本文目录
- 文本相似度的定义
- 文本相似度计算方法
- 基于字符串的方法
- 基于语料库的方法
- 基于词袋
- VSM
- LSA、PLSA
- LDA(需要进一步了解)
- 基于神经网络
- 基于搜索引擎
- 基于世界知识
- 基于本体
- 基于网络知识
- 其他方法
- 句法分析
- 混合方法
文本相似度的定义

其中, common(A,B) 是 A 和 B 的共性信息,description(A,B) 是描述 A 和 B 的全部信息, 公式(1)表达出相似度与文本共性成正相关。由于没有限制应用领域, 此定义是被较多采用的概念。
相似度一般可用[0,1]之间的实数表示, 该实数可通过语义距离计算获得。相似度与语义距离呈反比关系, 语义距离越小, 相似度越高; 语义距离越大则相似度越低。通常用公式(2)表示相似度与语义距离的关系。
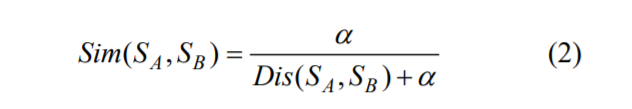
其中, Dis(Sa, Sb)表示文本 Sa、Sb之间的非负语义距离, α为调节因子, 保证了当语义距离为 0 时公式(2)具有意义。
文本相似度计算中还有一个重要概念是文本表示(如word2vec), 代表对文本的基本处理, 目的是将半结构化或非结构化的文本转换为计算机可读形式。文本相似度计算方法的不同的本质是文本表示方法的不同。
文本相似度计算方法
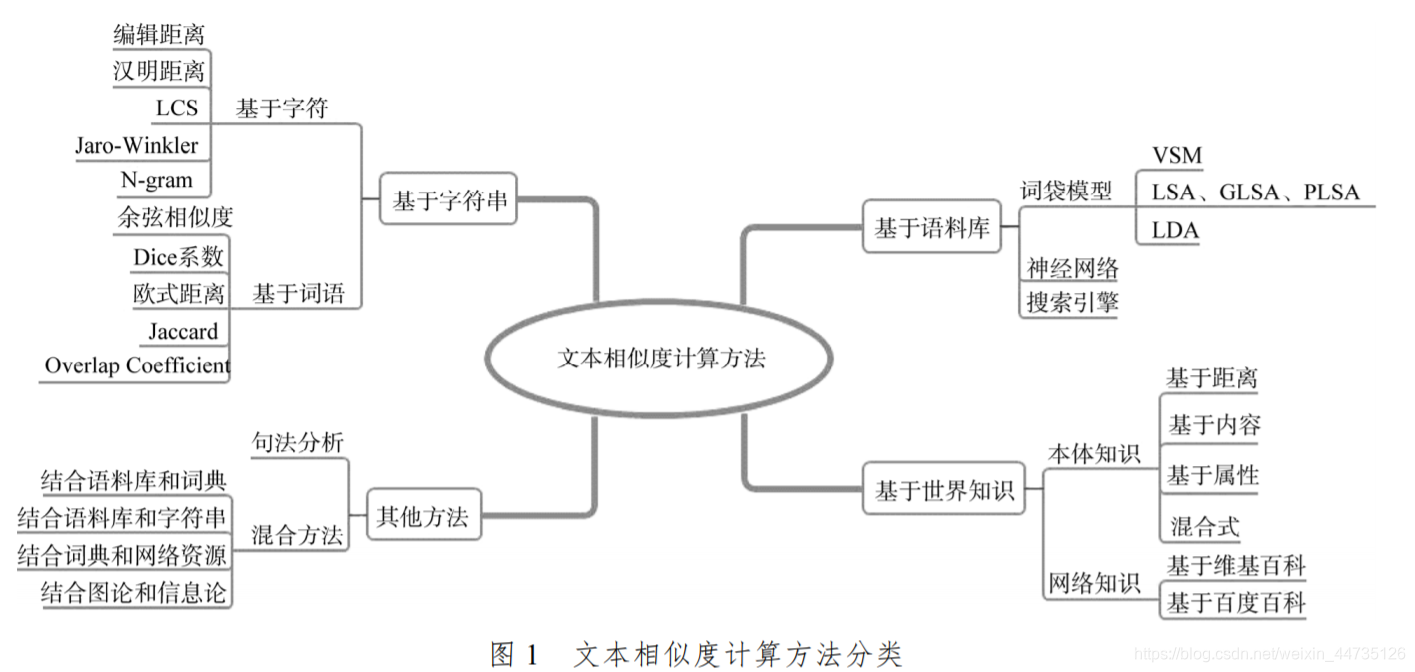
基于字符串的方法
该方法从字符串匹配度出发, 以字符串共现和重复程度为相似度的衡量标准。 根据计算粒度不同, 可将方法分为基于字符(Character-Based)的方法和基于词语(Term-Based)的方法。一类方法单纯从字符或词语的组成考虑相似度算法, 如编辑距离、汉明距离、余弦相似度、Dice 系数、欧式距离; 另一类方法还加入了字符顺序, 即字符组成和字符顺序相同是字符串相似
的必要条件 , 如最长公共子串 (Longest CommonSubstring, LCS)、Jaro-Winkler; 再一类方法采用集合思想, 将字符串看作由词语构成的集合, 词语共现可用集合的交集计算, 如 N-gram、Jaccard、Overlap Coefficient。表 1 列出了主要方法, 其中 Sa、Sb表示字符串 A、B。
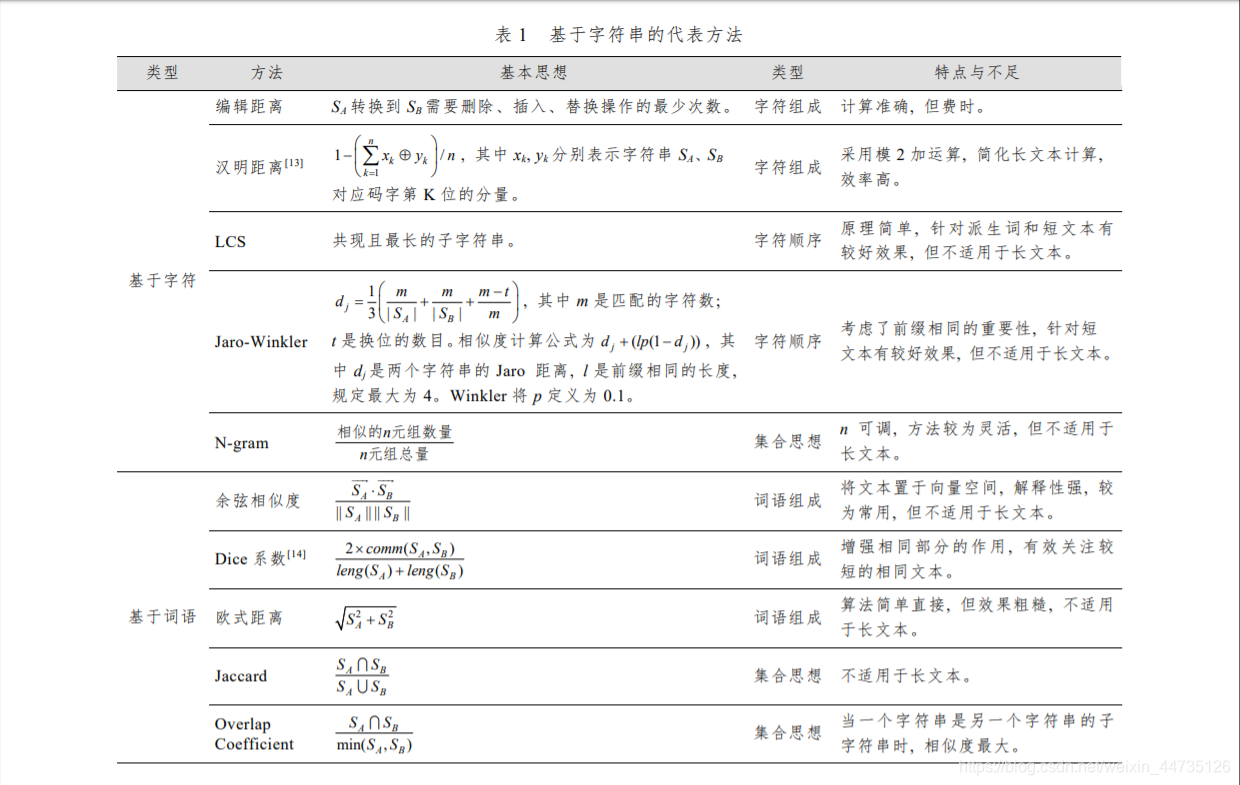
基于字符串的方法是在字面层次上的文本比较,文本表示即为原始文本。该方法优点是原理简单、易于实现,现已成为其他方法的计算基础。缺点是的是将字符或词语作为独立的知识单元, 并未考虑词语本身的含义和词语之间的关系。 以同义词为例, 尽管表达不同, 但具有相同的含义, 而这类词语的相似度依靠基于字符串的方法并不能准确计算。
基于字符串的方法也称作“字面相似度方法”, 其中较为典型的方法包括最长公共子串 (Longest
Common Substring, LCS)、编辑距离、Jaccard 等。基于字符串的方法没有考虑文本的语义信息, 计算效果受到很大限制。 为解决这一问题, 学者们开始对语义相似度方法展开研究, 包括基于字符串的方法、基于语料库的方法、基于世界知识的方法和其他方法。
(编辑距离、汉明距离、LCS、N-gram、余弦相似度、欧氏距离、Jaccard还需进一步了解。)
基于语料库的方法
基于语料库的方法利用从语料库中获取的信息计算文本相似度。
基于语料库的方法可以分为: 基于词袋模型的方法、基于神经网络的方法和基于搜索引擎的方法。 前两种以待比较相似度的文档集合为语料库,后一种以 Web 为语料库。
基于词袋
词袋模型(Bag of Words Model, BOW)建立在分布假说的基础上, 即“词语所处的上下文语境相似, 其语义则相似”。基本思想是不考虑词语在文档中出现的顺序, 将文档表示成一系列词语的组合。 根据考虑的语义程度不同, 基于词袋模型的方法主要包括向量空间模型(Vector Space Model, VSM)、潜在语义分析(Latent Semantic Analysis, LSA)、概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)和潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)。
VSM
20 世纪 60 年代末, Salton 等提出 VSM[16], 这种方法受到广大学者的青睐。基本思想是将每篇文档表示成一个基于词频或者词频 – 逆文档频率 (Term Frequency-Inverse Document Frequency, TF-IDF)权重的实值向量, 那么 N 篇文档则构成 n 维实值空间, 其中空间的每一维都对应词项, 每一篇文档表示该空间下的一个点或者向量。而两个文档的相似度就是两个向量的距离, 一般采用余弦相似度方法计算。
[16] Salton G, Wong A, Yang C S. A Vector Space Model forAutomatic Indexing [J]. Communications of the ACM, 1975,18(11): 613-620.
【17】【18】两篇论文是对VSM的一些改进。
[17] 郭庆琳, 李艳梅, 唐琦. 基于 VSM 的文本相似度计算的研究 [J]. 计算机应用研究, 2008,25(11): 3256-3258. (GuoQinglin, Li Yanmei, Tang Qi. Similarity Computing of
Documents Based on VSM [J]. Application Research of Computers, 2008, 25(11): 3256-3258.)
[18] 李连, 朱爱红, 苏涛. 一种改进的基于向量空间文本相似度算法的研究与实现 [J]. 计算机应用与软件, 2012, 29(2):282-284. (Li Lian, Zhu Aihong, Su Tao. Research and
Implementation of An Improved VSM-based Text Similarity Algorithm [J]. Computer Applications and Software, 2012,29(2): 282-284. )
基于 VSM 的方法基本原理简单, 但该方法有两个明显缺点: 一是该方法基于文本中的特征项进行相似度计算, 当特征项较多时, 产生的高维稀疏矩阵导致计算效率不高; 二是向量空间模型算法的假设是文本中抽取的特征项没有关联, 这不符合文本语义表达。
LSA、PLSA
LSA[19]算法的基本思想是将文本从稀疏的高维词汇空间映射到低维的潜在语义空间, 在潜在语义空间计算相似性。(有点像word2vec的思想) LSA 是基于 VSM 提出来的, 两种方法都是采用空间向量表示文本, 但 LSA 使用潜在语义空间, 利用奇异值分解(Singular Value Decomposition, SVD)技术对高维的词条–文档矩阵进行处理, 去除了原始向量空间的某些“噪音”, 使数据不再稀疏。 Hofmann[20] 在 LSA 基础上 引入主题层, 采用期望最大化算法(Expectation Maximization, EM)训练主题, 得到改进的 PLSA 算法。 LSA 本质上是通过降维提高计算准确度, 但该算法复杂度比较高, 可移植性差。 比较之下, PLSA具备统计基础, 多义词和同义词在 PLSA 中分别被训练到不同的主题和相同的主题下, 从而避免了多义词、同义词的影响, 使得计算结果更加准确, 但不适用于大规模文本。
[19] Landauer T K, Dumais S T. A Solution to Plato’s Problem:The Latent Semantic Analysis Theory of Acquisition,Induction, and Representation of Knowledge [J].Psychological Review, 1997, 104(2): 211-240.
[20] Hofmann T. Probabilistic Latent Semantic Analysis [C]//Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence.1999.
LDA(需要进一步了解)
LDA[21] 主题模型是一个三层贝叶斯概率模型, 包含词、主题和文档三层结构。采用 LDA 计算文本相似性的基本思想是对文本进行主题建模, 并在主题对应的词语分布中遍历抽取文本中的词语, 得到文本的主题分布, 通过此分布计算文本相似度[22]。 与 PLAS 不同的是, LDA 的文档到主题服从 Dirichlet 分布, 主题到词服从多项式分布, 此方法适用于大规模文本集, 也更具有鲁棒性。熊大平等[23] 提出利用 LDA计算问句相似度, 将查询语句和问题分别用 LDA 主题分布概率表示, 采用余弦相似度计算二者的相似度, 效果有了一定的提高, 尤其对特征词不同但主题相似的问题有突出效果, 该方法适用于单个问句。张超等[24] 将 LDA 分别应用于文本的名词、动词和其他词, 得到不同词性词语的相似度,综合加权三个相似度计算文本相似度, 此方法由于将建模过程并行化, 从而降低了时间复杂度。
[21] Blei D M, Ng A Y, Jordan M I. Latent Dirichlet Allocation [J].Journal of Machine Learning Research, 2003, 3: 993-1022.
[22] 王振振, 何明, 杜永萍. 基于 LDA 主题模型的文本相似度计 算 [J]. 计算机科学 , 2013, 40(12): 229-232. (WangZhenzhen, He Ming, Du Yongping. Text SimilarityComputing Based on Topic Model LDA [J]. ComputerScience, 2013, 40(12): 229-232. )
[23] 熊大平, 王健, 林鸿飞. 一种基于 LDA 的社区问答问句相似度计算方法 [J]. 中文信息学报, 2012, 26(5): 40-45.(Xiong Daping, Wang Jian, Lin Hongfei. An LDA-based Approach to Finding Similar Questions for Community Question Answer [J]. Journal of Chinese Information Processing, 2012, 26(5): 40-45. )
[24] 张超, 陈利, 李琼. 一种 PST_LDA 中文文本相似度计算方法 [J]. 计算机应用研究, 2016, 33(2): 375-377,383. (ZhangChao, Chen Li, Li Qiong. Chinese Text Similarity Algorithm Based on PST_LDA [J]. Application Research of Computers,2016, 33(2): 375-377,383. )
基于神经网络
通过神经网络模型生成词向量(Word Vector、WordEmbeddings 或 Distributed Representation)[25-26] 计算文本相似度是近年来自然语言处理领域研究较多的方法。不少产生词向量的模型和工具也被提出, 如Word2Vec[27]和 GloVe[28]等。词向量的本质是从未标记的非结构文本中训练出的一种低维实数向量, 这种表达方式使得类似的词语在距离上更为接近, 同时较好地解决了词袋模型由于词语独立带来的维数灾难和语义不足问题。Kenter 等[29] 合并由不同算法、语料库、参数设置得到的不同维度词向量并训练出特征, 经过监督学习算法得到训练分类器, 利用此分类器计算未标记短文本之间的相似度分数。Kusner 等[30] 提出使用词向量计算文档相似度的新方法, 即在词向量空间里计算将文档中所有的词移动到另一文档对应的词需要的最小移动距离(Word Mover’s Distance, WMD), 求解出来的 WMD 则是两个文档的相似度Huang 等[31] 在WMD 的基础上提出改进方法——监督词移动距离(Supervised-WMD, S-WMD), 实质上加入新文档特征“re-weighting”和新移动代价“metric A”, 令 WMD 方法适用于可监督的文本。
基于神经网络方法与词袋模型方法的不同之处在于表达文本的方式。 词向量是经过训练得到的低维实数向量, 维数可以人为限制, 实数值可根据文本距离调整, 这种文本表示符合人理解文本的方式, 所以基于词向量判断文本相似度的效果有进一步研究空间。
[25] Hinton G E. Learning Distributed Representations ofConcepts[C]//Proceedings of the 8th Annual Conference ofthe Cognitive Science Society. 1986.
[26] Bengio Y, Ducharme R, Vincent P, et al. A NeuralProbabilistic Language Model [J]. Journal of MachineLearning Research, 2003, 3(6): 1137-1155.
[27] Mikolov T, Sutskever I, Chen K, et al. DistributedRepresentations of Words and Phrases and Their Compositionality [C]//Proceedings of the 26th International Conference on Neural Information Processing Systems. 2013.
[28] Pennington J, Socher R, Manning C D. GloVe: Global Vectors for Word Representation [C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. 2014: 1532-1543.
[29] Kenter T, Rijke M D. Short Text Similarity with Word Embeddings [C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management.2015: 1411-1420.
[30] Kusner M J, Sun Y, Kolkin N I, et al. From Word Embeddings to Document Distances [C]//Proceedings of the 32nd International Conference on Machine Learning. 2015.
[31] Huang G, Guo C, Kusner M J, et al. Supervised Word Mover’s Distance [C]//Proceedings of the 30th Conference on Neural Information Processing Systems. 2016.
基于搜索引擎
随着 Web3.0 时代的到来, Web 成为内容最丰富、数据量最大的语料库, 与此同时搜索引擎相关算法的进步, 使得有任何需求的用户都可通过搜索找到答案 。 自 从 Cilibrasi 等 [32] 提 出 归 一 化 谷 歌 距 离(Normalized Google Distance, NGD) 之后, 基于搜索引擎计算语义相似度的方法开始流行起来。其基本原理是给定搜索关键词 x、y, 搜索引擎返回包含 x、y 的网页数量 f (x)、f (y)以及同时包含 x 和 y 的网页数量f (x, y), 计算谷歌相似度距离如公式(3)[32]所示。
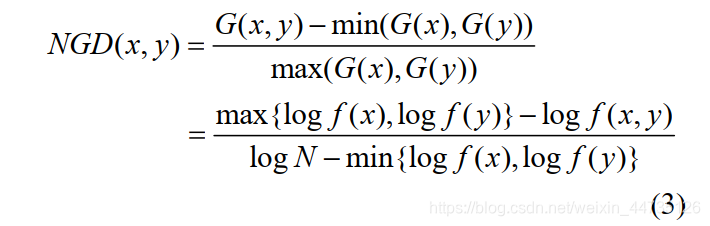
但是该方法最大的不足是计算结果完全取决于搜索引擎的查询效果, 相似度因搜索引擎而异。 刘胜久等[33]采用多个搜索引擎的搜索结果, 根据搜索引擎的市场份额为其赋予权重, 得到的结果更加综合全面。
一些学者提出通过分析返回网页内容计算相似度, Sahami 等[34]将查询关键词返回的网页内容构建为语境向量(Context Vector), 采用相似度核函数计算语境向量之间的相似度, 比单纯使用搜索数量计算相似度有更丰富的语义信息。第三类方法是综合搜索结果数量和搜索结果内容, 陈海燕[35]定义了语义片段, 即两个关键词共同出现的片段, 通过分析网页内容获取语义片段数量, 替换包含两个关键词的网页数量, 得到较为精确的相似度。
基于搜索引擎的相似度方法为相似度计算提供了丰富的语义信息, 计算结果依赖于搜索引擎的搜索效果以及对网页内容的语义分析效果, 所以精确获取返回网页数量和有效分析网页内容成为关键问题。
[32] Cilibrasi R L, Vitanyi P M B. The Google Similarity Distance[J]. IEEE Transactions on Knowledge and Data Engineering,2007, 19(3):370-383.
[33] 刘胜久, 李天瑞, 贾真, 等. 基于搜索引擎的相似度研究与 应 用 [J]. 计 算 机 科 学 , 2014, 41(4): 211-214. (Liu Shengjiu, Li Tianrui, Jia Zhen, et al. Research and Application of Similarity Based on Search Engine [J].Computer Science, 2014, 41(4): 211-214. )
[34] Sahami M, Heilman T D. A Web-based Kernel Function for Measuring the Similarity of Short Text Snippets [C]//Proceedings of the 15th International Conference on World Wide Web. 2006: 377-386.
[35] 陈海燕. 基于搜索引擎的词汇语义相似度计算方法 [J].计算机科学, 2015, 42(1): 261-267. (Chen Haiyan. Measuring Semantic Similarity Between Words Using Web Search Engines [J]. Computer Science, 2015, 42(1): 261-267.)
基于世界知识
基于世界知识的方法是指利用具有规范组织体系的知识库计算文本相似度, 一般分为两种: 基于本体知识和基于网络知识。前者一般是利用本体结构体系中概念之间的上下位和同位关系, 如果概念之间是语义相似的, 那么两个概念之间有且仅有一条路径[7,10]。而网络知识中词条呈结构化并词条之间通过超链接形式展现上下位关系, 这种信息组织方式更接近计算机的理解。概念之间的路径或词条之间的链接就成为文本相似度计算的基础。
基于本体
文本相似度计算方法使用的本体不是严格的本体概念, 而指广泛的词典、叙词表、词汇表以及狭义的本体。随着 Berners-Lee 等提出语义网的概念, 本体成为语义网中对知识建模的主要方式, 在其中发挥着重要作用。由于本体能够准确地表示概念含义并能反映出概念之间的关系, 所以本体成为文本相似度的研究基础[7]。最常利用的本体是通用词典, 例如 WordNet、《知网》(HowNet)和《同义词词林》等, 除了词典还有一些领域本体, 例如医疗本体、电子商务本体、地理本体、农业本体等。
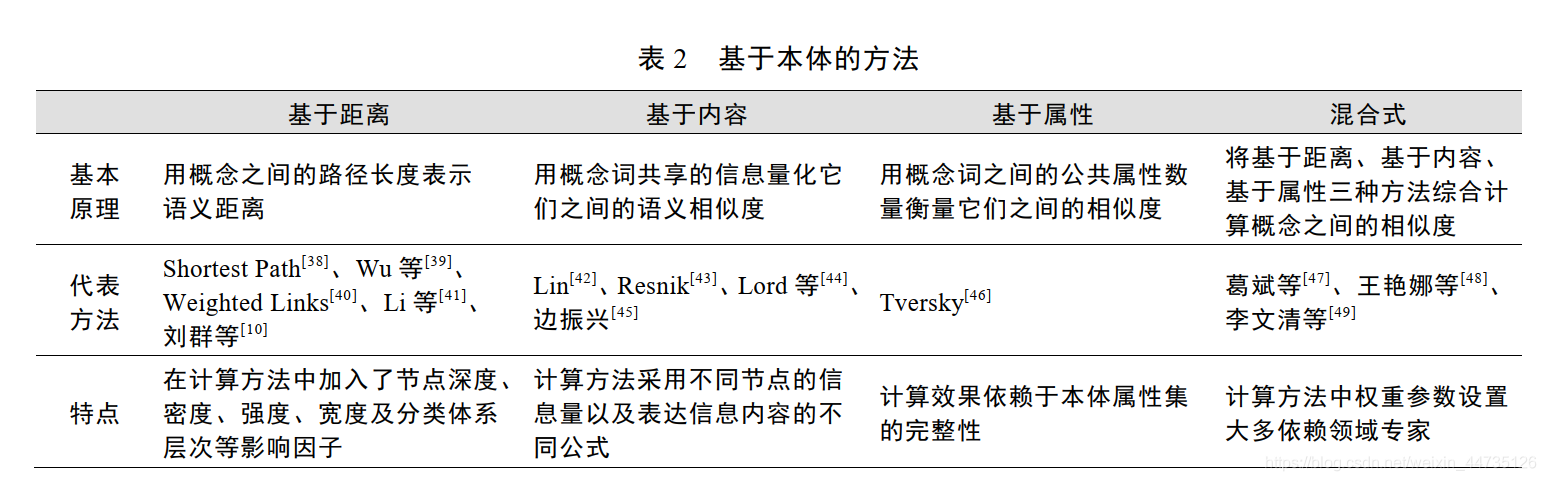
结合 Hliaoutakis[36] 、Batet 等[37]的研究, 将基于本体的文本相似度算法概括为 4 种: 基于距离(EdgeCounting Measures)、基于内容(Information Content Measures)、基于属性(Feature-based Measures)和混合式(Hybrid Measures)相似度算法。表 2 列出了各种方法的基本原理、代表方法和特点。
基于本体的方法将文本表示为本体概念以及概念之间的关系, 该方法能够准确反映概念内在语义关系,是一种重要的语义相似度计算方法, 主要缺点如下:
①本体一般需要专家参与建设, 耗费大量时间和精力,而已有的通用本体存在更新速度慢、词汇量有限等问题, 不适用于出现的新型词语;
②利用本体计算文本相似度, 首先是在词语层次进行计算, 然后累加词语相似度获得长文本相似度, 相对基于语料库的方法对文本整体处理而言计算效率较低;
③无论是通用本体还是领域本体, 本体之间相互独立将带来本体异构问题, 不利于跨领域的文本相似度计算。
基于网络知识
由于本体中词语数量的限制, 有些学者开始转向基于网络知识方法的研究, 原因是后者覆盖范围广泛、富含丰富的语义信息、更新速度相对较快, 使用最多的网络知识是维基百科、百度百科。网络知识一般包括两种结构, 分别是词条页面之间的链接和词条之间的层次结构。孙琛琛等[50]将其概括为: 文章网络和分类树(以树为主题的图)。最早使用维基百科计算语义相关度是 Strube 等[51]提出的 WikiRelate!方法, 基本原理是在维基百科中检索出与词语相关的网页, 并通过抽取网页所属类别找到分类树, 最终基于抽取的页面以及在分类法中的路径计算相关度。该方法利用了维基百科的层次结构,计算效果与基于本体的方法相当, 然而此方法更适用于词语丰富的文本。Gabrilovich 等[52]提出 ESA 方法,
基于维基百科派生出高维概念空间并将词语表示为维基百科概念的权重向量, 通过比较两个概念向量(比如采用余弦值方法)得到语义相关度, 计算效果优于人工判读。ESA 比 WikiRelate!表达更加复杂的语义, 而且模型对用户来说简单易懂, 鲁棒性较好。Milne 等[53]提出的 WLM 方法仅使用维基百科的链接结构以及较少的数据和资源, 比 ESA 简单, 但计算结果不如 ESA理想。严格来说, 这些方法是计算文本语义相关度,
其包括范围比语义相似度大, 但是这些方法为基于维基百科的语义相似度计算提供了良好的借鉴。盛志超等[54]提出一种模仿人脑联想方式的方法, 基于维基百科页面的链接信息, 并依托 TF-IDF 算法得到词语相似度, 尽管取得了一定的效果, 但是将维基百科的页面信息和类别信息以较为简单的方式结合成统一的。彭丽针等[55]考虑到维基百科页面的社区现象[56], 对带有标签的页面采用 HITS 算法获取社区类别, 基于词语类别与链接关系计算相似度, 实验证明该方法具有一定的可行性和有效性, 但由于未深入分析页面内容导致语义程度较弱。与维基百科类似, 百度百科作为众人参与可协作的中文百科全书, 到 2017 年 1 月已经有超过 1 400 万的词条, 数据量成为百度百科相较于其他语料库的绝对优势。詹志建等[57]在分析百科词条结构的基础上,采用向量空间模型计算百科名片、词条正文、相关词条的相似度, 采用基于信息内容的方法计算开放分类的相似度, 最终加权得到词条相似度, 计算效果优良,但是该方法对词条语义信息的分析并不深入。尹坤等[58]在计算方法中引入图论思想, 将百度百科视为图, 词条视为图中节点, 采用 SimRank 方法计算词条之间的相似度。该方法充分利用了百科词条之间的链接关系,但仅对于相关词条较多的词条有好的效果, 而对于相关词条较少的词条的计算效果则不理想。综上所述, 基于网络知识的文本相似度计算方法大多利用页面链接或层次结构, 能较好地反映出词条的语义关系。但其不足在于: 词条与词条的信息完备程度差异较大, 不能保证计算准确度; 网络知识的产生方式是大众参与, 导致文本缺少一定的专业性。识源, 过于简单, 缺乏一定的理论支撑。


![[将小白进行到底] 如何比较两篇文章的相似度](https://images0.cnblogs.com/blog/79263/201304/02151548-f7e8409392c846498b9d9e548e92926f.png)