1.spark中的RDD是什么,有哪些特性?
答:RDD(Resilient Distributed Dataset)叫做分布式数据集,是spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可以并行计算的集合
Dataset:就是一个集合,用于存放数据的
Destributed:分布式,可以并行在集群计算
Resilient:表示弹性的,弹性表示
1.RDD中的数据可以存储在内存或者磁盘中;
2.RDD中的分区是可以改变的;
五大特性:
1.A list of partitions:一个分区列表,RDD中的数据都存储在一个分区列表中
2.A function for computing each split:作用在每一个分区中的函数
3.A list of dependencies on other RDDs:一个RDD依赖于其他多个RDD,这个点很重要,RDD的容错机制就是依据这个特性而来的
4.Optionally,a Partitioner for key-value RDDs(eg:to say that the RDD is hash-partitioned):可选的,针对于kv类型的RDD才有这个特性,作用是决定了数据的来源以及数据处理后的去向
5.可选项,数据本地性,数据位置最优
2.概述一下spark中的常用算子区别(map,mapPartitions,foreach,foreachPatition)
答:map:用于遍历RDD,将函数应用于每一个元素,返回新的RDD(transformation算子)
foreach:用于遍历RDD,将函数应用于每一个元素,无返回值(action算子)
mapPatitions:用于遍历操作RDD中的每一个分区,返回生成一个新的RDD(transformation算子)
foreachPatition:用于遍历操作RDD中的每一个分区,无返回值(action算子)
总结:一般使用mapPatitions和foreachPatition算子比map和foreach更加高效,推荐使用
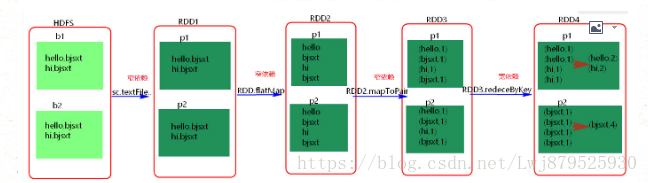
3.谈谈spark中的宽窄依赖:

答:RDD和它的父RDD的关系有两种类型:窄依赖和宽依赖
宽依赖:指的是多个子RDD的Partition会依赖同一个父RDD的Partition,关系是一对多,父RDD的一个分区的数据去到子RDD的不同分区里面,会有shuffle的产生
窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个partition使用,是一对一的,也就是父RDD的一个分区去到了子RDD的一个分区中,这个过程没有shuffle产生
区分的标准就是看父RDD的一个分区的数据的流向,要是流向一个partition的话就是窄依赖,否则就是宽依赖,如图所示:
4.spark中如何划分stage:
答:概念:Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分依据就是宽窄依赖,遇到宽依赖就划分stage,每个stage包含一个或多个task,然后将这些task以taskSet的形式提交给TaskScheduler运行,stage是由一组并行的task组成
1.spark程序中可以因为不同的action触发众多的job,一个程序中可以有很多的job,每一个job是由一个或者多个stage构成的,后面的stage依赖于前面的stage,也就是说只有前面依赖的stage计算完毕后,后面的stage才会运行;
2.stage 的划分标准就是宽依赖:何时产生宽依赖就会产生一个新的stage,例如reduceByKey,groupByKey,join的算子,会导致宽依赖的产生;
3.切割规则:从后往前,遇到宽依赖就切割stage;
4.图解:

5.计算格式:pipeline管道计算模式,piepeline只是一种计算思想,一种模式
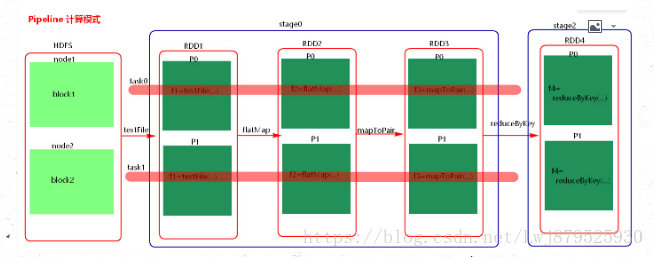
6.spark的pipeline管道计算模式相当于执行了一个高阶函数,也就是说来一条数据然后计算一条数据,会把所有的逻辑走完,然后落地,而MapReduce是1+1=2,2+1=3这样的计算模式,也就是计算完落地,然后再计算,然后再落地到磁盘或者内存,最后数据是落在计算节点上,按reduce的hash分区落地。管道计算模式完全基于内存计算,所以比MapReduce快的原因。
7.管道中的RDD何时落地:shuffle write的时候,对RDD进行持久化的时候。
8.stage的task的并行度是由stage的最后一个RDD的分区数来决定的,一般来说,一个partition对应一个task,但最后reduce的时候可以手动改变reduce的个数,也就是改变最后一个RDD的分区数,也就改变了并行度。例如:reduceByKey(_+_,3)
9.优化:提高stage的并行度:reduceByKey(_+_,patition的个数) ,join(_+_,patition的个数)
4.DAGScheduler分析:
答:概述:是一个面向stage 的调度器;
主要入参有:dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal,resultHandler, localProperties.get)
rdd: final RDD;
cleanedFunc: 计算每个分区的函数;
resultHander: 结果侦听器;
主要功能:1.接受用户提交的job;
2.将job根据类型划分为不同的stage,记录那些RDD,stage被物化,并在每一个stage内产生一系列的task,并封装成taskset;
3.决定每个task的最佳位置,任务在数据所在节点上运行,并结合当前的缓存情况,将taskSet提交给TaskScheduler;
4.重新提交shuffle输出丢失的stage给taskScheduler;
注:一个stage内部的错误不是由shuffle输出丢失造成的,DAGScheduler是不管的,由TaskScheduler负责尝试重新提交task执行。
5.Job的生成:
答:一旦driver程序中出现action,就会生成一个job,比如count等,向DAGScheduler提交job,如果driver程序后面还有action,那么其他action也会对应生成相应的job,所以,driver端有多少action就会提交多少job,这可能就是为什么spark将driver程序称为application而不是job 的原因。每一个job可能会包含一个或者多个stage,最后一个stage生成result,在提交job 的过程中,DAGScheduler会首先从后往前划分stage,划分的标准就是宽依赖,一旦遇到宽依赖就划分,然后先提交没有父阶段的stage们,并在提交过程中,计算该stage的task数目以及类型,并提交具体的task,在这些无父阶段的stage提交完之后,依赖该stage 的stage才会提交。
6.有向无环图:
答:DAG,有向无环图,简单的来说,就是一个由顶点和有方向性的边构成的图中,从任意一个顶点出发,没有任意一条路径会将其带回到出发点的顶点位置,为每个spark job计算具有依赖关系的多个stage任务阶段,通常根据shuffle来划分stage,如reduceByKey,groupByKey等涉及到shuffle的transformation就会产生新的stage ,然后将每个stage划分为具体的一组任务,以TaskSets的形式提交给底层的任务调度模块来执行,其中不同stage之前的RDD为宽依赖关系,TaskScheduler任务调度模块负责具体启动任务,监控和汇报任务运行情况。
7.RDD是什么以及它的分类:

8.RDD的操作










9.RDD缓存:
Spark可以使用 persist 和 cache 方法将任意 RDD 缓存到内存、磁盘文件系统中。缓存是容错的,如果一个 RDD 分片丢失,可以通过构建它的 transformation自动重构。被缓存的 RDD 被使用的时,存取速度会被大大加速。一般的executor内存60%做 cache, 剩下的40%做task。
Spark中,RDD类可以使用cache() 和 persist() 方法来缓存。cache()是persist()的特例,将该RDD缓存到内存中。而persist可以指定一个StorageLevel。StorageLevel的列表可以在StorageLevel 伴生单例对象中找到。
Spark的不同StorageLevel ,目的满足内存使用和CPU效率权衡上的不同需求。我们建议通过以下的步骤来进行选择:
·如果你的RDDs可以很好的与默认的存储级别(MEMORY_ONLY)契合,就不需要做任何修改了。这已经是CPU使用效率最高的选项,它使得RDDs的操作尽可能的快。
·如果不行,试着使用MEMORY_ONLY_SER并且选择一个快速序列化的库使得对象在有比较高的空间使用率的情况下,依然可以较快被访问。
·尽可能不要存储到硬盘上,除非计算数据集的函数,计算量特别大,或者它们过滤了大量的数据。否则,重新计算一个分区的速度,和与从硬盘中读取基本差不多快。
·如果你想有快速故障恢复能力,使用复制存储级别(例如:用Spark来响应web应用的请求)。所有的存储级别都有通过重新计算丢失数据恢复错误的容错机制,但是复制存储级别可以让你在RDD上持续的运行任务,而不需要等待丢失的分区被重新计算。
·如果你想要定义你自己的存储级别(比如复制因子为3而不是2),可以使用StorageLevel 单例对象的apply()方法。
在不会使用cached RDD的时候,及时使用unpersist方法来释放它。
10.RDD共享变量:
在应用开发中,一个函数被传递给Spark操作(例如map和reduce),在一个远程集群上运行,它实际上操作的是这个函数用到的所有变量的独立拷贝。这些变量会被拷贝到每一台机器。通常看来,在任务之间中,读写共享变量显然不够高效。然而,Spark还是为两种常见的使用模式,提供了两种有限的共享变量:广播变量和累加器。
(1). 广播变量(Broadcast Variables)
– 广播变量缓存到各个节点的内存中,而不是每个 Task
– 广播变量被创建后,能在集群中运行的任何函数调用
– 广播变量是只读的,不能在被广播后修改
– 对于大数据集的广播, Spark 尝试使用高效的广播算法来降低通信成本
- val broadcastVar = sc.broadcast(Array(1, 2, 3))方法参数中是要广播的变量
(2). 累加器
累加器只支持加法操作,可以高效地并行,用于实现计数器和变量求和。Spark 原生支持数值类型和标准可变集合的计数器,但用户可以添加新的类型。只有驱动程序才能获取累加器的值
11.spark-submit的时候如何引入外部jar包:
在通过spark-submit提交任务时,可以通过添加配置参数来指定
- –driver-class-path 外部jar包
- –jars 外部jar包
12.spark如何防止内存溢出:
- driver端的内存溢出
-
- 可以增大driver的内存参数:spark.driver.memory (default 1g)
- 这个参数用来设置Driver的内存。在Spark程序中,SparkContext,DAGScheduler都是运行在Driver端的。对应rdd的Stage切分也是在Driver端运行,如果用户自己写的程序有过多的步骤,切分出过多的Stage,这部分信息消耗的是Driver的内存,这个时候就需要调大Driver的内存。
- map过程产生大量对象导致内存溢出
-
- 这种溢出的原因是在单个map中产生了大量的对象导致的,例如:rdd.map(x=>for(i <- 1 to 10000