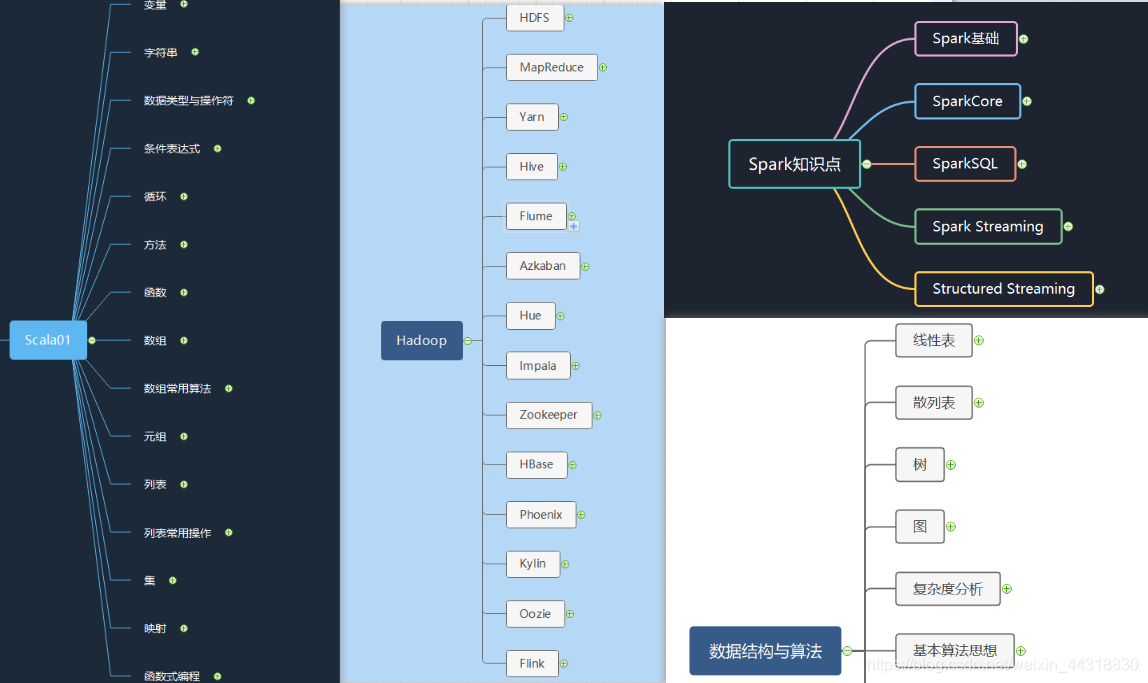
大数据面试题汇总 大数据面试题汇总 - 简书
spark 资源调优
1、列式存储和行式存储的区别

行存储,数据行存储,一个文件可表达一个二维表。适用于一般的业务场景如CSV文件,文本文件
因为这里的行结构是固定的,每一行都一样,即使你不用,也必须空到那里,而不能没有,而这样的空行也是需要占用一定的存储空间的,如果这样的空行占比较大,势必带来较大的存储空间的浪费,那么是否有什么好的解决办法么?

相当于将每一行的每一列拆开,然后通过rowkey(行唯一键)关联起来,rowkey相同的这些数据其实就是原来的一行。由于原来的列变为了现在的行,有需要就加一行,没需要就不加,有效地减少了存储空间的浪费。
列存储,每个文件存储一个列,多个文件合成一张二维表
适用的场景:
数仓的特性很大一部分是针对列的过滤,列的搜索,列的匹配,所以很多数仓结构比较适合使用列存储
列存储也比较适合做OLAP
行存储与列存储的对比
上图可以很清楚地看到,行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。所以它们就有了如下这些优缺点:
|
| 行式存储 | 列式存储 |
| 优点 |
| 查询时只有涉及到的列会被读取 投影(projection)很高效 任何列都能作为索引 列式存储更像一个Map,不提前定义,随意往里添加key/value。 扩展列, 删除列更简单, 能够指定列加载到内存中 |
| 缺点 |
|
|
二、Spark原理部分
1、spark为什么比hadoop的mr要快?
Spark比Hadoop快的主要原因:在内存核算战略和先进的DAG调度等机制的协助下,Spark能够用更快速度处理一样的数据集。
1、spark基于内存、消除了冗余的HDFS读写 、
MapReduce在每次执行时都要从磁盘读取数据,计算完毕后都要把数据存放到磁盘上。 Hadoop每次shuffle(分区合并排序等……)操作后,必须写到磁盘,
而Spark是基于内存的。Spark在shuffle后不一定落盘,可以cache到内存中,以便迭代时使用。如果操作复杂,很多的shufle操作,那么Hadoop的读写IO时间会大大增加。少磁盘IO操作
2、DAG优化操作、消除了冗余的MapReduce阶段、
Hadoop的shuffle操作一定连着完整的MapReduce操作,冗余繁琐。map-reduce-map-reduce-map-reduce。
而Spark基于RDD提供了丰富的算子操作,DAG调度等机制。它可以把整个执行过程做一个图,然后进行优化。DAG引擎有向无环图,shuffle过程中避免不必要的sort操作、 且reduce操作产生shuffle数据,可以缓存在内存中。
3.JVM的优化、Task启动(线程池)
Spark Task的启动时间快。Spark 使用多线程池模型来减少task启动开稍、Spark采用fork线程的方式,Spark每次MapReduce操作是基于线程的。Spark的Executor是启动一次JVM,内存的Task操作是在线程池内线程复用的。
而Hadoop采用创建新的进程的方式,启动一个Task便会启动一次JVM。每次启动JVM的时间可能就需要几秒甚至十几秒,那么当Task多了,这个时间Hadoop不知道比Spark慢了多少。
2、hadoop的MapReduce过程、shuffle过程 MapReduce 、Shuffle、数据倾斜、 MapReduce 实现join_.-CSDN博客
一、Map端的shuffle
二、Reduce端的shuffle
3、yarn工作原理
4、Spark任务提交、yarn-cluster、yarn-client模式
5、调度器DAGScheduler、TaskScheduler
6、rdd 怎么分区宽依赖和窄依赖
宽依赖:父RDD的分区被子RDD的多个分区使用 例如 groupByKey、reduceByKey、sortByKey等操作会产生宽依赖,会产生shuffle (一对多)

窄依赖:父RDD的每个分区都只被子RDD的一个分区使用 例如map、filter、union等操作会产生窄依赖(一对一)

三、Spark开发算子、 调优
3、RDD 中foreach与foreachPartition区别,foreachRDD
val rdd1 = sc.makeRDD(1 to 12, 3)rdd1.foreach(x => print(" foreachx: " + x))rdd1.foreachPartition(x => print(" x.size: " + x.size))rdd1.foreachPartition(x => x.foreach(t2 => print(" foreachPartition:foreach: " + t2)))/*foreachx: 1 foreachx: 2 foreachx: 3 foreachx: 4
foreachx: 5 foreachx: 6 foreachx: 7 foreachx: 8
foreachx: 9 foreachx: 10 foreachx: 11 foreachx: 12x.size: 4
x.size: 4
x.size: 4foreachPartition: 9 foreachPartition: 10 foreachPartition: 11 foreachPartition: 12
foreachPartition: 5 foreachPartition: 6 foreachPartition: 7 foreachPartition: 8
foreachPartition: 1 foreachPartition: 2 foreachPartition: 3 foreachPartition: 4
*/- foreachRDD 作用于DStream中每一个时间间隔的RDD,(用于kafka)
- foreachPartition 作用于每一个时间间隔的RDD中的每一个partition,
- foreach 作用于每一个时间间隔的RDD中的每一个元素。
Foreach与foreachPartition都是在每个partition中对iterator进行操作,
不同的是,foreach是直接在每个partition中直接对iterator执行foreach操作,而传入的function只是在foreach内部使用,
而foreachPartition是在每个partition中把iterator给传入的function,让function自己对iterator进行处理.
foreach的写库原理
默认的foreach的性能缺陷在哪里?
1、首先,对于每条数据,都要单独去调用一次function,task为每个数据,都要去执行一次function函数。
如果100万条数据,(一个partition),调用100万次。性能比较差。
2、另外一个非常非常重要的一点
如果每个数据,你都去创建一个数据库连接的话,那么你就得创建100万次数据库连接。
但是要注意的是,数据库连接的创建和销毁,都是非常非常消耗性能的。虽然我们之前已经用了数据库连接池,只是创建了固定数量的数据库连接。
你还是得多次通过数据库连接,往数据库(MySQL)发送一条SQL语句,然后MySQL需要去执行这条SQL语句。
如果有100万条数据,那么就是100万次发送SQL语句。
以上两点(数据库连接,多次发送SQL语句),都是非常消耗性能的。
foreachPartition,好处
在生产环境中,通常来说,都使用foreachPartition来写数据库的,使用批处理操作(一条SQL和多组参数)发送一条SQL语句,发送一次一下子就批量插入100万条数据。
1、对于我们写的function函数,就调用一次,一次传入一个partition所有的数据
2、主要创建或者获取一个数据库连接就可以
3、只要向数据库发送一次SQL语句和多组参数即可
foreachPartition,存在问题
在实际生产环境中,都是使用foreachPartition操作;但是有个问题,跟mapPartitions操作一样,如果一个partition的数量真的特别特别大,比如真的是100万,那基本上就不太靠谱了。一下子进来,很有可能会发生OOM,内存溢出的问题。
一组数据的对比:生产环境
一个partition大概是1千条左右
用foreach,跟用foreachPartition,性能的提升达到了2~3分钟。
实际项目操作:
首先JDBCHelper里面已经封装好了一次批量插入操作!
1343行
批量插入session detail
唯一不一样的是我们需要ISessionDetailDAO里面去实现一个批量插入
List<SessionDetail> sessionDetails

linesFormat.foreachRDD(rdd => {rdd.foreachPartition(it => {var exceptionExist = falseval jedis = RedisUtil.getConnectionit.foreach(record => {try{if(jedis != null && jedis.exists("abc" + record._2 + record._3)){//从Redis中获取数据val value = jedis.hmget("abc" + record._2 + record._3,"a1","a2","a3","a4","a5","a6") //使用数据。。。}}catch{case e: Exception => {println(e)exceptionExist = true}}})RedisUtil.closeConnection(jedis,exceptionExist)exceptionExist = false})}) 5、Spark的Cache和Checkpoint区别和联系
作为区别于 Hadoop 的一个重要 feature,cache 机制保证了需要访问重复数据的应用(如迭代型算法和交互式应用)可以运行的更快。与 Hadoop MapReduce job 不同的是 Spark 的逻辑/物理执行图可能很庞大,task 中 computing chain 可能会很长,计算某些 RDD 也可能会很耗时。这时,如果 task 中途运行出错,那么 task 的整个 computing chain 需要重算,代价太高。因此,有必要将计算代价较大的 RDD checkpoint 一下,这样,当下游 RDD 计算出错时,可以直接从 checkpoint 过的 RDD 那里读取数据继续算。
Cache 机制
回到 Overview 提到的 GroupByTest 的例子,里面对 FlatMappedRDD 进行了 cache,这样 Job 1 在执行时就直接从 FlatMappedRDD 开始算了。可见 cache 能够让重复数据在同一个 application 中的 jobs 间共享。
问题:哪些 RDD 需要 cache?
会被重复使用的(但不能太大)。
问题:用户怎么设定哪些 RDD 要 cache?
因为用户只与 driver program 打交道,因此只能用 rdd.cache() 去 cache 用户能看到的 RDD。所谓能看到指的是调用 transformation() 后生成的 RDD,而某些在 transformation() 中 Spark 自己生成的 RDD 是不能被用户直接 cache 的,比如 reduceByKey() 中会生成的 ShuffledRDD、MapPartitionsRDD 是不能被用户直接 cache 的。
问题:driver program 设定 rdd.cache() 后,系统怎么对 RDD 进行 cache?
将要计算 RDD partition 的时候(而不是已经计算得到第一个 record 的时候)就去判断 partition 要不要被 cache。如果要被 cache 的话,先将 partition 计算出来,然后 cache 到内存。cache 只使用 memory,写磁盘的话那就叫 checkpoint 了。
调用 rdd.cache() 后, rdd 就变成 persistRDD 了,其 StorageLevel 为 MEMORY_ONLY。persistRDD 会告知 driver 说自己是需要被 persist 的。
问题:cached RDD 怎么被读取?
下次计算(一般是同一 application 的下一个 job 计算)时如果用到 cached RDD,task 会直接去 blockManager 的 memoryStore 中读取。具体地讲,当要计算某个 rdd 中的 partition 时候(通过调用 rdd.iterator())会先去 blockManager 里面查找是否已经被 cache 了,如果 partition 被 cache 在本地,就直接使用 blockManager.getLocal() 去本地 memoryStore 里读取。如果该 partition 被其他节点上 blockManager cache 了,会通过 blockManager.getRemote() 去其他节点上读取,
获取 cached partitions 的存储位置:partition 被 cache 后所在节点上的 blockManager 会通知 driver 上的 blockMangerMasterActor 说某 rdd 的 partition 已经被我 cache 了,这个信息会存储在 blockMangerMasterActor 的 blockLocations: HashMap中。等到 task 执行需要 cached rdd 的时候,会调用 blockManagerMaster 的 getLocations(blockId) 去询问某 partition 的存储位置,这个询问信息会发到 driver 那里,driver 查询 blockLocations 获得位置信息并将信息送回。
读取其他节点上的 cached partition:task 得到 cached partition 的位置信息后,将 GetBlock(blockId) 的请求通过 connectionManager 发送到目标节点。目标节点收到请求后从本地 blockManager 那里的 memoryStore 读取 cached partition,最后发送回来。
Checkpoint
问题:哪些 RDD 需要 checkpoint?
运算时间很长或运算量太大才能得到的 RDD,computing chain 过长或依赖其他 RDD 很多的 RDD。实际上,将 ShuffleMapTask 的输出结果存放到本地磁盘也算是 checkpoint,只不过这个 checkpoint 的主要目的是去 partition 输出数据。
问题:什么时候 checkpoint?
cache 机制是每计算出一个要 cache 的 partition 就直接将其 cache 到内存了。但 checkpoint 没有使用这种第一次计算得到就存储的方法,而是等到 job 结束后另外启动专门的 job 去完成 checkpoint 。也就是说需要 checkpoint 的 RDD 会被计算两次。因此,在使用 rdd.checkpoint() 的时候,建议加上 rdd.cache(),这样第二次运行的 job 就不用再去计算该 rdd 了,直接读取 cache 写磁盘。其实 Spark 提供了 rdd.persist(StorageLevel.DISK_ONLY) 这样的方法,相当于 cache 到磁盘上,这样可以做到 rdd 第一次被计算得到时就存储到磁盘上,但这个 persist 和 checkpoint 有很多不同,之后会讨论。
问题:checkpoint 怎么实现?
RDD 需要经过 [ Initialized --> marked for checkpointing --> checkpointing in progress --> checkpointed ] 这几个阶段才能被 checkpoint。
Initialized:首先 driver program 需要使用 rdd.checkpoint() 去设定哪些 rdd 需要 checkpoint,设定后,该 rdd 就接受 RDDCheckpointData 管理。用户还要设定 checkpoint 的存储路径,一般在 HDFS 上。
marked for checkpointing:初始化后,RDDCheckpointData 会将 rdd 标记为 MarkedForCheckpoint。
checkpointing in progress:每个 job 运行结束后会调用 finalRdd.doCheckpoint(),finalRdd 会顺着 computing chain 回溯扫描,碰到要 checkpoint 的 RDD 就将其标记为 CheckpointingInProgress,然后将写磁盘(比如写 HDFS)需要的配置文件(如 core-site.xml 等)broadcast 到其他 worker 节点上的 blockManager。完成以后,启动一个 job 来完成 checkpoint(使用 rdd.context.runJob(rdd, CheckpointRDD.writeToFile(path.toString, broadcastedConf)))。
checkpointed:job 完成 checkpoint 后,将该 rdd 的 dependency 全部清掉,并设定该 rdd 状态为 checkpointed。然后,为该 rdd 强加一个依赖,设置该 rdd 的 parent rdd 为 CheckpointRDD,该 CheckpointRDD 负责以后读取在文件系统上的 checkpoint 文件,生成该 rdd 的 partition。
有意思的是我在 driver program 里 checkpoint 了两个 rdd,结果只有一个(下面的 result)被 checkpoint 成功,pairs2 没有被 checkpoint,也不知道是 bug 还是故意只 checkpoint 下游的 RDD:
val data1 = Array[(Int, Char)]((1, 'a'), (2, 'b'), (3, 'c'), (4, 'd'), (5, 'e'), (3, 'f'), (2, 'g'), (1, 'h'))
val pairs1 = sc.parallelize(data1, 3)val data2 = Array[(Int, Char)]((1, 'A'), (2, 'B'), (3, 'C'), (4, 'D'))
val pairs2 = sc.parallelize(data2, 2)pairs2.checkpointval result = pairs1.join(pairs2)
result.checkpoint
问题:怎么读取 checkpoint 过的 RDD?
在 runJob() 的时候会先调用 finalRDD 的 partitions() 来确定最后会有多个 task。rdd.partitions() 会去检查(通过 RDDCheckpointData 去检查,因为它负责管理被 checkpoint 过的 rdd)该 rdd 是会否被 checkpoint 过了,如果该 rdd 已经被 checkpoint 过了,直接返回该 rdd 的 partitions 也就是 Array[Partition]。
当调用 rdd.iterator() 去计算该 rdd 的 partition 的时候,会调用 computeOrReadCheckpoint(split: Partition) 去查看该 rdd 是否被 checkpoint 过了,如果是,就调用该 rdd 的 parent rdd 的 iterator() 也就是 CheckpointRDD.iterator(),CheckpointRDD 负责读取文件系统上的文件,生成该 rdd 的 partition。这就解释了为什么那么 trickly 地为 checkpointed rdd 添加一个 parent CheckpointRDD。
问题:cache 与 checkpoint 的区别?
深入一点讨论,rdd.persist(StorageLevel.DISK_ONLY) 与 checkpoint 也有区别。前者虽然可以将 RDD 的 partition 持久化到磁盘,但该 partition 由 blockManager 管理。一旦 driver program 执行结束,也就是 executor 所在进程 CoarseGrainedExecutorBackend stop,blockManager 也会 stop,被 cache 到磁盘上的 RDD 也会被清空(整个 blockManager 使用的 local 文件夹被删除)。而 checkpoint 将 RDD 持久化到 HDFS 或本地文件夹,如果不被手动 remove 掉(话说怎么 remove checkpoint 过的 RDD?),是一直存在的,也就是说可以被下一个 driver program 使用,而 cached RDD 不能被其他 dirver program 使用。
Discussion
Hadoop MapReduce 在执行 job 的时候,不停地做持久化,每个 task 运行结束做一次,每个 job 运行结束做一次(写到 HDFS)。在 task 运行过程中也不停地在内存和磁盘间 swap 来 swap 去。可是讽刺的是,Hadoop 中的 task 太傻,中途出错需要完全重新运行,比如 shuffle 了一半的数据存放到了磁盘,下次重新运行时仍然要重新 shuffle。Spark 好的一点在于尽量不去持久化,所以使用 pipeline,cache 等机制。用户如果感觉 job 可能会出错可以手动去 checkpoint 一些 critical 的 RDD,job 如果出错,下次运行时直接从 checkpoint 中读取数据。唯一不足的是,checkpoint 需要两次运行 job。
貌似还没有发现官方给出的 checkpoint 的例子,这里我写了一个:
package internalsimport org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConfobject groupByKeyTest {def main(args: Array[String]) {val conf = new SparkConf().setAppName("GroupByKey").setMaster("local")val sc = new SparkContext(conf) sc.setCheckpointDir("/Users/xulijie/Documents/data/checkpoint")val data = Array[(Int, Char)]((1, 'a'), (2, 'b'),(3, 'c'), (4, 'd'),(5, 'e'), (3, 'f'),(2, 'g'), (1, 'h')) val pairs = sc.parallelize(data, 3)pairs.checkpointpairs.countval result = pairs.groupByKey(2)result.foreachWith(i => i)((x, i) => println("[PartitionIndex " + i + "] " + x))println(result.toDebugString)}
}