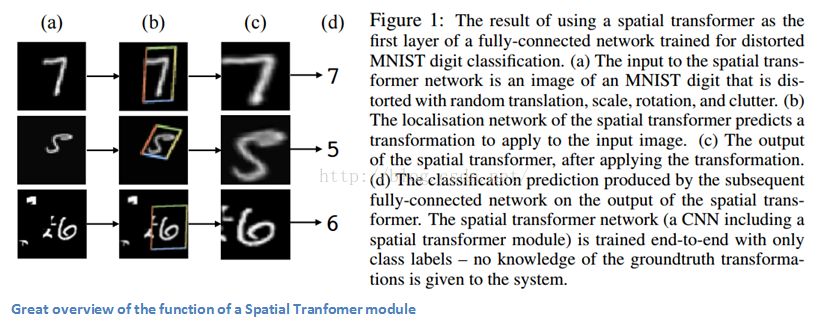
这是Machine-Learning-Collage系列,每隔一周作者都会编写一个本周论文的幻灯片摘要。每月底所有的幻灯片画都会被集中到一个总结文章中。作者希望给读者一个直观和直观的一些最酷的趋势。以下是作者在2021年3月读到的四篇最喜欢的论文,以及为什么我相信它们对深度学习的未来很重要。
“Discovery of Options via Meta-Learned Subgoals“
Veeriah et al. (2021) | 📝https://arxiv.org/abs/2102.06741
运动控制是一个极具挑战性的问题。我们人类擅长这一点是因为我们在多个扩展的时间尺度上进行计划:我们不制定每一个单独的肌肉动作,而是在一个抽象的层次上进行推理,并执行一系列细粒度的动作。层次强化学习(HRL)旨在借助所谓的时间抽象来模拟这种方法。简单地说,时间抽象就是一个在一段时间内执行的运动程序。它们由子策略和相应的终止条件组成。策略由更高级别的管理器调用并执行,直到终止条件停止为止。HRL中的一个关键问题是,如何自动推断出在多个任务之间传输的有用策略选项?Veeriah等人(2021)提议通过元梯度学习将选项参数化。在外部循环中,元梯度通过优化更新步骤(以可微的方式)传播高阶梯度来优化超参数。论文中使用经过优化的超参数训练神经网络。并提出的称为MODAC的元梯度方法能够发现有用的策略选项。元梯度方法可以从任务分布中提取有意义的规律性。他们在一个标准的四个房间的问题上测试了他们的方法,然后将其扩展到更具挑战性的DeepMind Lab领域。

“Clockwork Variational Autoencoders“
Saxena et al. (2021) | 📝 https://arxiv.org/abs/2102.09532
递归生成模型很难并捕获视频中的长期依存关系并生成长序列清晰图像的。 Saxena等人的CW-VAE(2021)旨在通过扩展递归状态空间模型(RSSM; Hafner et al.2019)来克服这一限制,这是一类递归VAE。 CW-VAE的核心是通过引入以不同固定时钟速度变化的潜在动态变量来扩展这些潜在动态模型。顶层以较低的速率适应,并调节较低层的生成过程。速度随着层次结构中的下降而增加,在最低层模型通过转置的CNN上采样输出生成的图像。使用ELBO目标对整个循环VAE体系结构进行端到端训练。作者证明,这种动态潜在变量的时间抽象层次优于许多基线模型,因为这些基线不包含潜在层次或者所有层次都以相同的速度移动。论文中的消融研究旨在提取存储在不同级别的内容信息。通过切断流入顶层的输入信号,作者能够证明顶层为低层提供全局的非特定信息。最后他们还表明,这种操作能够适应预处理序列输入的速度:高频序列导致更多的信息被快速低水平潜在变量捕获。总之,作用于不同时间尺度的机制层次结构不仅对强化学习非常有用,而且对于生成模型也非常有用。

“Coordination Among Neural Modules Through a Shared Global Workspace“
Goyal et al. (2021) | 📝 https://arxiv.org/abs/2103.01197
最著名的意识理论之一是全局工作空间理论。它提出了一个简单的认知架构,在这个架构中,经过处理的感官感知被投射到一个共享的工作空间,也被称为“黑板”。来自不同来源的信息被选择性地写入这个工作空间,并被潜意识地处理。这个处理阶段整合了不同的形态,抛弃了不相关的特征。转换后的信息被广播到与意识过程相关的大脑其他区域。Goyal等人(2021)从高层次意识的神经科学理论中获得灵感,并概述了将工作空间与注意力机制相结合的计算框架,以促进学习的神经模块之间的协调,作者提出了一个低维瓶颈区(也就是共享工作区)来促进专家模块的同步。不同的神经网络(例如Transformer 或不同的LSTMs)必须为“瓶颈”工作空间的写入而进行竞争。然后根据软或硬注意机制更新其外向表示。其核心思想是带宽限制有助于独立但集成的机制的协调学习。通过一组详尽的实验,作者表明,所提出的机制有助于模块之间的专业化,并有助于稳定它们的端到端训练。此外,工作空间的低维特性降低了专家之间的成对注意力交互的成本。因此,它不仅对训练有好处,而且对推理也有好处。

“Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability“
Authors: Cohen et al. (2021) | 📝 http://arxiv.org/abs/2103.00065
深度学习中最令人着迷但仍未完全解释的现象之一是:我们似乎仅使用简单的算法(例如随机梯度下降)就能有效地优化数十亿个参数。但是我们对学习动力和趋同行为到底了解多少呢?Cohen等人(2021)研究当批处理包含整个数据集时梯度下降的特殊情况。作者表明,这个全批梯度下降版本运行在一个非常特殊的区域。也就是说,处于“稳定的边缘”。这边缘到底是关于什么的?神经网络训练有两个阶段:在初始第一阶段,训练损失的最大特征值Hessian(即锐度)逐渐增加,直到达到2/学习率。在这一阶段,训练损失单调地减少。一旦该特征值达到2/学习率,则达到稳定边缘’。之后,梯度下降抑制了锐度的进一步增长。相反,它徘徊在2/学习率阈值之上。在短时间内,训练损失不再表现为单调而是波动的。但在较长的时间尺度上,梯度下降仍然能够减少损失。作者通过多个任务和不同的架构(包括标准的cnn和Transformer)来验证这一经验观察。结果发现,有关梯度下降的常规优化方法的许多方面都受到质疑:梯度下降如何抑制持续增长的清晰度?这对学习率表意味着什么?我们真的需要随着时间的流逝对其进行退火吗?良好的科学工作带来了很多有趣的未来研究问题,而这项工作肯定属于这个范畴。

作者:Robert Lange