么他们有什么相同和区别?
- 6、Spark应用程序的执行过程是什么?
- 7、spark on yarn Cluster 模式下,ApplicationMaster和driver是在同一个进程么?
- 8、Spark on Yarn 模式有哪些优点?
- 9、spark中的RDD是什么,有哪些特性?
- 10、spark如何防止内存溢出?
- 11、spark中cache和persist的区别?
- 12、Spark手写WordCount程序
- 13、Spark中创建RDD的方式总结3种
- 14、常用算子
- 15、什么是宽窄依赖
- 16、任务划分的几个重要角色
- 17、SparkSQL中RDD、DataFrame、DataSet三者的区别与联系?
- 18、自定义函数的过程
1、Spark Application在没有获得足够的资源,job就开始执行了,可能会导致什么问题发生?
执行该job时候集群资源不足,导致执行job结束也没有分配足够的资源,分配了部分Executor,该job就开始执行task,应该是task的调度线程和Executor资源申请是异步的;如果想等待申请完所有的资源再执行job的:需要将spark.scheduler.maxRegisteredResourcesWaitingTime设置的很大;spark.scheduler.minRegisteredResourcesRatio 设置为1,但是应该结合实际考虑,否则很容易出现长时间分配不到资源,job一直不能运行的情况。
2、driver的功能是什么?
- 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,具有main函数,并且有SparkContext的实例,是程序的人口点;
- 功能:负责向集群申请资源,向master注册信息,负责了作业的调度,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler
3、Spark中Work的主要工作是什么?
主要功能:管理当前节点内存,CPU的使用状况,接收master分配过来的资源指令,通过ExecutorRunner启动程序分配任务。
worker就类似于包工头,管理分配新进程,做计算的服务,相当于process服务。
需要注意的是:
1)worker会不会汇报当前信息给master?worker心跳给master主要只有workid,它不会发送资源信息以心跳的方式给master,master分配的时候就知道work,只有出现故障的时候才会发送资源。
2)worker不会运行代码,具体运行的是Executor是可以运行具体appliaction写的业务逻辑代码,操作代码的节点,它不会运行程序的代码的。
4、Spark为什么比mapreduce快?
- spark是基于内存进行数据处理的,MapReduce是基于磁盘进行数据处理的
- spark中具有DAG有向无环图,DAG有向无环图在此过程中减少了shuffle以及落地磁盘的次数
- spark是粗粒度资源申请,也就是当提交spark application的时候,application会将所有的资源申请完毕,如果申请不到资源就等待,如果申请到资源才执行application,task在执行的时候就不需要自己去申请资源,task执行快,当最后一个task执行完之后task才会被释放。而MapReduce是细粒度资源申请,当提交application的时候,task执行时,自己申请资源,自己释放资源,task执行完毕之后,资源立即会被释放,task执行的慢,application执行的相对比较慢。
5、Mapreduce和Spark的都是并行计算,那么他们有什么相同和区别?
- hadoop的一个作业称为job,job里面分为map task和reduce task,每个task都是在自己的进程中运行的,当task结束时,进程也会结束。
- spark用户提交的任务成为application,一个application对应一个sparkcontext,app中存在多个job,每触发一次action操作就会产生一个job。这些job可以并行或串行执行,每个job中有多个stage,stage是shuffle过程中DAGSchaduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset有TaskSchaduler分发到各个executor中执行,executor的生命周期是和app一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算。
- hadoop的job只有map和reduce操作,表达能力比较欠缺而且在mr过程中会重复的读写hdfs,造成大量的io操作,多个job需要自己管理关系。 而spark的迭代计算都是在内存中进行的,API中提供了大量的RDD操作如join,groupby等,而且通过DAG图可以实现良好的容错。
6、Spark应用程序的执行过程是什么?
- 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
- Task在Executor上运行,运行完毕释放所有资源。
7、spark on yarn Cluster 模式下,ApplicationMaster和driver是在同一个进程么?
是,driver 位于ApplicationMaster进程中。该进程负责申请资源,还负责监控程序、资源的动态情况。
8、Spark on Yarn 模式有哪些优点?
- 与其他计算框架共享集群资源(eg.Spark框架与MapReduce框架同时运行,如果不用Yarn进行资源分配,MapReduce分到的内存资源会很少,效率低下);资源按需分配,进而提高集群资源利用等。
- 相较于Spark自带的Standalone模式,Yarn的资源分配更加细致
- Application部署简化,例如Spark,Storm等多种框架的应用由客户端提交后,由Yarn负责资源的管理和调度,利用Container作为资源隔离的单位,以它为单位去使用内存,cpu等。
- Yarn通过队列的方式,管理同时运行在Yarn集群中的多个服务,可根据不同类型的应用程序负载情况,调整对应的资源使用量,实现资源弹性管理。
9、spark中的RDD是什么,有哪些特性?
RDD(Resilient Distributed Dataset)叫做分布式数据集,是spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可以并行计算的集合。
五大特性:
- A list of partitions:一个分区列表,RDD中的数据都存储在一个分区列表中
- A function for computing each split:作用在每一个分区中的函数
- A list of dependencies on other RDDs:一个RDD依赖于其他多个RDD,这个点很重要,RDD的容错机制就是依据这个特性而来的
- Optionally,a Partitioner for key-value RDDs(eg:to say that the RDD is hash-partitioned):可选的,针对于kv类型的RDD才有这个特性,作用是决定了数据的来源以及数据处理后的去向
- 可选项,数据本地性,数据位置最优
10、spark如何防止内存溢出?
driver端的内存溢出 :
可以增大driver的内存参数:spark.driver.memory (default 1g)
map过程产生大量对象导致内存溢出:
具体做法可以在会产生大量对象的map操作之前调用repartition方法,分区成更小的块传入map。
数据不平衡导致内存溢出:
数据不平衡除了有可能导致内存溢出外,也有可能导致性能的问题,解决方法和上面说的类似,就是调用repartition重新分区。
shuffle后内存溢出:
shuffle内存溢出的情况可以说都是shuffle后,单个文件过大导致的。在Spark中,join,reduceByKey这一类型的过程,都会有shuffle的过程,在shuffle的使用,需要传入一个partitioner,大部分Spark中的shuffle操作,默认的partitioner都是HashPatitioner,默认值是父RDD中最大的分区数,这个参数通过spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) , spark.default.parallelism参数只对HashPartitioner有效,所以如果是别的Partitioner或者自己实现的Partitioner就不能使用spark.default.parallelism这个参数来控制shuffle的并发量了。如果是别的partitioner导致的shuffle内存溢出,就需要从partitioner的代码增加partitions的数量。
standalone模式下资源分配不均匀导致内存溢出:
这种情况的解决方法就是同时配置–executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache()。
rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间
11、spark中cache和persist的区别?
cache:缓存数据,默认是缓存在内存中,其本质还是调用persist。
persist:缓存数据,有丰富的数据缓存策略。数据可以保存在内存也可以保存在磁盘中,使用的时候指定对应的缓存级别就可以了。
12、Spark手写WordCount程序
这个常出现在笔试阶段,手写WordCount算是一项基本技能。
//创建SparkConf并设置App名称和master地址
val conf=new SparkConf().setAppName(“wc”).setMaster(“Local[*]”)
//创建SparkContext,该对象是提交Spark App的入口
val sc=new SparkContext(conf)
//使用sc创建RDD并执行相应的transformation和action
val result=sc.textFile(“输入文件的路径”)
Val rdd2=result.flatmap(x=>x.split(“ ”))
.map((_,1)).reduceBykey((_+_)).saveAsTextFile(“输出文件路径”)
//关闭链接
sc.stop()
13、Spark中创建RDD的方式总结3种
1、从集合中创建RDD;
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8))
val rdd = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
2、从外部存储创建RDD;
val rdd= sc.textFile("hdfs://node01:8020/data/test")
3、从其他RDD创建。
val rdd1 = sc.parallelize(Array(1,2,3,4))
val rdd2 =rdd.map(x=>x.map(_*2))
14、常用算子
这个涉及到的算子就比较多了,感兴趣的朋友可以去看看博主的这两篇博客:
Spark之【RDD编程】详细讲解(No2)——《Transformation转换算子》
Spark之【RDD编程】详细讲解(No3)——《Action行动算子》
绝对不会让你失望的~
15、什么是宽窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle。
16、任务划分的几个重要角色
RDD任务切分中间分为:Application、Job、Stage和Task
1)Application:初始化一个SparkContext即生成一个Application;
2)Job:一个Action算子就会生成一个Job;
3)Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage;
4)Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task
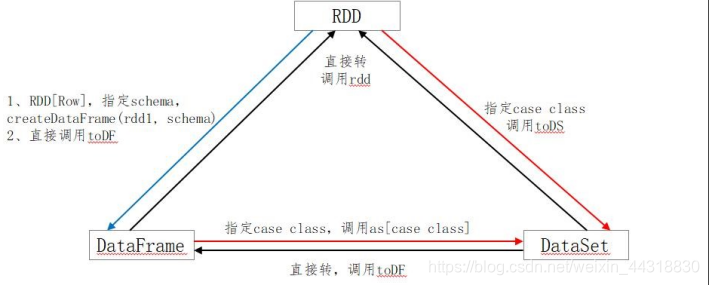
17、SparkSQL中RDD、DataFrame、DataSet三者的区别与联系?
RDD
弹性分布式数据集;不可变、可分区、元素可以并行计算的集合。
优点:
- RDD编译时类型安全:编译时能检查出类型错误;
- 面向对象的编程风格:直接通过类名点的方式操作数据。
缺点:
- 序列化和反序列化的性能开销很大,大量的网络传输;
- 构建对象占用了大量的heap堆内存,导致频繁的GC(程序进行GC时,所有任务都是暂停)
DataFrame
DataFrame以RDD为基础的分布式数据集。
优点:
- DataFrame带有元数据schema,每一列都带有名称和类型。
- DataFrame引入了off-heap,构建对象直接使用操作系统的内存,不会导致频繁GC。
- DataFrame可以从很多数据源构建;
- DataFrame把内部元素看成Row对象,表示一行行的数据
- DataFrame=RDD+schema
缺点:
- 编译时类型不安全;
- 不具有面向对象编程的风格。
Dataset
DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
(1)DataSet可以在编译时检查类型;
(2)并且是面向对象的编程接口。
(DataSet 结合了 RDD 和 DataFrame 的优点,并带来的一个新的概念 Encoder。当序列化数据时,Encoder 产生字节码与 off-heap 进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。)。
三者之间的转换:
18、自定义函数的过程
1)创建DataFrame
scala> val df = spark.read.json("/export/spark/examples/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2)打印数据
scala> df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
3)注册UDF,功能为在数据前添加字符串
scala> spark.udf.register("addName", (x:String)=> "Name:"+x)
res5: org.apache.spark.sql.expressions.UserDefinedFunction = UserDefinedFunction(<function1>,StringType,Some(List(StringType)))
4)创建临时表
scala> df.createOrReplaceTempView("people")
5)应用UDF
scala> spark.sql("Select addName(name), age from people").show()
+-----------------+----+
|UDF:addName(name)| age|
+-----------------+----+
| Name:Michael|null|
| Name:Andy| 30|
| Name:Justin| 19|
本篇博客就分享到这里,建议所有没看过开头提到的《不会这20个Spark热门技术点,你敢出去面试大数据吗?》这篇博客的朋友都去阅读一下,真的墙裂推荐!!!
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波🙏
希望我们都能在学习的道路上越走越远😉