前言
现在距离2021年还有不到一个月的时间了,是不是有的小伙明年不知该怎么复习spark,以及不知道该备战企业中会问到那些问题。好今天他来了总结了20个企业中经常被问到的面题以及会附带一些笔试题哦,编写不易建议收藏。

一、 Spark 有几种部署方式?
spark 中的部署模式分为三种 Standalone, Apache Mesos, Hadoop YARN,那他们分别有啥作用那?
-
Standalone: 独立模式, Spark 原生的简单集群管理器, 自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统,使用 Standalone 可以很方便地搭建一个集群;
-
Apache Mesos: 一个强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括 yarn;
-
Hadoop YARN: 统一的资源管理机制,在上面可以运行多套计算框架,如 mapreduce、 storm 等, 根据 driver 在集群中的位置不同,分为 yarn client 和 yarncluster。
二、 Spark 提交作业参数
企业问这个问题基本考验你对有没有是用spark提交过任务,以及是否了解每个参数的含义。合理设置参数也是可以起到优化作用的哦。
- executor-cores —— 每个executor使用的内核数,默认为1
- num-executors —— 启动executors的数量,默认为2
- executor-memory —— executor内存大小,默认1G
- driver-cores —— driver使用内核数,默认为1
- driver-memory —— driver内存大小,默认512M
三、简述Spark on yarn的作业提交流程
既然spark是支持yarn调度的那你的调度流程是什么样的那?yarn这边是有两个模式分别为 yarn Clint 和yarn Cluster模式,那我这边分别讲下吧。
yarn Clint模式
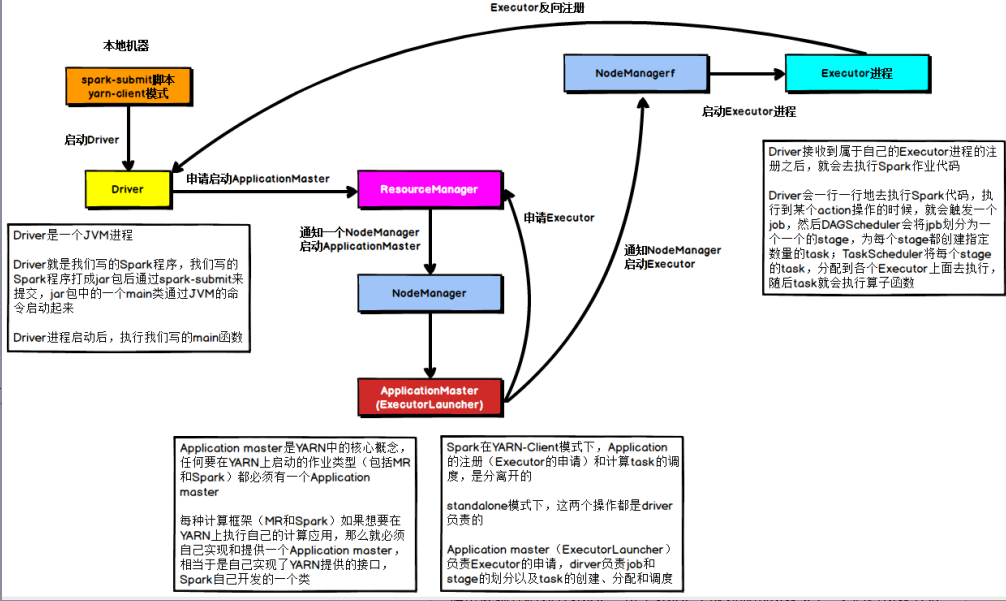
在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
yarn Cluster 模式
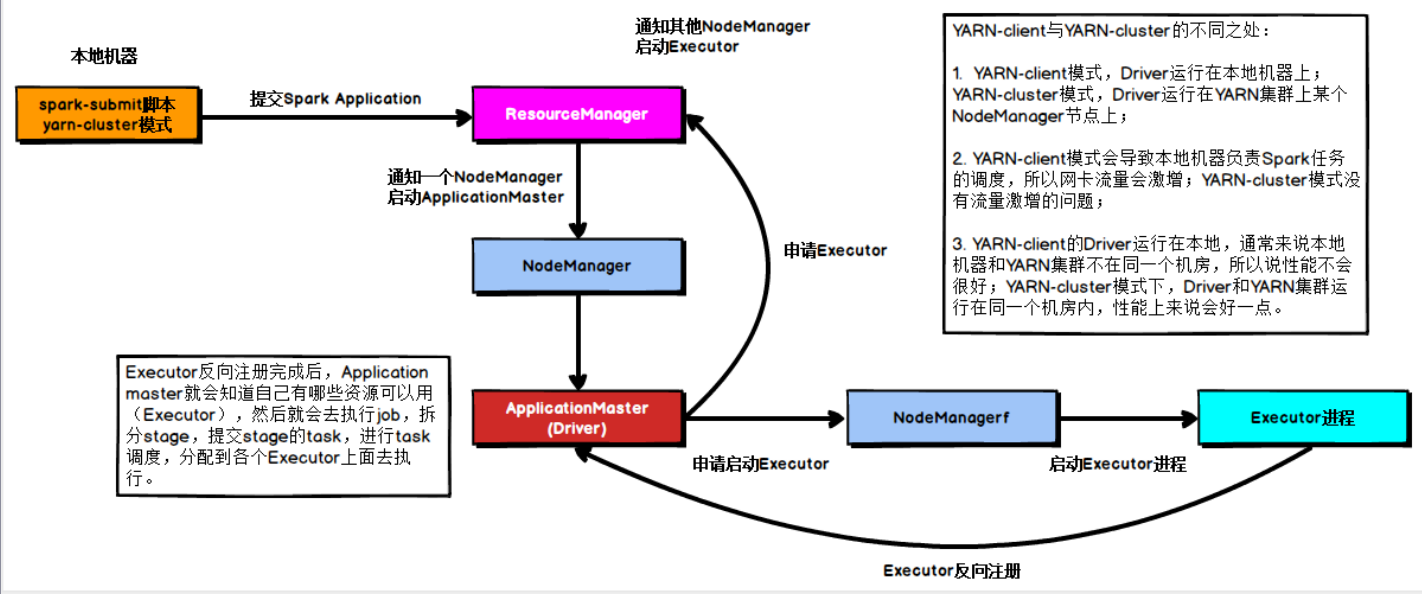
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到。
ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
四、既然有Yarn Client 和Yarn Cluster 那它这两个模式的区别?
如果在面试的时候面试官问到了yarn 的提交流程,你恰好有说了yarn clinet 和 yanr cluster 面试官基本上都会问一下他们的区别,看看大数据老哥是怎么回答的。
- yarn-cluster是用于生产环境,这种模式下客户端client在提交了任务以后,任务就托管给yarn了,这个时候client就可以断开连接不需要再管后续事情了,这种情况下无法直接查看到application运行的日志,查看日志较为麻烦;
- 而yarn-client则是主要用于测试时使用,这种模式下客户端client提交任务后,不能直接断开连接,客户端可以看到application运行的实时日志,非常方便开发调试。
五、请列举Spark的transformation算子(不少于5个)
Spark中的算子是非常多的我这里就列举几个我在开发中常用的算字吧。
- map
- flatMap
- filter
- groupByKey
- reduceByKey
- sortByKey
六、请列举Spark的action算子(不少于5个)
尽然有转换算子是不是执行算子也是必不可少上的呀。好那我也分别给大家列举几个常用的执行算子。
- reduce
- collect
- first
- take
- aggregate
- countByKey
- foreach
- saveAsTextFile
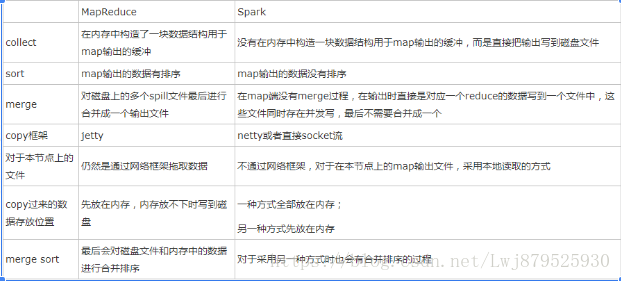
七、 简述Spark的两种核心Shuffle
Hashshuffle
- 优化前下游有一个task他就会生成一个对应的文件,有几个task就会有几个文件
优化后通过复用buffer来优化shuffle过程中产生小文件的数量 - 2.0版本之后就不用了
Sortshuffle - 当shuffle read task的数量小于等于默认的200个时,并且不是聚合类的shuffle算子,就会启动bypass机制,bypass机制并没有对数据进行sort
八、简述SparkSQL中RDD、DataFrame、DataSet三者的区别与联系
RDD :
优点:
- 编译时类型安全
- 编译时就能检查出类型错误
- 面向对象的编程风格
- 直接通过类名点的方式来操作数据
缺点:
- 序列化和反序列化的性能开销
- 无论是集群间的通信, 还是 IO 操作都需要对对象的结构和数据进行序列化和反序列化。
- GC 的性能开销,频繁的创建和销毁对象, 势必会增加 GC
DataFrom:
- DataFrame 引入了 schema 和 off-heap(堆外内存)
- schema : RDD 每一行的数据, 结构都是一样的,这个结构就存储在 schema 中。 Spark 通过 schema 就能够读懂数据, 因此在通信和 IO 时就只需要序列化和反序列化数据, 而结构的部分就可以省略了。
DataSet:
- DataSet 结合了 RDD 和 DataFrame 的优点,并带来的一个新的概念 Encoder。
- 当序列化数据时, Encoder 产生字节码与 off-heap 进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。
九、Repartition和Coalesce关系与区别
关系:
两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)

区别:
- repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle
- 一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
十、RDD有多少种持久化方式?
MEMORY_ONLY 以非序列化的 java 对象的方式持久在 JVM 内存中,如果内
存无法完成存储 RDD 所有的 partition,那么那些没有持久化的 partition 就会在
下一次使用它的的时候,重新计算
MEMORY_AND_DISK 同上,但是当某些 partition 无法存储在内存中的时
候,会持久化到硬盘中。下次使用这些 partition 时,需要从磁盘上读取
MEMORY_ONLY_SER 同 MEMORY_ONLY ,但是会使用 java 序列化方式,将
java 对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,
因此会加大 CPU 开销。
总结
以上10个企业中经常被问到的Spark面试题,也希望没有找到工作的小朋友找都自己满意的工作,我这边也会粉丝们带来我在自己在学习spark中整理的脑图和文档 微信搜索公众号【大数据老哥】回复【回复spark面试题】,我们下期见~~~
微信公众号搜索【大数据老哥】可以获取 200个为你定制的简历模板、大数据面试题、企业面试题…等等。