一、案例背景
1.案例说明
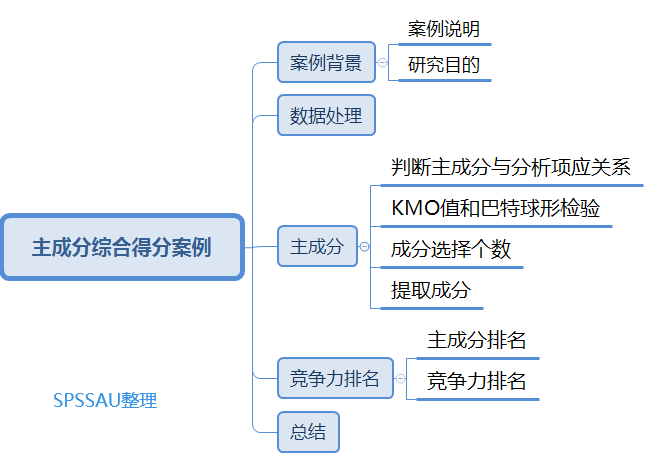
研究调查100家公司2010-2013年关于财务方面的具体数据,这些财务指标维度分别为盈利能力、偿债能力、运营能力、发展能力以及公司治理。其中每个维度分别有几个分析项,但是有些指标是越大越好,有些指标是越小越好。 需要在研究前进行数据处理。
2.研究目的
此案例主要目的是利用数据进行主成分分析,最后进行各个公司的主成分排名或者竞争力排名,利用成分得分分析每个公司在2010-2013年对于每个维度的排名情况以及最终的综合得分排名,并找出排名前20的公司。
二、数据处理
主成分的目的就是用少数几个成分去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个成分(之所以称其为成分,是因为它是不可观测的,即不是具体的变量),以最少的信息丢失为前提,以较少的几个成分反映原资料的大部分信息。
在进行主成分之前,由于所选取的指标体系中每个指标都有自己的量纲和变动差异性,这样给综合分析建模带来不便,于是我们需要对收集得到的数据进行预处理,以消除量纲和变动差异性的影响。通常对数据进行的处理包括标准化处理(Z-score 法)、正向处理、均值化处理等。
此案例中有些指标需要提前处理,具体指标隶属维度以及指标性质如下,比如资产负责率是逆向指标可以进行逆向化处理或者取倒数;但是取倒数需要分析项的数据大于0,其他指标需要正向化处理,公司治理的2个指标可以做正向化处理也可以做适度化,比如认为指标不是越大越好也不是越小越好,接近于某个值或某个范围内认为更好那就使用适度化,此案例中认为越大越好处理为正向化(也有参考文献做适度化处理,建议以参考文献为主)。
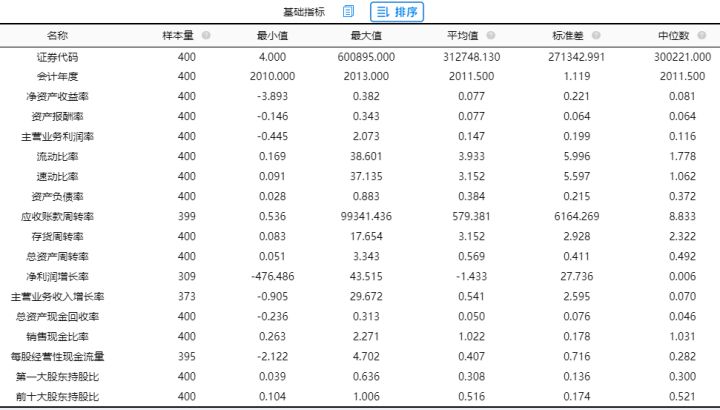
首先用SPSSAU将分析项进行“描述分析”观察数据的基本情况。发现资产负债率所有数据均大于0,所以进行处理时可以直接“取倒数”。
分析结果来源于SPSSAU
然后利用SPSSAU“数据处理”中的“生成变量”进行指标处理(一般正逆向化处理后不需要在进行标准化处理,因为已经正逆向化已经处理了量纲问题,但是取倒数后需要进行标准化处理)。
三、主成分
主成分结果分为4个部分,判断主成分与分析项对应关系、KMO值和巴特球形检验、成分选择个数以及提取成分。
1.判断主成分与分析项应关系

使用主成分分析进行信息浓缩研究,首先分析研究数据是否适合进行主成分分析,从上表可以看出:KMO为0.642,大于0.6,满足主成分分析的前提要求,意味着数据可用于主成分分析研究。以及数据通过Bartlett 球形度检验(p<0.05),说明研究数据适合进行主成分分析。
成分与对应项之间的关系:
一般情况下,如果16项与5个成分之间的对应关系情况,与专业知识情况不符合,比如第一项被划分到了第一个成分下面,此时则说明可能这项应该被删除处理,其出现了‘张冠李戴’现象。因而在进行分析时很可能会对部分不合理项进行删除处理。除此之外,也有可能会出现‘纠缠不清’现象。
- “张冠李戴”
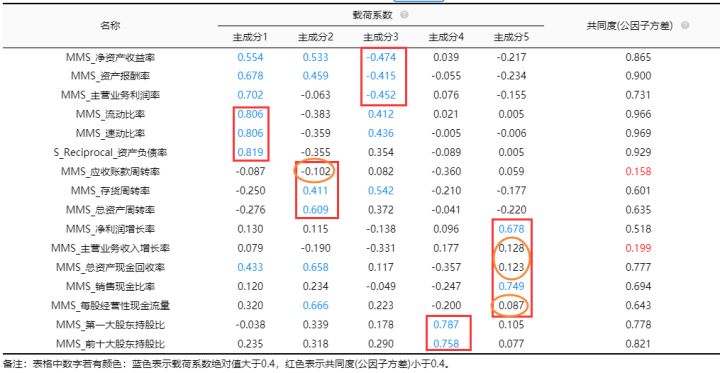
一般情况下,如果16项与5个成分之间的对应关系情况,与专业知识情况不符合,比如第一项被划分到了第一个成分下面,此时则说明可能这项应该被删除处理,其出现了‘张冠李戴’现象。例如案例中的“应收账款周转率”应该属于成分2是分析时被划分到别的成分中。
- “纠缠不清”
除了“张冠李戴”现象,有时候会出现‘纠缠不清’现象,比如案例中的“净资产收益率”可归属为成分1,成分2,同时也可归属到成分3,这种情况较为正常(称作‘纠缠不清’),需要结合实际情况处理即可,可将该项删除,也可不删除,这时,分析带有一定主观性。
主成分分析是一个多次重复的过程,比如删除某个或多个题项后,则需要重新再次分析进行对比选择等。最终目的在于:成分与分析项对应关系,与专业知识情况基本吻合。
Step1: 第一次分析
本例子中共16个分析项,此16个分析项共分为5个维度,因此在分析前可主动告诉SPSSAU,此16项是五个维度,否则SPSSAU会自动判断多少个成分 (通常软件自动判断与实际情况有很大出入,所以建议主动设置成分个数)。如下图:
从上图中可以看出:
“流动比率”、“速动比率”以及“资产负债率”这3项,它们全部对应着成分1,公因子方差均高于0.4,说明此3项应该同属于一个维度,即逻辑上这3项,并没有出现 “张冠李戴”现象。但是有出现“纠缠不清”的情况。暂不处理。“应收账款周转率”、“存货周转率”、“总资产周转率”它们对应着成分2,但应收账款周转率共同度小于0.4所以需要删除处理。 “净资产收益率”、“资产报酬率”以及“主营业务利润率”共3项,此3项均对应着成分3,此3项并没有出现‘张冠李戴’问题,但是出现了“纠缠不清”。“第一大股东持股比”和“前十大股东持股比”共2项,它们全部对应着成分4,也没有出现“纠缠不清”的现象。“净利润增长率”、“主营业务收入增长率”、“总资产现金回收率”、“销售现金比率”以及“每股经营性现金流量”共5项,当他们对应成分5, “主营业务收入增长率”、“总资产现金回收率”以及“每股经营性现金流量”出现“张冠李戴”进行删除处理。
总结上述分析可知:“主营业务收入增长率”、“总资产现金回收率”以及“每股经营性现金流量”这三项出现“张冠李戴”,应该将此三项删除;“应收账款周转率”共同度小于0.4需要删除处理,而其他出现“纠缠不清”现象的,暂时不处理(进行关注即可)。重新分析如下。
Step2: 第二次分析
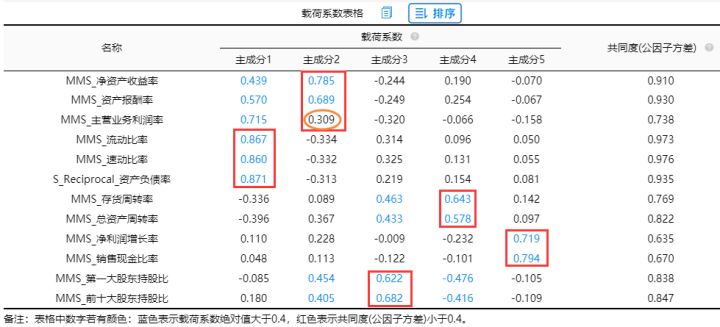
从上图可知 “主营业务利润率”出现‘张冠李戴’现象,应该删除,以及“资产收益率”、“资产报酬率”等出现‘纠缠不清’现象,暂不处理,但应该给予关注。总结可知:应该将“主营业务利润率”先删除后再次进行第3次分析。
Step3: 第三次分析
将“主营业务利润率”删除后进行分析如下:
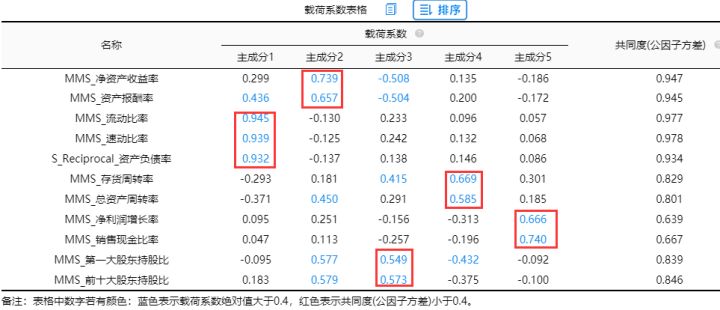
从上图可知
除了“流动比率”、“速动比率”以及“资产负债率”这3项,“净利润增长率”、“销售现金比率”这两项,其余的项均存在“纠缠不清”的现象,但考虑到成分下只余下两项,因而表示可以接受,主成分析分析结束。
2.KMO值和巴特球形检验

使用主成分分析进行信息浓缩研究,首先分析研究数据是否适合进行主成分分析,从上表可以看出:KMO为0.605,大于0.6,满足主成分分析的前提要求,意味着数据可用于主成分分析研究。以及数据通过Bartlett 球形度检验(p<0.05),说明研究数据适合进行主成分分析。
3.成分选择个数
当数据确定可以使用主成分分析后,下一步确定主成分成分选择个数。利用SPSSAU的主成分中选择主成分分析方法来判断选取的成分个数。成分数目的确定没有精确的定量方法,但常用的方法是借助三个准则来确定成分的个数。一是特征值准则,二是碎石图检验准则,三是专业知识判断法。特征值准则就是选取特征值大于或等于1的主成分作为初始成分,而放弃特征值小于1的主成分。碎石图检验准则是根据成分被提取的顺序绘出特征值随成分个数变化的折线图,根据图的形状来判断成分的个数。折线图的特点是由高到低,先陡后平,最后几乎成一条直线。曲线开始变平的前一个点被认为是提取的最大成分数。专业知识判断法是结合自身专业知识情况,主观判断成分数量。本部分使用特征根值与碎石图判断方式。
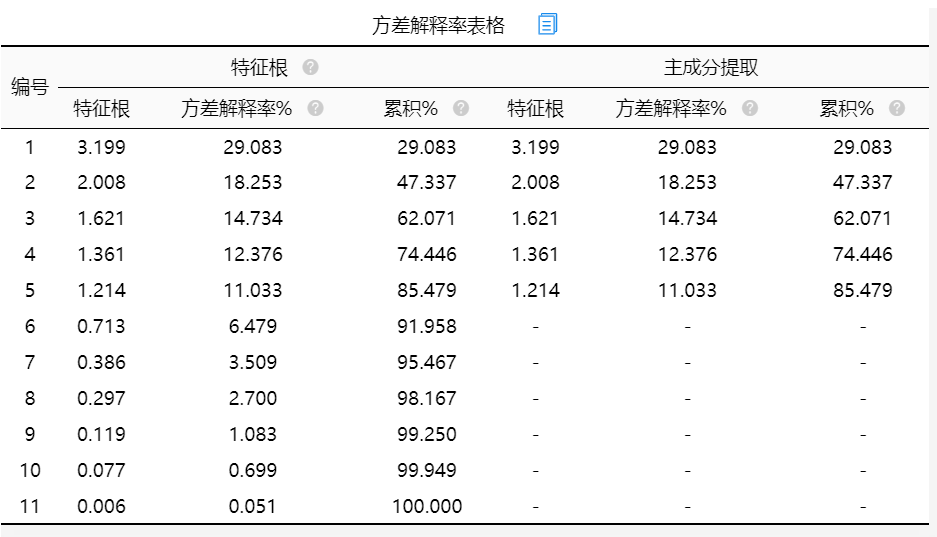
方差解释率表格主要用于判断提取多少个主成分合适。以及每个主成分的方差解释率和累计方差解释率情况。方差解释率越大说明主成分包含原数据信息的越多。
上表格针对主成分提取情况,以及主成分提取信息量情况进行分析,从上表可知:主成分分析一共提取出5个主成分,特征根值均大于1,此5个主成分的方差解释率分别是29.083%,18.253%,14.734%,12.376%,11.033%,累积方差解释率为85.479%。(提示:如果主成分提取个数与预期不符,可在分析时主动设置主成分个数)。另外,本次分析共提取出5个主成分,它们对应的加权后方差解释率即权重依次为:29.083/85.479=34.02%;18.253/85.479=21.35%;14.734/85.479=17.24%;12.376/85.479=14.48%;11.033/85.479=12.91%;同时SPSSAU还提供了碎石图帮助研究者判断主成分提取个数。
特征根一般是指标每个成分的贡献程度。此值的总和与项目数匹配,此值越大,代表主成分贡献越大。当然主成分分析通常需要综合自己的专业知识综合判断,即使是特征根值小于1,也一样可以设置成分。在进行主成分分析时,研究者没有预设成分数,系统就会以特征根“大于1”为标准进行划分。可以看出有五个特征根值大于1,提取五个成分是合理的,除了特征根之外SPSSAU还提供了更加直观的碎石图帮助判断。
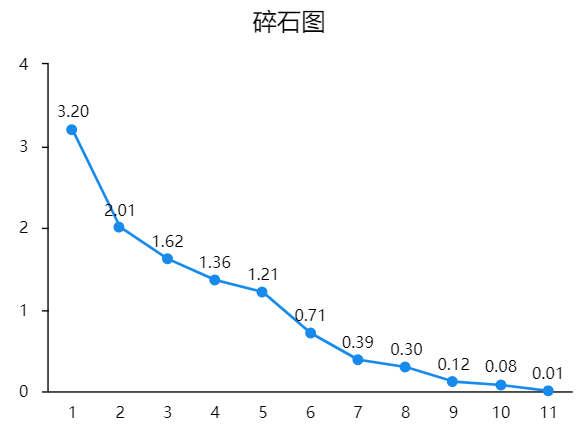
同时可结合碎石图辅助判断主成分提取个数。当折线由陡峭突然变得平稳时,陡峭到平稳对应的主成分个数即为参考提取主成分个数。实际研究中更多以专业知识,结合主成分与研究项对应关系情况,综合权衡判断得出主成分个数。
从图中可以看出,横轴表示指标数,纵轴表示特征根值,当提取5个成分时,特征根值变化较明显;当提取5个以后的成分时,特征根变化也相对平稳,对原有变量贡献相对较小,由此可见提5个成分对原变量有的显著作用。碎石图仅辅助决策成分个数,如果由此图分析6个成分也是可以的。
此案例按专业知识来看提取5个成分,如果没有预设成分个数也可以默认让系统进行决策。
4.提取成分
已经确定了成分选择个数经过分析得到载荷系数矩阵如下:
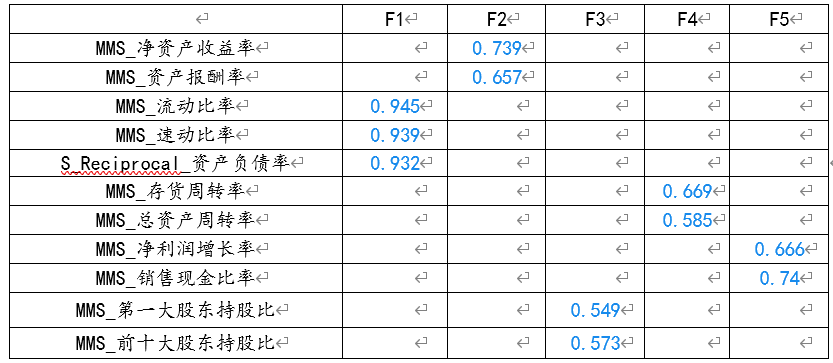
载荷系数表格,主要展示主成分对于研究项的信息提取情况,以及主成分和研究项对应关系。蓝色数值代表载荷系数绝对值大于0.4。共同度代表某题项可被提取的信息量,共同度越高说明指标能被主成分解释的程度越高,被提取的信息量越多。一般以0.4作为标准。
从结果中可以看出,主成分1中反映“流动比率”、“速动比率”以及“资产负债率”共3个指标的信息,它们主要反映了公司的偿债能力。主成分2中反映了“净资产收益率”、“资产报酬率”共2项它们主要反映了公司的盈利能力,主成分3中反映了“第一大股东持股比”和“前十大股东持股比”共2项,它们主要反映了公司治理能力,主成分4中反映了“存货周转率”、“总资产周转率”共2项,它们主要反映了公司运营能力,主成分5中反映了“净利润增长率”、 “销售现金比率”,它们主要反映了公司发展能力。
整理表格如下:五个成分的名字分别叫F1偿债能力、F2盈利能力、F3治理能力、F4运营能力以及F5发展能力。
四、竞争力排名
主成分越大意味着在该成分上竞争力越大,综合得分越高意味着该项公司的综合竞争力水平越强,以及主成分和综合得分在SPSSAU中分析如下。分为主成分排名与竞争力排名两个部分。
主成分排名
成份得分系数矩阵
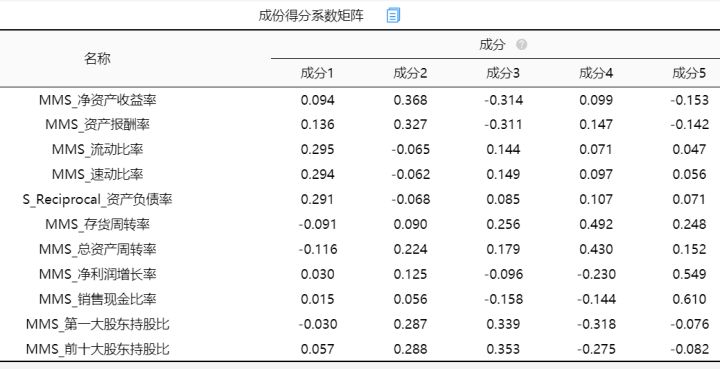
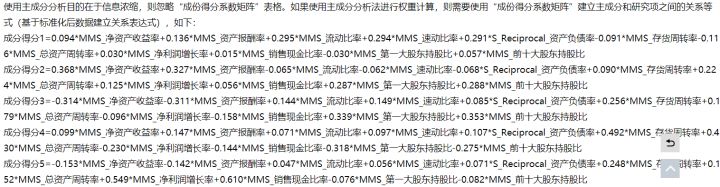
可直接SPSSAU右上角“我的数据”进行查看成分得分也可以进行下载。
接下来分别输出各个公司在2010-2013年的各成分排名情况(仅展示前20项):
- 偿债能力
| 排序 | 名称 | 偿债能力 |
| 1 | 双鹭药业 | 16.41 |
| 2 | 千红制药 | 13.03 |
| 3 | 华兰生物 | 7.40 |
| 4 | 智飞生物 | 6.78 |
| 5 | 舒泰神 | 6.20 |
| 6 | 大华农 | 5.77 |
| 7 | 博雅生物 | 5.39 |
| 8 | 上海莱士 | 4.56 |
| 9 | 冠昊生物 | 3.78 |
| 10 | 金达威 | 3.23 |
| 11 | 科华生物 | 3.20 |
| 12 | 安科生物 | 2.40 |
| 13 | 东阿阿胶 | 2.07 |
| 14 | 吉林敖东 | 2.04 |
| 15 | 瑞普生物 | 2.03 |
| 16 | 四环生物 | 1.77 |
| 17 | 星河生物 | 1.38 |
| 18 | 通化东宝 | 1.28 |
| 19 | 天山生物 | 1.01 |
| 20 | 沃森生物 | 0.70 |
针对公司的盈利能力,利用数据透视表将主成分得分求和,根据数据结果显示最好的是“双鹭药业”其次是“千红制药”前20名如上表显示。
2)盈利能力
| 排序 | 名称 | 盈利能力 |
| 1 | 华润三九 | 7.17 |
| 2 | 中牧股份 | 6.81 |
| 3 | 上海莱士 | 6.18 |
| 4 | 正邦科技 | 5.79 |
| 5 | 大北农 | 5.48 |
| 6 | 青岛啤酒 | 5.38 |
| 7 | 伊力特 | 4.61 |
| 8 | 华润双鹤 | 4.45 |
| 9 | 天坛生物 | 4.35 |
| 10 | 澳柯玛 | 4.03 |
| 11 | 悦达投资 | 3.68 |
| 12 | 东阿阿胶 | 3.35 |
| 13 | 燕京啤酒 | 3.24 |
| 14 | 獐子岛 | 3.14 |
| 15 | 金种子酒 | 3.08 |
| 16 | 科华生物 | 3.03 |
| 17 | 万向德农 | 3.03 |
| 18 | 光明乳业 | 2.98 |
| 19 | 天康生物 | 2.95 |
| 20 | 双鹭药业 | 2.95 |
针对公司的盈利能力,利用数据透视表将主成分得分求和,根据数据结果显示最好的是“华润三九”其次是“中牧股份”前20名如上表显示。
3)治理能力
| 排序 | 名称 | 治理能力 |
| 1 | 诚志股份 | 7.992604 |
| 2 | 正邦科技 | 7.153529 |
| 3 | 智飞生物 | 6.679127 |
| 4 | 美罗药业 | 6.650961 |
| 5 | 千红制药 | 4.80757 |
| 6 | 光明乳业 | 4.745864 |
| 7 | 天康生物 | 3.93622 |
| 8 | 舒泰神 | 3.915128 |
| 9 | 大北农 | 3.838614 |
| 10 | 华润双鹤 | 3.812249 |
| 11 | 扬农化工 | 3.253352 |
| 12 | 瑞普生物 | 3.20509 |
| 13 | 燕京啤酒 | 2.992444 |
| 14 | 金达威 | 2.920408 |
| 15 | 星河生物 | 2.850168 |
| 16 | 四环药业 | 2.731311 |
| 17 | 华润三九 | 2.618381 |
| 18 | 博雅生物 | 2.598811 |
| 19 | 中牧股份 | 2.353754 |
| 20 | 申华控股 | 2.292654 |
针对公司的治理能力,利用数据透视表将主成分得分求和,根据数据结果显示最好的是“诚志股份”其次是“正邦科技”前20名如上表显示。
4)运营能力
| 排序 | 名称 | 运营能力 |
| 1 | 正邦科技 | 9.41 |
| 2 | 诚志股份 | 7.50 |
| 3 | 双鹭药业 | 6.43 |
| 4 | 科华生物 | 5.79 |
| 5 | 申华控股 | 5.73 |
| 6 | 中粮生化 | 5.39 |
| 7 | 沙隆达A | 4.96 |
| 8 | 海王生物 | 4.76 |
| 9 | 大北农 | 4.35 |
| 10 | 华北制药 | 4.22 |
| 11 | 东阿阿胶 | 3.81 |
| 12 | 光明乳业 | 3.64 |
| 13 | 大华农 | 3.37 |
| 14 | 扬农化工 | 3.15 |
| 15 | 千红制药 | 3.15 |
| 16 | 威远生化 | 2.79 |
| 17 | 四环生物 | 2.69 |
| 18 | 荣华实业 | 2.45 |
| 19 | 新安股份 | 2.45 |
| 20 | 啤酒花 | 2.34 |
针对公司的运营能力,利用数据透视表将主成分得分求和,根据数据结果显示最好的是“正邦科技”其次是“诚志股份”前20名如上表显示。
5)发展能力
| 排名 | 名称 | 发展能力 |
| 1 | 诚志股份 | 6.99 |
| 2 | 四环生物 | 4.94 |
| 3 | 中源协和 | 4.84 |
| 4 | 中粮生化 | 4.32 |
| 5 | 正邦科技 | 4.31 |
| 6 | 光明乳业 | 4.15 |
| 7 | 江苏吴中 | 3.59 |
| 8 | 千红制药 | 2.99 |
| 9 | 澳柯玛 | 2.94 |
| 10 | 青海明胶 | 2.79 |
| 11 | 新安股份 | 2.75 |
| 12 | 晨光生物 | 2.61 |
| 13 | 扬农化工 | 2.42 |
| 14 | 海王生物 | 2.39 |
| 15 | 威远生化 | 2.01 |
| 16 | 荣华实业 | 1.92 |
| 17 | 啤酒花 | 1.79 |
| 18 | 大华农 | 1.79 |
| 19 | 燕京啤酒 | 1.73 |
| 20 | 海南海药 | 1.64 |
针对公司的发展能力,利用数据透视表将主成分得分求和,根据数据结果显示最好的是“诚志股份”其次是“四环生物”前20名如上表显示。
2.竞争力排名
对于“综合得分”SPSSAU提供一键生成综合得分非常方便,可以分析后点击右上角我的数据进行查看,具体计算如下:
综合得分等于每个主成分得分乘以各自权重求和所得的结果。
即为:综合得分F值=a1*F1+a2*F2+a3*F3+a4*F4+a5*F5, ai=Fi的方差解释率/总的方差解释率(i从1到5);求解得到a1到a5的值分别为34.02%,21.35%,17.24%,14.48%,12.91%。
F=34.02%*主成分1得分+21.35%*主成分2得分+17.24%*主成分3得分+14.48%*主成分4得分+12.91%*主成分5得分;
因此最后计算出每个公司的综合得分F值,并得到财务竞争力排名如下表所示(中间过程可用数据透视表处理):
- 透视表部分结果如下
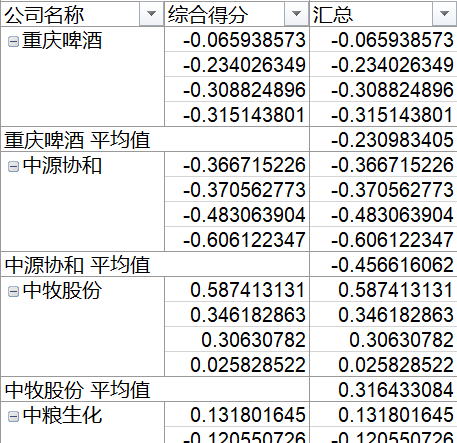
- 最终结果如下
| 1 | 双鹭药业 | 1.73114 |
| 2 | 千红制药 | 1.726451 |
| 3 | 智飞生物 | 1.018631 |
| 4 | 博雅生物 | 1.011556 |
| 5 | 正邦科技 | 0.987016 |
| 6 | 舒泰神 | 0.802011 |
| 7 | 金达威 | 0.747585 |
| 8 | 华兰生物 | 0.593216 |
| 9 | 大华农 | 0.553165 |
| 10 | 上海莱士 | 0.525126 |
| 11 | 大北农 | 0.499163 |
| 12 | 诚志股份 | 0.49584 |
| 13 | 星河生物 | 0.391593 |
| 14 | 青岛啤酒 | 0.35341 |
| 15 | 光明乳业 | 0.346792 |
| 16 | 冠昊生物 | 0.330535 |
| 17 | 中牧股份 | 0.316433 |
| 18 | 金河生物 | 0.282712 |
| 19 | 科华生物 | 0.272181 |
| 20 | 华润双鹤 | 0.262264 |
五、总结
此案例对数据进行主成分分析并对成分得分与综合得分进行描述,首先对数据进行处理,使用SPSSAU生成变量功能,然后判断主成分与分析项对应关系,并描述成分选择个数以及提取成分,接下来对竞争力进行排名利用成分得分分析每个公司在2010-2013年对于每个维度的排名情况由于数据过多所以结果只显示前20名的公司,以及具体描述综合得分的计算得到最终的综合得分排名。此次分析结束。
更多干货请前往SPSSAU官网查看。




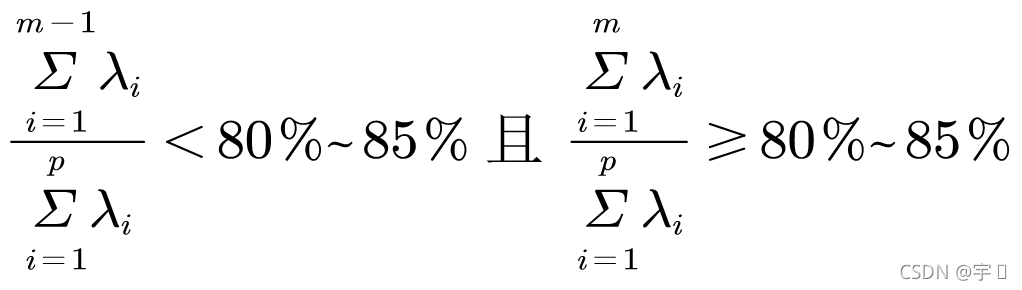
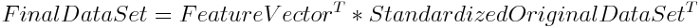
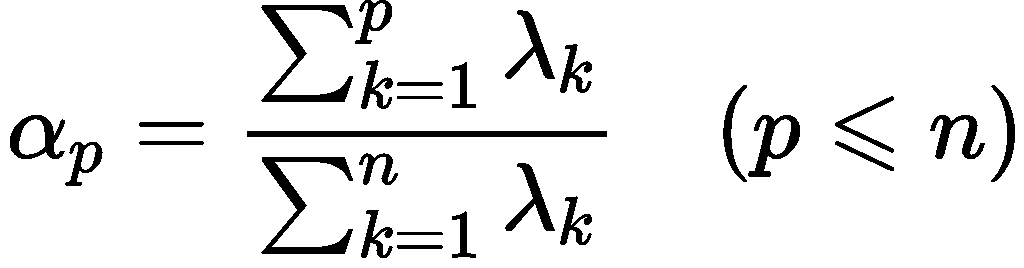





![[将小白进行到底] 如何比较两篇文章的相似度](https://images0.cnblogs.com/blog/79263/201304/02151548-f7e8409392c846498b9d9e548e92926f.png)